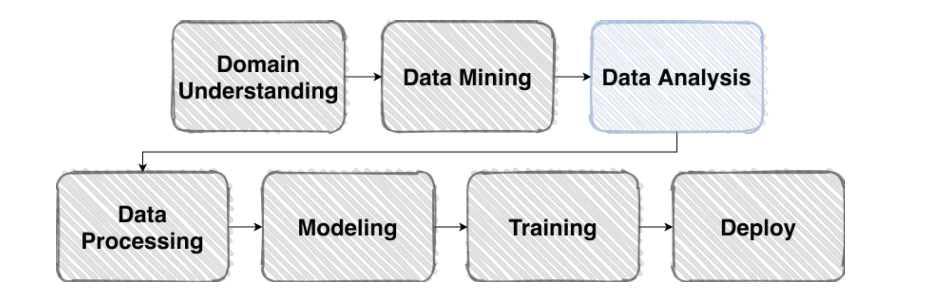
1. Competition이란?

- 주어진 데이터로 원하는 결과를 만들기 위한 가장 좋은 방법을 찾기 위해 경쟁
Competition details
Overview
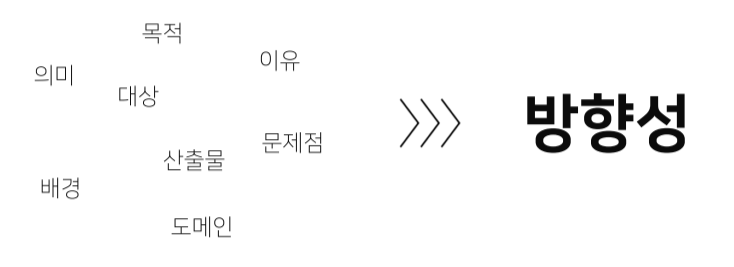
- 문제 발생과 해결방안 인식, 데이터를 갖고 그 문제를 해결할 수 있을지를 먼저 파악
- 개요를 잘 읽어보자!
- Problem Definition
- 내가 풀어야 할 문제가 무엇인가?
- 이 문제의 input/output은 무엇인가?
- 이 솔루션은 어디서 어떻게 사용되는가?
Data dsecription

- File 형태, Metadata field 소개 및 설명
--> 데이터 스펙 요약본
Notebook
- 플랫폼 따라 제공을 안하기도
Submission
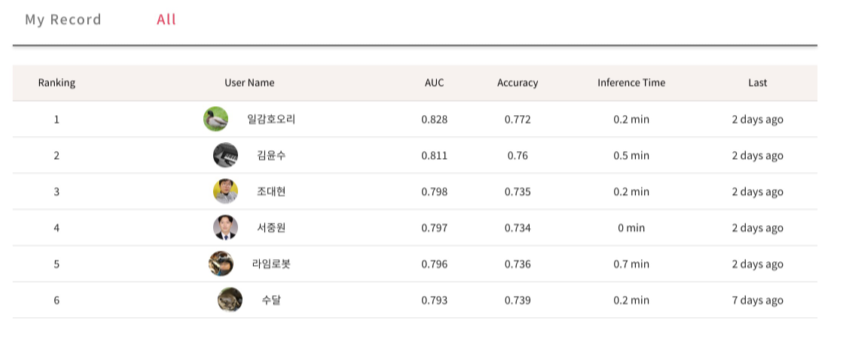
- 순위 확인
Discussion
- 점수를 올리는 것보다 문제를 해결하고 싶은 마음!
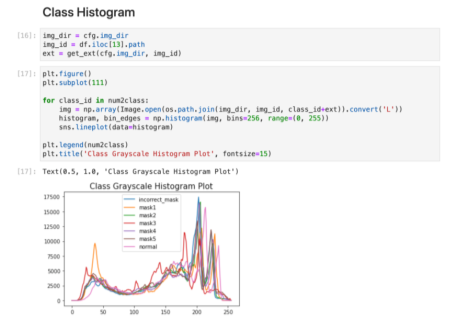
2. EDA, Exploratory Data Analysis
- 데이터를 이해하기 위한 노력

- 데이터를 보면서 들었던 궁금증을 정리하는 것부터 시작
- 코드의 의미를 이해해야 활용할 수 있음
Image Classification
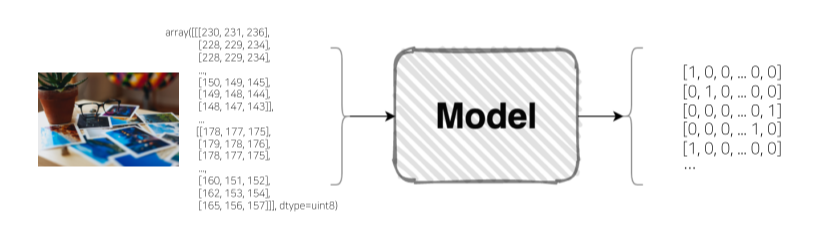
- 이미지 + 모델 = categorical class
3. Dataset
Pre-processing

