MASS: Masked Sequence to Sequence Pre-training for Language Generation
Abstract
-
BERT는 pre-training 후 fine-tuning을 통해 큰 성공을 거뒀다. 이에 BERT로부터 영감을 받아 언어 생성을 위해 encoder-decoder 기반 Masked Sequence to Sequence pre-training (MASS)를 제안한다.
-
MASS의 encoder는 랜덤으로 문장의 일부분이 마스킹 된 sentence가 input으로 들어가고, decoder는 마스킹된 부분을 예측한다.
-
zero/low-resource language generation (neural machine translation, 문서 요약, 대화 응답 생성 등)에 좋은 성능을 얻었다.
-
특히, 영어-프랑스어 비지도 번역에서 SOTA를 달성했다. (BLEU score 37.5)
Introduction
-
타겟 task의 학습 데이터는 적거나 없고, 충분히 많은 pre-training 데이터가 있을 경우 Pre-training과 fine-tuning이 널리 사용된다.
-
Pre-trainig 방법으로 ELMo, OpenAI GPT, BERT 등은 적은 양의 supervised data를 가지고 있는 여러 language understanding task(감성 분류, 언어 추론, 개체 인식, QA 등)에서 SOTA를 달성했다.
-
Language understanding과 달리 language generation은 일부 입력에 조건화된 자연어 문장을 생성하는 것을 목적으로 한다. (NMT, 문서 요약, 대화 응답 생성 등)
-
Language generation 테스크는 보통 데이터가 부족하다. BERT의 경우 language understanding에 특화되어 있기 때문에, language generation에 적합하지 않다.
-
MASS는 seq2seq 프레임워크를 기반으로 한다. 실험에서 Transformer를 seq2seq 모델로 사용했다.
-
MASS는 encoder 혹은 decoder만 사용하는 언어 모델들과 다르게, encoder와 decoder를 모두 학습한다.
1) MASS의 encoder는 unmasked token의 context에 대해 더 잘 학습할 수 있다.
2) MASS의 decoder의 입력 일부분에도 마스킹을 함으로써 decoder가 encoder를 더 많이 활용할 수 있게 한다.
- MASS는 pre-train 된 모델을 하나 사용하며, 이후 다양한 task에 대해 fine-tuning을 진행한다.
MASS
Sequence to Sequence Learning
- 는 sentence pair 이다.
- 와 는 각각 source domain과 target domain 이다.
- = () 는 source sentence, = () 을 target sentence 이다.
- Objective function 은 다음과 같다. X와 Y의 모든 sentence pair들에 대해 x가 주어졌을 때 y를 구하는 조건부 확률의 log liklihood를 더한 것이다.
- 조건부 확률은 다음과 같이 구할 수 있다. source sentence 와 target sentence 의 현재 token 이전의 모든 token들이 주어졌을 때 현재 token에 대한 조건부 확률이다.
- 는 ~ 의 token들을 의미한다.
Masked Sequence to Sequence Pre-training
-
비지도 예측 태스크에 대해 소개한다.
-
MASS의 MASK token들은 연속적으로 마스킹되어 있다.
-
는 MASK token의 개수이며, 개의 MASK token은 연속되어 있다.
-
마스킹 된 token이 부터 까지라면, 0< < < 이며, 은 sentence 의 전체 토큰 개수 (전체 sentence의 길이) 이고, = 이다.
-
Unpaired 된 source sentence 가 주어졌을 때, 는 부터 까지 마스킹된 sentence 전체를 뜻한다.
-
는 부터 까지의 tokens을 의미한다.
-
MASS는 MASK가 씌워진 sentence 전체를 input으로 입력받고, seq2seq 모델을 pre-training 할 때 문장에서 마스킹된 부분인 부터 까지의 tokens을 예측한다.
-
Objective function 은 다음과 같다.
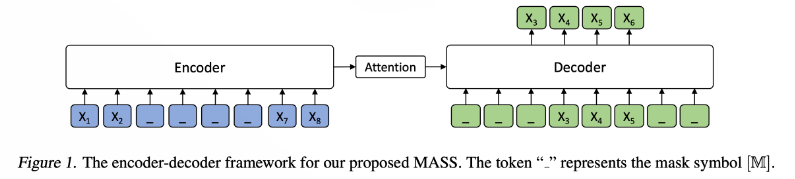
예를 들어보자.
- 위의 그림에는 input sentence의 길이가 8이고, , , , 이 마스킹 되어있다. ( = 4, = 3, = 6)
- Encoder의 입력으로는 마스킹된 input sentence 이 들어오고, attention을 거쳐 decoder로 값이 넘어온다. decoder에서는 입력으로 이 들어온다.
- Decoder의 input으로 들어온 token , , , 중 만 사용되기 때문에 은 사용되지 않는다.

-
는 매우 중요한 hyperparameter이며, 값의 special case에 대해 살펴보자
-
= 1인 경우, BERT의 MLM(Masked Language Model)과 동일하다. (Encoder만 작동)
-
가 1일 때, source sentence에는 단 한 개의 토큰만 마스킹되어 있다. Decoder에서는 input이 추가로 주어지지 않고, encoder에서 넘어온 context vector만을 사용해 마스킹된 token을 예측한다.
-
= 인 경우, 일반적인 Language Model이라고 할 수 있고, GPT와 동일하다. (Decoder만 작동)
-
= 일 때, encoder의 모든 token들이 마스킹되었고, decoder에는 기존 sentence의 모든 token이 입력된다.
-
표로 정리하면 다음과 같다.

Discussion
-
MASS는 encoder와 decocer를 모두 사용하여 language generation task에 적합하게 짜여졌다.
