0. 서론
구현하면서 생겼던 문제나 캠퍼들과 논의한 이슈, 아이디어 위주로 정리
1. Local minimum?
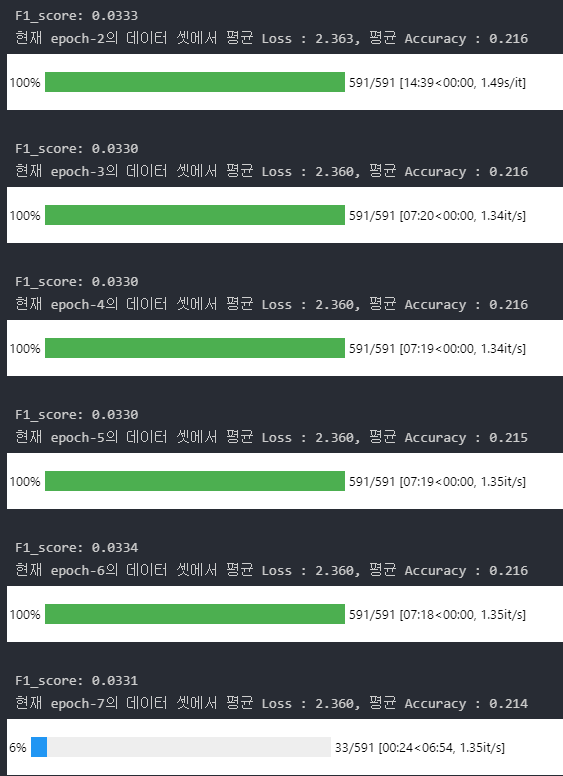
Efficientnet-b4를 사용하니 생긴 문제
--> https://github.com/lukemelas/EfficientNet-PyTorch 에서 가져온 모델
해결: timm 라이브러리 사용
2. Train에서만 성능 나오고 test에선 안 나옴!
Test dataset을 shuffle해버려서 순서가 섞여서 그랬음.. 그러면 Ground Truth와 순서가 달라지기 때문에 아예 검증을 못해버림
3. Data augmentation
Transformer만 하지 말고 원래 data에 추가해서 data의 양을 늘리는 방법?은? 어?떤지?에 대한 논의
-
해당 방식도 많이 사용하나, 데이터 저장 공간이 상당히 많이 필요하게 되는게 단점입니다(좌우 flip / 상하 flip 만 하게 되도 원본 대비 4배의 공간을 차지하니까) Deterministic 하게 augmentation(원본 data에 추가)하기도 하고, 또 코드 상에서 stochastic 하게 augmentation 하기도 한다
-
적절하게 사용된다면 당연히 도움이 되겠지만 augmentation 결과의 데이터의 분포가 너무 기존의 데이터와 유사하면, 오히려 그 적은 set에도 overfit 될 수도 있을 듯 하다
-
모집단의 분포를 예측하기 위해 표본에 대해 augmentation을 수행한 것인데, 표본의 augmentation을 이미지로 생성해서 미리 고정시켜놔버리면, augmentation 결과물 자체에 overfitting이 될수도 (원본 데이터를 그대로 두고 augmentation을 추가하면 특정 경향만 강화하는 역할을 할 수도)