- 가장 힘들고 시간이 많이 걸리는 작업
- image는 noise보다는 크기, bounding box 등의 이슈가 있음
Bounding box

- bbox info로 원하는 부분의 이미지만 이용할 수 있음
Resize
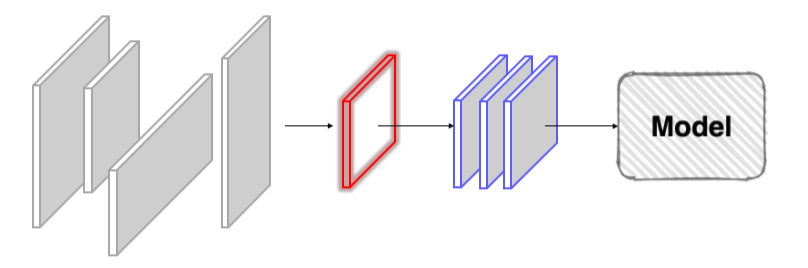
- train하기 적당한 크기로 resize
- 성능엔 크게 영향을 안 주면서 train 속도를 높임
Generalization
Bias & Variance
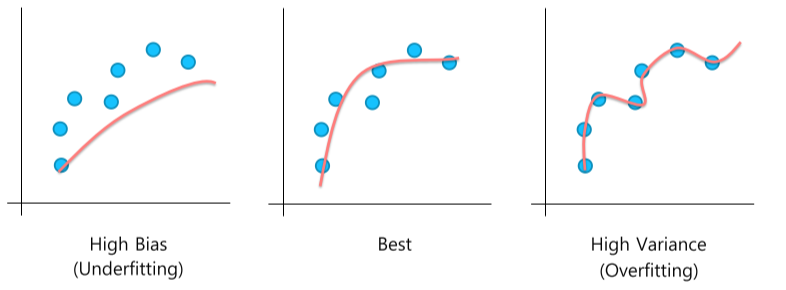
- 학습이 너무 안 됐거나, 너무 잘 됐거나
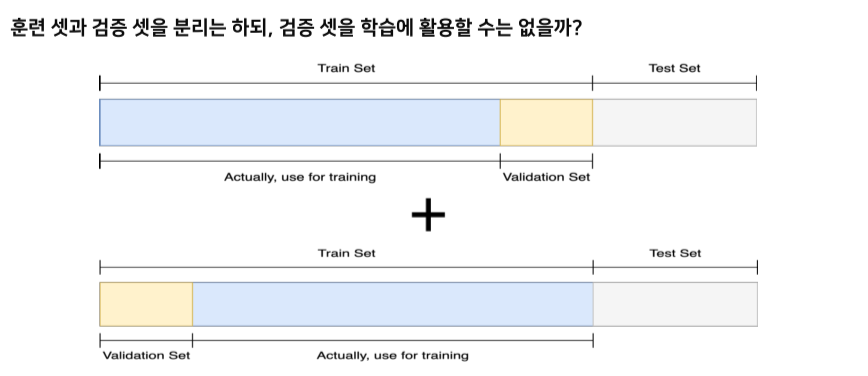
Train / Validation
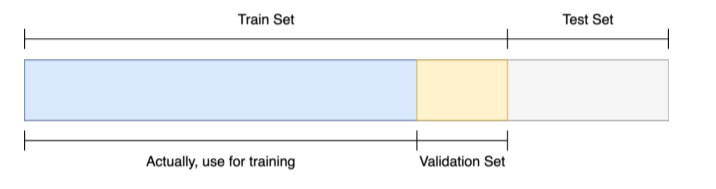
- 학습이 제대로 됐는지 검증
--> 학습에 쓰이지 않은 data로 검증해야함 == validation set
Data Augmentation
- 무조건 적용 가능한 마스터키는 없다!
- Problem(주제)을 잘 관찰하고 그에 맞는 기법들을 적용해보며 실험으로 증명해야함

- 주어진 데이터가 가질 수 있는 case(경우), state(상태)의 다양성
- 문제가 만들어진 배경과 모델의 쓰임새를 살펴보면 힌트를 얻을 수 있다

torch.transforms를 이용

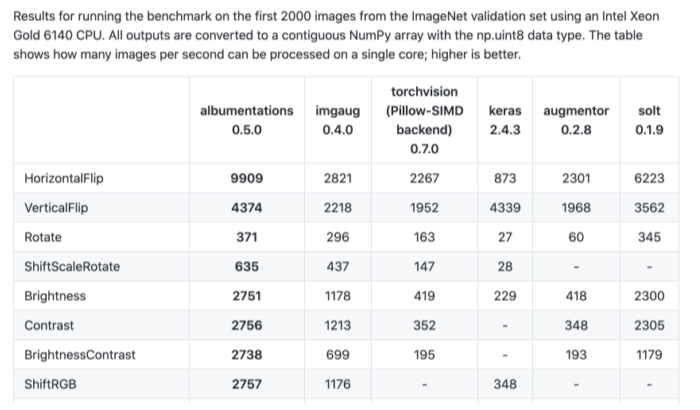
albumentations: 더 빠르고, 더 다양한 tool
4. Data Generation
Data Feeding
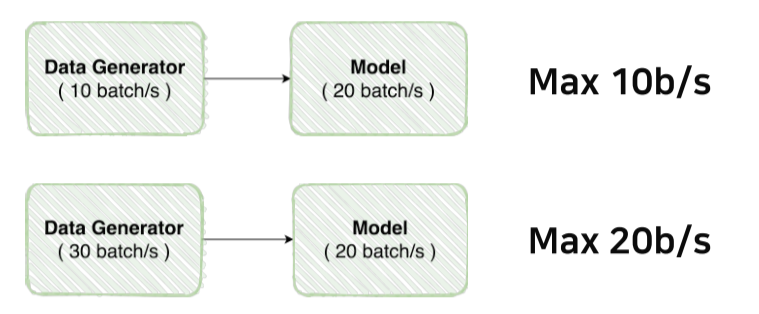
- Model이 처리할 수 있는 양을 넘어서면 효율이 떨어짐
- Generator와 model의 성능을 체크한 후 스펙에 맞춰 최적화 해줘야함
torch.utils.data
Dataset의 구조

