T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Introduction
-
최근 높은 성능을 보인 NLP 연구들은 대량의 unsupervised dataset에 pre-training 한 후 downstream task에 대해 supervised fine-tuning하는 transfer learning 방식을 사용하고 있다.
-
또한, 단순하게 더 큰 모델을 더 많은 데이터셋으로 학습 시킬수록 성능이 더 좋았다는 것으로 알려져 있다.
-
해당 논문에서는 transfer learning (pre-training -> fine-tuning) technique들에 대해 탐색하고, 모든 텍스트 기반 언어 문제를 text to text 형식으로 변환하는 통합 프레임워크를 소개한다.
-
구체적으로, pre-training objective, architectures, unlabeled dataset, fine-tuning methods 등에 대하여 각 기법의 효과에 대해 연구하는 비교 실험을 진행한다.
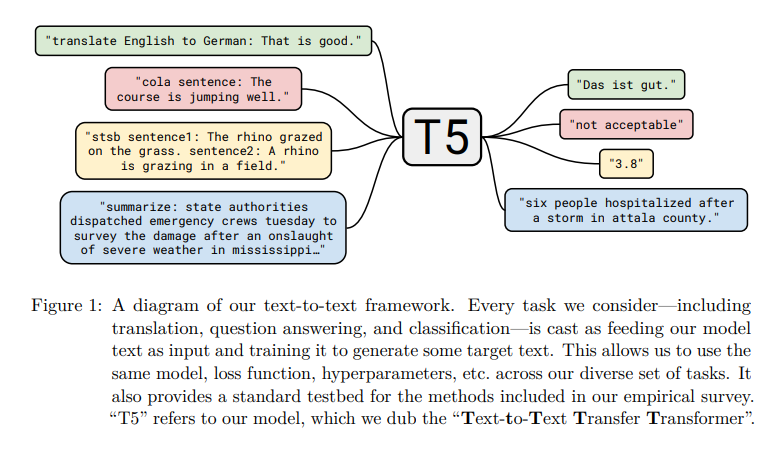
-
T5 모델의 기본 아이디어는 text가 input으로 들어가고, 새로운 text가 output으로 출력되는 것이다. 즉, 모든 NLP 문제를 text-to-text 방식으로 해결하는 것이다.
-
Text-to-text framework는 모든 task에 대해 동일한 model, hyperparameters, loss function 등을 사용한다는 점이 중요하다.
-
Text-to-text 모델 하나로 loss, hyperparameters 등의 변경 없이 요약, QA, 분류 등 다양한 nlp task에서 SOTA를 달성했다는 점에서 의의가 있다.
C4 (Colossal Clean Crawled Corpus)
- C4는 논문 저자들이 새로 만든 unlabeled data이며, T5 pre-training에 사용된 데이터셋이다.
- Unlabeled data에 대한 다양한 실험을 진행하고 quality, characteristics, size 등과 같은 요소들의 effect를 연구하기 위해 만들었다.
- 이전에 GPT-3와 같은 여러 모델들의 학습에 사용되었던 Common Crawl에서 몇가지 cleaning 기법을 적용하여 만든 데이터셋이다.
- C4와 다른 데이터셋과의 성능 비교 결과, C4의 성능이 타 데이터셋에 비해 그닥 뛰어나지 않음을 알 수 있었다. 이는, 타 데이터셋이 특정 domain이 국한되어 있었기 때문이라고 한다.
- 추가적으로, domain에 specific된 데이터는 task에 도움이 되지만, 과적합을 방지하기 위해 대량의 데이터가 필요하다는 것을 알 수 있다.
T5 vs Transformer
Transformer와의 공통점
- T5는 기존 transformer 모델(encoder-decoder 구조)을 사용한다.
- T5와 Transformer 둘 다 encoder, decoder 모두가 multi-head self attention layer, feed forward network, residual skip connection, dropout 기법을 사용한다.
Transformer와의 차이점
- layer normalization에서 bias를 제거하고, rescale만 진행한다.
- Input token에 Fixed embedding이 아닌, relative position embedding을 사용한다.
- Position embedding parameter를 모든 layer에서 공유한다.