따라서 확률적으로 랜덤하게 표본에 transpose를 가하는 것이 표본을 다양하게 만들어주는듯
근데 속도면에서는 미리 만들어둔게 더 빠르니까 질문자가 말한 방식도 쓴다~의 뉘앙스인듯
4. Labelling?
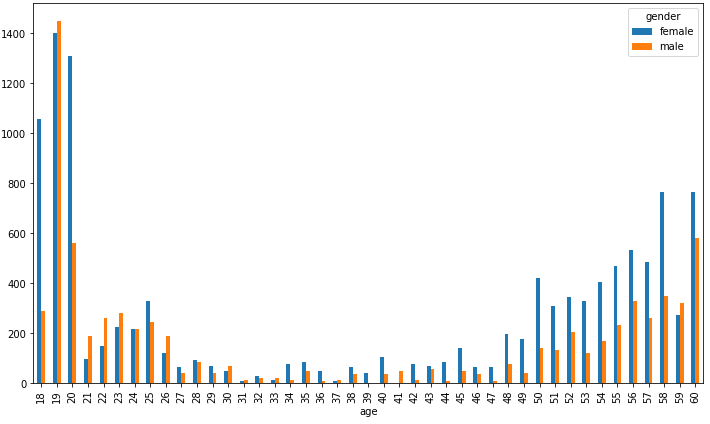
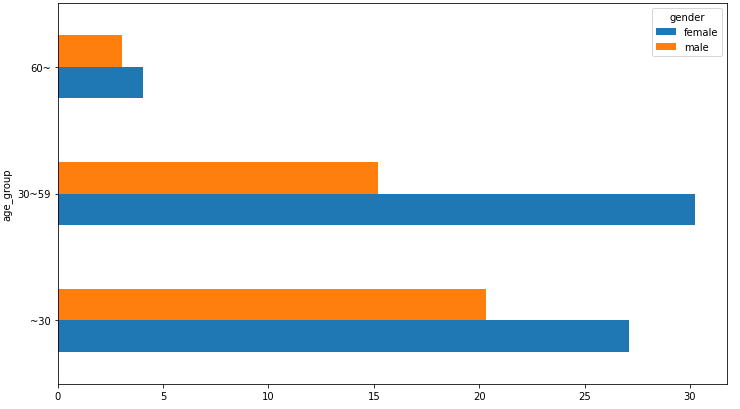
0~29 > 30~59 >> 60 순으로 데이터가 편향돼있기 때문에 정확이 30, 60을 기준이 아니라 29, 59를 기준으로 구간을 나눠서 라벨링함
생각보다 효과가 있다
5. One vs one
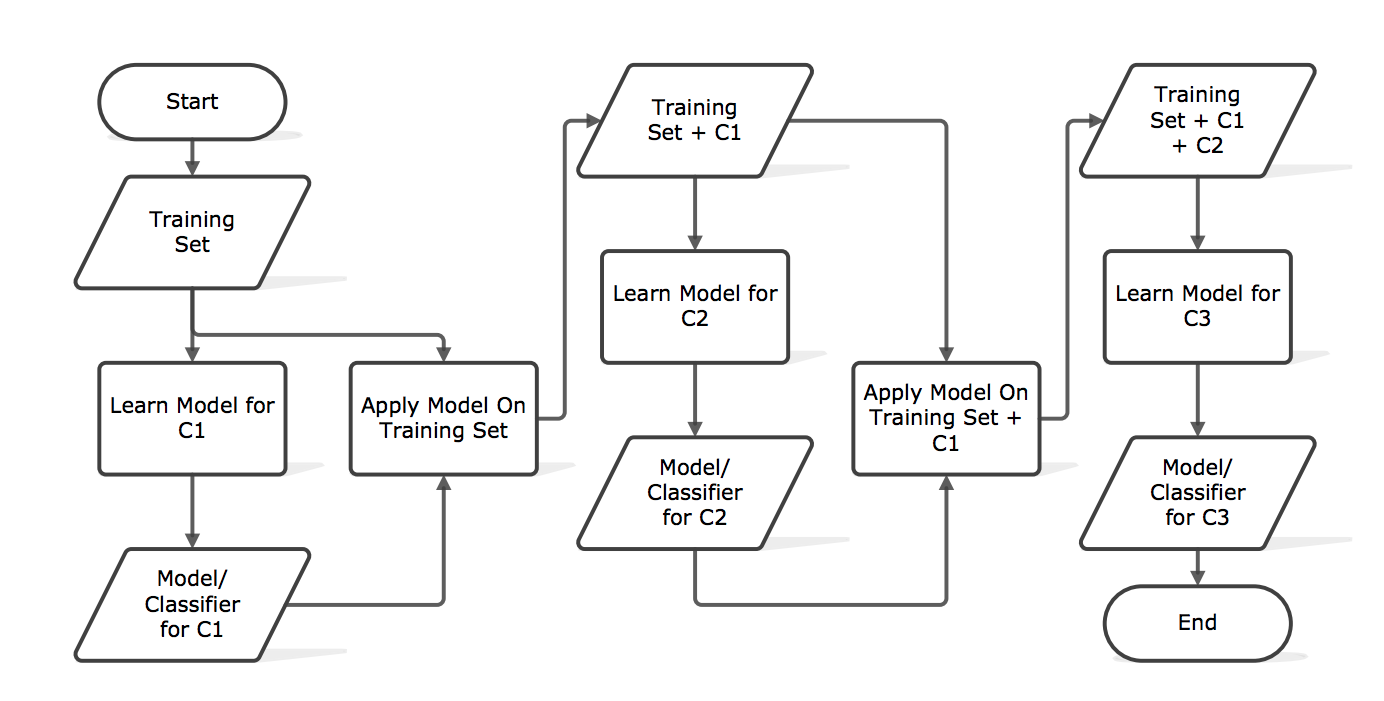
3개의 feature(mask/gender/age)가 있으면 그 중 1개의 feature에 대해서만 학습하는 model을 각각 만들고(총 3개) ensemble함
효과가 좋았다
https://towardsdatascience.com/journey-to-the-center-of-multi-label-classification-384c40229bff
6. Dataset.__getitem__에서 텐서 복사할 때
https://stackoverflow.com/questions/55266154/pytorch-preferred-way-to-copy-a-tensor
torch.tensor(output)를 어떻게 정의할지?