- Vanilla data를 dataset으로 변환
DataLoader
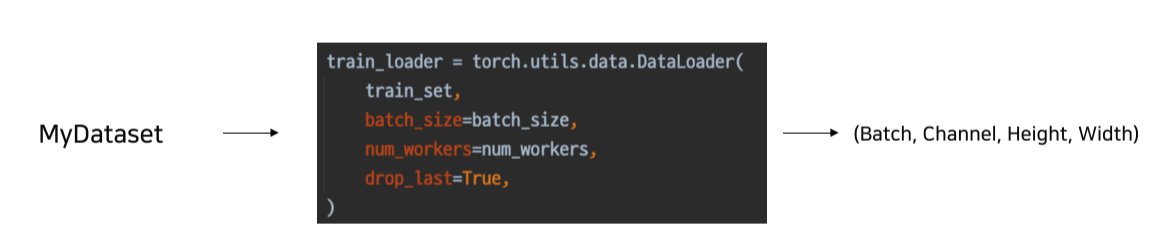
- 내가 만든 dataset을 효율적으로 사용할 수 있도록 하는 기능 추가
- batch_size, num_workers(thread 갯수) 등등
5. Model
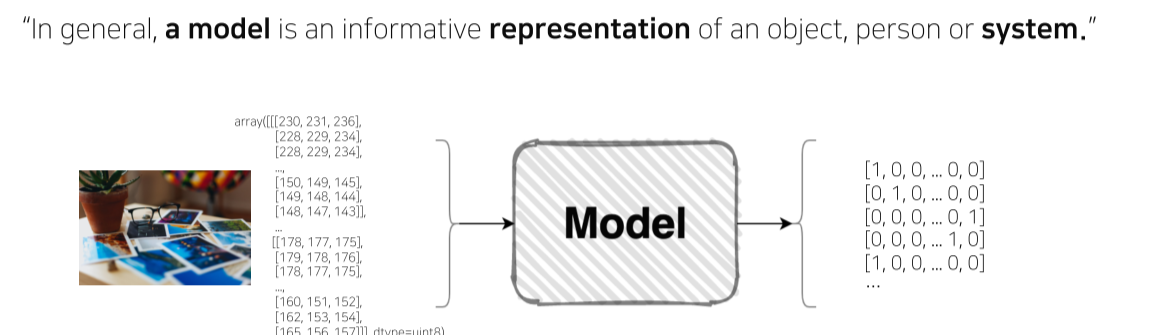
- Model: 시스템을 표현하는 방식
PyTorch

- Low-level, Pythonic, Flexibility 때문에 입문, 교육에 적합
nn.Module

- PyTorch model의 모든 layer는 nn.Module 클래스를 따른다

- 모델(혹은 모듈)이 호출될 때 forward가 실행됨
- 모든 nn.Module은 forward()를 갖고, 각각 module은 상속되기 때문에 내가 정의한 모델의 forward()만 실행시켜도 각각 모델(혹은 모듈)의 forward()가 실행됨
Parameters
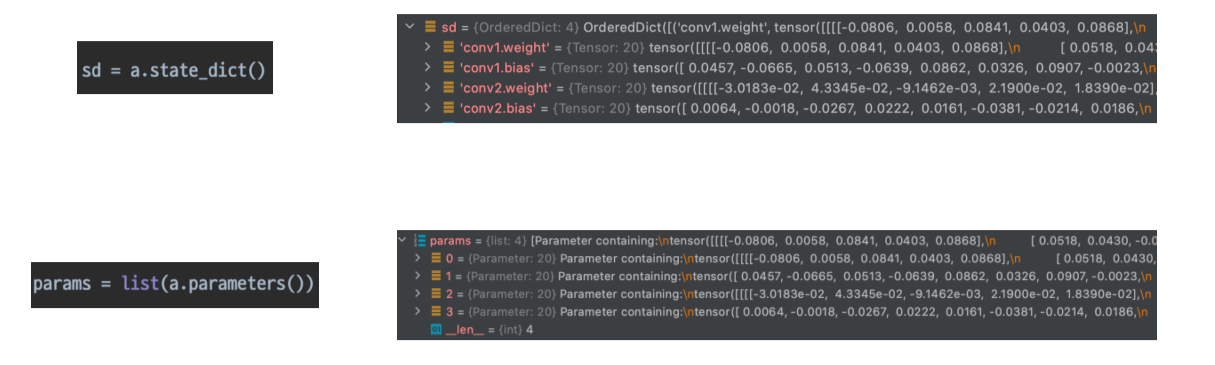
- 모델에 정의된 modules가 갖고있는 계산에 쓰일 parameters
- 각 parameter들은 data, grad, requires_grad 변수 등을 갖고있다
- dict라서 원하는대로 parsing해서 사용 가능
6. Pretrained Model
ImageNet

- 획기적인 알고리즘 개발과, 검증을 위해서는 높은 품질의 데이터셋이 필수적
Pretrained Model의 배경
- 미리 학습된 좋은 성능이 검증된 모델을 이용해 시간을 효율적으로 사용
Transfer Learning
CNN base model 구조

