가시다님께서 진행하신 AEWS라는 스터디를 진행하면서 작성하는 글입니다.
AEWS= AWS EKS Workshop Study
AEWS 스터디는 4월 23일 ~ 6월 4일동안 총 7번 진행될 예정입니다.
PKOS 스터디에서 정말 좋은 경험을 했어서 다시 이렇게 참가하게 되었습니다.
가시다님께서 진행하시는 스터디에 관심있으신 분들은 Cloudnet@Blog에 들어가시면 자세한 정보를 확인하실 수 있습니다.
Kubernetes autoscaling overview
-
HPA(Horizontal Pod Autoscaling)
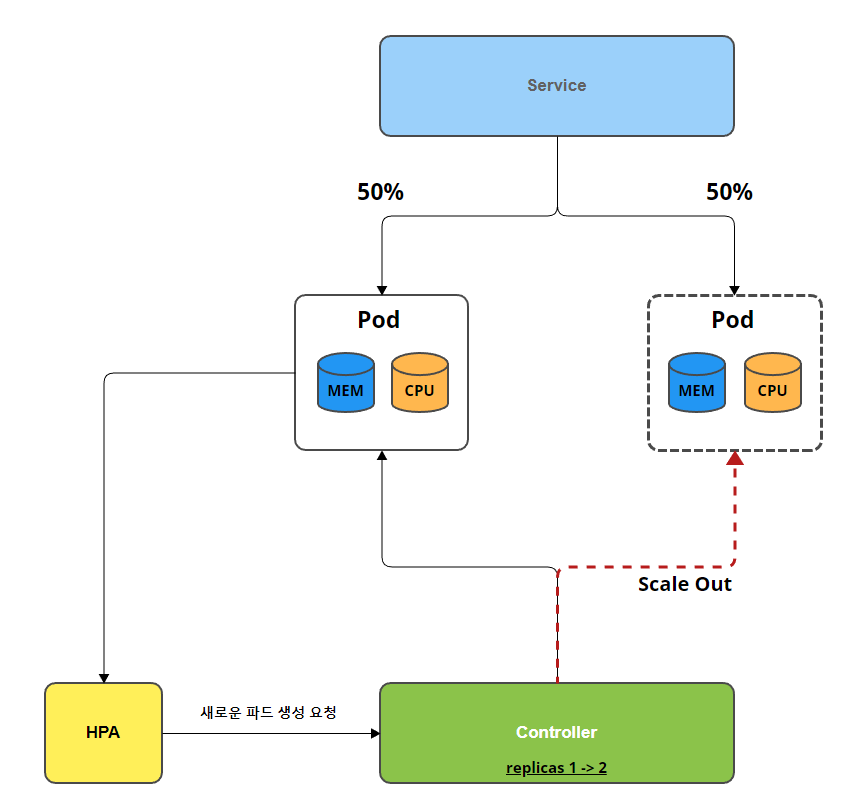
- 파드의 리소스를 감시하며, 리소스가 부족한 경우 Controller의 replicas를 증가시켜, 파드의 수를 증가
