1. Overview
사진에서 일반 쓰레기, 플라스틱, 종이, 유리 등 10 종류의 쓰레기를 Detection하는 모델을 만들어 쓰레기 분리배출에 도움이 되고자 함 🌎
-
Input : 쓰레기 객체가 담긴 이미지와 bbox 정보(좌표, 카테고리)가 모델의 인풋으로 사용
Bbox annotation은 COCO format으로 제공 -
Output : 모델은 bbox 좌표, 카테고리, score 값을 리턴
-
Metric: test set의 mAP50
2. Dataset
dataset
├── train.json
├── test.json
├── train
└── test- train: 4883 images
- test: 4871 images
- class: General trash, Paper, Paper pack, Metal, Glass, Plastic, Styrofoam, Plastic bag, Battery, Clothing
# images
{
"width": 1024,
"height": 1024,
"file_name": "train/0000.jpg",
"license": 0,
"flickr_url": null,
"coco_url": null,
"date_captured": "2020-12-26 14:44:23",
"id": 0
},
# annotations
{
"image_id": 0,
"category_id": 0,
"area": 257301.66,
"bbox": [
197.6,
193.7,
547.8,
469.7
],
"iscrowd": 0,
"id": 0
},- Bbox annotation: .json / coco dataset
- images에는 데이터셋 전체 이미지 목록과 이미지 각각의 width, height, 파일명이 포함돼있음
- annotations에는 해당 image에 대한 자세한 라벨 정보들이 포함돼있음
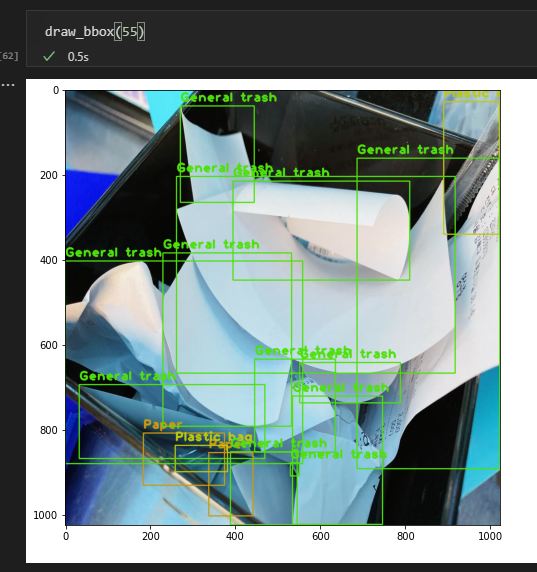
Train/test dataset/annotation 모두 bbox가 제대로 안 쳐있는것도 많고 기준도 모호하거나 하는 등 기준이 명확하지 않음
Data cleaning
그래서 dataset 다 뜯어보고 일정 기준을 정해서 data cleaning하기로 함
일관적으로 작업되어 있는 경우 test에도 그렇게 되어있을 것으로 생각돼 지우지 않았음
- 배경이 대부분인 줄 안 지움
- 애매한 general trash 안 지움
- 과일 포장하는거 plastic, general trash 둘 다 둠
- paper, paper pack 모호한거 안 지움
- 박스 위 테이프 때문에 paper, genral trash 겹친거 안 지움
- 명함, 광고지 paper, general trash 둘 다 둠
- 컵라면, 컵 general trash, paper pack 둘 다 둠
- paper pack, plastic bag 거의 겹친거 안 지움 ( ex) 담뱃갑)
- 종량제 봉투는 plastic bag
- 영수증 뭉치는 지우기
- 어두워서 안 보이는건 지우기
- 전단지에 안 보이는 테이프 지우기
3. EDA