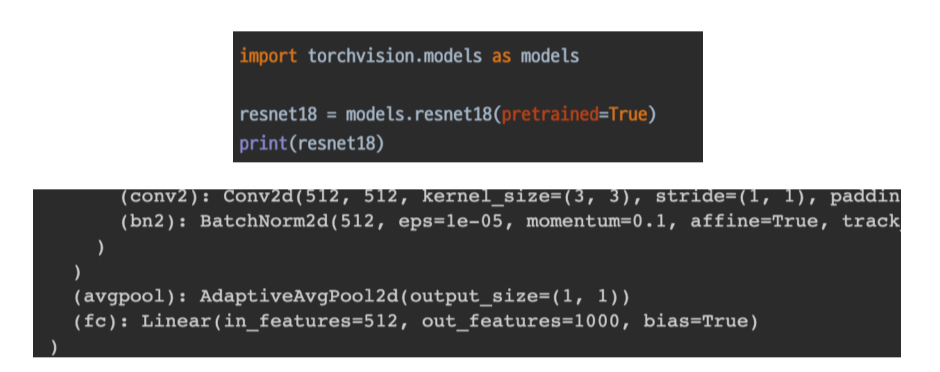
- Backbone: ResNet 등등
- classifier == fully connected layer == fc
내 데이터 모델과의 유사성
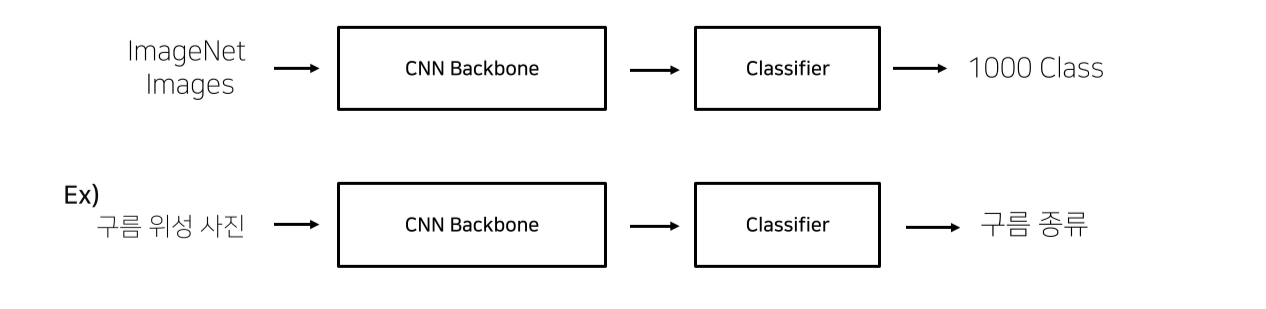
- Pretraining할 때 설정했던 문제와 현재 문제와의 유사성을 고려해야됨
Case1. 학습데이터가 충분할 경우
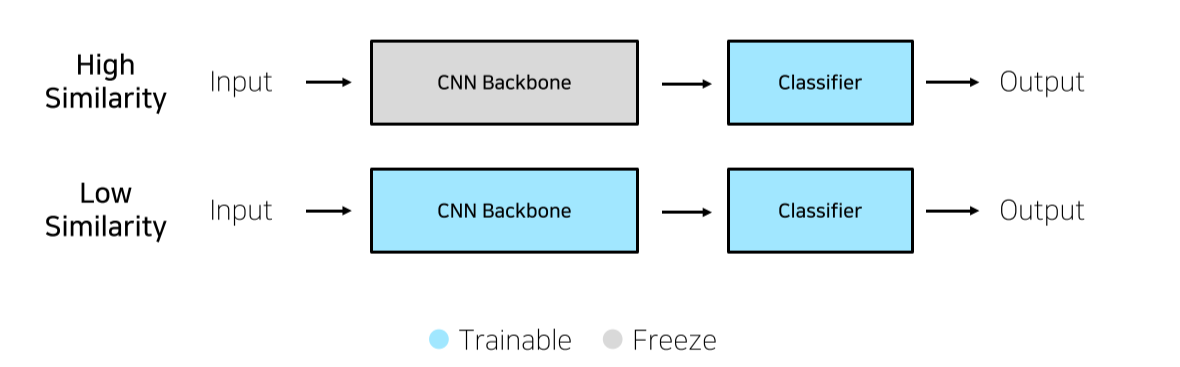
- Pretrain data와 문제의 train data간의 유사성에 따라 train할 parameter를 결정
- Feature Extracion: Classifier만 train하는 방식
- Fine Tuning: Backbone까지 train
Case2. 학습데이터가 충분하지 않은 경우
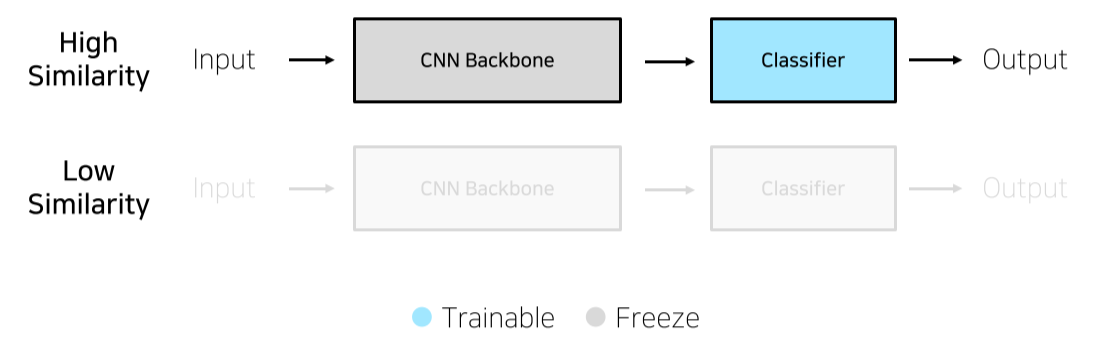
- Pretrain - Train data 간의 유사성이 있을 경우에만 효과가 있음
7. Training
Loss
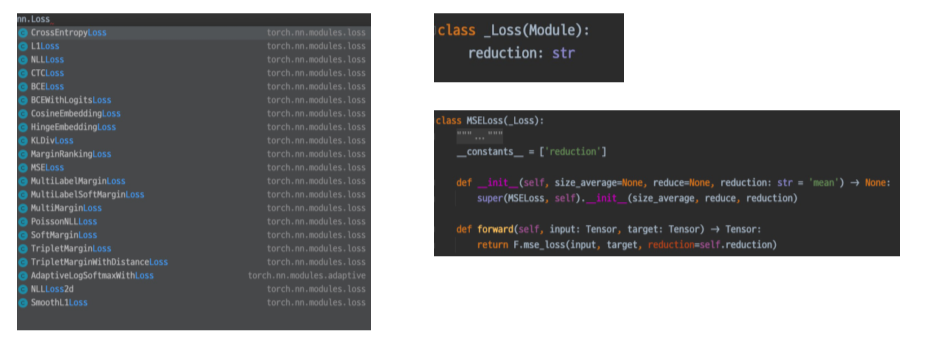
- Loss도 사실 nn.Module의 일부
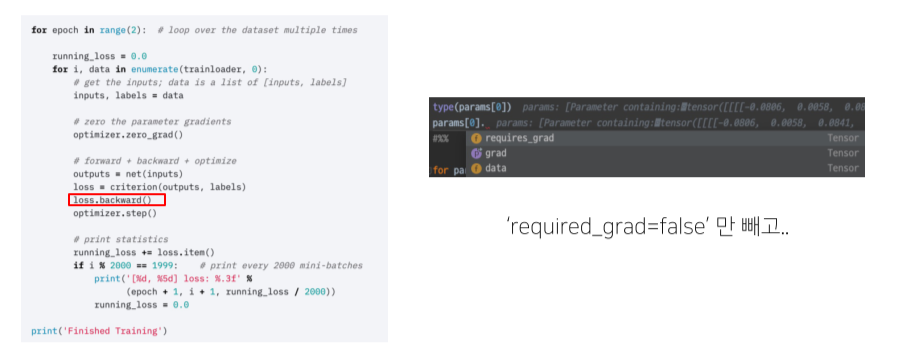
- loss.backward()로 gradient update
val/test할 때: 근데required_grad=false면 실행 x

