가시다님께서 진행하신 AEWS라는 스터디를 진행하면서 작성하는 글입니다.
AEWS= AWS EKS Workshop Study
AEWS 스터디는 4월 23일 ~ 6월 4일동안 총 7번 진행될 예정입니다.
PKOS 스터디에서 정말 좋은 경험을 했어서 다시 이렇게 참가하게 되었습니다.
가시다님께서 진행하시는 스터디에 관심있으신 분들은 Cloudnet@Blog에 들어가시면 자세한 정보를 확인하실 수 있습니다.
EKS Console
EKS를 모두 배포한 후에 AWS EKS 콘솔에서쿠버네티스 API를 통해서 리소스 및 정보를 확인 할 수 있습니다.
(단, 사용 중인 IAM에서 최소한 특정 IAM 및 kubernetes의 권한을 가지고 있어야 리소스를 볼 수 있습니다.)
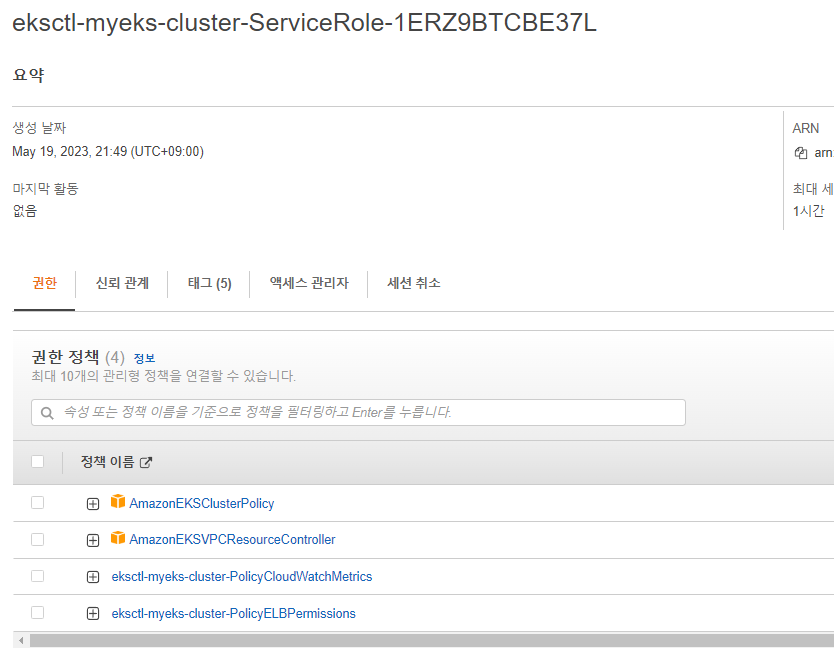
좀 더 상세한 권한을 보시기 원하면 링크에서 보실 수 있습니다..!
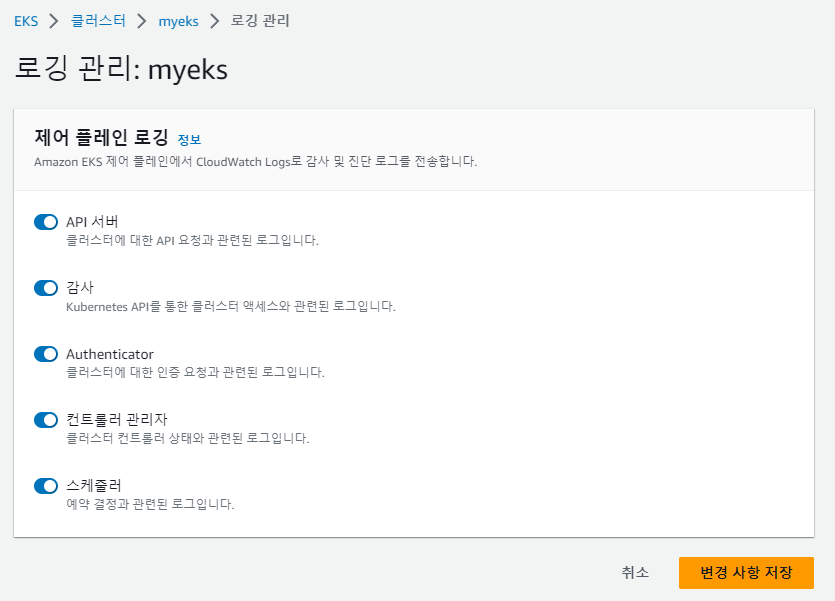
Logging in EKS
kubernetes Logging은 control plane logging, node logging, 그리고 application logging 이 3가지로 나눌 수 있습니다.
여기서는 Control plane log를 활성화 하고 Amazone Cloudwatch에서 확인해보겠습니다.
우선 Control plane log에는 어떤 유형이 있는지 보겠습니다.
Control plane log 유형
- 각 로그 유형은 k8s Control plane의 구성요소에 해당
- API Server
kube-apiserver-<nnn...>- 클러스터의 API 서버는 Kubernetes API가 표시되는 컨트롤 플레인 구성 요소
- 클러스터를 시작할 때 또는 직후에 API 서버 로그를 활성화하면 API 서버를 시작하는 데 사용된 API 서버 플래그가 로그에 포함
- Audit
kube-apiserver-audit-<nnn...>- Kubernetes 감사 로그는 클러스터에 영향을 준 개별 사용자, 관리자 또는 시스템 구성 요소에 대한 기록을 제공
- Authenticator
authenticator-<nnn...>- Amazon EKS가 IAM 자격 증명을 사용한 Kubernetes Kubernetes 역할 기반 액세스 컨트롤(RBAC) 인증에 사용하는 컨트롤 플레인 구성 요소를 나타냄
- Controller manager
kube-controller-manager-<nnn...>- Kubernetes와 함께 제공되는 핵심 컨트롤 루프를 관리
- Scheduler
kube-scheduler-<nnn...>- 클러스터에서 pods를 실행하는 시기와 위치를 관리
기본적으로 EKS Control plane log는 CloudWatch Logs로 전송되지 않습니다. 클러스터에 대해 로그를 전송하려면 각 로그 유형을 개별적으로 활성화해야 합니다.
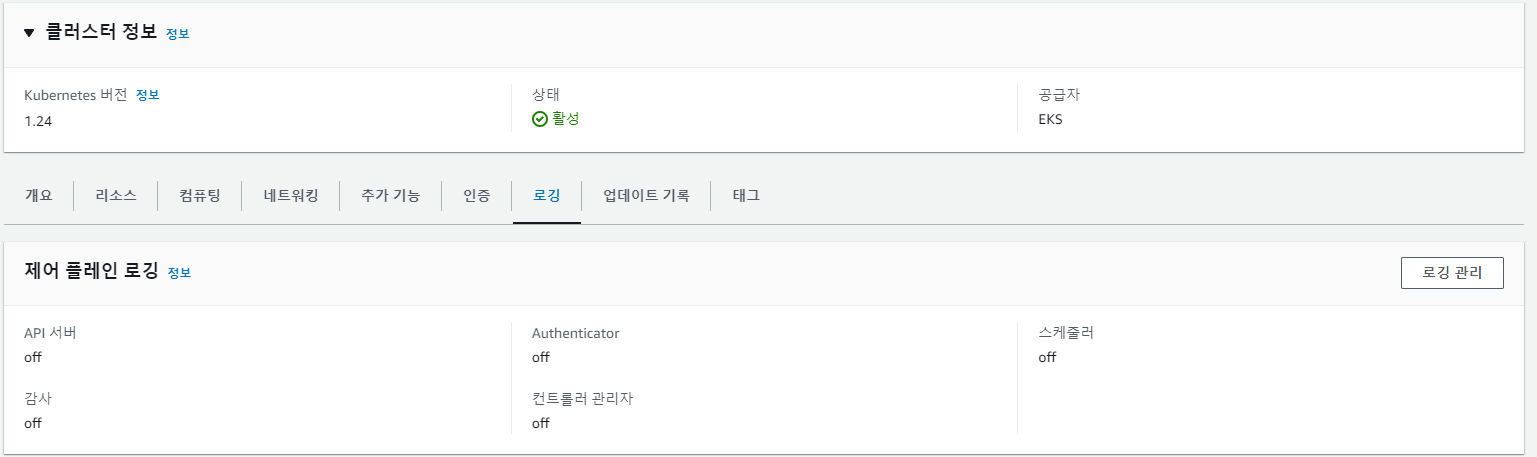
로그 활성화는 직접 로깅관리에 들어가서 off를 on으로 전환해서 활성화 할 수 있고 혹은 멋지게 CLI를 사용하여 활성화를 할 수 있습니다.
저는 가시다님께서 알려주신 멋진 CLI를 사용하여 활성화 해보겠습니다.