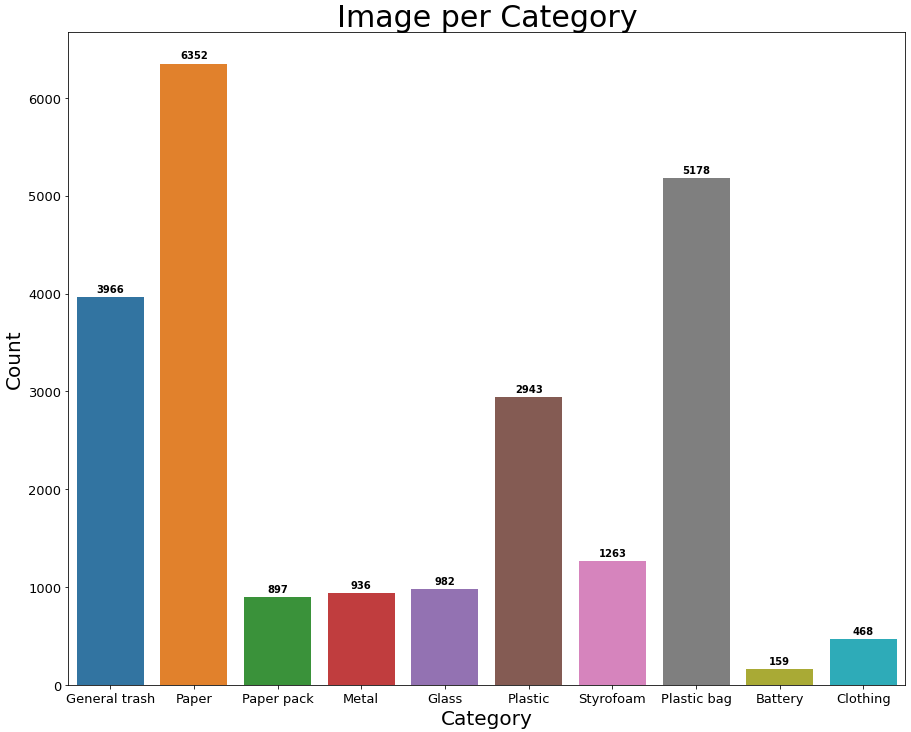
- Class imbalance가 심각함
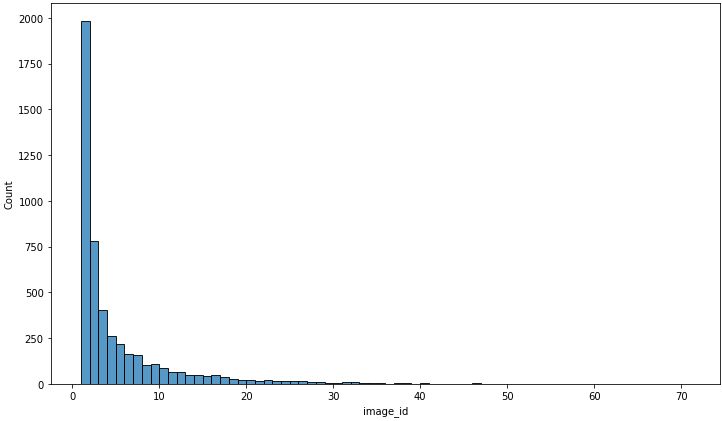
- 하나의 image에 나타나는 object의 수의 대부분은 1~40 사이
Outlier로는 71이 존재
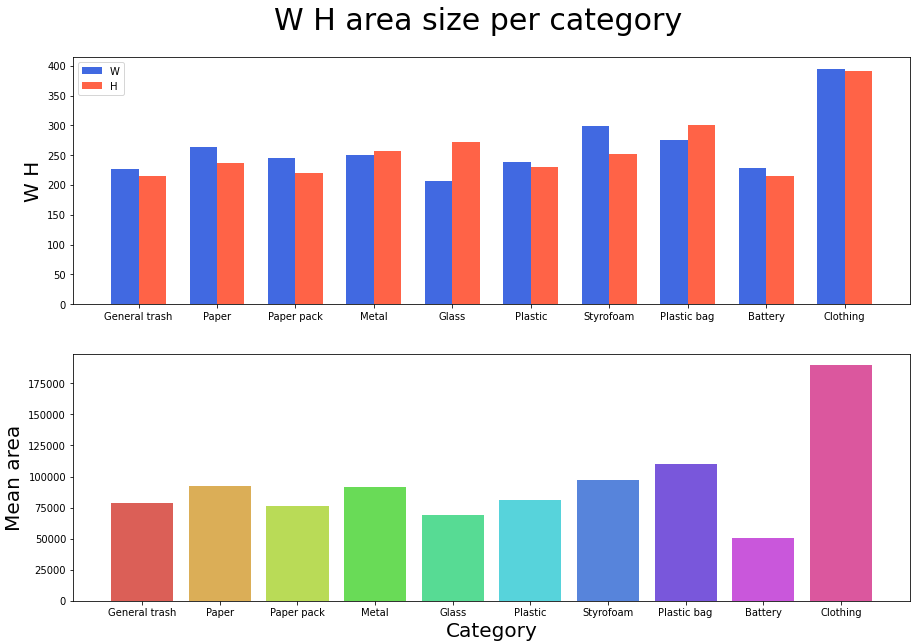
- Class별 bbox size는 이렇다 할 특징이 없는편
clothing은 대부분 큰 편이고, battery는 작은 편이라는 점이 그나마 주목할만한 점
4. Pipeline
Baseline model
-
MMDetection: MMDetection을 기반으로 SOTA 논문이 구현돼있는 UniverseNet을 사용
readme.md와 PapersWithCode를 기준으로 mAP 높은 모델들이 대체로 좋은 성능을 보임
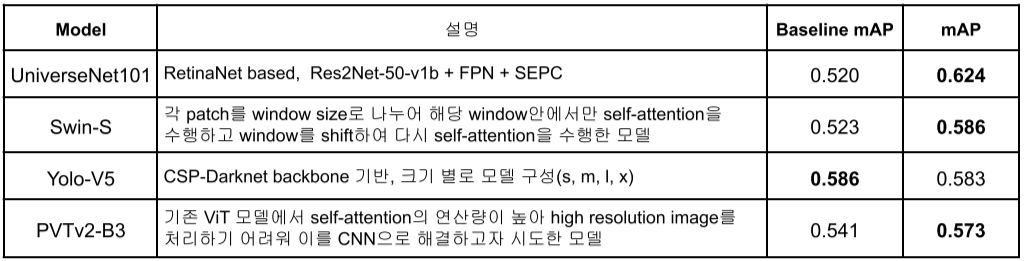
- 최종으로 사용한 모델들
Validation
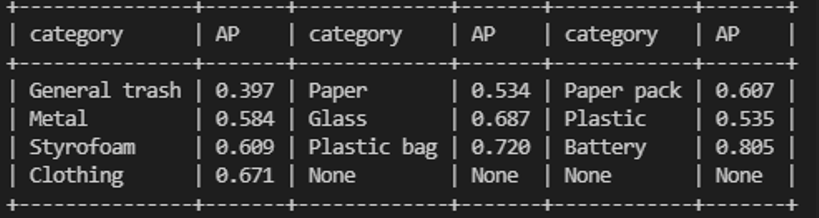
MMDetection에서 제공하는 class별 AP와 Public leaderboard를 사용
명확한 별도의 validation set을 정해두지 않고 Public leaderboard에만 의존하다 보니 기록이 쌓일수록 model 별 성능 측정과 개선 방향을 정하는 것이 어려웠던 것 같음
Wandb도 public leaderboard와 1:1 대응이라고 보기 어려워 섣불리 믿기도 어려웠고..