- loss 만드는 variation
Optimizer

- 어느 방향으로, 얼마나 움직일지
LR scheduler
lr 조정하는 방법
Step LR
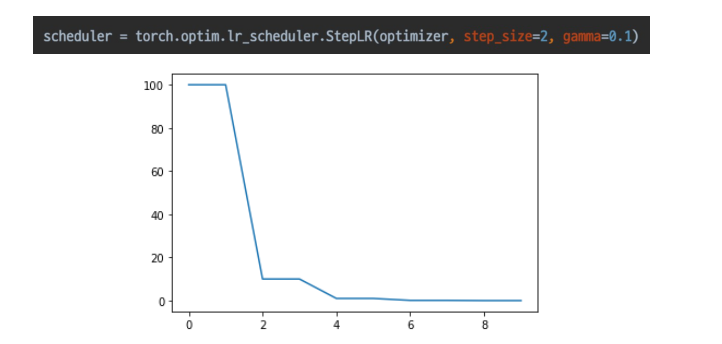
- 스텝마다 줄어듬
CosineAnnelaingLR
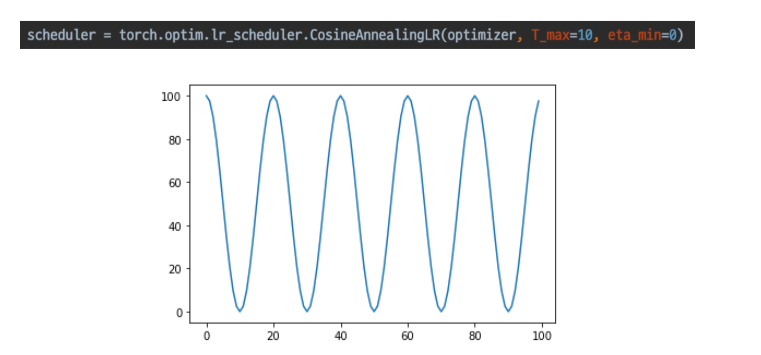
- cos처럼 급격히 변경
- local min을 빠르게 탈출할 수 있음
ReduceLROnPlateau
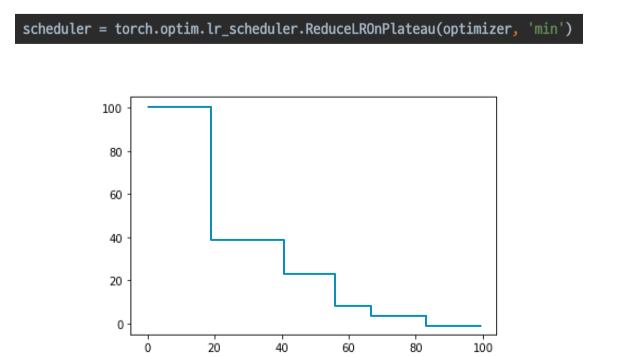
- 성능 향상 없을때 LR 감소
Metric
모델의 평가요소