# 모든 EKS **Control plane logging** 활성화
aws eks **update-cluster-config** --region $AWS_DEFAULT_REGION --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["**api**","**audit**","**authenticator**","**controllerManager**","**scheduler**"],"enabled":**true**}]}'
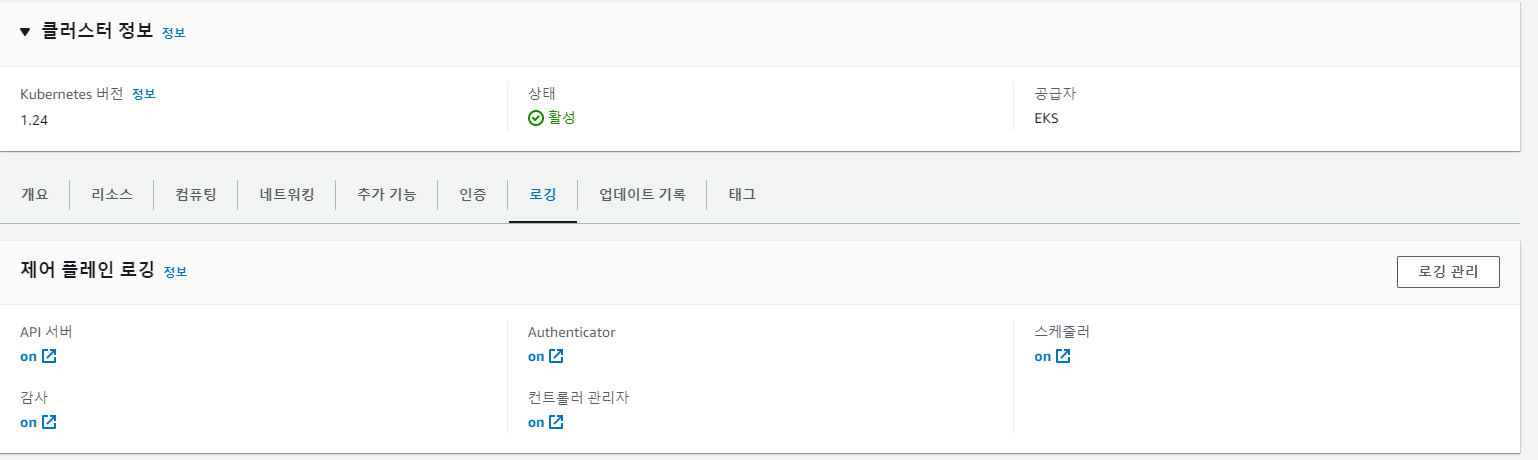
그럼 위와 같이 모두 logging 활성화가 된 것을 볼 수 있습니다.
활성화가 완료가 되면 cloudwatch에 들어가서 로그 그룹이 생성된 것을 확인할 수 있습니다.
로그 그룹을 클릭하시면 EKS Control plane에서 CloudWatch Logs로 전송되는 항목들을 보실 수 있습니다.
CloudWatch Logs Insights
CloudWatch Logs Insights를 사용하면 CloudWatch Logs에서 로그 데이터를 대화식으로 검색하고 분석할 수 있습니다.
- 쿼리를 수행하여 운영 문제에 보다 효율적이고 효과적으로 대응
- 문제가 발생하면 CloudWatch Logs Insights를 사용하여 잠재적인 원인을 식별하고 배포된 수정 사항을 검증
예를 들어 API 서버에 대량의 요청을 보내는 EKS 클러스터 내의 구성요소를 식별할 수 있습니다.

fields userAgent, requestURI, @timestamp, @message
| filter @logStream ~= "kube-apiserver-audit"
| stats count(userAgent) as count by userAgent
| sort count desc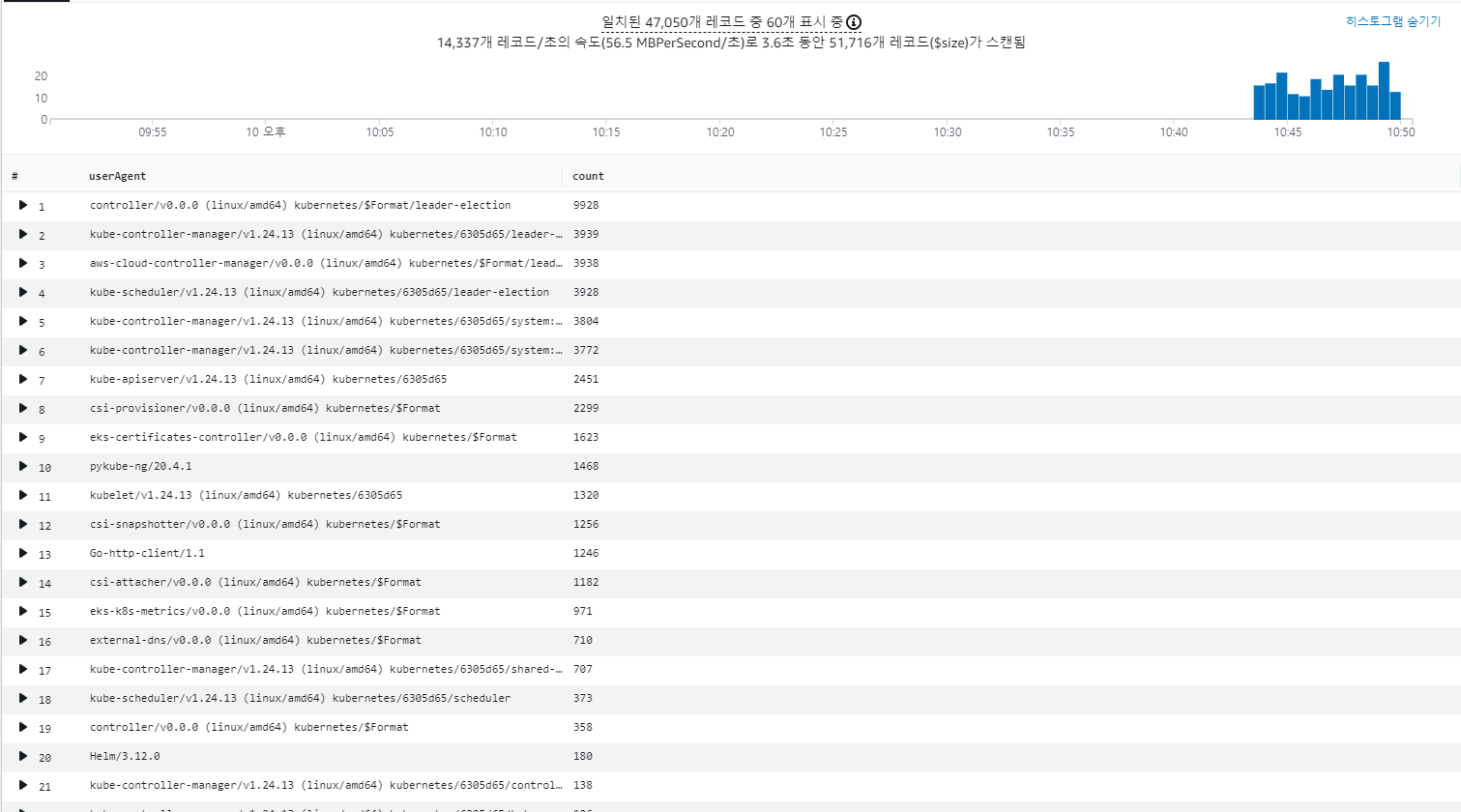
또는 AWS CLI로 CloudWatch Logs Insights를 사용할 수 있습니다.
# CloudWatch Log Insight Query
aws logs get-query-results --query-id $(aws logs start-query \
--log-group-name '/aws/eks/myeks/cluster' \
--start-time `date -d "-1 hours" +%s` \
--end-time `date +%s` \
--query-string 'fields @timestamp, @message | filter @logStream ~= "kube-scheduler" | sort @timestamp desc' \
| jq --raw-output '.queryId')마지막으로 Logging을 비활성화를 하고싶다면 직접 콘솔 로깅 관리에 들어가서 끌 수도 있고
아니면 멋지게 CLI로 비활성화 할 수 있습니다.
# EKS Control Plane 로깅(CloudWatch Logs) 비활성화
eksctl utils **update-cluster-logging** --cluster $CLUSTER_NAME --region $AWS_DEFAULT_REGION **--disable-types all** --approve
# 로그 그룹 삭제
aws logs **delete-log-group** --log-group-name /aws/eks/$CLUSTER_NAME/cluster저는 CLI로 멋지게 Logging을 비활성화 하고 로그 그룹 삭제 하겠습니다.

Pod(container) Logging
현대 애플리케이션 설계를 위한 표준을 제공하는 the Twelve-Factor App manifesto에 따르면 컨테이너형 애플리케이션은 로그를 stdout 및 stderr에 출력해야 합니다.
- 표준입력(STDIN): 표준 입력 장치의 ID 는 숫자로는 0 이며 일반적으로는 키보드가 됩니다.
- 표준출력(STDOUT): 출력을 위한 스트림으로 표준 출력 장치의 ID 는 1이며 일반적으로는 현재 쉘을 실행한 콘솔(console)이나 터미널(terminal)이 됩니다.
- 표준에러(STDERR): 에러를 위한 스트림으로 표준 에러 장치의 ID 는 2이며 일반적으로는 표준 출력과 동일합니다.
이것이 k8s에서도 모범사례로 간주되며 로그 수집 시스템이 이 전제를 기반으로 구축됩니다.
