0. 서론
이미지 분류 과제를 진행하며 배운 점이나 새로 적용해본 걸 정리
구현 위주로 정리함
1. 서버 연결
VS Code에서 SSH로 서버 연결하는 방법
AI stage에서 할당받은 서버를 SSH 원격접속을 통해 연결
연결 후엔 Open Folder로 접근 가능
2. EDA
EDA(Exploratory Data Analysis, 탐색적 데이터 분석)는 벨연구소의 수학자 ‘존 튜키’가 개발한 데이터분석 과정에 대한 개념으로, 데이터를 분석하고 결과를 내는 과정에 있어서 지속적으로 해당 데이터에 대한 ‘탐색과 이해’를 기본으로 가져야 한다는 것을 의미
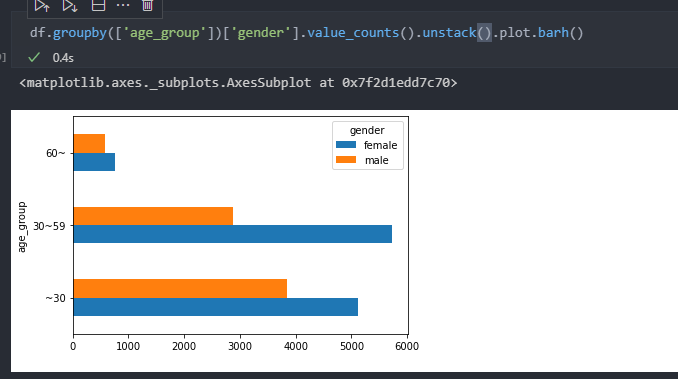
- EDA sample:
groupby.plot()
Pandas에서 제공하는 method로 matplotlib를 사용하지 않고도 그래프를 plot할 수 있음
kind로 그래프의 형태를 변경하거나 label, figsize를 정하는 등 다양한 설정 변경 가능
- 참고:
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.plot.html
https://stackoverflow.com/questions/48238305/bar-plot-with-groupby


Input image size 판별
Image를 열어 size를 출력하는 함수 f를 apply로 각 data에 적용
f = lambda x: Image.open(str(x)).size
df['image_size'] = os.join(train_dir, df['path'])
df["image_size"] = df["image_size"].apply(f)3. Dataset
map-style dataset은 torch.utils.data에서 Dataset class를 상속해서 __init__, __len__, __getitem__ 메서드로 구성된다
__init__: 데이터의 위치나 파일명과 같은 초기화 작업을 위해 동작
csv, xml 파일과 같은 데이터를 불러오고, 이미지를 처리할 transform을 정의__len__: Dataset의 최대 요소 수를 반환하는데 사용__getitem__: 데이터셋의 idx번째 데이터를 반환하는데 사용
일반적으로 원본 데이터를 가져와서 전처리하고 데이터 증강하는 부분이 모두 여기에서 진행
보통은 train/test에서 쓸 train, label을 return
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self,):
pass
def __len__(self):
pass
def __getitem__(self, idx):
pass파일 확장자 통일
.jpg, .png 등이 섞여있어 모두 .jpg로 파일을 통합했다
하지만 os.listdir을 사용해 확장자에 상관없이 이미지를 불러오는 방법이 더 좋았을듯
root_dir = '/opt/ml/input/data/train/images'
not_jpg_file = []
for (root, dirs, files) in os.walk(root_dir):
if len(files) > 0:
for file_name in files:
t = file_name.split('.')[-1] # t = 확장자
if len(t) > 4:
continue
if t != 'jpg' and file_name[0] != '.':
not_jpg_file.append(f'{root}/{file_name}')
for imagedir in not_jpg_file:
im = Image.open(imagedir)
im.save(imagedir.split('.')[0] + '.jpg')os.walk: 하위 폴더들을 for문으로 탐색할 수 있게 해줌root: dir과 file이 있는 pathdirs: root 아래에 있는 폴더들files: root 아래에 있는 파일들
특정 directory의 파일 찾기
glob과 os.path.join을 이용해 원하는 directory의 파일을 list 형태로 얻을 수 있음
-
glob: 유닉스 셸이 사용하는 규칙에 따라 지정된 패턴과 일치하는 모든 경로명을 찾는다
https://docs.python.org/ko/3.6/library/glob.html -
os.path.join: 인수에 전달된 문자열을 결합하여, 1개의 경로로 할 수 있다
https://engineer-mole.tistory.com/188
from glob import glob
import os
>>> glob('*.exe') # 현재 디렉터리의 .exe 파일
['python.exe', 'pythonw.exe']
>>> glob('*.txt') # 현재 디렉터리의 .txt 파일
['LICENSE.txt', 'NEWS.txt']
>>> glob(path) # path 디렉터리의 모든 파일
print("join(): " + os.path.join("/A/B/C", "file.py"))
# join(): /A/B/C/file.py
img_dir = '/opt/ml/input/data/train/images'
img_id = '0010'
os.path.join('img_dir', 'img_id', '*')
# /opt/ml/input/data/train/images/0010/*
glob(os.path.join('img_dir', 'img_id', '*'))
# img_id 하위의 모든 파일들을 불러옴진행률 표시
tqdm으로 Iterable을 감싸서 진행률을 표시할 수 있음
for i in tqdm(range(1, 60)):
print(i)
- 53% : 진행률
- 100/189 : 189개의 작업중 100개 진행
- 01:01< 00:54 : 진행시간 1분 1초, 남은 시간 54초
- 1.63it/s : 1초에 1.63번의 itertaion 수행
- tqdm 파라미터 설명
- iterable : 반복자 객체
- desc : 진행바 앞에 텍스트 출력
- total : int, 전체 반복량
- leave : bool, default로 True. (진행상태 잔상이 남음)
- ncols : 진행바 컬럼길이. width 값으로 pixel 단위로 보임.