- 파드의 수 증가로 인해 기존의 트래픽이 분산되어 서비스를 더 안정적으로 유지 가능
-
VPA(Vertical Pod Autoscaling)
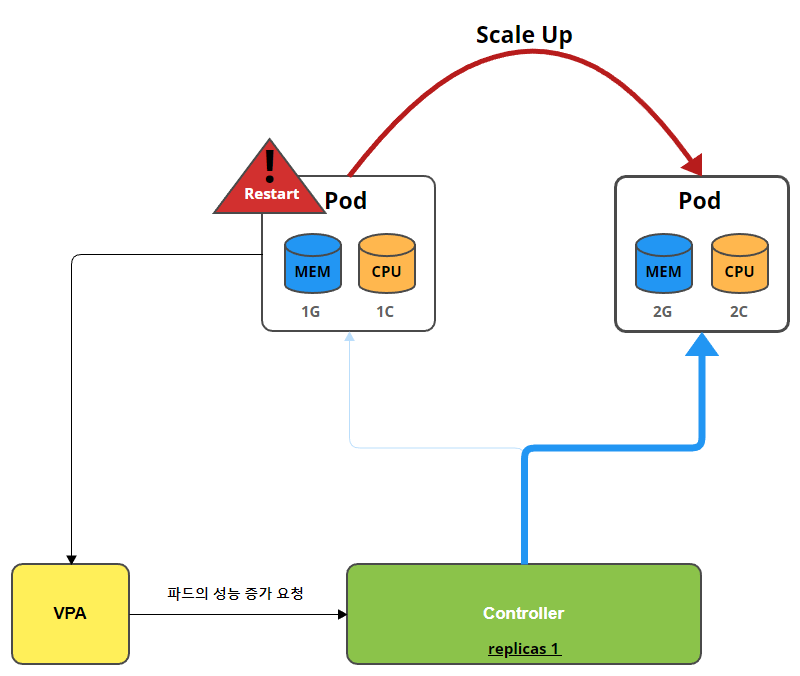
- 파드의 리소스를 감시하여, 파드의 리소스가 부족한 경우 파드를 Restart하여, 파드의 성능을 증가
-
CA(Cluster Autoscaler)
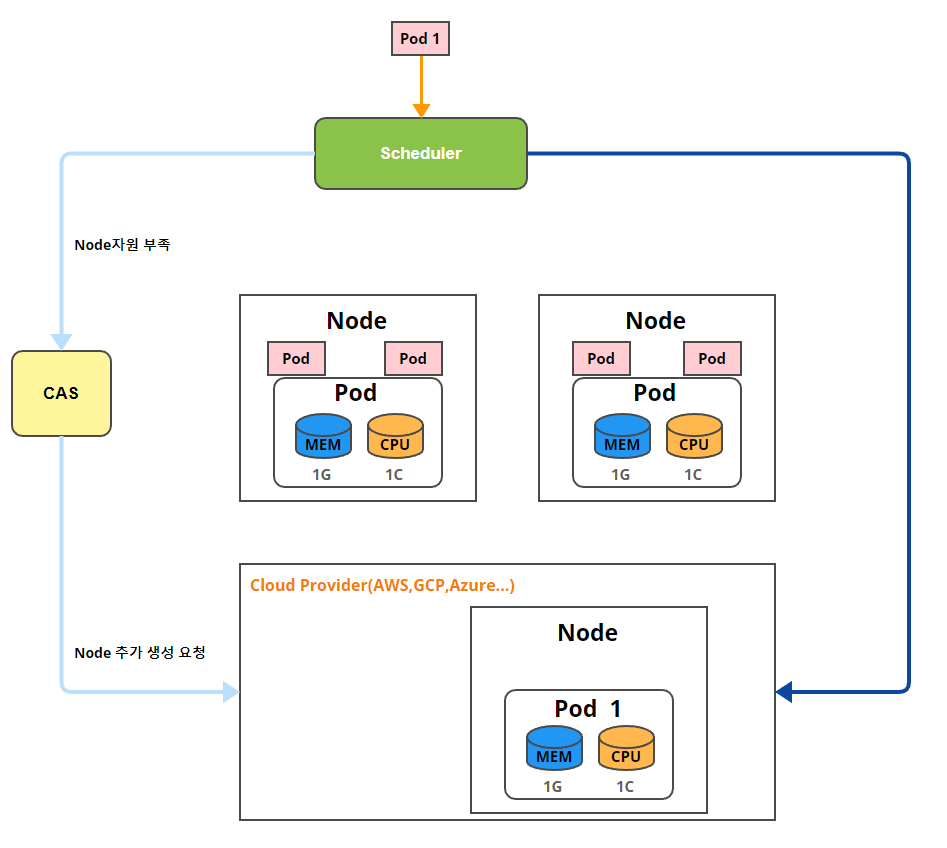
- 사용자가 요청한 Pod의 자원량보다 현재 Cluster의 자원이 부족한 경우 노드 증가
- Cluster Autoscaler는 현재 사용 중인 자원 기반으로 동작하지 않음
- 따라서 Pod의 부하가 아무리 높더라도 요청한 자원량 이 없다면 Node가 증가하지 않음.