Kubernetes logging architecture는 세가지 다른 수준을 정의
- Basic level logging
- kubectl을 사용하여 pod log를 가져오는 기능
- Node level logging
- 컨테이너 엔진은 애플리케이션의 stdout 및 stderr에서 로그를 캡처하여 로그 파일에 기록
- Cluster level logging
- Node level logging을 기반으로 하며, 로그 캡처 에이전트가 각 노드에서 실행
- 이러한 로그 캡처 에이전트는 워커노드에서 DaemonSets 형식으로 실행
- 에이전트는 로컬 파일 시스템에서 로그를 수집하여 Elasticsearch 또는 CloudWatch와 같은 중앙 집중식 로깅 대상으로 전송
- 에이전트는 두 가지 유형의 로그를 수집
- 노드의 컨테이너 엔진이 캡처한 컨테이너 로그
- 시스템 로그.
- 에이전트는 두 가지 유형의 로그를 수집
한번 테스트로 Nginx 서버를 배포하고 로그를 생성해보겠습니다.
# NGINX 웹서버 **배포**
helm repo add bitnami https://charts.bitnami.com/bitnami
# 사용 리전의 인증서 ARN 확인
CERT_ARN=$(aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text)
echo $CERT_ARN
# 도메인 확인
echo $MyDomain
# 파라미터 파일 생성
cat <<EOT > nginx-values.yaml
service:
type: NodePort
ingress:
enabled: true
ingressClassName: alb
hostname: nginx.$MyDomain
path: /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
**alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'**
EOT
cat nginx-values.yaml | yh
# 배포
**helm install nginx bitnami/nginx --version 14.1.0 -f nginx-values.yaml**
그리고 반복 접속을 해서 로그를 만들어보겠습니다..
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; sleep 1; done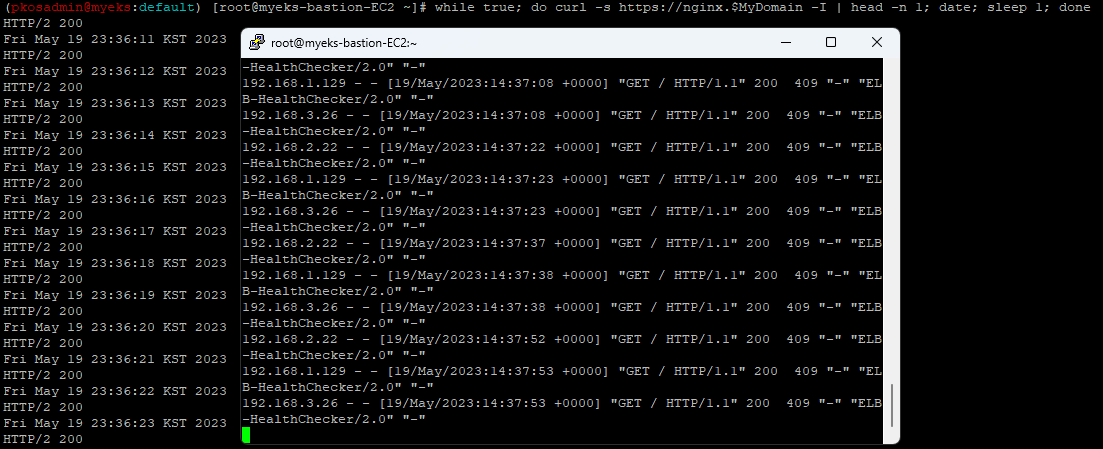
그럼 아래에 로그 파일이 생성된 것을 확인할 수 있습다.

그럼 위에서 설명했던 것 처럼 로컬 파일 시스템에서 로그를 수집하여 Elasticsearch 또는 CloudWatch와 같은 중앙 집중식 로깅 대상으로 전송해야하는데 이 것을 AWS에서는 어떻게 할까요?
Fluent Bit을 사용한다고 합니다.
Fluent Bit (Logs) & CloudWatchContainer Insights
우선 Fluent Bit에 대해서 살펴보자면,

- Fluent Bit 컨테이너를 데몬셋으로 동작시키고, 아래 3가지 종류의 로그를 CloudWatch Logs 에 전송
- /aws/containerinsights/
Cluster_Name/application : 로그 소스(All log files in/var/log/containers), 각 컨테이너/파드 로그 - /aws/containerinsights/
Cluster_Name/host : 로그 소스(Logs from/var/log/dmesg,/var/log/secure, and/var/log/messages), 노드(호스트) 로그 - /aws/containerinsights/
Cluster_Name/dataplane : 로그 소스(/var/log/journalforkubelet.service,kubeproxy.service, anddocker.service), 쿠버네티스 데이터플레인 로그
- /aws/containerinsights/
- CloudWatch Logs 에 로그를 저장
- CloudWatch 의 Logs Insights 를 사용하여 대상 로그를 분석하고, CloudWatch 의 대시보드로 시각화한다
정리하자면,
- 다양한 소스에서 데이터와 로그를 수집하고 필터를 사용하여 데이터를 강화한 후
- CloudWatch, Kinesis Data Firehose, Kinesis Data Streams 및 Amazon OpenSearch Service와 같은 여러 대상으로 전송할 수 있는 경량 로그 프로세서 및 포워더입니다.
그리고 CloudWatch Container Insight에 대해서 보자면,
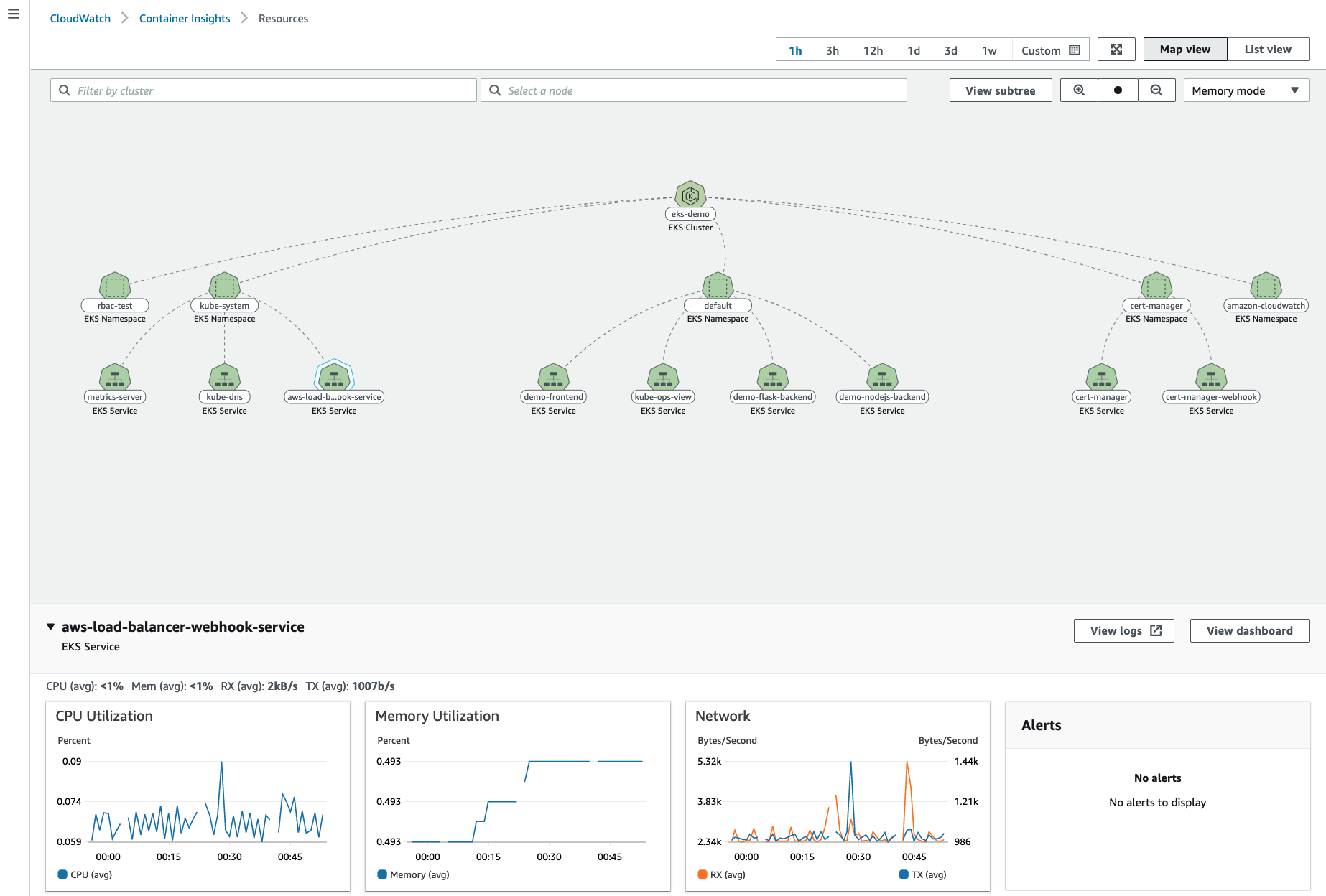
- 컨테이너형 애플리케이션 및 마이크로 서비스에 대한 모니터링, 트러블 슈팅 및 알람을 위한 완전 관리형 관측 서비스
- CloudWatch 콘솔에서 자동화된 대시보드를 통해 container metrics, Prometeus metrics, application logs 및 performance log events를 탐색, 분석 및 시각화
- CloudWatch Container Insight는 CPU, 메모리, 디스크 및 네트워크와 같은 인프라 메트릭을 자동으로 수집
- EKS 클러스터의 crashloop backoffs와 같은 진단 정보를 제공하여 문제를 격리하고 신속하게 해결할 수 있도록 지원
- 이러한 대시보드는 Amazon ECS, Amazon EKS, AWS ECS Fargate 그리고 EC2 위에 구동되는 k8s 클러스터에서 사용 가능
설치
그럼 cloudwatch-agent & fluent-bit를 설치해보겠습니다.
