- gpu를 여러개 가지고 있다면 multi gpu 설정을 해 보자!
- 단! 같은 종류의 gpu를 사용해야한다.
- 같은 gpu가 아닐경우 accuracy가 00.000이런식으로 이상한 값을 반환한다.
MirroredStrategy
1) gpu들 확인
- 내가 어떤gpu를 가지고있으며 해당 gpu번호가 무엇인지 확인한다.
from tensorflow.python.client import device_lib
device_lib.list_local_devices()
## 결과
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 464487649102182972,
name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 200212480
locality {
bus_id: 2
numa_node: 1
links {
link {
device_id: 1
type: "StreamExecutor"
strength: 1
}
link {
device_id: 6
type: "StreamExecutor"
strength: 1
}
link {
device_id: 7
type: "StreamExecutor"
strength: 1
}
}
}
incarnation: 5076821105153766538
physical_device_desc: "device: 2, name: GeForce GTX 1080 Ti, pci bus id: 0000:03:00.0, compute capability: 6.1",
name: "/device:GPU:3"
device_type: "GPU"
memory_limit: 10523291200
locality {
bus_id: 1
links {
link {
device_id: 2
type: "StreamExecutor"
strength: 1
}
link {
device_id: 4
type: "StreamExecutor"
strength: 1
}
link {
device_id: 5
type: "StreamExecutor"
strength: 1
}
}
}
incarnation: 11849997712688992303
physical_device_desc: "device: 3, name: GeForce GTX 1080 Ti, pci bus id: 0000:04:00.0, compute capability: 6.1",
name: "/device:GPU:4"
device_type: "GPU"
memory_limit: 10523291200
locality {
bus_id: 1
links {
link {
device_id: 2
type: "StreamExecutor"
strength: 1
}
link {
device_id: 3
type: "StreamExecutor"
strength: 1
}
link {
device_id: 5
type: "StreamExecutor"
strength: 1
}
}
}]2) gpu를 선택하고 변수에 넣어준다.
mirrored_strategy = tf.distribute.MirroredStrategy(devices=["/GPU:3","/GPU:4","/GPU:5","/GPU:6","/GPU:7"])3) model에 넣어준다.
- 이때 model 구조 ~ model.compile까지 with mirrored_strategy.scope(): 안에 넣어준다.
def transformer_model(X_test, y_test, X_train, y_train, max_len, vocab_size, y_softmax, market_obj, x_num, y_num):
with mirrored_strategy.scope():
inputs = layers.Input(shape=(max_len,))
embedding_layer = TokenAndPositionEmbedding(max_len, vocab_size, embed_dim)
x = embedding_layer(inputs)
transformer_block = TransformerBlock(embed_dim, num_heads, ff_dim)
x = transformer_block(x)
x = layers.GlobalAveragePooling1D()(x)
x = layers.Dropout(0.1)(x)
x = layers.Dense(128, activation="relu")(x)
# x = layers.Dropout(0.1)(x)
outputs = layers.Dense(y_softmax, activation="softmax")(x)
mall_n = mall_name.split('.')[0]
mall_n = mall_n.split('_')[0]
print('mall_n -- ', mall_n)
createFolder('market_models_v2/'+mall_n)
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=5)
# mc = ModelCheckpoint('market_models/'+mall_n+'/'+market_obj+'_model.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=False)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile("adam", "sparse_categorical_crossentropy", metrics=["accuracy"])
history = model.fit(
X_train, y_train, batch_size=200, epochs=100, validation_split=0.2, callbacks=[es]
)
model.save_weights('market_models_v2/'+mall_n+'/'+mall_n+'_model')
result.append((mall_name, market_obj, model.evaluate(X_test, y_test)[1], x_num, y_num, y_num/x_num))확인
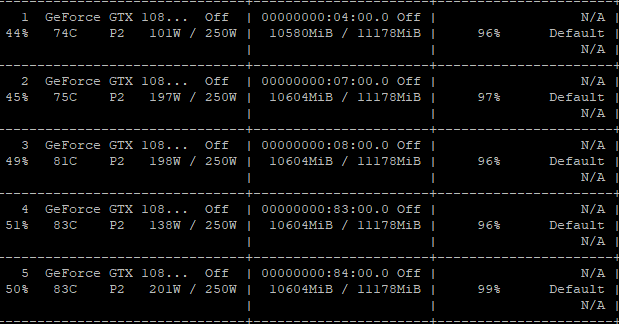
- watch nvidia-smi로 확인

Data Analytics Engineer