- 학습에 직접 사용되는 것은 아니지만 학습된 모델을 객관적으로 평가할 수 있는 지표가 필요
- 랭킹: 추천시스템 등에서 사용. 선호도가 높은 아이템이 상단에 노출되는 등

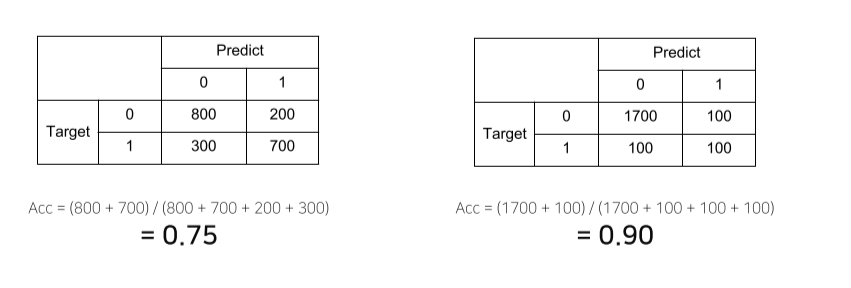
- 데이터 상태에 따른 적절한 metric 선택하는 것이 필요
Training Process
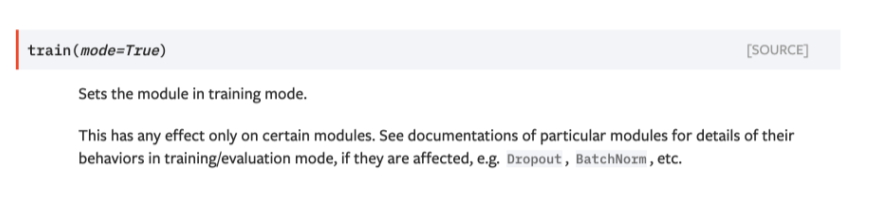
train할 땐 model.train()
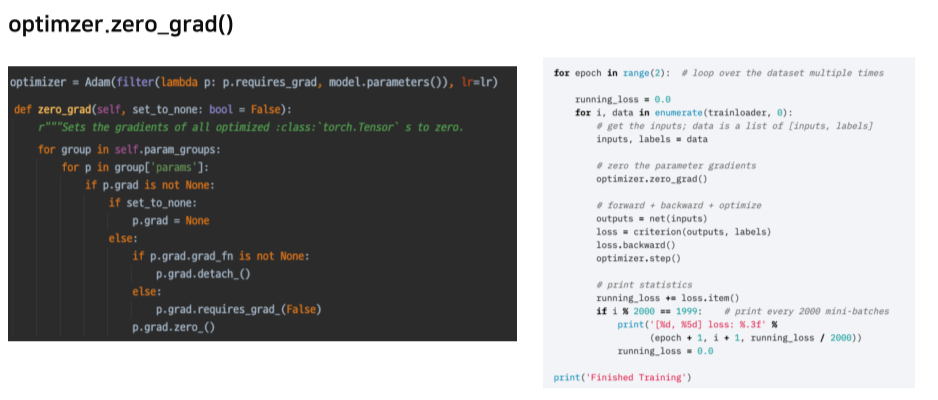
optimizer = loss가 backward할 때 학습하는 기준
이전 batch의 gradient에 대한 정보는 필요 없으니까 초기화

estimated value와 ground truth 간의 비교
nn.Module을 상속하기 때문에 chain을 만들 수 있다

chain 형식이라 backward() 한번으로 연결된 모든 param update 가능
gradient accumulation
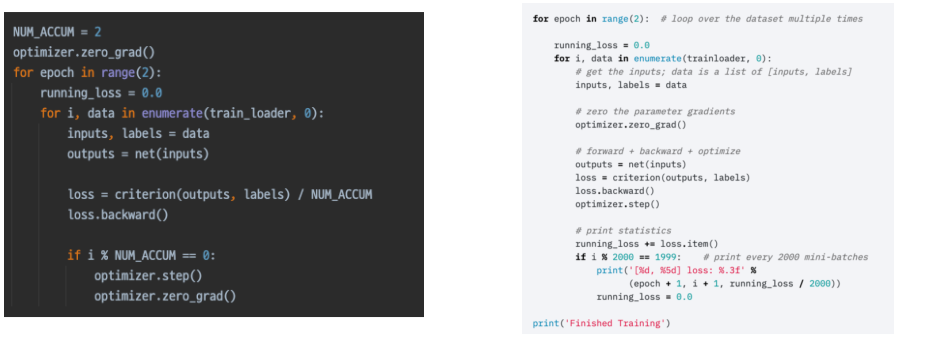
작은 batch에서 정보를 충분히 담지 못할 때 사용
mini batch를 모아서 큰 batch의 역할을 하게 만들어줌
8. Inference
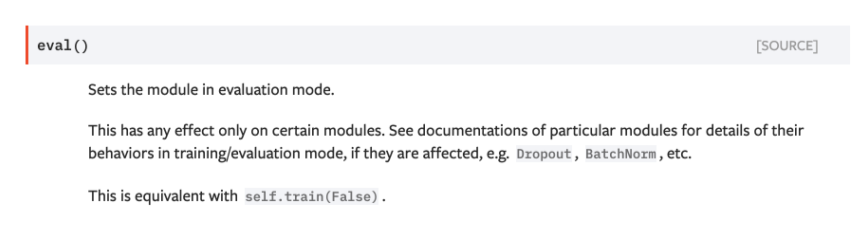
eval할 땐 model.eval()
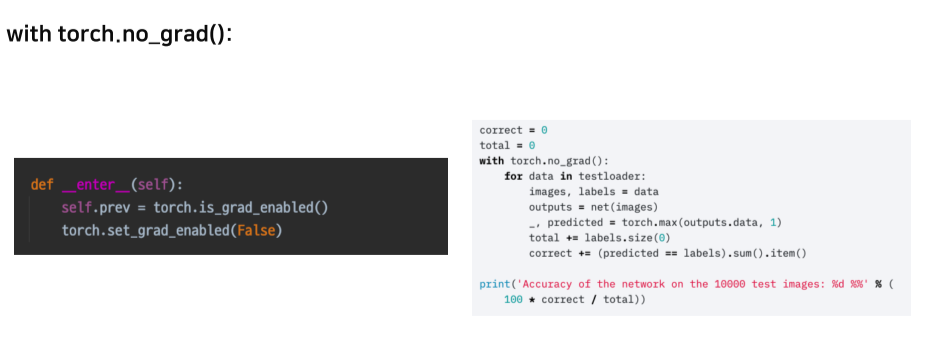
gradient 업데이트 꺼줌