# 설치
FluentBitHttpServer='On'
FluentBitHttpPort='2020'
FluentBitReadFromHead='Off'
FluentBitReadFromTail='On'
**curl -s https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/quickstart/cwagent-fluent-bit-quickstart.yaml | sed 's/{{cluster_name}}/'${CLUSTER_NAME}'/;s/{{region_name}}/'${AWS_DEFAULT_REGION}'/;s/{{http_server_toggle}}/"'${FluentBitHttpServer}'"/;s/{{http_server_port}}/"'${FluentBitHttpPort}'"/;s/{{read_from_head}}/"'${FluentBitReadFromHead}'"/;s/{{read_from_tail}}/"'${FluentBitReadFromTail}'"/' | kubectl apply -f -**kubectl get po -n amazon-cloudwatch 명령어를 사용하여 정상적으로 설치되었는지 확인합니다.
cloudwatch-agent pod 및 fluent-bit pod가 각각 3개씩 나오면 정상설치입니다.

그 외에 다른 것들도 확인해보겠습니다.
# 설치 확인
kubectl get ds,pod,cm,sa -n amazon-cloudwatch
kubectl describe **clusterrole cloudwatch-agent-role fluent-bit-role** # 클러스터롤 확인
kubectl describe **clusterrolebindings cloudwatch-agent-role-binding fluent-bit-role-binding** # 클러스터롤 바인딩 확인
kubectl -n amazon-cloudwatch logs -l name=cloudwatch-agent -f # 파드 로그 확인
kubectl -n amazon-cloudwatch logs -l k8s-app=fluent-bit -f # 파드 로그 확인
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo ss -tnlp | grep fluent-bit; echo; done
# cloudwatch-agent 설정 확인
**kubectl describe cm cwagentconfig -n amazon-cloudwatch**- 로깅확인
- 메트릭 확인
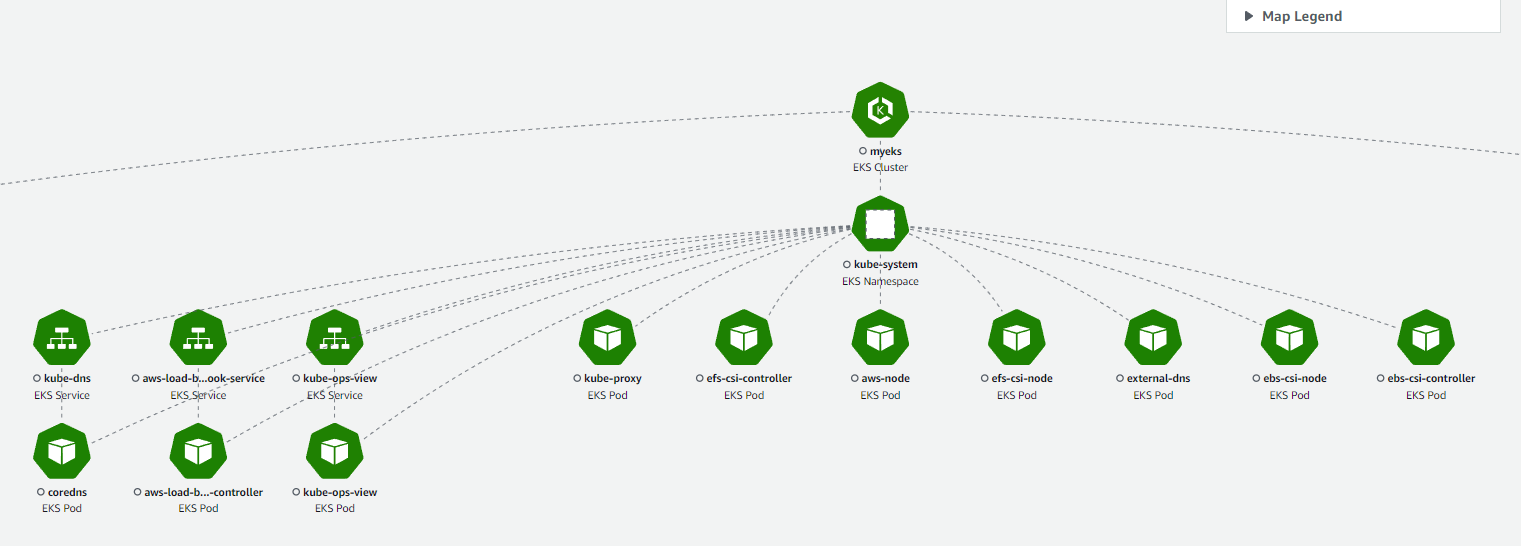
- 메트릭 map view 확인
Nginx 웹서버에 부하를 발생시키고 log insights에서 로그를 분석해보겠습니다.
- 부하 발생
# 부하 발생
curl -s https://nginx.$MyDomain
yum install -y httpd
ab -c 500 -n 30000 https://nginx.$MyDomain/
# 파드 모니터
kubectl logs deploy/nginx -f- log insights 분석
# **Application log errors** by container name : 컨테이너 이름별 애플리케이션 로그 오류
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/**application**
stats count() as error_count by kubernetes.container_name
| filter stream="stderr"
| sort error_count desc
# All **Kubelet errors/warning logs** for for a given EKS worker node
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/**dataplane**
fields @timestamp, @message, ec2_instance_id
| filter message =~ /.*(E|W)[0-9]{4}.*/ and ec2_instance_id="<YOUR INSTANCE ID>"
| sort @timestamp desc
# **Kubelet errors/warning count** per EKS worker node in the cluster
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/**dataplane**
fields @timestamp, @message, ec2_instance_id
| filter message =~ /.*(E|W)[0-9]{4}.*/
| stats count(*) as error_count by ec2_instance_id
**# performance 로그 그룹**
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/**performance**
# 노드별 평균 CPU 사용률
STATS avg(node_cpu_utilization) as avg_node_cpu_utilization by NodeName
| SORT avg_node_cpu_utilization DESC
# 파드별 재시작(restart) 카운트
STATS avg(number_of_container_restarts) as avg_number_of_container_restarts by PodName
| SORT avg_number_of_container_restarts DESC
# 요청된 Pod와 실행 중인 Pod 간 비교
fields @timestamp, @message
| sort @timestamp desc
| filter Type="Pod"
| stats min(pod_number_of_containers) as requested, min(pod_number_of_running_containers) as running, ceil(avg(pod_number_of_containers-pod_number_of_running_containers)) as pods_missing by kubernetes.pod_name
| sort pods_missing desc
# 클러스터 노드 실패 횟수
stats avg(cluster_failed_node_count) as CountOfNodeFailures
| filter Type="Cluster"
| sort @timestamp desc
**# 파드별 CPU 사용량**
stats pct(container_cpu_usage_total, 50) as CPUPercMedian by kubernetes.container_name
| filter Type="Container"
| sort CPUPercMedian desc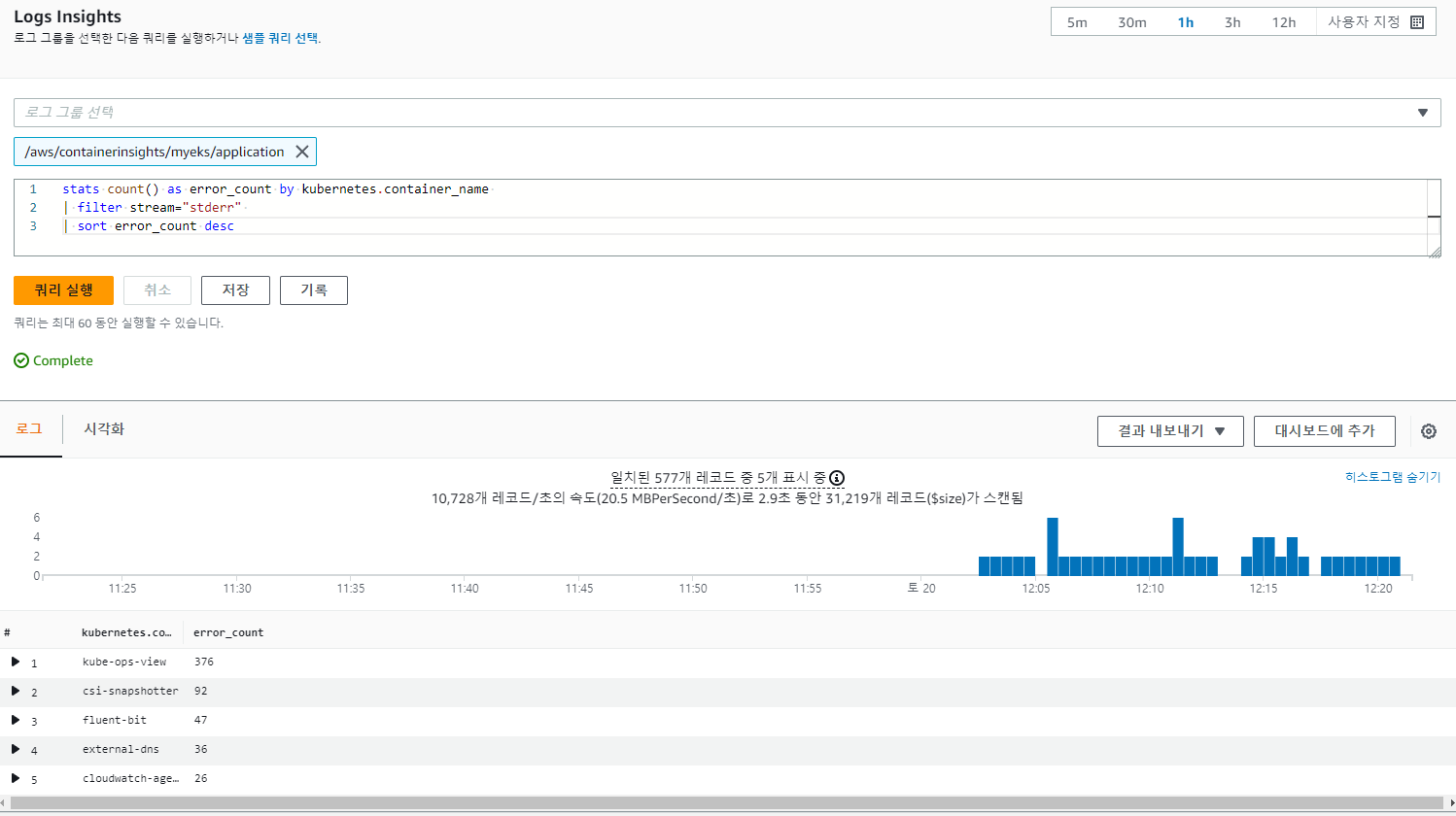
Metrics-server
Metrics-server는 메트릭 API에 대한 구현입니다.