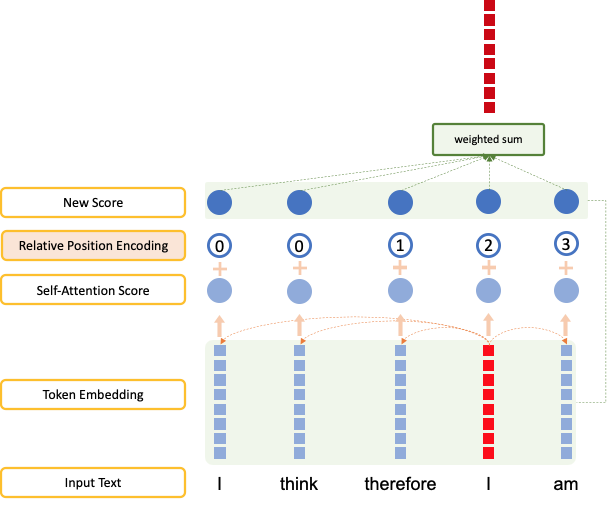
Relative position encoding이란?
- self-attention 계산 시 offset boundary 내의 token들에 relative position encoding 값을 준 것
- Ex. offset = 2일 때, relative position encoding index
- 다음 그림은 I think therefore I am"이라는 문장을 relative position encoding을 사용하여 transormer의 self-attention layer를 통과시키는 과정이다. (offset=2)
- Offset boundary를 넘어가는 단어는 가장 바깥쪽 index의 encoding 값을 부여한다. 그림에서 offset 범위를 넘어가는 첫 번째 토큰 I에 index 0의 encoding이 부여한다.
- T5에서는 offset을 32에서 128로 설정한다.
- 그림 출처: 티스토리 <끄적끄적>

T5 Model Structure
Attention Masks: Fully-visible vs Causal vs Causal with prefix
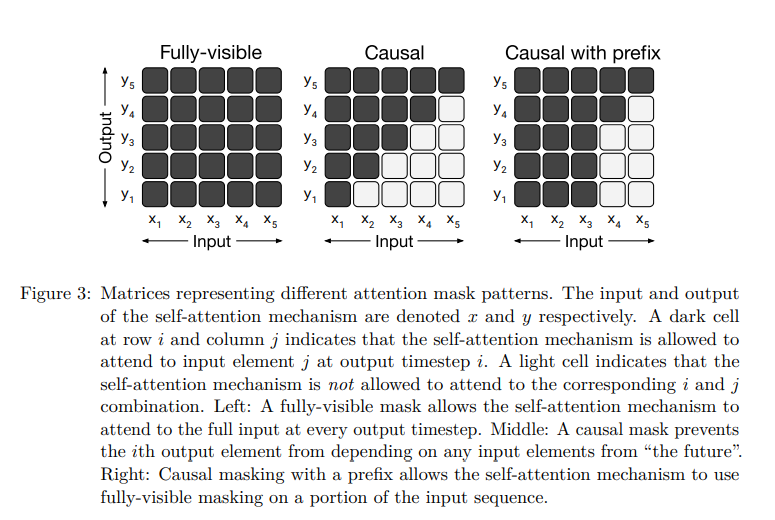
Fully-visible mask
- 매 출력 단어(Query)가 모든 입력 단어(Key)에 attention 가능
Causal mask
- 출력 단어(Query)가 자신의 과거, 현재 timestamp인 입력 단어(Key)에만 attention 가능
- 즉, 출력 단어(Query)가 미래의 입력 단어(Key)에는 attention 불가
Causal masking with prefix
- 출력 단어(Query)가 자신의 과거, 현재 timestamp인 입력 단어(Key)와 일정 길이의 prefix 단어에 attention 가능