개인적으로 가장 아쉬웠던 부분이라 다음 대회에서 개선해야 할 부분
Augment
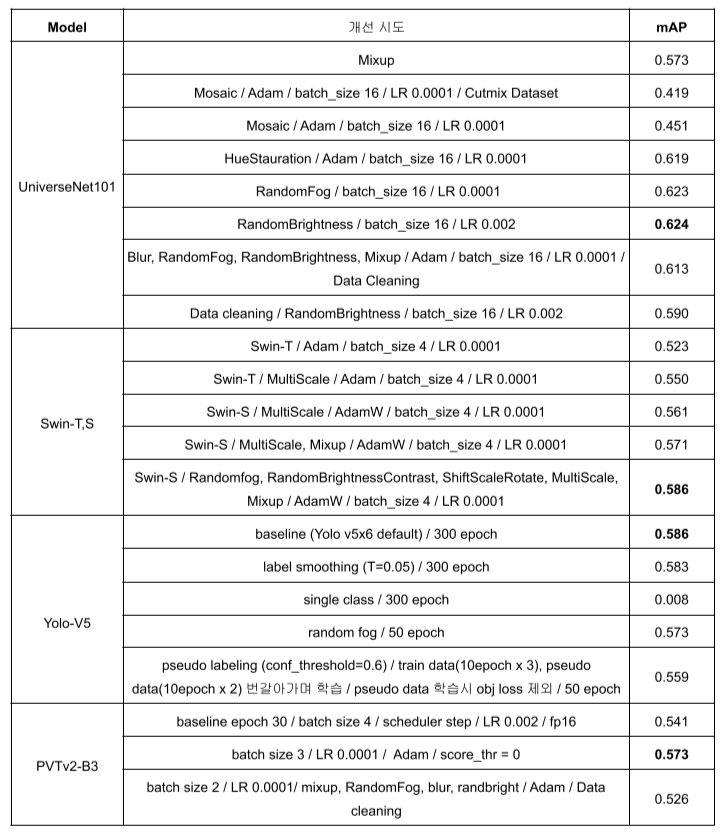
Seed 고정은 config가 아니라 train.py에서 --seed로 seed 고정을 해야되는데 이를 대회 후반부에 알아서 각 augment별 정확한 성능 평가는 하지 못했음
UniverseNet-50에 augment만 변경해서 각 augment별 성능을 확인 후 좋은 것들만 ensemble하려고 했는데, model이 작아서 그런지 학습이 잘 안돼서 오히려 성능이 떨어져서 Universenet-101을 이용하기로 함
RandomFog, RandomBrightness, Blur + batch_size를 늘리는 것 정도가 눈에 띄는 성능 향상이 있었음
Pseudo labeling, mosaic은 의외로 mAP가 크게 오르지 않았는데, 해당 방법들이 오히려 test dataset과 다른 분포를 만들어 학습에 악영향을 미칠 수도 있다는 결론이 나옴
Ensemble
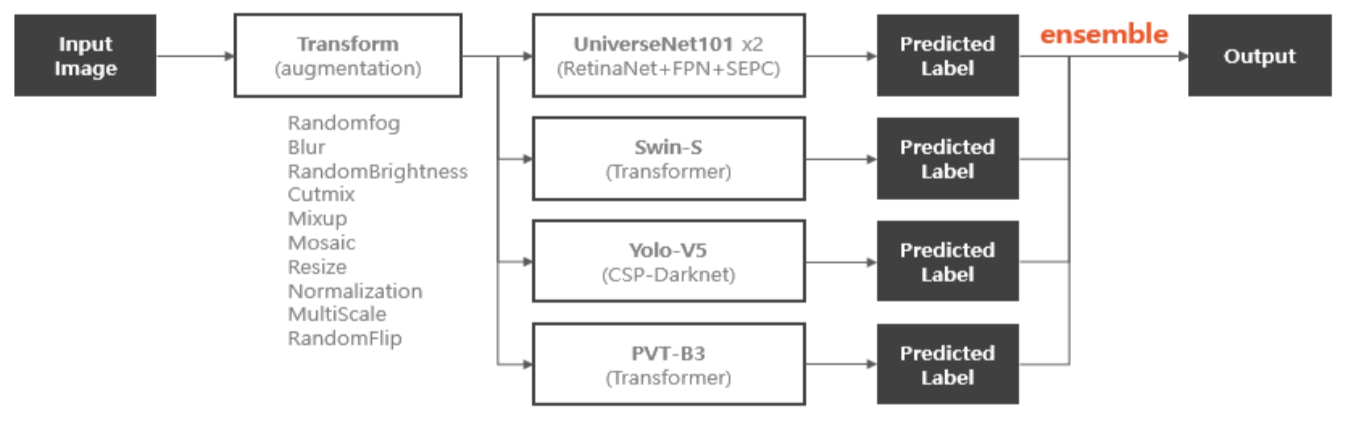
최종적으로는 UniverseNet-101, Swin-s, YOLOv5, PVT-B3을 ensemble해서 사용