- 이 API는 클러스터 내 노드와 파드의 CPU 및 메모리 사용 정보에 접근 가능하게 도와줌
- 주 역할은 리소스 사용 메트릭을 쿠버네티스 오토스케일러 구성 요소에 제공
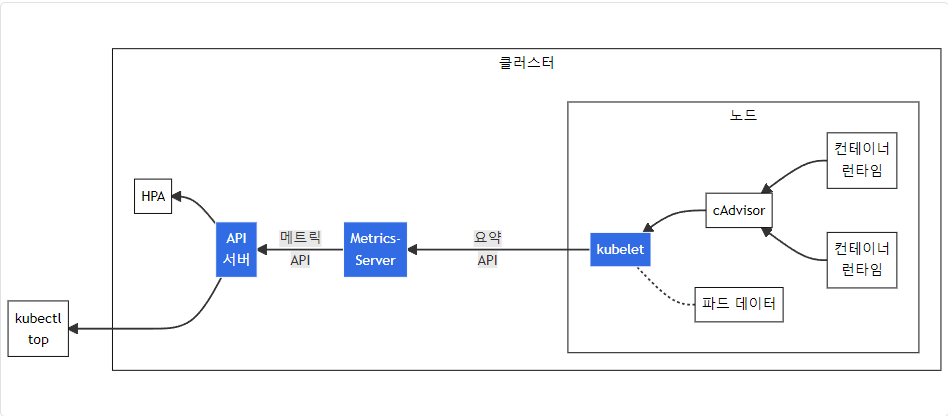
위 그림은 Metrics 파이프라인을 나타냅니다.
구성 요소는
- cAdvisor
- kubelet에 포함된 컨테이너 메트릭을 수집, 집계, 노출하는 데몬
- kubelet
- 컨테이너 리소스 관리를 위한 노드 에이전트.
- 리소스 메트릭은 kubelet API 엔드포인트
/metrics/resource및/stats를 사용하여 접근 가능
- 요약 API
/stats엔드포인트를 통해 사용할 수 있는 노드 별 요약된 정보를 탐색 및 수집할 수 있도록 kubelet이 제공하는 API
- metrics-server
- 각 kubelet으로부터 수집한 리소스 메트릭을 수집 및 집계하는 클러스터 애드온 구성 요소.
- API 서버는 HPA, VPA 및
kubectl top명령어가 사용할 수 있도록 메트릭 API를 제공 - metrics-server는 메트릭 API에 대한 기준 구현(reference implementation) 중 하나
- 메트릭 API
- 워크로드 오토스케일링에 사용되는 CPU 및 메모리 정보로의 접근을 지원하는 쿠버네티스 API.
- 이를 클러스터에서 사용하려면, 메트릭 API를 제공하는 API 확장(extension) 서버가 필요
그럼 한번 설치를 해보고 메트릭을 확인해보겠습니다.
# 배포
**kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml**
# 메트릭 서버 확인
kubectl get pod -n kube-system -l k8s-app=metrics-server
kubectl api-resources | grep metrics
kubectl get apiservices |egrep '(AVAILABLE|metrics)'
# 노드 메트릭 확인
kubectl top node
# 파드 메트릭 확인
kubectl top pod -A
kubectl top pod -n kube-system --sort-by='cpu'
kubectl top pod -n kube-system --sort-by='memory'- 메트릭 서버 확인
kubectl get pod -n kube-system -l k8s-app=metrics-server kubectl api-resources | grep metrics kubectl get apiservices |egrep '(AVAILABLE|metrics)'
- 노드 메트릭 확인
kubectl top node
- 파드 메트릭 확인
kubectl top pod -A kubectl top pod -n kube-system --sort-by='cpu' kubectl top pod -n kube-system --sort-by='memory'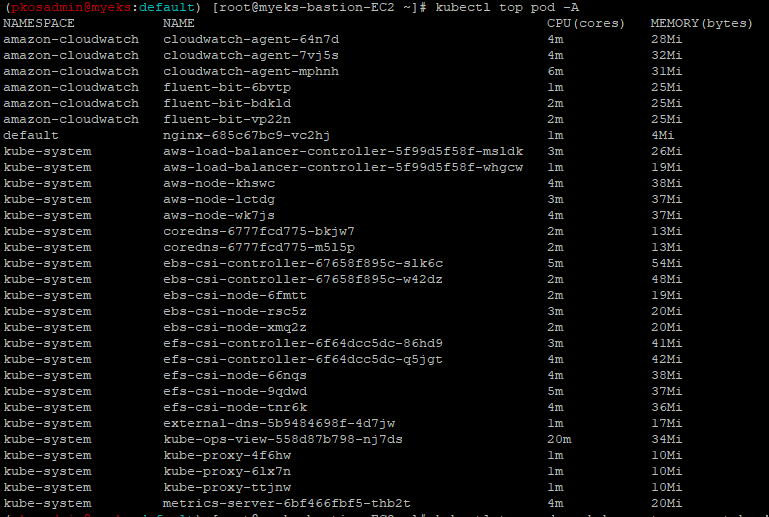
kwatch
kwatch는 Kubernetes(K8s) 클러스터의 모든 변경 사항을 모니터링하고, 실행 중인 앱의 충돌을 실시간으로 감지하고, 채널에 알림(슬랙, 디스코드 등)을 즉시 게시할 수 있도록 도와줍니다
슬랙으로 알람을 보낼 수 있게 한번 설정을 진행해보겠습니다.
# configmap 생성
cat <<EOT > ~/kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
**alert**:
**slack**:
webhook: '<슬랙웹훅주>'
title: $NICK-EKS
#text:
**pvcMonitor**:
enabled: true
interval: 5
threshold: 70
EOT
**kubectl apply -f kwatch-config.yaml**
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.3/deploy/**deploy.yaml**정상배포가 되면 아래와 같이 설정한 슬랙에 메세지가 날라오게됩니다.

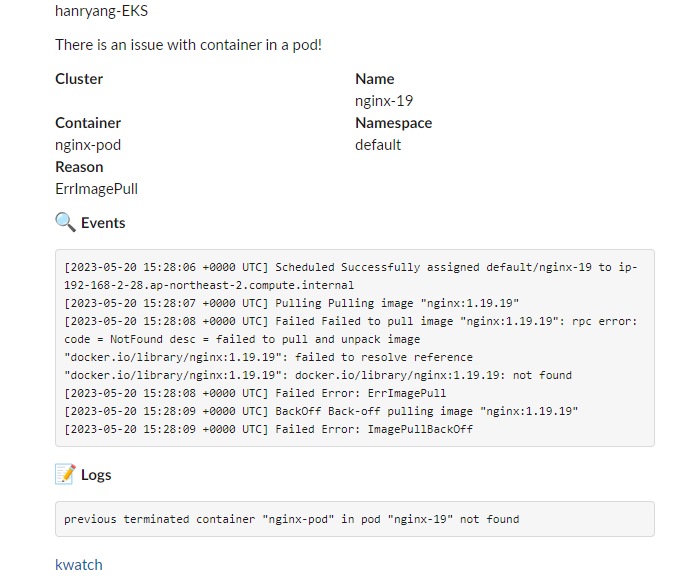
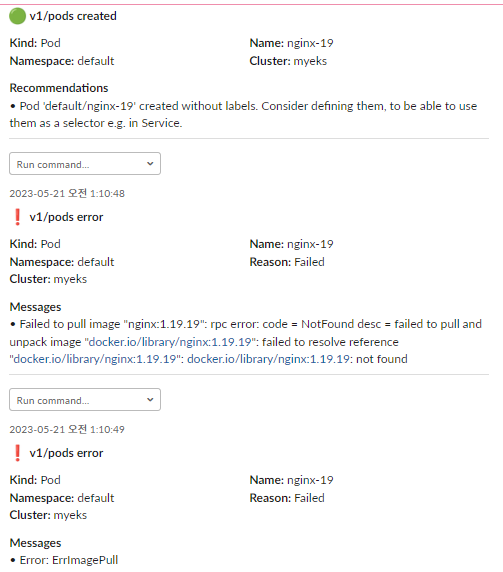
만약 잘못된 이미지 파드를 배포하게 되면 어떻게 될까요?
kwatch가 실시간으로 감지를 하고 슬랙에 메세지를 아래와 같이 뿌려줍니다.
