Background
1) 기존 pre-trained language model의 문제점
- 좋은 성능에는 large model이 필요
- 하지만 model이 클 수록 large memory가 필요 할 뿐만 아니라 inference 및 학습 시간이 오래 걸린다. (하드웨어의 한계)
2) score의 많은 손실없이 성능 좋은 작은 모델을 만들어보자!
- Parameter Reduction Technique
- Factorized Embedding Parameterization
- Cross-layer parameter sharing
- parameter sharing으로 size를 줄인것!
- Sentence-order prediction (new task)
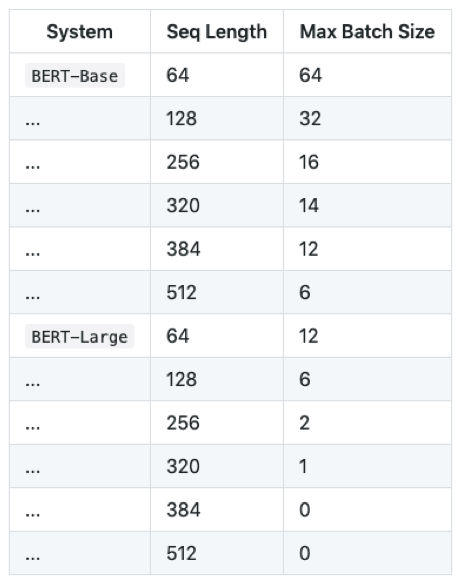
3) Training과 Inference시 Memory Limitation
- 12Gb Titan X GPU를 사용 할 경우
- Lart BERT의경우 기본 Seq Length인 512도 사용 하기 힘들다

Contribution
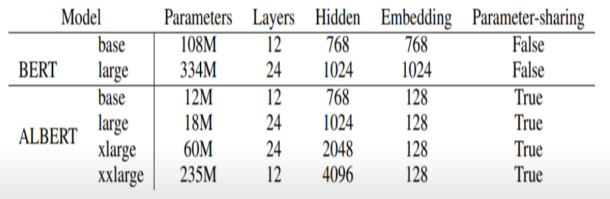
1) Factorized Embedding Parameterizatin
- BERT: Input Token Embedding Size(E)와 Hidden Size(H)가 같다.
- ALBERT: E를 H보다 작게 설정하여 Parameter 수를 줄인다.
- Input Token Embedding은 각 Token의 정보를 담고 있는 Vector를 생성한다. 반면, Transformer의 각 Layer에서의 Output은 해당 Token과 주변 Token들 간의 관계까지 반영한 Contextualized Representation이다. 따라서, 담고 있는 정보량 자체가 다르기 때문에 E가 H 보다 비교적 작아도 될 것이라고 생각할 수 있다. (H > E)
- BERT의 경우 V가 30,000으로 상당히 크고 이에 비해 E와 H는 작은 값이므로 ALBERT에서는 Parameter 수를 줄일 수 있다.
- (Embedding 과정을 2개의 Matrix로 나누어서 수행하므로 Factorized Embedding 이라고 합니다.)
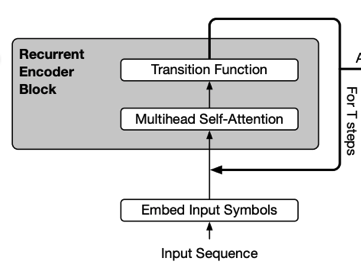
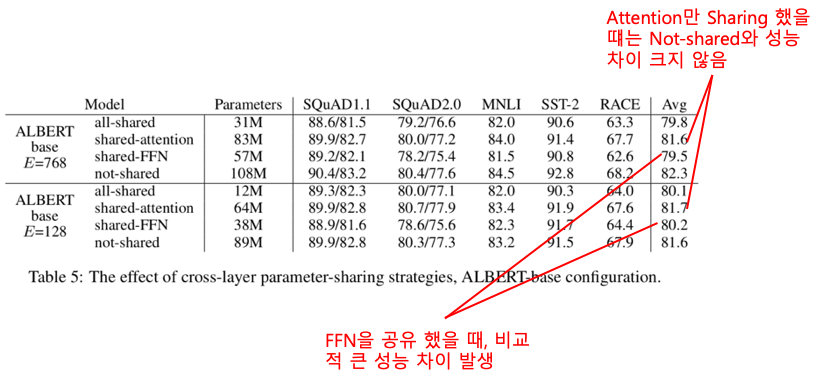
2) Cross-layer Parameter Sharing
- ALBERT에서는 layer의 모든 Parameter를 공유한다.
- BERT: transformer block 1~12까지를 거쳤다
- ALBERT: 단 하나의 transformer block을 12번 거친다.
3) Sentence Order Prediction
- BERT: 연속된 문장인지 맞추는 Next Sentence Prediction(NSP) 사용
- NSP는 두번 째 문장이 첫 문장의 다음 문장인지를 맞추는데 학습 데이터 구성 시 두 번째 문장은 실제 문장(positive example) 혹은 임의로 뽑은 문장(negative example)이 됩니다. 하지만, 임의로 뽑은 문장은 첫 문장과 완전히 다른 Topic의 문장일 확률이 높으므로 문장 간 연관 관계를 학습한다기 보다는 두 문장이 같은 Topic에 대해 말하는지를 판단하는 Topic Prediction에 가깝다.
- ALBERT: 문장의 순서를 맞추는 Sentence Order Prediction(SOP) 사용
- 실제 연속인 두 문장(Positive Example)과 두 문장의 순서를 앞뒤로 바꾼 것(Negative Example)으로 구성되고 문장의 순서가 옳은지 여부를 예측
Experiment
1) Memory Limitation
- ALBERT느 BERT와 같은 Layer 수, Hidden size에서 모델의 크기가 훨씬 작다. 따라서, Memory 사용량을 훨씬 줄일 수 있다. (ex) BERT large - 334mb, ALBERT large - 18mb)
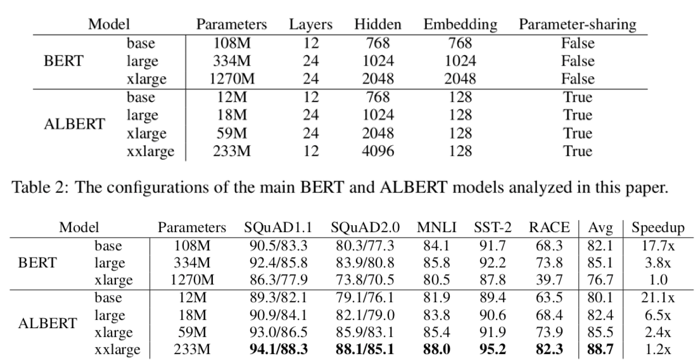
2) Training Time
- layer 수, Hidden size가 같을 때 ALBERT는 BERT 보다 학습 속도가 훨씬 빠르다.
- (ex) ALBERT xlarge는 BERT xlarge 보다 학습 속도가 2배 빠름)
2) Model Degradation
- BERT는 large에서 xlarge로 커질 경우 오히려 성능이 떨어집니다. 하지만, ALBERT의 경우 xxlarge가 xlarge 보다 그리고 xlarge가 large 보다 성능이 높은 성능을 보인다.
Reference
https://www.youtube.com/watch?v=1qU3BjejLSg
https://y-rok.github.io/nlp/2019/10/23/albert.html

Data Analytics Engineer