후술할 mAP trick 때문에 ensemble의 결과를 다시 ensemble하는 것으로도 mAP가 0.001~0.003 정도 꾸준히 올라갔으나, 결과는 오히려 직관성이 떨어졌음
5. Evaluate
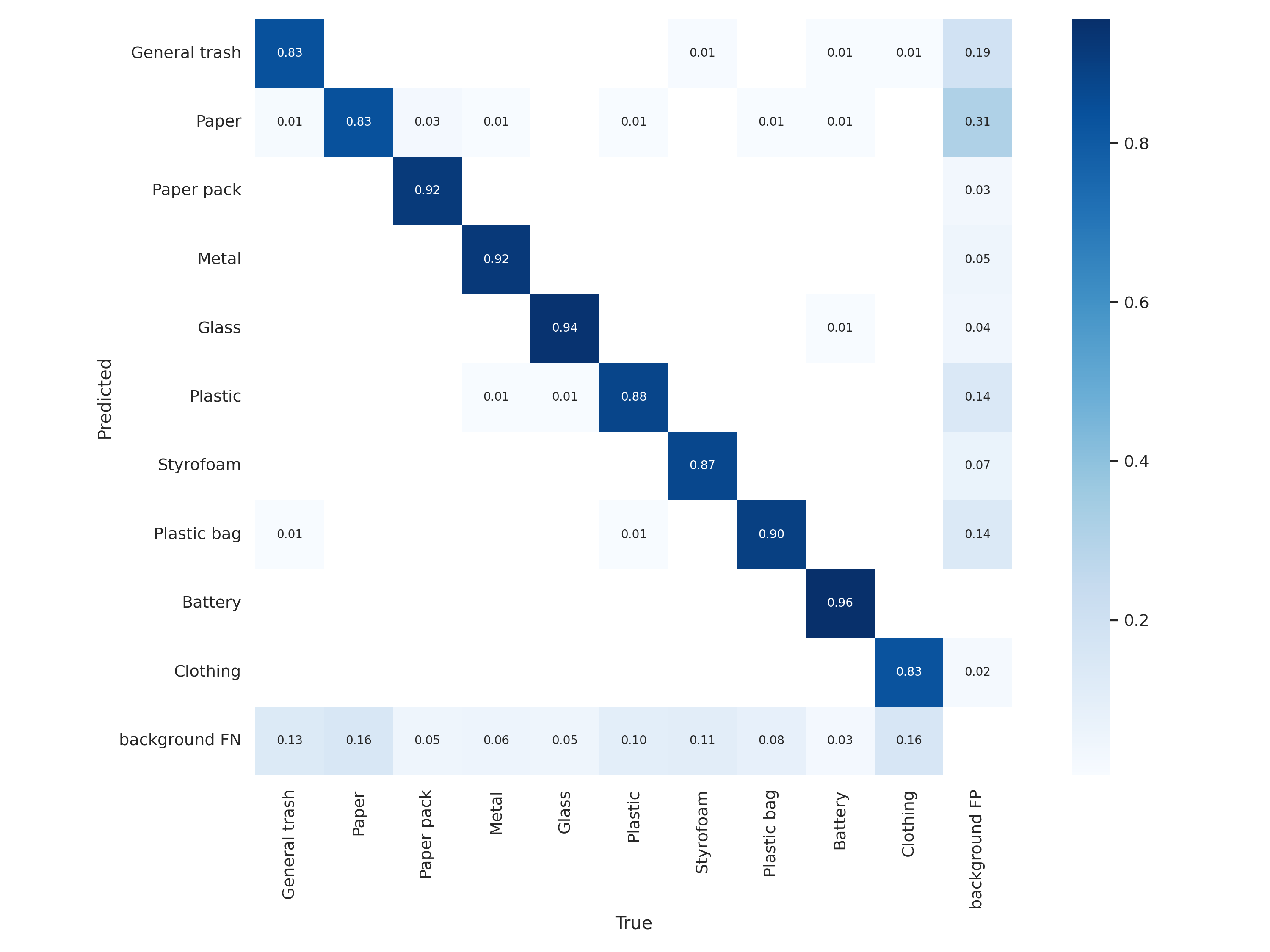
- 배터리는 갯수가 적어서 걱정했는데 생각보다 잘 잡아냄
- train/test 모두 배터리는 따로 찍은 사진이 대부분이기 때문에 dataset이 적더라도 비해서 잘 잡아내는편
- 반면, data가 많더라도 annotation이 불분명한 경우 AP가 낮음
- 종이-종이팩 간 구분이 안됨
- clothing도 장갑 같은 경우 GT-clothing 왔다갔다 해서 헷갈리는듯
- paper가 전단지, 영수증, 명함 등은 GT로, 종이컵 등은 paper pack으로 헷갈리게 돼있어서 다른 class와 혼동을 많이 함
- 이를 고려해 data cleaning을 진행
- UniverseNet, YOLOv5 모두 clean data로 train하자 오히려 mAP가 감소
- Test dataset의 annotation도 train처럼 모호하기 때문에 감소했을 것이라 추측
mAP Trick?