-
MASK token만 예측하게 함으로써 encoder는 unmaksed token에 대한 context를 잘 학습하게 되고, decoder는 encoder에서 더 유용한 정보를 추출할 수 있도록 한다.
-
뿔뿔히 흩어진 MASK token을 예측하는 것이 아닌 연속된 MASK token을 예측하게 함으로써 decoder가 언어 모델의 capability를 향상시킬 수 있다.
-
Decoder의 입력으로 source sentence의 마스킹되지 않은 부분이 들어오지 않게 함으로써 decoder가 input token에서 정보를 추출하기 보다 encoder에서 나온 context vector로부터 정보를 더 잘 추출할 수 있게 하였다.
Experiments and Results
MASS Pre-training
- Base Model로 Transformer (6-layer encoder & 6-layer decoder)을 채택했다.
- NMT(Neural Machine Translation) task의 경우, source와 target language에 대해 monolingual data로 pre-train 진행하였다. (English-French, English-German, English-Romanian 사용)
- Text Summarization, Conversational Response Generation task의 경우, English data로만 pre-train을 진행했다.
- MASS의 low-resource langage에 대한 pre-train 성능을 측정하고자 data가 적은 Romanian data도 pre-train에 사용하였다.
- BERT와 동일하게 전체 토큰의 80%는 [M] 토큰으로 치환하고, 10%는 랜덤 토큰으로 치환, 10%는 변경하지 않았다.
- 하이퍼파라미터인 는 전체 sentence 길이(전체 토큰의 수) m의 50%와 비슷하게 설정했다.
Fine-Tuning on NMT
Results on Unsupervised NMT
- Back-translation: Bilingual data가 없기 때문에 source language data로 가상의 bilingual data를 생성한다.
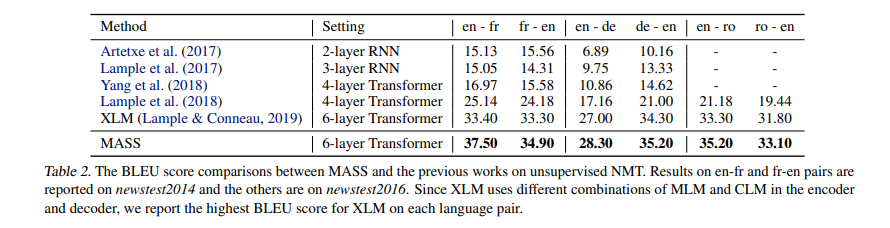
- MASS는 RNN 계열의 모델들과 Transformer 모델들보다 우수한 성능을 보여 SOTA를 달성했다. 기존 SOTA 모델은 XLM 모델이다.
Compared with Other Pre-training Methods
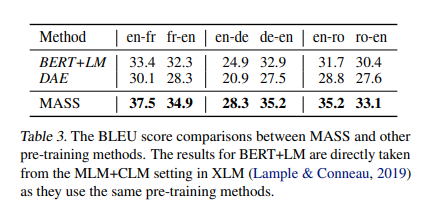
- MASS가 BERT+LM, DAE보다 높은 성능을 보였다.
- DAE: Denoising auto-encoder Pre-training 방식
Experiments on Low-Resource NMT
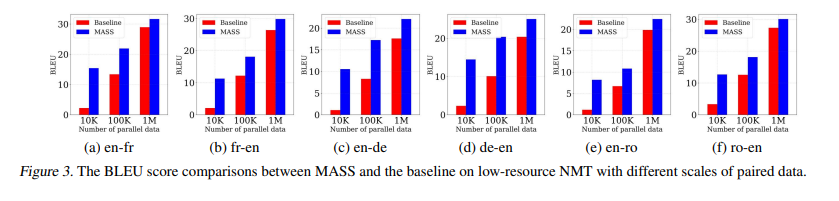
- 데이터 양이 적은 bilingual training data 학습에 대한 성능 측정
- bilingual dataset 크기별로, 각 언어별로 성능 측정
- Baseline은 pre-train을 하지 않은 모델이다.
- MASS가 모든 실험에서 baseline보다 높은 성능을 보였으며, 특별히 data sample 크기가 작을수록 성능의 차이가 압도적으로 컸다.
Fine-Tuning on Text Summarization
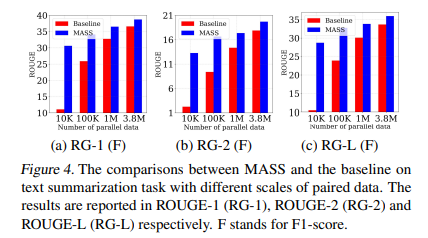
- Encoder의 input은 article, decoder의 input은 title을 사용했다.
- MASS와 pre-train을 수행하지 않은 모델과 비교했을 때, MASS가 높은 성능을 보였으며, data 크기가 작을수록 성능 차이가 컸다.
Compared with Other Pre-training Methods
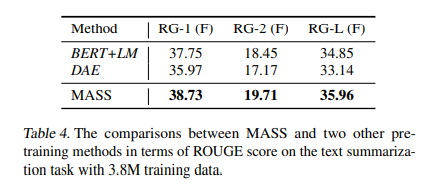
- 다른 pre-training method와 비교했을 때도 MASS의 성능이 가장 좋다.
Fine-Tuning on Conversational Response Generation
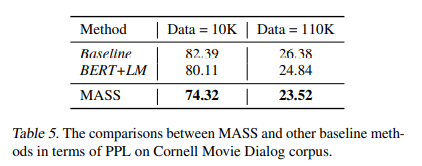
- Baseline Model은 pre-training을 수행하지 않은 모델이며, BERT+LM 모델은 pre-training을 수행한 모델이다.
- MASS의 성능이 가장 높다. (PPL이 낮을수록 성능이 높은 모델임)