y = tensor.new_tensor(x) #a
y = x.clone().detach() #b
y = torch.empty_like(x).copy_(x) #c
y = torch.tensor(x) #db가 제일 좋은 방법임. it makes explicit the fact that y is no more part of computational graph i.e. doesn't require gradient.
7. Train/valid split 시 사람별로 + 클래스 라벨 균등하게 나누기
이슈: https://github.com/scikit-learn/scikit-learn/issues/9193
https://teddylee777.github.io/scikit-learn/train-test-split
train/valid split할 때 원래 분포와 다르게 나누면 편향될 수 있음
--> profile별로+라벨별로 균등하게 나눠서 원래의 분포를 적용!
http://www.xavierdupre.fr/app/pandas_streaming/helpsphinx/pandas_streaming/df/connex_split.html#pandas_streaming.df.connex_split.train_test_apart_stratify 에서 train_test_apart_stratify를 이용
8. CutMix
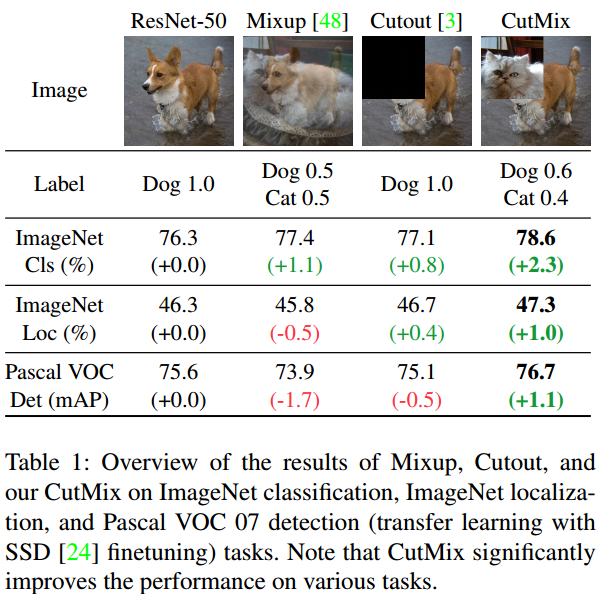
CutMix는 모델이 객체의 차이를 식별할 수 있는 부분에 집중하지 않고, 덜 구별되는 부분 및 이미지의 전체적인 구역을 보고 학습도록 하여 일반화와 localization 성능을 높이는 방법
다른 캠퍼분이 정리해주신 내용
베타분포에서 랜덤하게 얻은 Lam과 패치가 차지하는 비율을 이용하여 Loss 값을 계산
(간단하게 예를 들면 기존 이미지 A와 패치 이미지 B가 있을 경우 Loss를 계산할 때 B 패치의 크기가 40%를 차지한다면 TotalLoss= Loss(OutputA, TargetA) 0.6 + Loss(OutputB, Target_B) 0.4 이런 느낌)

- 좌: 패치된 이미지가 기존의 이미지의 얼굴을 다 가려 원본 이미지가 이 사진의 라벨을 결정하는데 무의미
또한 아래 사진을 보게되면 반대로 패치 이미지가 라벨을 결정짓는데 아무런 도움도 주지 않게 되어 학습이 어려움 - 우: CenterCrop 적용
CentorCrop하기 전에 비해서는 보다 배경 쪽 이미지가 패치가 되어 무의미한 패치가 발생하는 경우가 줄어들었지만 여전히 패치된 이미지가 원래의 이미지의 중요한 부분을 가리는 현상이 발생

가로 축은 그대로 두고, 세로 축으로만 잘라보자는 생각에 VerticalCrop을 적용
성능 개선 효과 있음
9. Stratified K-fold
더 적용해볼 idea
- K-fold
- TTA, Test Time Augmentation
