Python 비동기 병렬 처리로 OCR 속도 단축하기 (with ThreadPoolExecutor & asyncio)

최근 회사에서 한 달 정도의 신입사원 SW교육을 수강하면서, 라즈베리파이를 이용한 On-Device AI 프로젝트를 진행했습니다. 프로젝트를 진행하면서 마주한 기술적 고민과 해결, 분석 과정을 공유합니다.
진행한 프로젝트

텔레스트레이션 이라는 보드게임을 아시나요?
여러 명의 플레이어가 제시어를 받아 그림을 그리고 서로에게 넘기면서 제시어를 맞추고, 다시 그리면서 서로의 그림 실력과 추론 능력을 비웃는(?) 보드게임입니다.
저희는 이 텔레스트레이션 게임을 4개의 라즈베리파이에서 멀티플레이로 즐길 수 있는 프로젝트를 진행했습니다.
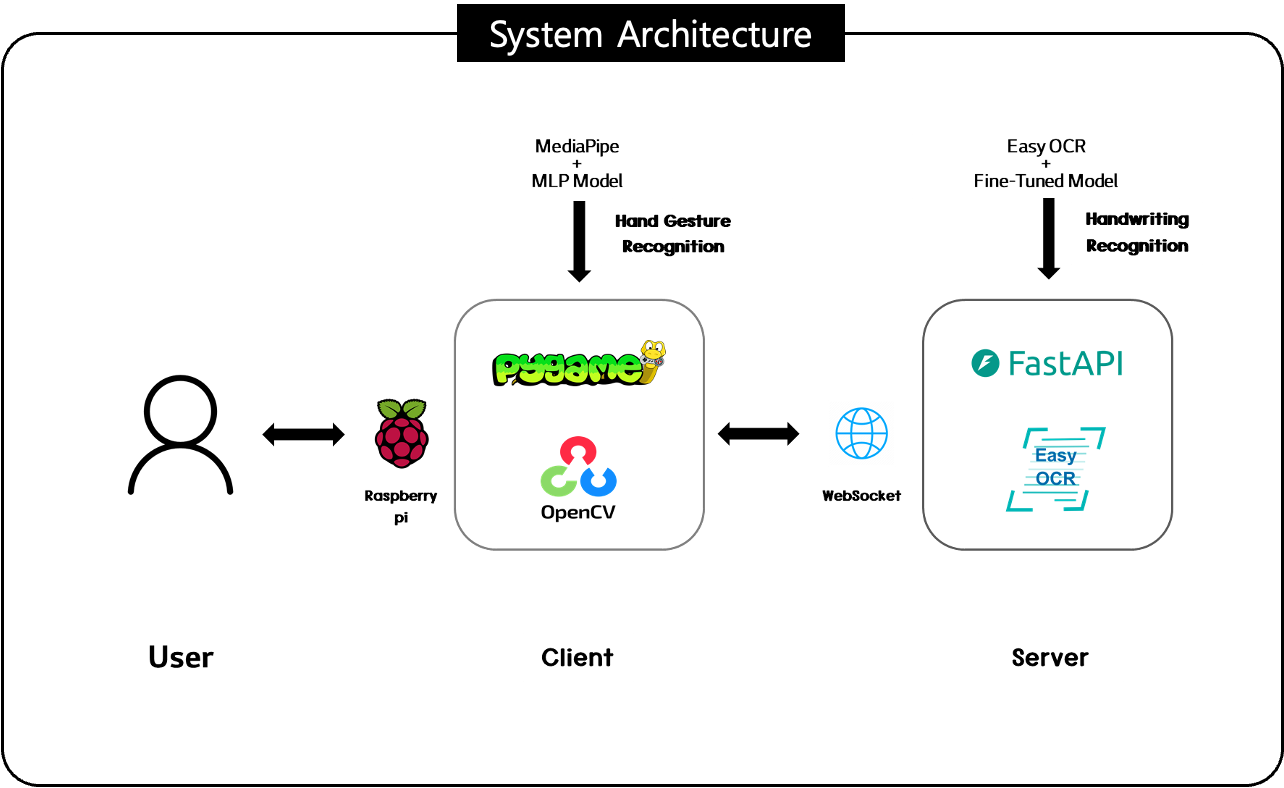
라즈베리파이에서 게임을 실행하는 클라이언트는 Pygame을 사용했고, 게임 서버는 FastAPI를 사용했으며, 클라이언트 - 서버 간 통신은 WebSocket을 사용했습니다.