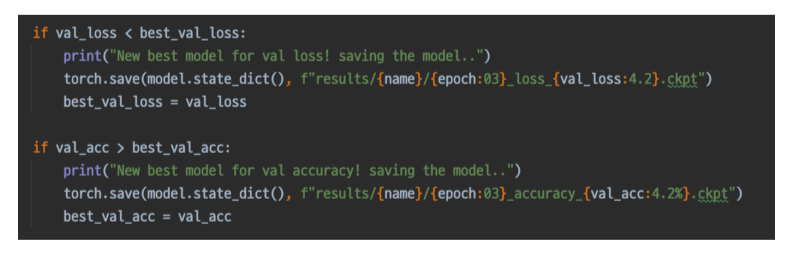
좋은 결과를 저장
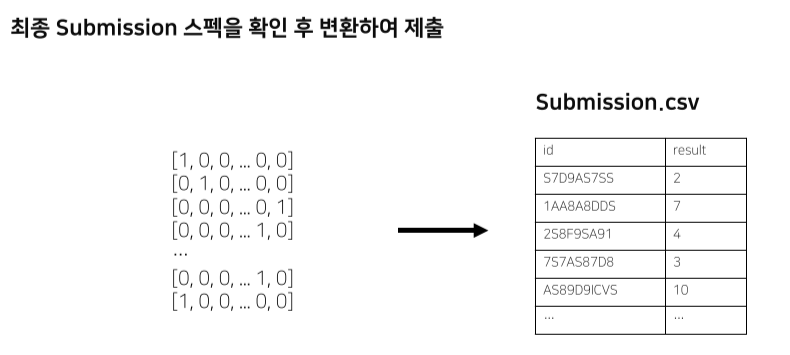
최종 결과를 csv로 변환해서 제출
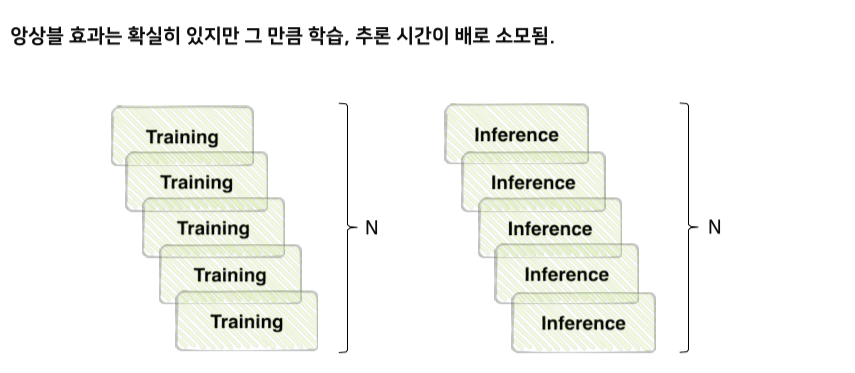
9. Ensemble
model averaging