Botkube
Kubernetes 클러스터 모니터링 및 디버깅을위한 메시징 봇이며, Slack, Mattermost, Microsoft Teams 등을 지원하고 슬랙에서 kubectl 을 통한 명령도 가능합니다.
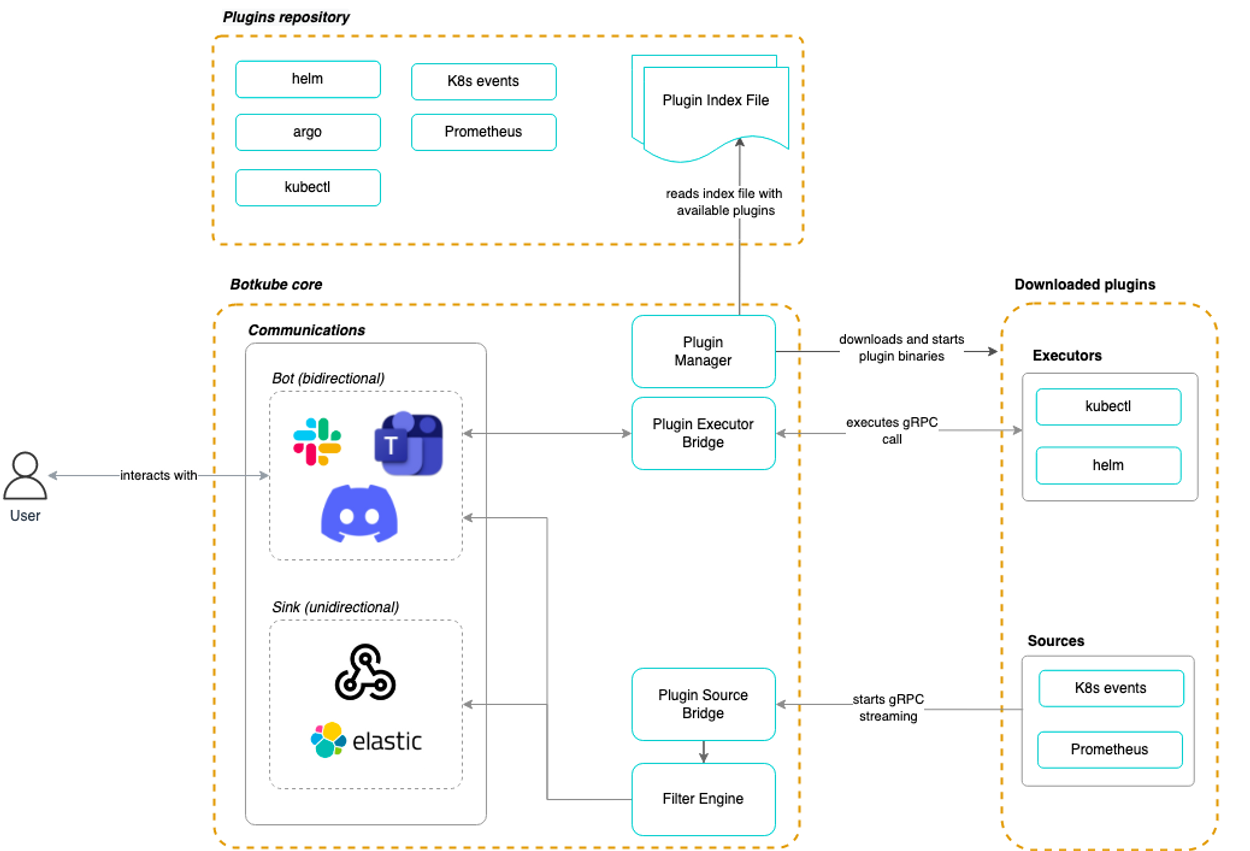
한번 Botkube를 배포하고 슬랙에서 명령어를 날려서 답이 나오는지 확인해보겠습니다,
-
배포
# repo 추가 helm repo add botkube https://charts.botkube.io helm repo update # 변수 지정 export ALLOW_KUBECTL=true export ALLOW_HELM=true export SLACK_CHANNEL_NAME=webhook3 # cat <<EOT > botkube-values.yaml actions: 'describe-created-resource': # kubectl describe enabled: true 'show-logs-on-error': # kubectl logs enabled: true executors: k8s-default-tools: botkube/helm: enabled: true botkube/kubectl: enabled: true EOT # 설치 helm install --version **v1.0.0** botkube --namespace botkube --create-namespace \ --set communications.default-group.socketSlack.enabled=true \ --set communications.default-group.socketSlack.channels.default.name=${SLACK_CHANNEL_NAME} \ --set communications.default-group.socketSlack.appToken=${SLACK_API_APP_TOKEN} \ --set communications.default-group.socketSlack.botToken=${SLACK_API_BOT_TOKEN} \ --set settings.clusterName=${CLUSTER_NAME} \ --set 'executors.k8s-default-tools.botkube/kubectl.enabled'=${ALLOW_KUBECTL} \ --set 'executors.k8s-default-tools.botkube/helm.enabled'=${ALLOW_HELM} \ -f **botkube-values.yaml** botkube/botkube -
슬랙 작동 테스트
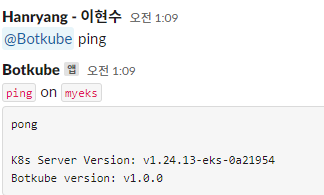
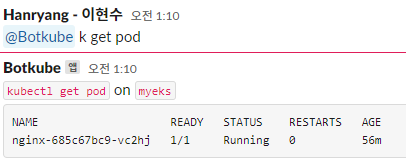
혹여나 잘못된 파드 배포를 하게 되면 메세지를 슬랙으로 보내게 됩니다.
Prometheus
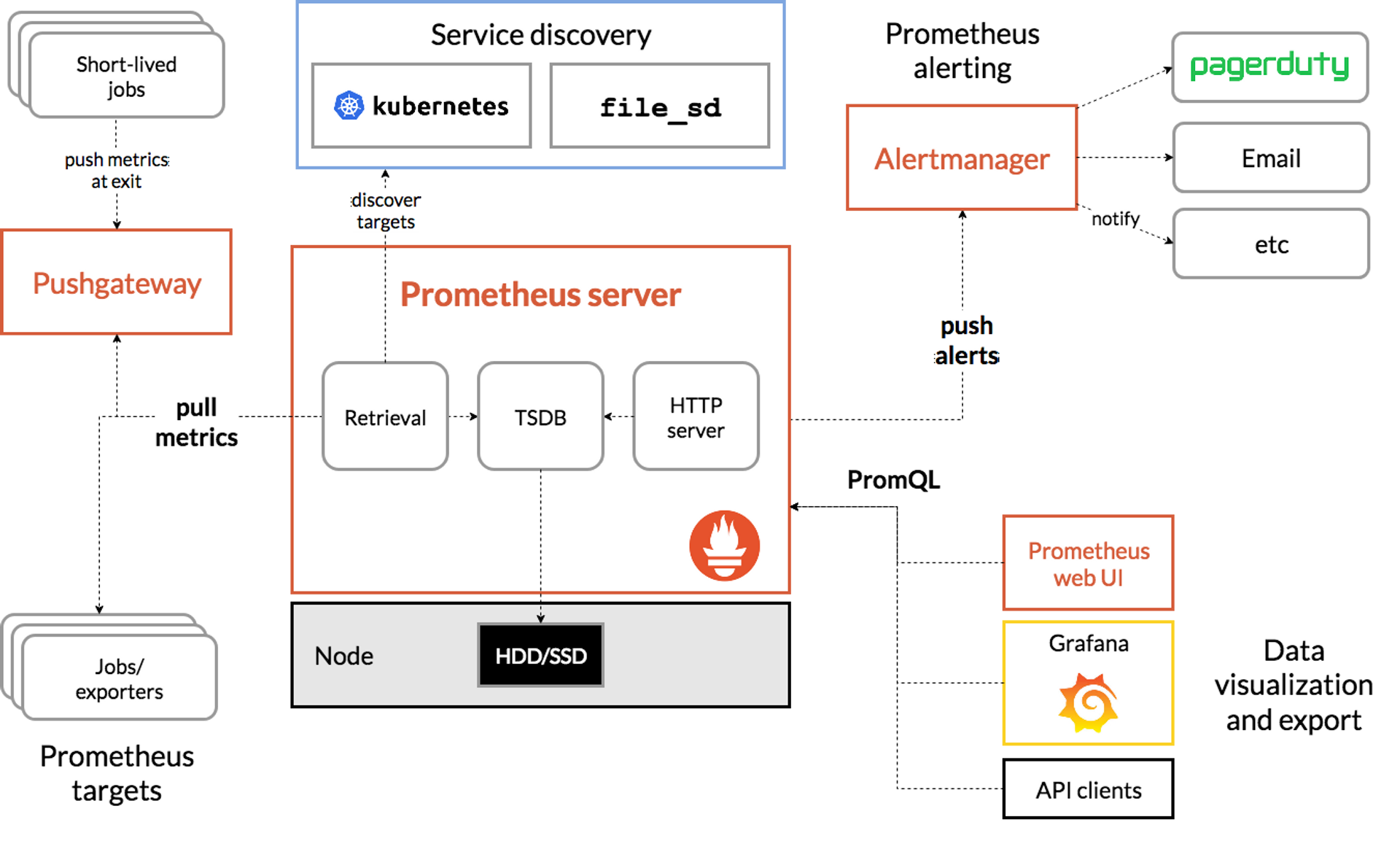
Prometheus는 시스템 및 서비스 모니터링 시스템입니다.