저는 텔레스트레이션 게임을 진행하고 클라이언트와 데이터를 제대로 주고 받을 수 있도록 하는 서버 개발을 주로 담당했습니다.
🚨 문제 발생 🚨
게임의 마지막 단계에서 서버는 4개의 클라이언트에게 손글씨로 작성된 글자 이미지를 받습니다.
각 클라이언트에서 타이머를 관리하지만, 그 시작 시점은 서버에서 동시에 보내주기 때문에, 거의 동시에 4개 이미지가 서버에 도착합니다.
그러면 서버는 4개 이미지를 받아 각각 OCR을 통해 손글씨 이미지를 글자로 변환합니다. 이 과정에서 EasyOCR이라는 OCR 모델이 사용됩니다.
모델을 로드하는 과정은 오래 걸리지만, 서버 시작 초기에 수행됩니다. 각 이미지를 OCR로 처리하는 과정에는 시간이 상대적으로 적게 걸립니다.
실제 사용자들이 사용하는 데모 환경에서는 GPU가 탑재된 고성능의 외부 서버 (집 데스크탑...) 을 사용할 예정이어서 별 문제가 되지 않는다고 생각했습니다.
라즈베리파이에서는?
그렇게 개발한 OCR 기능을 탑재한 서버를 클라이언트에서도 쉽게 재실행하며 테스트할 수 있도록, 클라이언트가 실행되는 라즈베리파이에 서버도 같이 실행할 수 있도록 설정해 주었습니다.
클라이언트를 개발하면서 동작을 테스트해 보는데, 문제가 생겼습니다. 마지막 라운드가 끝나고 결과가 나오기까지 10초가 넘게 걸리는 것이었습니다.
문제의 원인은 OCR 처리 과정이 너무 오래 걸려서 였습니다.
외부 서버를 사용할 때는 각 과정이 0.5초가 채 안 걸려 전체 과정이 2초도 걸리지 않았는데, 낮은 성능의 라즈베리파이에서 서버를 구동하니 각 과정이 3초가 넘게 걸리면서, 결과가 나오기까지 너무 오랜 시간을 기다려야 했습니다.
고성능의 서버를 사용하면 해결될 문제이지만 (이 안일한 생각은 나중에 발목을 잡습니다), 최근에 공부했던 병렬 처리 기법을 사용하면 전체 처리 속도를 단축할 수 있을 것 같아, 한번 시도해보기로 했습니다.
1. ProcessPoolExecutor
처음에 생각했던 건 ProcessPoolExecutor 를 사용하는 방식이었습니다.
공부하기로는 병렬 처리할 작업이 CPU Bound 작업이면 멀티 프로세스를, I/O Bound 작업이면 멀티 쓰레드를 사용하는 것이 유리하다고 알고 있었습니다.
CPU Bound: 계산이 많아 CPU 성능이 성능의 핵심인 작업. (ex. 수학 계산, 데이터 처리)
I/O Bound: 디스크나 네트워크 같은 입출력을 기다리는 시간이 많은 작업. (ex. 파일 읽기, 웹 요청)
OCR 처리 과정은 계산이 많을테니 CPU Bound겠구나! 라는 매우 단순한 생각으로 멀티 프로세스를 사용하는 ProcessPoolExecutor를 먼저 사용해 봤습니다.
결과적으로, 여러 문제가 발생했습니다.
- 멀티 프로세스를 사용하면서 GameManager에서 처리 결과를 활용하기 복잡함 (각 처리 과정의 순서가 꼬이는 등)
- 프로세스를 생성할 때마다 모델을 새로 로드함..! (매우 오래 걸림..)
- 로드된 모델에 OCR 처리를 위탁하는데, 이 경우 멀티 프로세스의 장점이 퇴색됨 (
CPU Bound작업이 아닐 수 있음)
구조와 원리를 제대로 이해하지 않고 사용했던 터라 여러 문제가 있었고, 빠르게 포기하고 다음 방법으로 넘어갔습니다.
2. ThreadPoolExecutor
그래서 다음으로 시도했던 건 ThreadPoolExecutor 를 사용하는 방식이었습니다.
OCR Reader 객체에 이미지를 로드하고, base64로 이미지를 디코딩하고, 이미지를 전처리하는 과정에서 I/O Bound도 발생할 수 있다고 생각해서, 멀티 쓰레드로도 시간을 단축할 수 있지 않을까? 하는 생각에 ThreadPoolExecutor 를 사용하는 방식도 시도해 보았습니다.