현업에서 잘 쓰지는 않음
모델 여러개 쓰면 시간이 오래 걸리기 때문에.. 하지만 성능 중요한 domain에서는 사용하기도
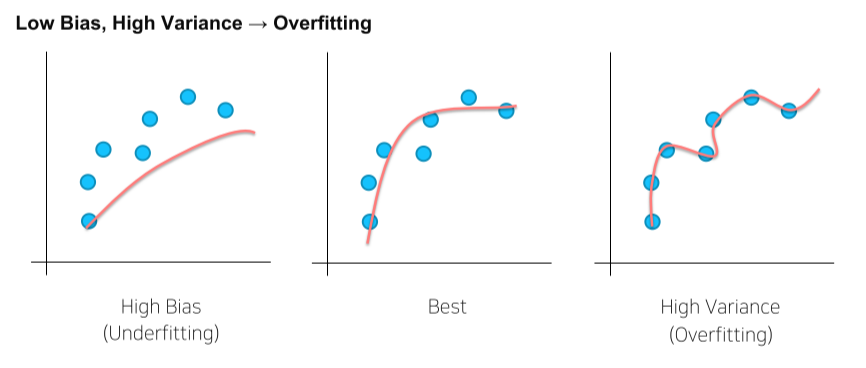
high bias에서는 (gradient) boosting을,
high variance에서는 bagging을 주로 사용
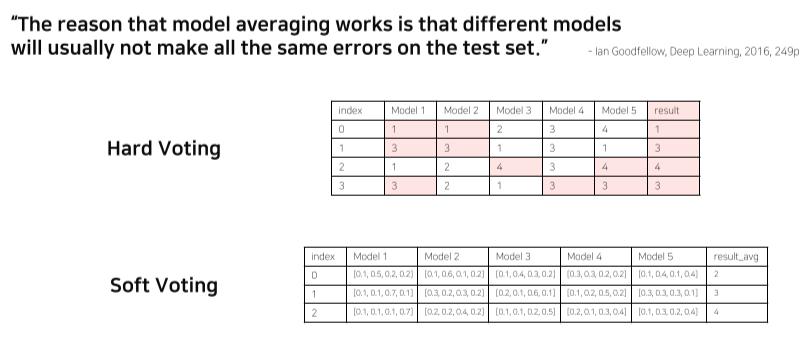
서로 다른 모델이 각자 다른 경향을 나타낸다는게 base
voting 방식에 따라서도 결과가 달라짐
cross validation
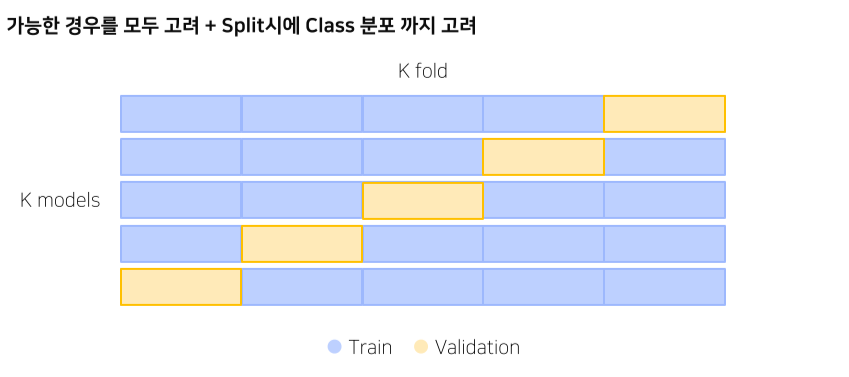
stratified k-fold CV
class 분포까지 고려한다는 것이 특징
random하게 뽑으면 어떤 class엔 overfit, 어떤 class는 학습하지 못할 수도
tta, test time augmentation
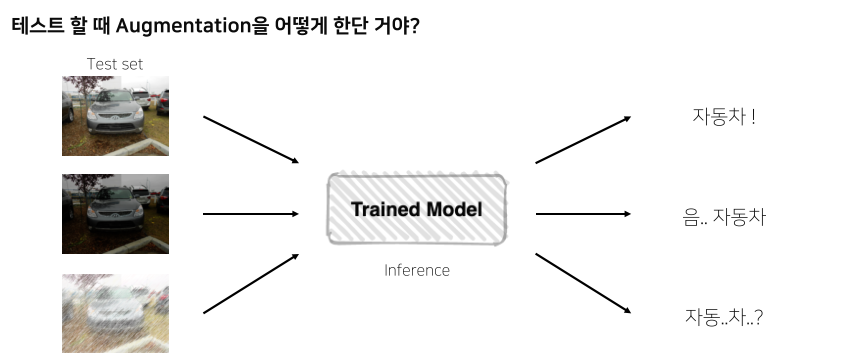
noise가 섞여도 잘 infer할 수 있는지?
--> 더 일반화할 수 있음
1개 img에 5개 aug --> 6개 결과를 앙상블
trade-off
10. Hyperparameter optimization

매 param마다 train해야돼서 시간과 장비가 많이 필요

tuning해주는 library
11. Experiment Toolkits & Tips
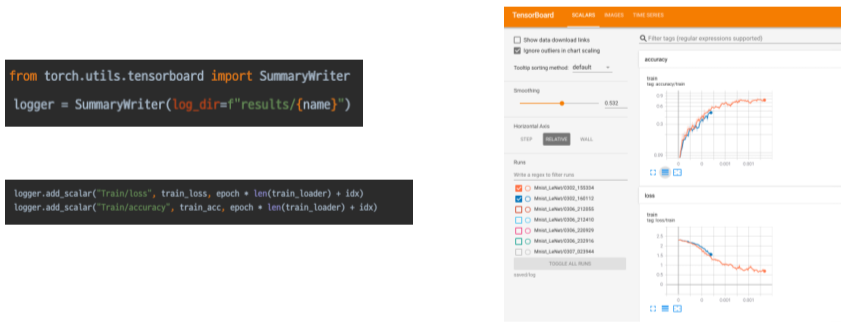
Training Visualization
Tensorboard

Wandb
init, log를 이용
페이지에서 로그 확인 가능
Machine Learning Project
Jupyter
Cell 단위 실행 가능
EDA 확인할 때 매우 편리
학습 도중 노트북 창이 꺼지면 못 돌아감
Python IDLE
구현은 1번만, 사용은 언제나, 간편한 코드 재사용
디버깅 가능
자유로운 시험 핸들링