- mininterval, maxinterval : 업데이트 주기. 기본은 mininterval=0.1 sec, maxinterval=10 sec
- miniters : Minimum progress display update interval, in iterations.
- ascii : True로 하면 '#'문자로 진행바가 표시됨.
- initial : 진행 시작값. 기본은 0
- bar_format : str
전체 작업량을 알고 있고, 처리된 량으로 진행바를 표시할 경우에, update()로 진행량 추가
- 메소드
- clear() : 삭제
- refresh() : 강제 갱신
참고: https://skillmemory.tistory.com/17
수치 데이터를 범주 데이터로
pd.cut을 이용해 수치 데이터를 범주 데이터로 바꿔줌
bins로 범위 설정, labels로 범위당 라벨 설정

참고: https://blog.naver.com/youji4ever/221671830297
albumentation
기존의 torchvision.transforms 이외에도 이미지를 augment해주는 라이브러리
pip install albumentaion으로 사용
https://albumentations-demo.herokuapp.com/ 에서 적용해본 결과를 미리 볼 수 있다
train/test dataset 나누기
torch.utils.data.random_split으로 dataset을 나눌 수 있음
sklearn.model_selection.train_test_split으로도 사용 가능
# Dataset 만들기
dataset = myDataset(root_dir=train_dir)
# train dataset과 validation dataset을 8:2 비율로 나눕니다.
n_val = int(len(dataset) / 5)
n_train = len(dataset) - n_val
train_dataset, val_dataset = data.random_split(dataset, [n_train, n_val])4. Dataloader
모델 학습을 위해서 데이터를 미니 배치(Mini batch)단위로 제공해주는 역할
DataLoader(dataset, # Dataset 인스턴스가 들어감
batch_size=1, # 배치 사이즈를 설정
shuffle=False, # 데이터를 섞어서 사용하겠는지를 설정
sampler=None, # sampler는 index를 컨트롤
batch_sampler=None, # 위와 비슷하므로 생략
num_workers=0, # 데이터를 불러올때 사용하는 서브 프로세스 개수
collate_fn=None, # map-style 데이터셋에서 sample list를 batch 단위로 바꾸기 위해 필요한 기능
pin_memory=False, # Tensor를 CUDA 고정 메모리에 할당
drop_last=False, # 마지막 batch를 사용 여부
timeout=0, # data를 불러오는데 제한시간
worker_init_fn=None # 어떤 worker를 불러올 것인가를 리스트로 전달
)
dataloader_custom = DataLoader(dataset_custom)K-fold
train/val 나누는 법 --> 아직 맞게 한건지 모르겠음! 마무리 필요!!
5. Model
Custom model 정의
timm을 이용해 다양한 custom model을 module로 사용할 수 있음
num_classes로 output class의 갯수를 설정할 수 있어서 편리하다
class MyModel(nn.Module):
def __init__(self, num_classes: int = 1000):
super(MyModel, self).__init__()
self.efficient = timm.create_model(model_name='efficientnet_b4',
num_classes=num_classes,
pretrained=True
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.efficient(x)6. Train
Model, dataset, dataloader를 불러오고 loss, learning rate를 설정해서 train한다
이때 model.train()으로 gradient를 학습할 수 있는 상태로 만들어야됨
Seed 고정
매 train마다 seed가 바뀌면 모델, method간 정확한 성능평가가 어렵기 때문에 seed 고정
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if use multi-GPU
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(seed)
random.seed(seed)Wandb
Tensorboard처럼 학습에 쓰인 설정, 학습 도중의 변수값 등을 확인할 수 있다
Tensorflow나 pytorch 등 여러 flatform에서 사용가능한 것이 특징
import wandb
# wandb 초기화 및 연결
# train하기 전에 init하면 해당 run이 기록됨
wandb.init(project="project_name", entity='my_entitiy')
# config 지정해 각 run의 설정을 확인 가능
config={"epochs": EPOCHS, "batch_size": BATCH_SIZE, "learning_rate" : LEARNING_RATE}
# train 중에 log를 기록 그 순간의 변수를 확인
wandb.log({'accuracy': epoch_acc, 'loss': epoch_loss})예제 참고: https://github.com/wandb/examples
Learning rate scheduler
Learning rate scheduler로 learning rate를 업데이트 가능
학습할 때 optimizer.step() 하고 scheduler.step()하는 방식으로 업데이트
torch.optim.lr_scheduler에서 LambdaLR, MultiplicativeLR, StepLR 등 다양한 scheduler를 지원한다
- Scheduler의 종류와 parameter에 대한 참고:
https://sanghyu.tistory.com/113
https://gaussian37.github.io/dl-pytorch-lr_scheduler/
import torch
import torch.nn as nn
import torch.optim as optim
from data import AudioDataset, AudioDataLoader
from matplotlib import pyplot as plt
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear = nn.Linear(10, 10)