Encoder-Decoder vs Language Model vs Prefix LM
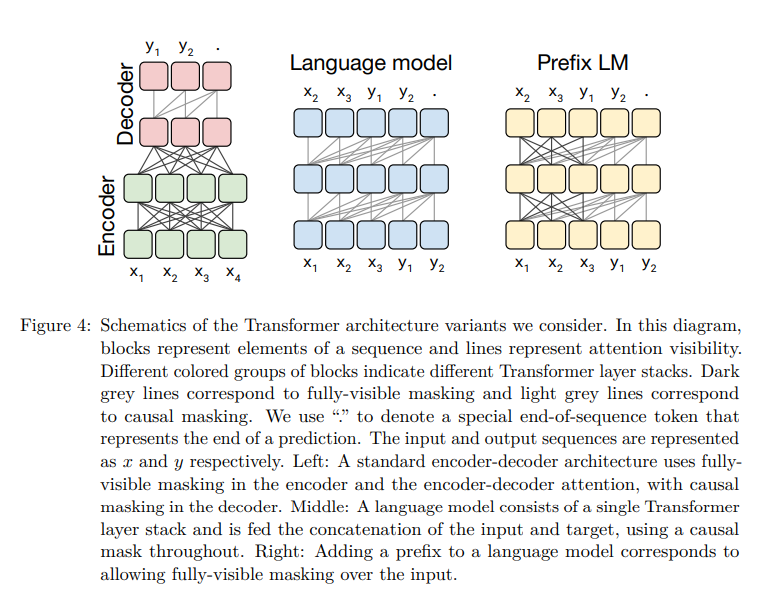
Encoder-Decoder
- Encoder: fully-visible self-attention 적용
- Decoder: casual self-attention 적용
Language Model
- Decoder만 사용
- Causal self-attention
Prefix LM
- 입력 문장 x에는 fully-visible self attention
- 출력 문장 y에는 causal self-attention
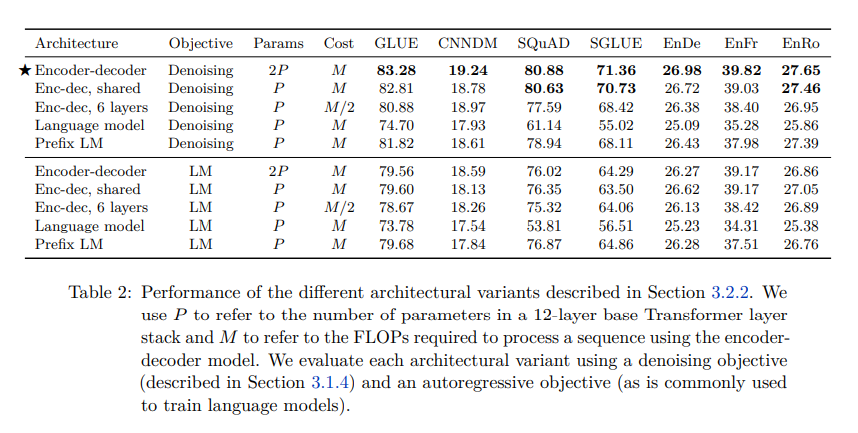
- Encoder-Decoder with denoising objective의 성능이 가장 좋았다. 이에 T5는 Encoder-Decoder 구조를 채택함.

- Model 구조에 따라 objective가 달라지며, objective에 따른 input-target은 다음과 같다.
Denoising Corrupted Span (Modified MLM)

- T5는 pretraining objectives로 span corruption을 사용한다. BERT의 MLM에 영감을 받았다.
- 기존에 BERT가 입력 문장에서 하나의 단위 token을 [MASK] 토큰으로 바꾸는 반면, T5는 연속된 token (즉, span) 혹은 단위 토큰을 하나의 토큰으로 마스킹한다.
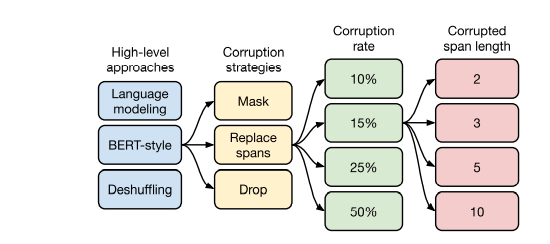
High-level approaches (Pre-training objectives 비교 실험)
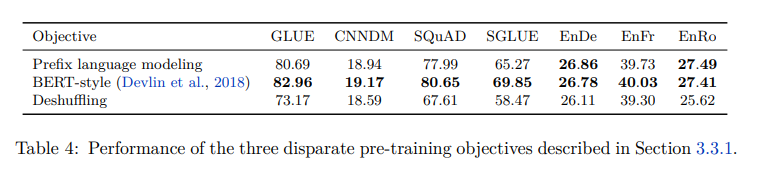
- 각 pre-training 방법 중 Bert-style 방식의 성능이 가장 높았다.