HPA - Horizontal Pod Autoscaler
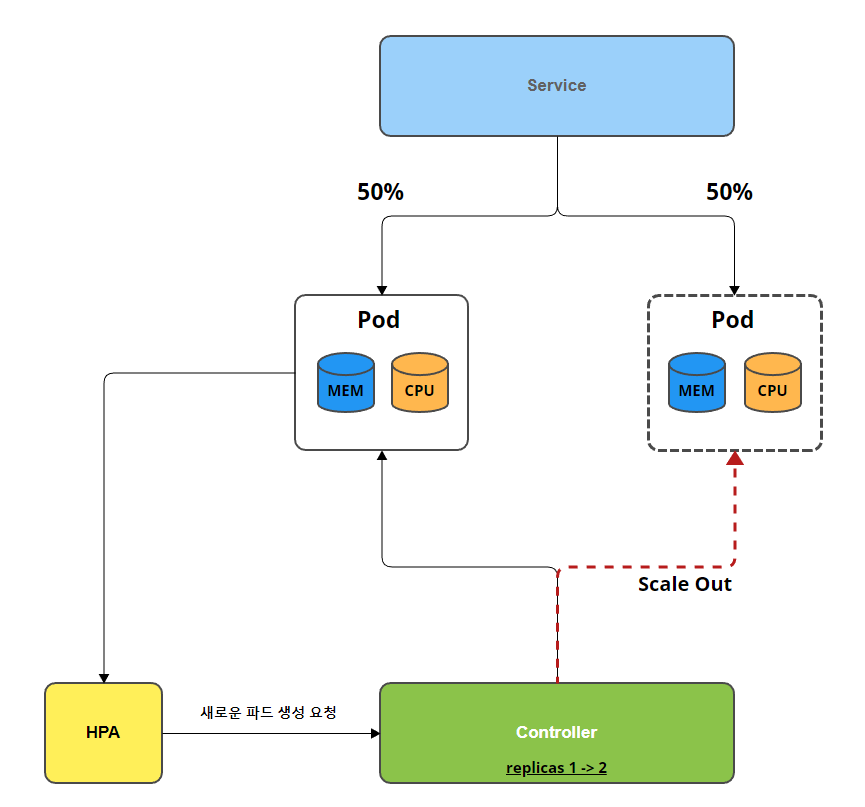
php-apache 서버를 올려서 HPA의 작동을 확인해보겠습니다.
-
php-apache.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: php-apache spec: selector: matchLabels: run: php-apache template: metadata: labels: run: php-apache spec: containers: - name: php-apache image: registry.k8s.io/hpa-example ports: - containerPort: 80 resources: limits: cpu: 500m requests: cpu: 200m --- apiVersion: v1 kind: Service metadata: name: php-apache labels: run: php-apache spec: ports: - port: 80 selector: run: php-apache -
php-apache 서버 생성
curl -s -O https://raw.githubusercontent.com/kubernetes/website/main/content/en/examples/application/php-apache.yaml cat php-apache.yaml | yh **kubectl apply -f php-apache.yaml** # 확인 kubectl exec -it deploy/php-apache -- **cat /var/www/html/index.php => <이 코드는 제곱근 연산을 1000000번 반복하여 $x의 값을 증가>** ... # 접속 테스트 PODIP=$(kubectl get pod -l run=php-apache -o jsonpath={.items[0].status.podIP}) curl -s $PODIP; echo -
HPA 생성
# HPA 생성 kubectl autoscale deployment php-apache **--cpu-percent=50** --min=1 --max=10 **kubectl describe hpa** # HPA 설정 확인 apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: php-apache namespace: default spec: maxReplicas: 10 metrics: - resource: name: cpu target: averageUtilization: 50 type: Utilization type: Resource minReplicas: 1 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache -
부하테스트
# 반복 접속 1 (파드1 IP로 접속) >> 증가 확인 후 중지 while true;do curl -s $PODIP; sleep 0.5; done # 반복 접속 2 (서비스명 도메인으로 접속) >> 증가 확인(몇개까지 증가되는가? 그 이유는?) 후 중지 >> **중지 5분 후** 파드 갯수 감소 확인 # Run this in a separate terminal # so that the load generation continues and you can carry on with the rest of the steps kubectl run -i --tty load-generator --rm --image=**busybox**:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done" -
결과
maxReplicas를 10개로 지정했으므로 총 10개까지 올라갈 것 이라고 예상했지만, 총 6개까지만 pod가 증가가 된것을 확인할 수 있다.