기존 OCR 코드는 아래와 같이 recognize_text 함수로 구성되어 있었습니다.
def recognize_text(base64_str) -> List[str]:
"""Base64로 인코딩된 이미지 문자열을 OCR로 분석하고 인식된 단어를 반환"""이 recognize_text 함수를 병렬로 실행할 수 있게 ThreadPoolExecutor를 활용하는 함수를 새로 만들었습니다.
from .ocr_image_convert import recognize_text
def threadpool_ocr(image_data, executor):
"""OCR을 스레드에서 실행"""
future = executor.submit(recognize_text, image_data)
result = future.result()
return "".join(result) if result else "인식안됨"전체 게임 진행을 담당하는 GameManager 객체에서 이미지를 받으면 threadpool_ocr 함수를 호출해서 OCR 처리를 하는 구조였습니다.
if self.game_round == self.max_players:
self.result_words[word_index] = threadpool_ocr(data, self.executor)ThreadPoolExecutor는 GameManager에서 self.executor로 생성해서 각 요청마다 공통으로 사용했습니다. 각 요청이 하나의 executor를 공유해야 병렬 처리가 제대로 동작할 것이기 때문입니다.
self.executor = ThreadPoolExecutor(max_workers=4)최대 4개의 요청이 동시에 들어올 수 있으므로 max_workers 는 4로 설정했습니다.
max_workers를 따로 설정하지 않으면 기본값으로 설정됩니다.
기본값은 Python 3.8 기준min(32, os.cpu_count() + 4), 3.13 기준min(32, (os.process_cpu_count() or 1) + 4)입니다.
https://docs.python.org/3.13/library/concurrent.futures.html#threadpoolexecutor
위와 같은 구조로 ThreadPoolExecutor를 활용한 병렬 처리를 구현하고, 별다른 테스트 코드나 시간 측정은 하지 않고 그냥 몇 번 돌려보면서 성능이 개선되었구나..! 하고 넘어갔습니다.
나중에 코드를 다시 보니 위 방식에는 문제가 있었습니다. (왜 당시에 성능이 개선되었다고 느꼈는지.. 시간 기록이라도 해 두었으면 좋았을텐데..)
왜 문제가 되었는가?
위와 같이 구현한 뒤 쭉쭉 기능을 잘 개발해서 성공적으로 텔레스트레이션 멀티플레이 게임을 구현하였습니다.
당시 사외 교육장에서 다른 교육생들이 직접 게임을 해 볼 수 있도록 데모 시연을 진행했었는데, 그 때는 앞서 말한 고성능 서버를 사용했기 때문에 결과가 바로 나오면서 정상적으로 게임 진행을 할 수 있었습니다.
그 다음 날에 회사 내에서도 데모 시연을 하게 되었는데, 변수가 생겼습니다.
사내에서 서버 연결이 필요할 경우 휴대폰의 핫스팟 기능을 사용하라고 안내를 받았고, 사외에서 테스트 할 때는 정상적으로 동작했는데, 당일이 되니 사람이 많아서인지 핫스팟 기능이 정상적으로 동작하지 않았습니다.
여러 방법을 시도해 봤지만 라즈베리파이 하나에 서버를 구동해서 로컬로 연결하는게 최선이었고, 그 방식으로 데모 시연을 진행하였습니다.
그런데...
😭 개선이 안 됨 😭
데모를 진행해 보니 결과 화면이 뜨는 데 너무 오랜 시간이 걸리는 문제가 여전히 발생했습니다.
저성능 서버이고, GPU 활용이 안 되는 환경이니 시간이 더 오래 걸리는 것은 당연했지만, 병렬 처리가 제대로 작동한다면 분명 그 정도까지 오래 걸리지는 않았을 것이었습니다.
게임 진행이 아예 안 되는 것은 아니었으니 데모 시연은 그대로 진행했지만, 데모에 참가한 참가자 분들께 결과가 나오는 데 오래 걸리니 양해를 부탁드린다는 말씀을 계속 드려야만 했습니다.
프로젝트가 끝나고..
데모 시연을 어찌저찌 끝내고 프로젝트도 잘 마무리했지만, 분명 고려하지 못한 부분이 아니었음에도 제대로 개선하지 못했다는 아쉬움이 남았습니다.
나중에라도 이 부분을 다시 확인해서 왜 개선이 되지 않았는지를 알아내야겠다고 생각했고, 2주 정도 지난 지금 시점에 다시 확인해 보았습니다.
🔎 문제 재분석 🔍
프로젝트가 끝나고 라즈베리파이는 반납했던 터라, 문제 상황을 그대로 재현하기는 어려웠습니다.
그래서 Pytest 를 사용해서 결과 화면이 나오는 상황을 비슷하게 재현해 보기로 했습니다.