mAP 0.673인 output의 visualization

mAP는 기존의 bbox보다 낮은 confidence score를 가진 bbox를 새로 추가한다고 해서 떨어지지 않음
따라서 NMS 등 ensemble을 할 때 IOU threshold를 낮게 줘서 무조건 bbox를 많이 치는 것이 점수가 높게 나온다는 trick이 존재함
하지만 WBF, Soft-NMS 같은 경우는 bbox의 score를 재조정하면서 순위가 바뀌게 되고, mAP가 떨어질 수도 있기 때문에 가장 중요한 것은 상위 score의 bbox를 잘 예측하는 것
mAP에 대해서 먼저 말씀드리겠습니다. mAP의 경우 pr curve를 그린 뒤 threshold에 따라서 ap를 계산하여 평균낸 값입니다. 여기서 박스를 많이 그릴수록 점수가 오르는 것은 무작정 box가 많다고 점수가 향상되는 것이 아닙니다. box가 무작정 많다면 잘못된 box로 인해서 점수가 깍일 가능성이 높습니다. 그렇기 때문에 ensemble을 이용해서 예측한 모델들을 기준으로 가장 정확하다고 판단되는 box를 추출하는 것입니다.
여기서 잘못된 박스란 예를 들어 1 클래스로 예측을 했는데 해당 지역에 iou < 50 인 1 클래스 객체가 없다는 것을 의미합니다.
그렇다면 이렇게 앙상블을 통해서 과연 성능이 오르는 지는 관련 논문과 강의를 참고하시면 좋을 것 같습니다.
https://arxiv.org/pdf/1910.13302.pdf
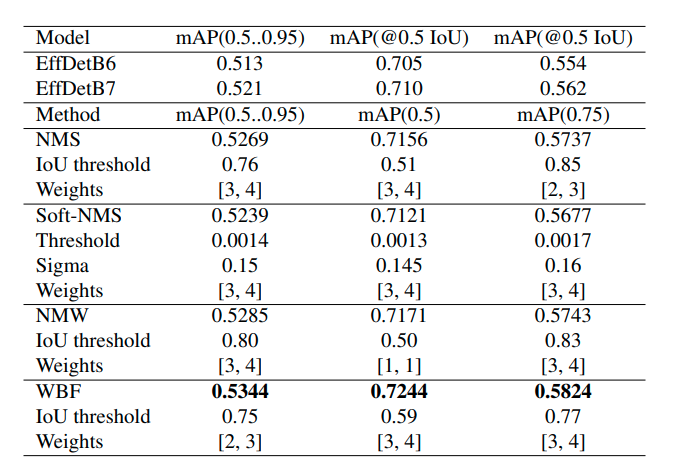
해당 사진은 논문에 첨부된 결과표입니다.
추가적으로 드리고 싶은 말씀은 대회 결과도 중요하겠지만 그에 대해서 잘되냐 안되냐 판단만 하는것보다는 '이게 왜 잘되지?'에 대해서 학습하는 것도 중요할 것 같습니다. 또한 대회 일정이 빠듯하다면 timeline을 세워 캠퍼님이 말씀하신 것처럼 앙상블 과정을 생략하거나 다른 모델 실험을 마무리 하지 못하더라도 앙상블이 중요하다고 생각한다면 timeline에 포함하는 것이 좋을 것 같습니다.