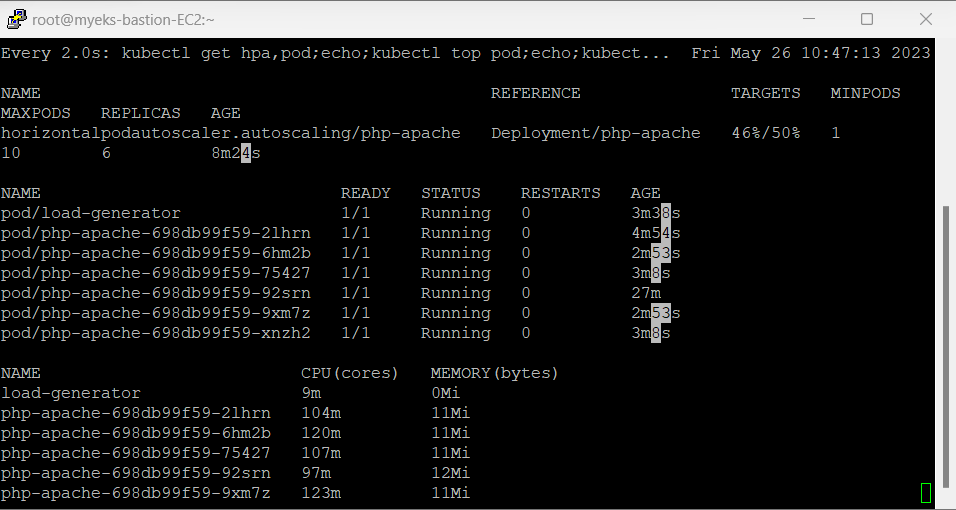
그 이유는 CPU 활용률이 총 50%이상일 때 pod가 Scale out이 되는데, 6개로 pod가 늘어난 이후 CPU 활용률이 50% 미만으로 유지되기 때문에 6개까지만 생성된 것을 확인할 수 있다.
부하를 중단하면, 5분 정도 후에 파드가 모두 사라지는 을 확인할 수 있었다.
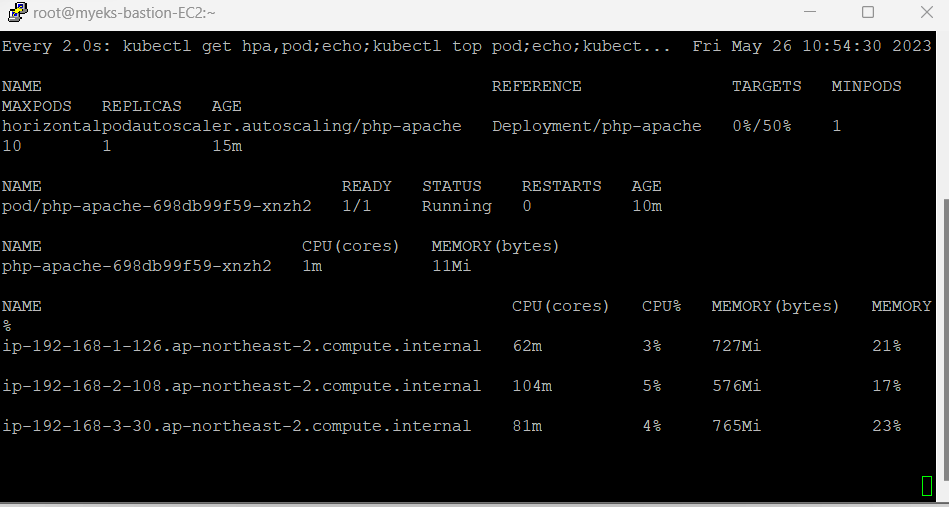
- 그라파나 모니터링