지정된 간격으로 구성된 대상에서 메트릭을 수집하고, 규칙 표현식을 평가하고, 결과를 표시하고, 지정된 조건이 관찰되면 경고를 트리거할 수 있습니다.
- 구성요소
- Prometheus server
- 시계열 데이터를 스크랩하여 저장
- client libraries
- 서비스를 모니터링하려면 먼저 Prometheus 클라이언트 라이브러리 중 하나를 통해 코드에 계측을 추가
- 애플리케이션이 작성된 언어와 일치하는 Prometheus 클라이언트 라이브러리를 선택
- 애플리케이션 인스턴스의 HTTP 엔드포인트를 통해 내부 메트릭을 정의하고 노출할
- push gateway
- 임시 및 배치 작업이 메트릭을 Prometheus에 노출할 수 있도록 하기 위해 존재
- exporters
- HAProxy, StatsD, Graphite 등과 같은 서비스를 위한
- Alertmanager
- Prometheus 서버와 같은 클라이언트 애플리케이션에서 보낸 경고를 처리
- Prometheus server
그럼 Prometheus 설치를 진행해보겠습니다. (뒤에 그라파나도 진행하므로 같이 설치를 진행했습니다.)
설치를 진행할 때 가시다님께서 주신 미션인 “프로메테우스-스택 설치 시, 주요 애플리케이션(파드)들은 EBS 스토리지클래스를 사용할 수 있게 helm 파라미터를 변경”을 진행하고자
**# 가시다님 미션 추가**
persistentVolume:
enabled: true
storageClass: ebs-csi-controller해당 파라미터를 추가하여 진행하였지만.. 계속된 오류로 일단 기존 설치방식대로 진행을 했습니다.
cat <<EOT > monitor-values.yaml
**prometheus**:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
**alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'**
**grafana**:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
**alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'**
defaultRules:
create: false
**kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false**
alertmanager:
enabled: false
# alertmanager:
# ingress:
# enabled: true
# ingressClassName: alb
# hosts:
# - alertmanager.$MyDomain
# paths:
# - /*
# annotations:
# alb.ingress.kubernetes.io/scheme: internet-facing
# alb.ingress.kubernetes.io/target-type: ip
# alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
# alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
# alb.ingress.kubernetes.io/success-codes: 200-399
# alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
# alb.ingress.kubernetes.io/group.name: study
# alb.ingress퍄 .kubernetes.io/ssl-redirect: '443'
EOT- 배포 확인
kubectl get pod,svc,ingress -n monitoring kubectl get-all -n monitoring
모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출이 되고 프로메테우스는 해당 경로에 http get 방식으로 메트릭 정보를 가져와서 TSDB형식으로 저장합니다.
# 아래 처럼 프로메테우스가 각 서비스의 9100 접속하여 메트릭 정보를 수집
kubectl get node -owide
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter
# 노드의 9100번의 /metrics 접속 시 다양한 메트릭 정보를 확인할수 있음 : 마스터 이외에 워커노드도 확인 가능
ssh ec2-user@$N1 curl -s localhost:9100/metrics정상적으로 설치가 되었는지 웹으로 접속해서 확인해보겠습니다.
Grafana
메트릭, 로그 및 추적이 저장되는 위치에 관계없이 쿼리, 시각화, 경고 및 탐색할 수 있습니다.
- 시계열 데이터베이스(TSDB) 데이터를 통찰력 있는 그래프 및 시각화로 변환하는 도구를 제공
- 플러그인 프레임워크를 사용하면 NoSQL/SQL 데이터베이스와 같은 다른 데이터 소스, Jira 또는 ServiceNow와 같은 티켓팅 도구, GitLab과 같은 CI/CD 도구를 연결
위에서 프로메테우스를 설치할 때 같이 그라파나를 설치를 진행했으므로 버전확인 및 , ingress확인을 진행하겠습니다.
# 그라파나 버전 확인
kubectl exec -it -n monitoring deploy/kube-prometheus-stack-grafana -- **grafana-cli --version**
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
그리고 그라파나에 접속해보겠습니다.
데이터 소스쪽에서 살펴보면 자동으로 프로메테우스를 데이터 소스로 추가해 둔것을 확인할 수 있습니다.

데이터 소스를 통해서 생성한 pod의 수집을 확인할 수있습니다.
# 테스트용 파드 배포
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: netshoot-pod
spec:
containers:
- name: netshoot-pod
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
EOF
kubectl get pod netshoot-pod
# 접속 확인
**kubectl exec -it netshoot-pod -- nslookup kube-prometheus-stack-prometheus.monitoring**
kubectl exec -it netshoot-pod -- curl -s kube-prometheus-stack-prometheus.monitoring:9090/graph -v ; echo
그라파나는 기본대시보드와 공식 대시보드를 가지고 있습니다.
- 스택을 통해서 설치된 기본 대시보드
- 공식 대시보드 여러가지 대시보드가 존재하며 Dashboard → New → Import에서 원하는 대시보드의 숫자를 입력하면 적용 완료.