- Prefix language modeling은 GPT의 standard language modeling 방식이며, BERT-style 방식은 BERT의 MLM 방식을 말한다. 그리고, Deshuffling 방식은 denoising sequential autoencoder를 의미한다. (sequence를 입력으로 받아 순서를 shuffling한 후 원래 sequence를 target으로 해서 복구하는 방식)
Corruption strategies (Denoising objectives 비교 실험)
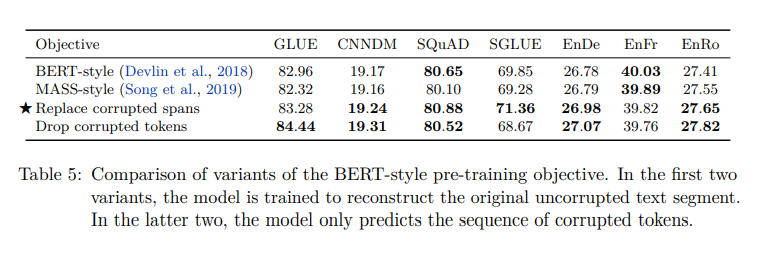
- 세 번째 방식인 Replace corrupted spans가 위에서 설명한 연속된 토큰을 하나의 마스킹 토큰으로 바꾸는 방식이다. (T5 방식)
- 참고로, Drop corrupted tokens란 input sequence의 token들을 제거하고 다시 복원하는 방식이다.
- 세 번째 방식인 T5 방식이 가장 좋은 성능을 냈다.
Corruption rate (Masking 비율) 비교 실험
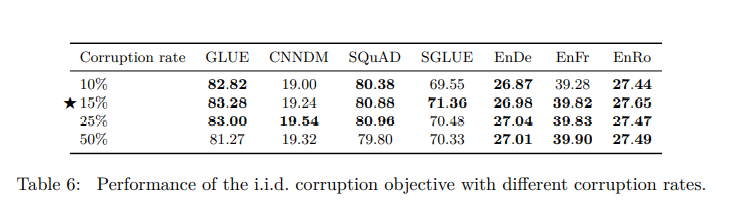
- 전체 token의 15% 정도를 마스킹하는 것이 가장 좋은 성능을 냈다.
Corruption span length
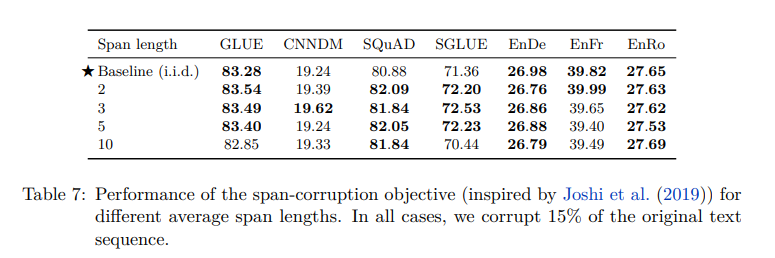
- Span length가 10일 때 제외하곤 큰 차이가 없다.
- Task에 따라 적절하게 설정하면 될 것 같다.
Multi-Task Learning
- Multi-task pre-training이란 pre-training 시 하나(single)의 task에 대해서 unsupervised pre-training을 진행한 후 fine-tuning을 진행하는 것과 달리 여러 개의 task에 대해 한 번에 pre-training을 하는 것을 의미한다.
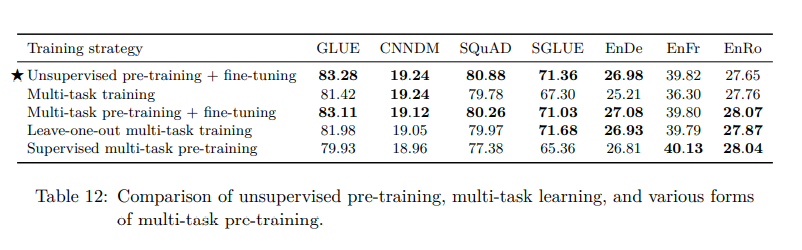
- 저자는 multi-task pre-training + fine-tuning 방식을 고안했고, 기존의 unsupervied pre-training + fine-tuning과 비슷한 성능을 낸 걸 확인했다.
T5 정리
마지막으로 T5가 채택한 것을 정리하면 다음과 같다.
- Encoder-decoder architecture
- Span corruption
- C4 dataset
- multi-task pretraining + fine-tuning
- bigger models trained longer
Reference
- https://soundprovider.tistory.com/entry/Exploring-Transfer-Learning-with-T5-the-Text-To-Text-Transfer-Transformer-2
- https://www.youtube.com/watch?v=enkKXuU6_Ok
- https://www.youtube.com/watch?v=eT0GXvt1PX4
- https://velog.io/@mooncy0421/Paper-Review-T5-Exploring-the-Limits-of-Transfer-Learning-with-a-Unified-Text-to-Text-Transformer#%EB%85%BC%EB%AC%B8-%EC%9D%BD%EB%8A%94-%EC%88%9C%EC%84%9C-%EC%B6%94%EC%B2%9C