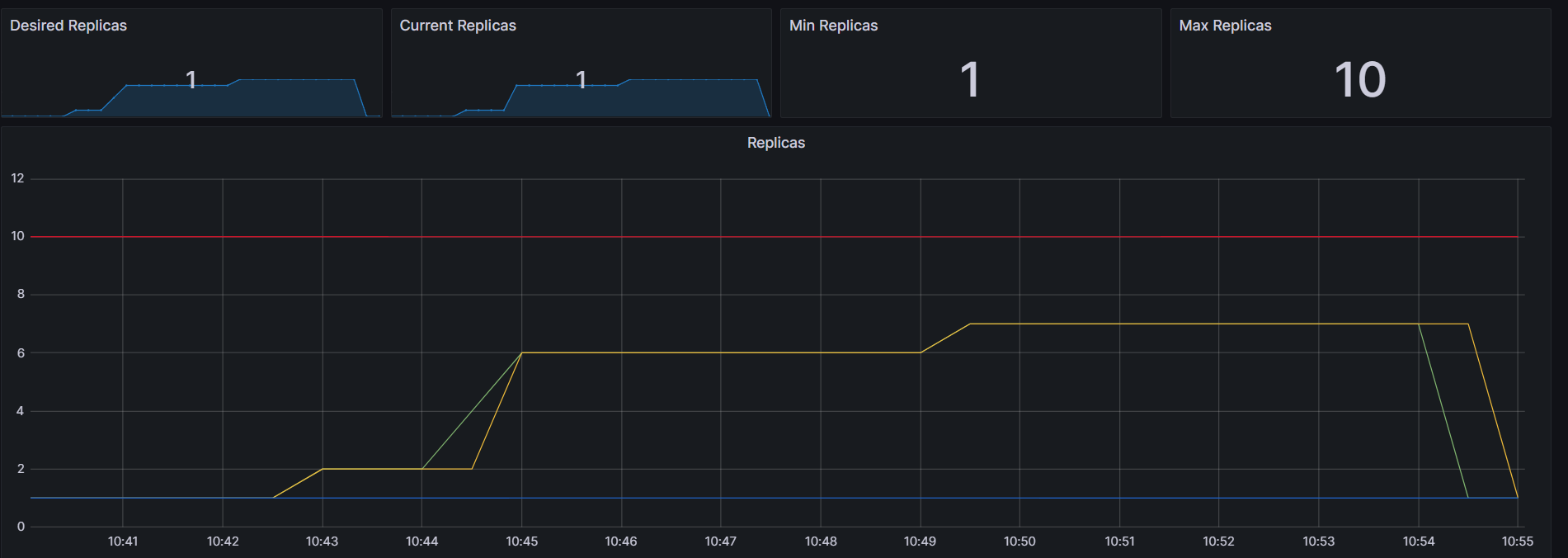
- 그라파나 모니터링
KEDA - Kubernetes based Event Driven Autoscaler
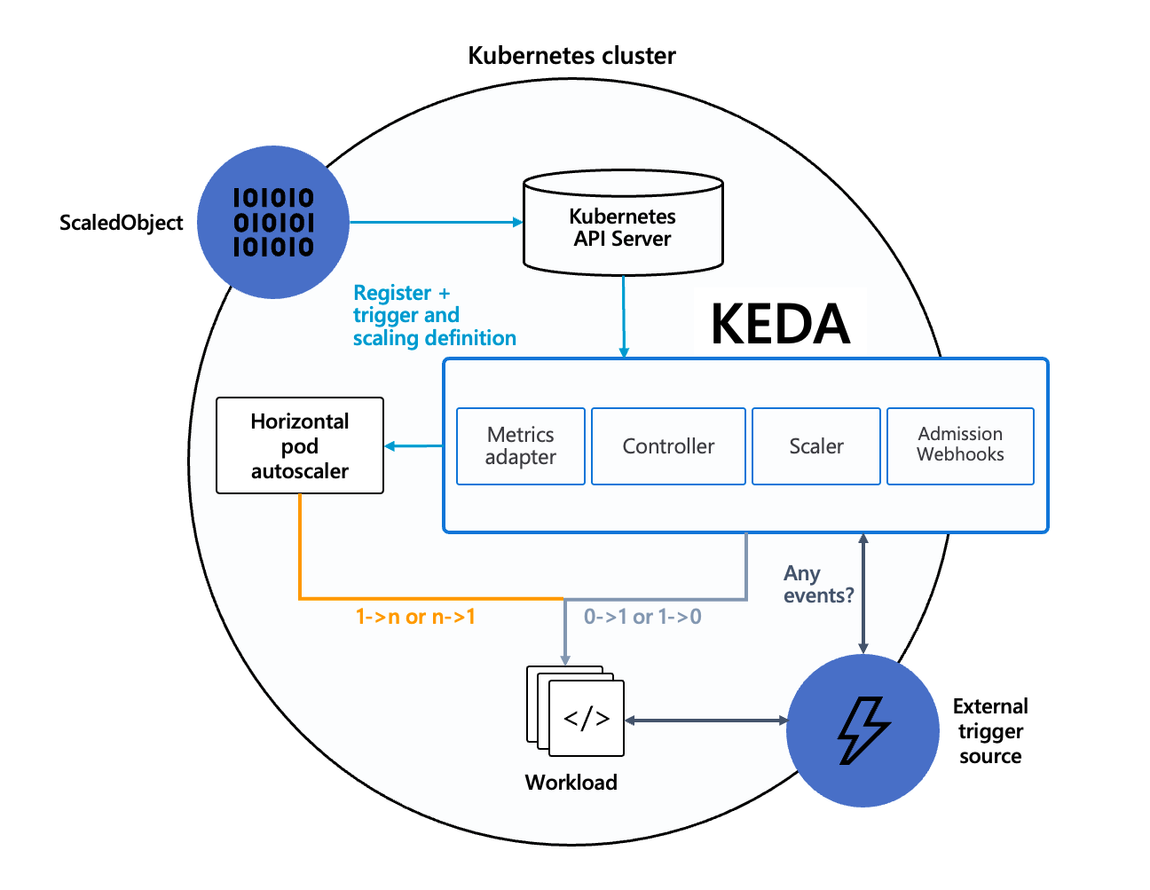
기존의 HPA(Horizontal Pod Autoscaler)는 리소스(CPU, Memory) 메트릭을 기반으로 스케일 여부를 결정하지만, 반면에 KEDA는 특정 이벤트를 기반으로 스케일 여부를 결정할 수 있습니다.