-
**Kubernetes / Views / Global ⇒ 15757**
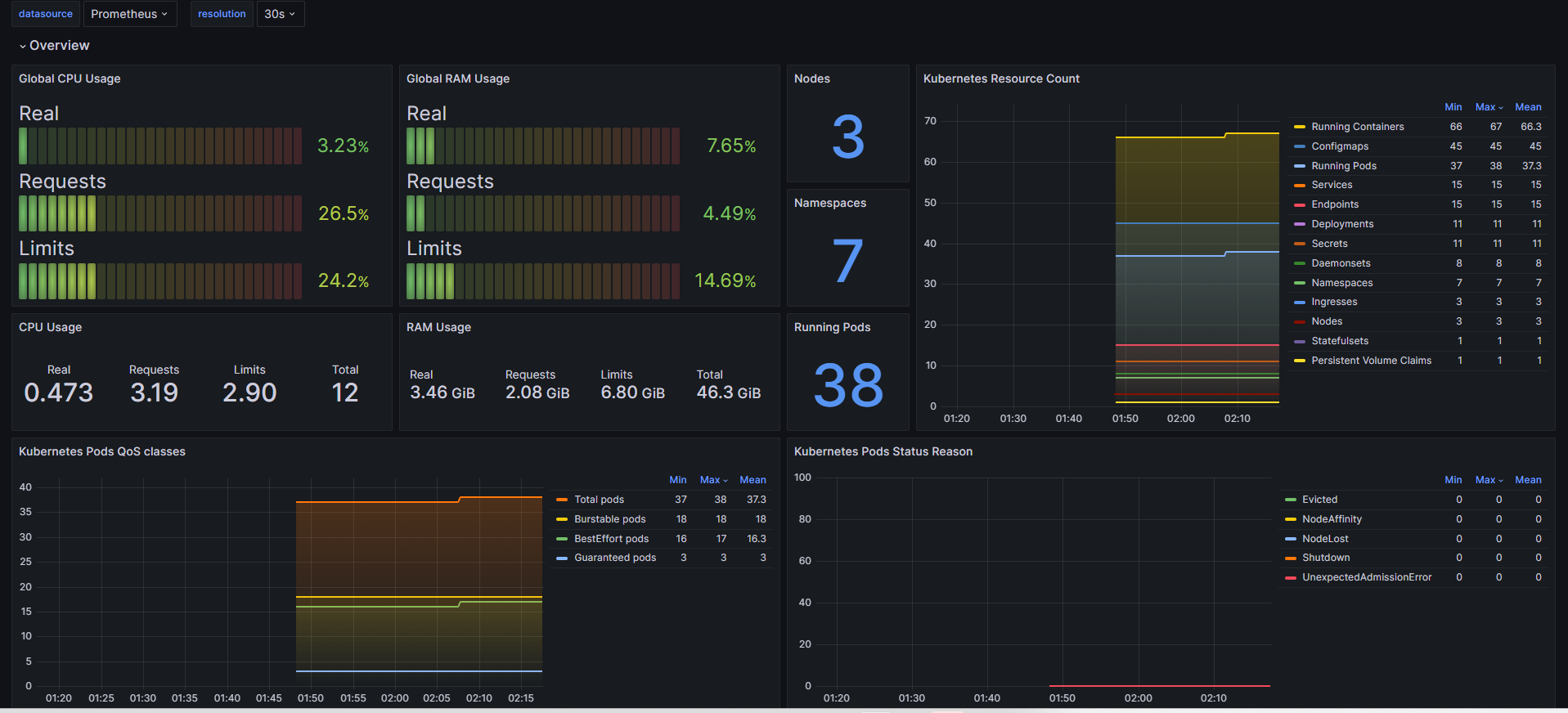
-
Nginx 웹서버 배포 및 모니터링 설정
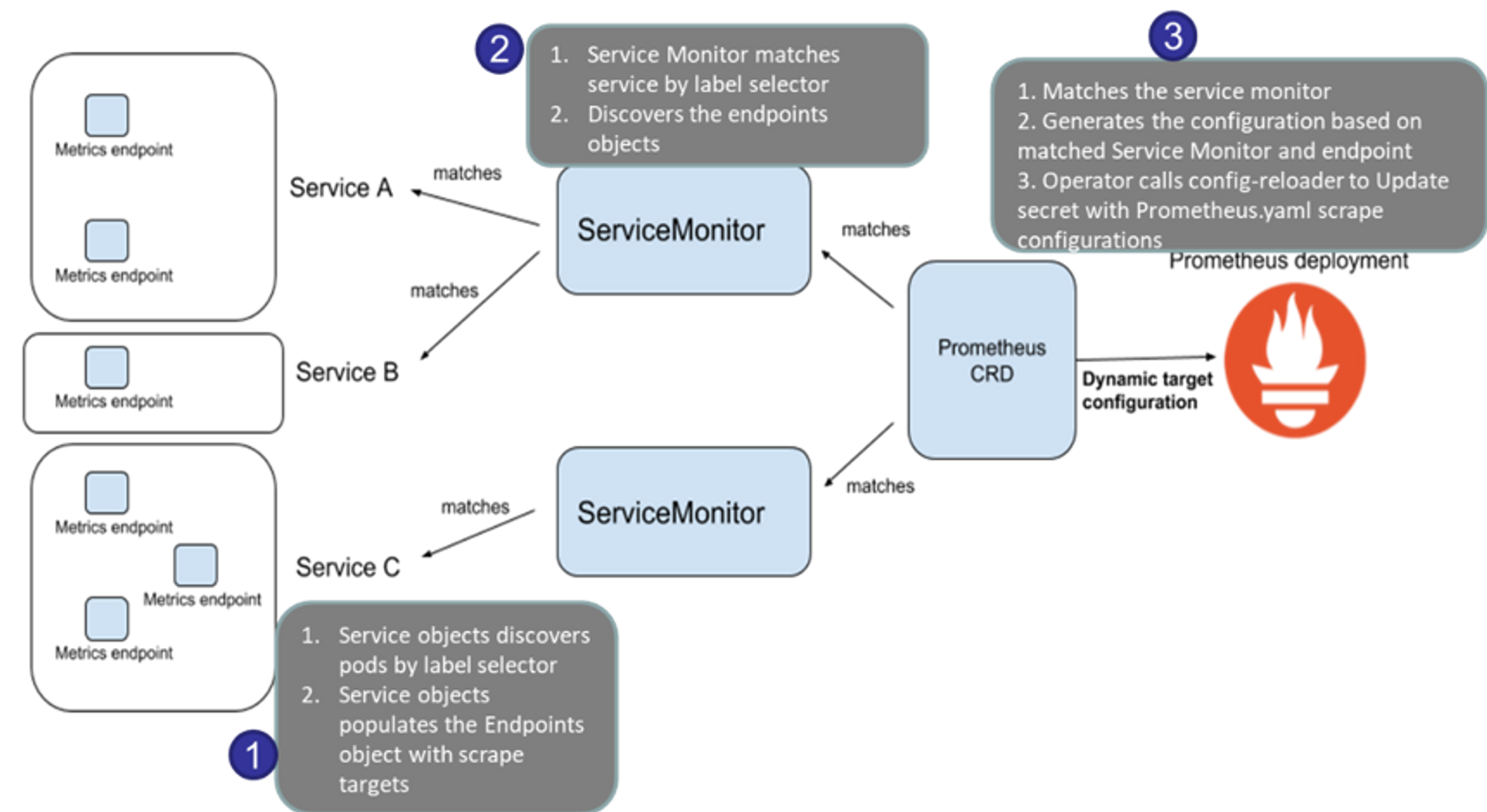
nginx 를 helm 설치 시 프로메테우스 익스포터 Exporter 옵션 설정 시 자동으로 nginx 를 프로메테우스 모니터링에 등록 가능합니다.
한번 nginx를 배포해보겠습니다.
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용, nginx 웹서버 노출은 AWS CLB 기본 사용
cat <<EOT > ~/nginx_metric-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm **upgrade** nginx bitnami/nginx **--reuse-values** -f nginx_metric-values.yaml
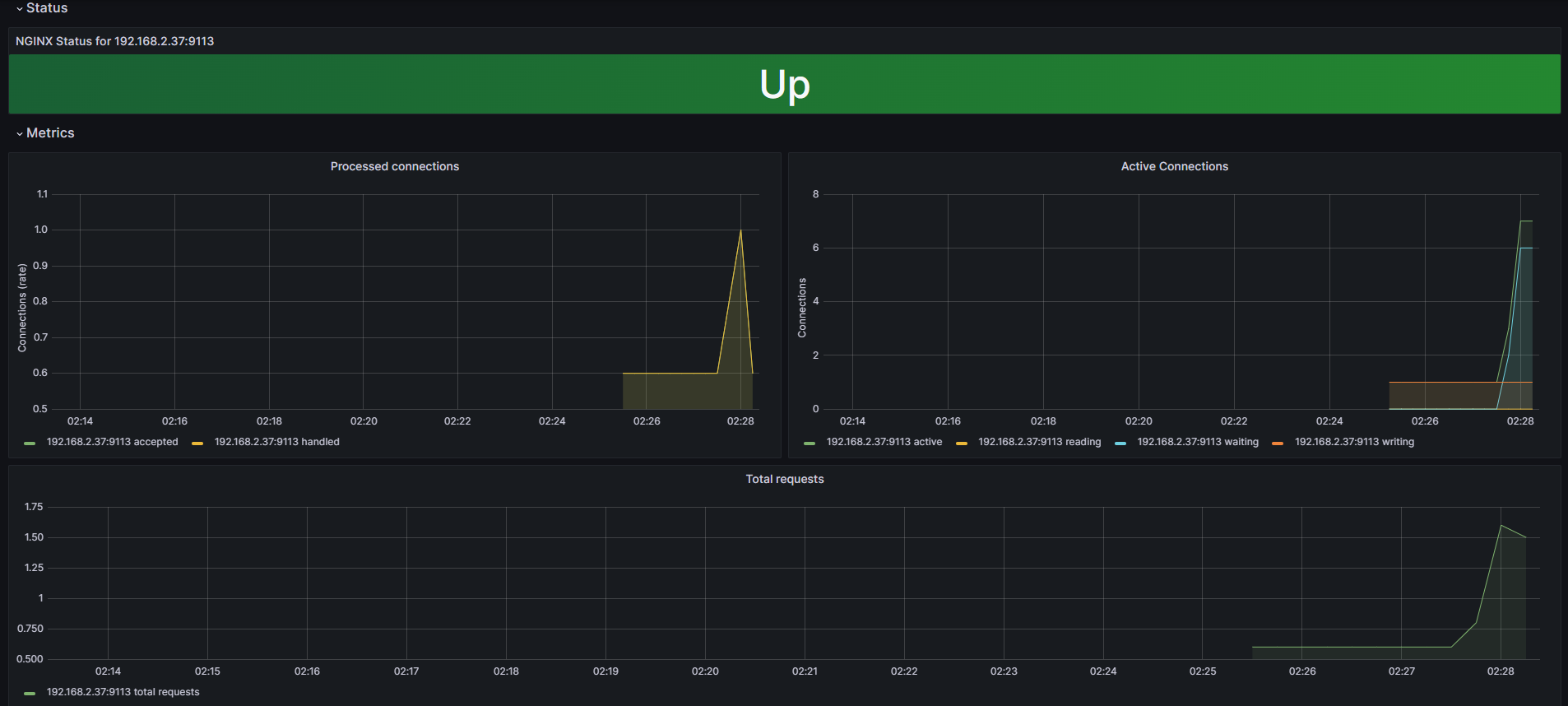
배포를 완료한 후에 프로메테우스 웹서버에서 nginx 서비스 모니터 추가 확인할 수 있습니다.

그라파나에 해당 Nginx 애플리케이션 모니터링을 추가해보겠습니다.
- 그라파나에 12708 대시보드 추가