self.activation = nn.ReLU()
def forward(self, x):
return self.activation(self.linear1(x))
# data
tr_dataset = AudioDatset('tr')
data_loader = AudioDataLoader(tr_dataset, batch_size=3, shuffle=1)
# model
model = Model()
# loss
loss = nn.MSELoss()
# optimizer
optimizer = optim.Adam(model.parameters(), lr=1e-3)
#scheduler
scheduler = optim.lr_scheduler.LambdaLR(optimizer=optimizer,
lr_lambda=lambda epoch: 0.95 ** epoch,
last_epoch=-1,
verbose=False)
epochs=100
for epoch in range(epochs):
for i, (data) in enumerate(data_loader):
x_data, y_data = data
optimizer.zero_grad()
estimated_y = model(x_data)
loss = loss(y_data, estimated_y)
loss.backward()
optimizer.step()
scheduler.step() # you can set it like this!Loss
https://github.com/CoinCheung/pytorch-loss 에서 다양한 loss 사용 가능
Gradient accumulation
큰 배치사이즈를 사용하는 이유는 학습시에 정보의 노이즈를 제거하고 더 나은 gradient decsent를 수행할수 있지만, GPU 메모리 제한 때문에 batch_size를 늘리지 못하는 것을 gradient accumulation으로 개선
optimizer.zero_grad() # Reset gradients tensors
for ind, (images, labels) in enumerate(dataloader):
logits = my_model(images) # Forward pass
_, preds = torch.max(logits, 1)
loss = loss_fn(logits, labels) # Compute loss function
loss.backward() # Backward pass
if (ind+1) % accumulate_grad_batches == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
optimizer.zero_grad() # Reset gradients tensorsSlack에 알림 띄우기
Train이 오래 걸리기 때문에 매 epoch마다 slack에 결과를 전송
링크
Early stopping

Epoch을 너무 많이 주면 train dataset에 overfit해서 오히려 validation accuracy, test accuracy 떨어질 수 있음
이를 방지하기 위해 validation error가 감소하다 다시 증가하면 epoch이 끝나지 않더라도 stop하게 해준다
그리고 가장 error가 적을때 model 상태를 torch.save(model.state_dict(), '경로')로 저장
저장한 model_state는 mmodel.load_state_dict(torch.load('경로'))로 불러올 수 있다
best_test_accuracy = 0
for epoch in range(1, EPOCH+1):
running_acc = 0
for ind, (images, labels) in enumerate(dataloader):
optimizer.zero_grad()
logits = my_model(images)
_, preds = torch.max(logits, 1)
loss = loss_fn(logits, labels)
loss.backward()
optimizer.step()
running_acc += torch.sum(preds == labels.data)
# best accuracy 계산
epoch_acc = running_acc / len(dataloader.dataset)
if best_test_accuracy < epoch_acc:
best_test_accuracy = epoch_acc
best_model_state = my_model.state_dict()
early_stop_point = 0
else:
early_stop_point += 1
if early_stop_point == EARLY_STOP:
print('early_stopped')
break
torch.save(best_model_state, './best_weight.pt')7. Inference(evaluate)
with torch.no_grad()로 gradient가 학습하지 않게 만들어 연산을 최소화함
Transform 또한 normalize 같이 값에 직접 영향을 주는 연산 외에는 사용하지 않게 최소화 해야한다
model.eval()로 layer를 inference 모드로 만듬
Metric
모델이 얼마나 잘 작동하는지 통계적으로 확인하는 공식
Scikit-Learn이라는 라이브러리에서 해당 지표를 계산하는 공식 제공중
Accuracy(정확도): 올바르게 예측된 데이터의 수를 전체 데이터의 수로 나눈 값Recall(재현율): 실제로 True인 데이터를 모델이 True라고 인식한 데이터의 수Precision(정밀도): 모델이 True로 예측한 데이터 중 실제로 True인 데이터의 수F1 Score: Precision 과 recall의 조화평균
참고: https://eunsukimme.github.io/ml/2019/10/21/Accuracy-Recall-Precision-F1-score/
from sklearn.metrics import f1_score
...
for epoch in range(1, NUM_EPOCHS+1):
epoch_f1 = 0
n_iter = 0
for images, labels in dataloader:
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
logits = model(images)
_, preds = torch.max(logits, 1)
loss = criterion(logits, labels)
loss.backward()
optimizer.step()
epoch_f1 += f1_score(labels.cpu().numpy(), preds.cpu().numpy(), average='macro')
n_iter += 1
epoch_f1 = epoch_f1/n_iter
print(f"{epoch_f1:.4f}")