1. es to dataframe in jupyter
- 기본적으로 es로 데이터를 받아올때는 10000개로 개수가 제한된다
- 아마 성능상 이유로 기본셋팅을 10000개로 제한한거 같다
- 여러방법이 있지만 주로사용하는 search_after를 소개한다.
- sort로 조회한다.
data = {"match_all":{}}
sort = {"_id":{"order":"asc"}}
body = {'from':0, 'size':10000,"query":data,"sort":sort}
results = es.search(index='datalake_market_category_matching', body=body)
print(len(results['hits']['hits']))
result = results['hits']['hits']
df = json_normalize(result)
df.tail()- 결과
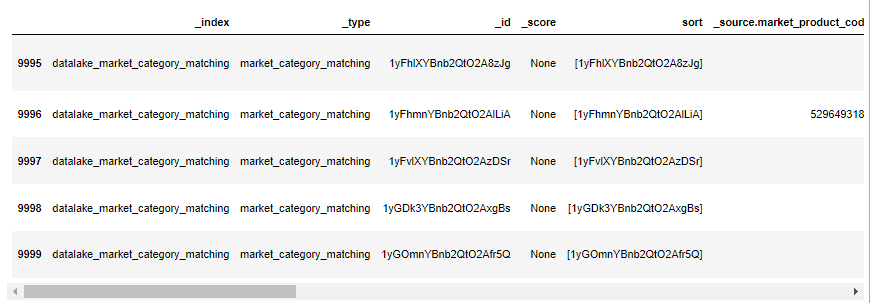
- 결과값중 sort값을 찾아 search_aftert의 value값으로 넣고 검색한다.
data = {"match_all":{}}
sort = {"_id":{"order":"asc"}}
body = {'from':0, 'size':10000,"query":data, "search_after":["1yGOmnYBnb2QtO2Afr5Q"],"sort":sort}
results = es.search(index='datalake_market_category_matching', body=body)
print(len(results['hits']['hits']))
result = results['hits']['hits']
df2 = json_normalize(result)
df2.head()- 처음 sort한 값의 마지막 행 다음부터 조회가 된다.
Reference

Data Analytics Engineer