- KEDA를 사용하면 처리해야 하는 이벤트 수에 따라 Kubernetes의 모든 컨테이너 확장
- 표준 Kubernetes 구성 요소와 함께 작동
- 특징
- 사용자가 KEDA에 관리를 요청하기 위한 ScaledObject자원을 생성하면, admission에 의해서 검수
- 유효한 자원일 경우 SclaedObject와 KEDA가 관리하는 HPA자원이 자동으로 생성
- KEDA는 애플리케이션 POD들의 개수를 조절하는 스케링 작업을 직접 수행하지 않는다
- 쿠버네티스 HPA를 대체할 목적이 아닌 확장/보조를 목표로 개발
설치를 진행하여 어떻게 동작하는지 확인해보겠습니다.
- KEDA 설치
cat <<EOT > keda-values.yaml
metricsServer:
useHostNetwork: true
**prometheus**:
metricServer:
enabled: true
port: 9022
portName: metrics
path: /metrics
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
operator:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
webhooks:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus webhooks
enabled: true
EOT
kubectl create namespace **keda**
helm repo add kedacore https://kedacore.github.io/charts
helm install **keda** kedacore/keda --version 2.10.2 --namespace **keda -f** keda-values.yaml- KEDA 설치확인
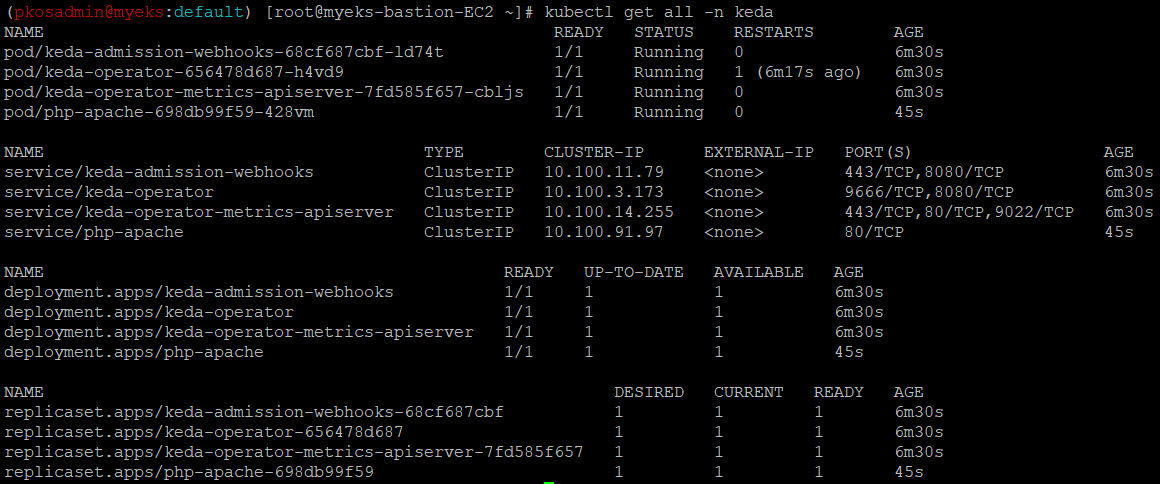
- keda 네임스페이스에 디플로이먼트를 생성