테스트 fixtures
@pytest.fixture
def base64_image_list():
image_list = []
for image_name in os.listdir(TEST_IMAGE_PATH):
with open(os.path.join(TEST_IMAGE_PATH, image_name), "rb") as f:
image_list.append(base64.b64encode(f.read()).decode())
return image_list
@pytest.fixture
# 모델 예열
def warmup_model():
"""모델 예열"""
# 예열할 이미지 경로
image_path = os.path.join(TEST_IMAGE_PATH, "기타.png")
with open(image_path, "rb") as f:
base64_str = base64.b64encode(f.read()).decode()
# 모델 예열
recognize_text(base64_str)base64_image_list 는 프로젝트 진행 당시 수집했던 이미지를 사용해 만든 테스트 이미지셋입니다. 손글씨 이미지가 들어 있으며, 테스트에서는 4장이 사용됩니다.
warmup_model 은 테스트 구현 중에 추가한 부분입니다.
def test_serial_ocr_speed(base64_image_list):
"""직렬 방식 OCR 처리 속도 측정"""
print(f"[직렬 처리] 총 시간: {elapsed:.2f}초")
def test_parallel_ocr_speed(base64_image_list):
"""병렬 방식 OCR 처리 속도 측정"""
print(f"[병렬 처리] 총 시간: {elapsed:.2f}초")구현 초기에는 이렇게 직렬 처리와 병렬 처리 테스트 코드를 작성해서 실행 시간을 비교하는 방식으로 진행했습니다.
pytest -s와 같이-s옵션을 사용하면 테스트 코드 내에 작성한
이렇게 확인해보니 병렬 처리가 직렬 처리보다 약 2배 정도 빠르다고 결과가 나왔습니다.
데모 시연 때 확인했던 결과와 달라서, 각각 10회 실행하고 평균치로 계산할 수 있도록 코드를 바꿔서 실행해 봤는데, 두 경우의 시간이 비슷하게 나왔습니다.
좀 더 자세히 확인하기 위해 pytest -s services/test_parallel_ocr.py::test_serial_ocr_speed 와 같은 명령어로 테스트 함수를 하나씩 수행해 봤는데, 두 경우 다 이전보다 시간이 늘어났습니다.
왜 그런가 확인해 보니, pytest 를 실행해서 EasyOCR 모델을 초기에 로드하는 시간이 처음 실행되는 테스트 함수의 시간에 포함되는 것으로 보였습니다.
이 문제를 해결하기 위해 테스트 수행 시 먼저 모델을 로드할 수 있도록 fixture로 warmup_model 을 만들어 각 테스트 함수에 포함시켰습니다.
초기 로드 시간이 테스트 결과에 영향을 주지 않도록 테스트 함수 작동 전에 먼저 warmup_model 이 작동하게 만든 것입니다.
직렬 vs 병렬 비교
그렇게 만든 테스트 코드는 다음과 같았습니다.
def test_serial_ocr_speed(base64_image_list, warmup_model):
"""직렬 방식 OCR 처리 속도 측정"""
num_tasks = 4
start_time = time.time()
for i in range(num_tasks):
recognize_text(base64_image_list[i % len(base64_image_list)])
end_time = time.time()
elapsed = end_time - start_time
print(f"[직렬 처리] 총 시간: {elapsed:.2f}초")
assert isinstance(elapsed, float)
def test_parallel_ocr_speed(base64_image_list, warmup_model):
"""병렬 방식 OCR 처리 속도 측정"""
num_tasks = 4
executor = ThreadPoolExecutor(max_workers=4)
start_time = time.time()
for i in range(num_tasks):
threadpool_ocr(base64_image_list[i % len(base64_image_list)], executor)
end_time = time.time()
elapsed = end_time - start_time
print(f"[병렬 처리] 총 시간: {elapsed:.2f}초")
assert isinstance(elapsed, float)이렇게 작성해서 두 과정을 비교한 결과, 직렬 처리와 병렬 처리의 시간 차이는 거의 나지 않고, 오히려 병렬 처리가 10% 정도 더 오래 걸리는 결과가 나왔습니다.
데모 시연에서 문제가 생긴 것도 병렬 처리가 제대로 작동하지 않았기 때문으로 보였고, threadpool_ocr 함수가 의도와 다르게 작동하고 있는게 아닌가 하는 의심이 들었습니다.