6. Private Leaderboard
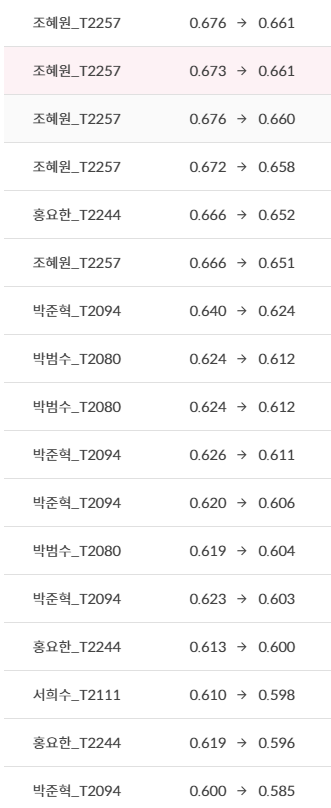
앙상블한게 덜 떨어진 느낌?
대략 0.015 정도 떨어졌고, 다른 팀도 비슷했음
7. 개선할 점
- 기존 대회나 다른 report 보고 방법을 제대로 세우기
- test는 datasheet 1장에 정리하기
- data cleaning 먼저 하기
- Validation set 세워서 model별 효과를 판단할 수 있는 기준을 세우기
- git에서 각 팀원별로 branch 파서 버전관리
-> 성능 좋은 것들만 baseline에 merge
8. Reference & Error
1. MMDetection 사용법
Customized dataset 사용을 위한 config 파일 수정
2. RuntimeError: nms is not compiled with GPU support
https://github.com/open-mmlab/mmdetection/issues/4075
https://github.com/open-mmlab/mmdetection/issues/2686
The first time I installed Pytorch with the wrong version of CUDA, and I got the same error.
But after deleting the "/ build" folder and repeating installation, everything now works.
3. Wandb 연결
TUTORIAL 5: CUSTOMIZE RUNTIME SETTINGS
SOURCE CODE FOR MMCV.RUNNER.HOOKS.LOGGER.WANDB
log_config에서 WandbLoggerHook를 추가해 사용 가능
4. Duplicate key is not allowed among bases
config 중에서 동일 key에 대해 중복으로 선언해서 생기는 문제 --> config 뜯어보고 수정할것
5. Mixup
class Mixup(BufferTransform):
def __init__(self, min_buffer_size=2, p=0.5, pad_val=0):
assert min_buffer_size >= 2, "Buffer size for mosaic should be at least 2!"
super(Mixup, self).__init__(min_buffer_size=min_buffer_size, p=p)
self.pad_val = pad_val
def apply(self, results):
# take four images
a = self.buffer.pop()
b = self.buffer.pop()
# get min shape
max_h = max(a["img"].shape[0], b["img"].shape[0])
max_w = max(a["img"].shape[1], b["img"].shape[1])
# cropping pipe
padder = Pad(size=(max_h, max_w), pad_val=self.pad_val)
# crop
a, b = padder(a), padder(b)
# check if cropping returns None => see above in the definition of RandomCrop
if not a or not b:
return results
# collect all the data into result
results["img"] = ((a["img"].astype(np.float32) + b["img"].astype(np.float32)) / 2).astype(a["img"].dtype)
results["img_shape"] = (max_h, max_w)
for key in ["gt_labels", "gt_bboxes", "gt_labels_ignore", "gt_bboxes_ignore"]:
if key in results:
results[key] = np.concatenate([a[key], b[key]], axis=0)
return resultsmmdet/datasets/pipeline에서 transforms.py, init.py에 추가
6. sub_iter.strides(0)[0] == 0 internal assert failed
https://github.com/pytorch/pytorch/issues/37583
Multiplication of sparse with dense tensor on GPU breaks
Q) RuntimeError: sub_iter.strides(0)[0] == 0 INTERNAL ASSERT FAILED at "/opt/conda/conda-bld/pytorch_1603729062494/work/aten/src/ATen/native/cuda/Reduce.cuh":928, please report a bug to PyTorch.
A) This error message occurs for me with pytorch 1.7.0 when calling sum on a large tensor on GPU. The tensor is of shape torch.Size([8, 1, 128, 1024, 1024]) and the call was x.sum(dim=1).
--> batch_size가 너무 커서 CUDA에 보낼 때 터져서 생기는 문제
batch_size를 줄여서 해결 가능