**kubectl apply -f php-apache.yaml -n keda kubectl get pod -n keda** - 관리를 요청하기 위한 ScaledObject자원을 생성(cron)
cat <<EOT > keda-cron.yaml apiVersion: keda.sh/v1alpha1 kind: **ScaledObject** metadata: name: php-apache-cron-scaled spec: minReplicaCount: 0 maxReplicaCount: 2 pollingInterval: 30 cooldownPeriod: 300 **scaleTargetRef**: apiVersion: apps/v1 kind: Deployment name: php-apache **triggers**: - type: **cron** metadata: timezone: Asia/Seoul **start**: 00,15,30,45 * * * * **end**: 05,20,35,50 * * * * **desiredReplicas**: "1" EOT => 이 설정은 스케일링 대상인 php-apache Deployment의 Replica 수를 지속적으로 모니터링하고, 정의된 트리거 이벤트에 따라 자동으로 스케일링을 수행하여 원하는 Replica 수를 유지하도록 합니다. "**desiredReplicas"**는 ****트리거 이벤트 발생 시 설정된 Replica 수를 나타냅니다. 여기서는 "1"로 설정되어 있어 트리거 이벤트 발생 시 스케일링하여 1개의 Replica만 유지하도록 합니다. **kubectl apply -f keda-cron.yaml -n keda** - 확인

VPA
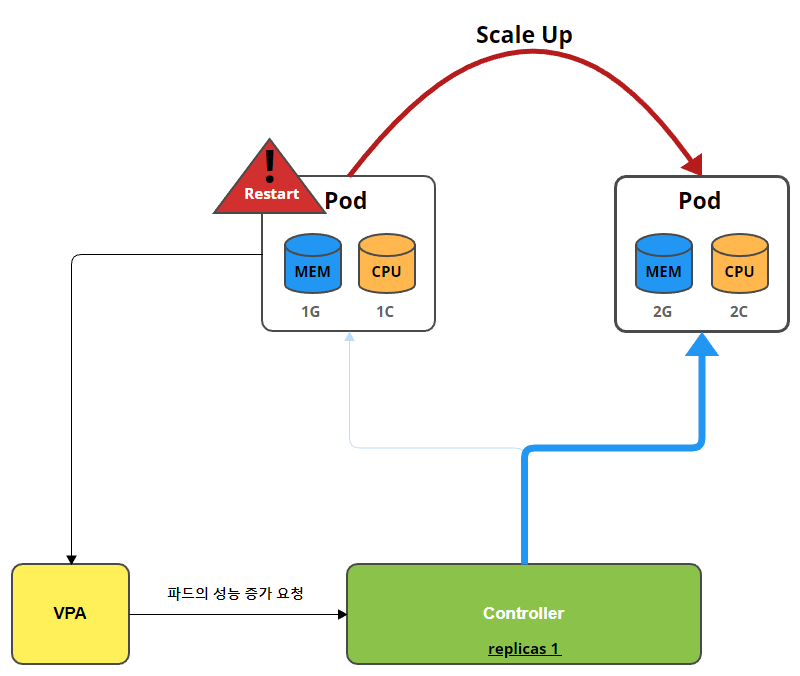
VPA(Vertical Pod Autoscaler)는 사용자가 포드의 컨테이너에 대한 최신 리소스 제한 및 요청을 설정할 필요가 없도록 합니다.
- 구성되면 사용량에 따라 자동으로 요청을 설정하므로 노드에 적절한 스케줄링을 허용하여 각 포드에 적절한 리소스 양을 사용
- 초기 컨테이너 구성에 지정된 제한과 요청 사이의 비율을 유지합니다.
- VPA는 HPA와 같이 사용할 수 없음
- VPA는 pod자원을 최적값으로 수정하기 위해 pod를 재실행
VPA controller EKS에서 제공한 쉘 스크립트를 실행하여 설치를 해보고 어떻게 동작하는지 확인해보겠습니다.
- 설치