원인 분석
# services/threadpool_ocr.py
from .ocr_image_convert import recognize_text
def threadpool_ocr(image_data, executor):
"""OCR을 스레드에서 실행"""
future = executor.submit(recognize_text, image_data)
result = future.result() # <- 이 부분이 문제 🚨
return "".join(result) if result else "인식안됨"threadpool_ocr 함수를 다시 분석해보니, 문제가 보였습니다.
executor에 recognize_text 를 처리하라고 맡겨놓고, 정작 GameManager에 return 할 때는 result를 받아서 처리하는 구조로 되어 있었습니다.
오래 걸리는 작업을 처리하고 있으라고 executor에 게 맡겨 놨는데, 정작 메인 쓰레드가 그 앞에 서서 result가 나오기를 기다리는 blocking 구조였던 것입니다.
구조적으로 이 문제를 해결하는 방법은 두 가지 정도가 떠올랐습니다.
threadpool_ocr함수에서는 executor에 submit하는 작업만 수행.GameManager에 result를 넘겨 처리하는 부분은recognize_text에 구현threadpool_ocr함수를asyncio로 비동기 처리할 수 있도록 변환
1번 방법이 직관적으로 떠올랐으나, recognize_text 에서 어떻게 결과를 GameManager 로 보낼지도 생각해 봐야 했고, 결국 그 부분에서도 콜백 함수를 사용하는 등 구조가 복잡해질 것 같았습니다.
그래서 asyncio 를 사용해 개선하는 것이 효과가 있는지를 검증해 보기로 했습니다.
asyncio를 통한 개선
# services/threadpool_ocr.py
import asyncio
async def threadpool_ocr_async(image_data, executor):
loop = asyncio.get_event_loop()
return await loop.run_in_executor(executor, recognize_text, image_data)기존 함수 밑에 위와 같은 async 활용 코드를 새로 작성했습니다.
asyncio 의 run_in_executor 를 사용해서, 처음 의도한 대로 recognize_text 작업을 비동기 병렬 처리하는 구조로 변경했습니다.
이렇게 변경했을 때, 처리 시간을 확인하는 테스트 코드는 다음과 같습니다.
@pytest.mark.asyncio
async def test_parallel_ocr_speed_async(base64_image_list, warmup_model):
"""비동기 병렬 OCR 처리 속도 측정"""
num_tasks = 4
executor = ThreadPoolExecutor(max_workers=4)
start_time = time.time()
tasks = [
threadpool_ocr_async(base64_image_list[i % len(base64_image_list)], executor)
for i in range(num_tasks)
]
results = await asyncio.gather(*tasks)
end_time = time.time()
elapsed = end_time - start_time
print(f"[비동기 병렬 처리] 총 시간: {elapsed:.2f}초")
assert isinstance(elapsed, float)
assert results is not None
asyncio를 사용한 테스트 코드를 수행하기 위해서는pytest-asyncio와 같은 패키지를 설치해야 하고,@pytest.mark.asyncio데코레이터를 달아주면 된다.
직렬 처리, 기존 병렬 처리, 비동기 병렬 처리 세 가지를 비교한 테스트 결과는 다음과 같았습니다.
[직렬 처리] 총 시간: 0.20초
[병렬 처리] 총 시간: 0.22초
[비동기 병렬 처리] 총 시간: 0.12초비동기 병렬 처리가 기존 방식보다 약 2배 정도 빨리 수행되었음을 확인할 수 있었습니다.
결론
이 과정을 통해 깨달은 사실이 몇 가지 있었습니다.
- 꼭 테스트 코드를 작성하지 않더라도, 기능 개선 시에는 결과를 명확히 비교하고 기록하자... (시간에 쫓기더라도...)
- 테스트 코드를 작성하여 실제 클라이언트 없이도 기능 동작, 성능을 확인할 수 있다 (
pytest의-s옵션에 대해 처음 알게 됨)- 아직 executor와 asyncio 사용에 미숙하니 공부가 더 필요하다...
그래도 ThreadPoolExecutor 등 병렬 처리 관련해서 공부한 적이 있어 실제 문제에 적용할 시도라도 해볼 수 있어서 뿌듯했습니다.
asyncio 등 비동기 처리는 아직도 제대로 이해하지 못해 계속해서 공부할 필요를 느꼈습니다.
테스트 코드로 성능 확인은 해 봤지만, 라즈베리파이 보드를 반납해 실제 환경에서 테스트 해 보지 못해 아쉬움이 남습니다.
또 테스트 코드를 수정한 것처럼 GameManager의 실제 코드도 수정해야 했는데, 이 부분이 제대로 동작하는 지도 확인하지 못해 아쉬움이 있습니다.
다음에 비슷한 문제를 만나면 잘 개선할 수 있기를..!