# openssl 버전 확인 **openssl version** OpenSSL 1.0.2k-fips 26 Jan 2017 # openssl 1.1.1 이상 버전 확인 **yum install openssl11 -y openssl11 version** OpenSSL 1.1.1g FIPS 21 Apr 2020 # VPA controller 설치 git clone https://github.com/kubernetes/autoscaler.git cd ~/autoscaler/vertical-pod-autoscaler/ tree hack **./hack/vpa-up.sh** - 설치 확인 → VPA 모듈 3개 실행

- 공식 예제 배포
# 공식 예제 배포 cd ~/autoscaler/vertical-pod-autoscaler/ cat examples/hamster.yaml | yh **kubectl apply -f examples/hamster.yaml && kubectl get vpa -w** - VPA 리소스를 조회하여 VPA가 계산한 Pod 최적값 확인 가능

- Pod 리소스 Requestes 확인
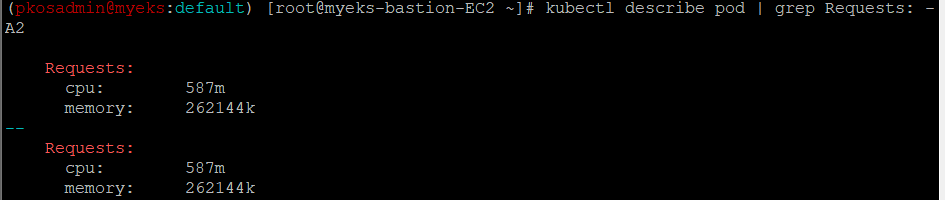
- VPA에 의해 기존 파드가 삭제되고 신규 파드가 생성됨을 확인

KRR
KRR(Kubernetes Resource Recommender)
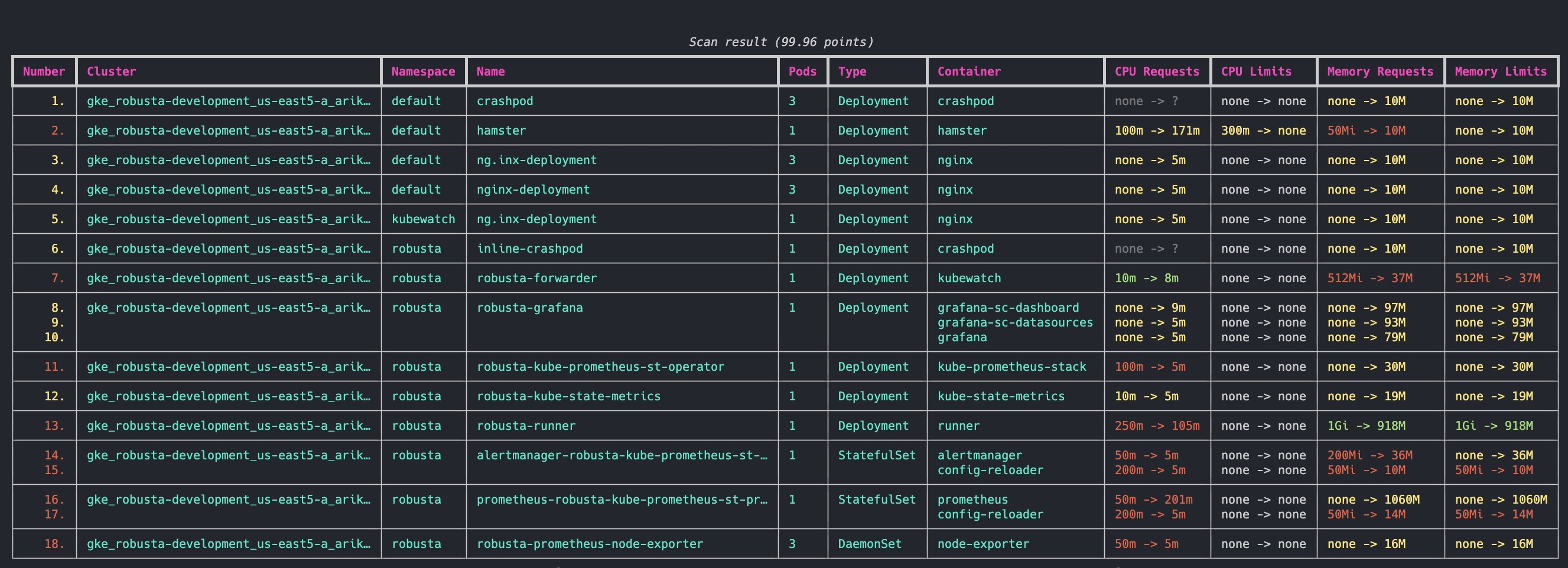
Kubernetes 클러스터에서 리소스 할당을 최적화하기 위한 CLI 도구입니다.
-
Prometheus에서 포드 사용 데이터를 수집하고 CPU 및 메모리에 대한 요청 및 제한을 권장
-
비용을 줄이고 성능을 향상시킵니다.
-
특징
- 에이전트 필요 없음
- Robusta KRR은 로컬 시스템에서 실행되는 CLI 도구.
- 클러스터에서 포드를 실행할 필요가 없습니다.
- Prometheus 통합
- 내장된 Prometheus 쿼리를 사용하여 리소스 사용 데이터를 수집
- 에이전트 필요 없음
-
VPA와 차이점
특징🛠️ 로부스타 KRR🚀 쿠버네티스 VPA🌐 리소스 권장 사항💡 ✅CPU/메모리 요청 및 제한 ✅CPU/메모리 요청 및 제한 설치 위치🌍 ✅클러스터 내부에 설치할 필요가 없으며 클러스터에 연결된 자신의 장치에서 사용할 수 있습니다. ❌클러스터 내부에 설치해야 함 워크로드 구성🔧 ✅각 워크로드에 대해 VPA 개체를 구성할 필요가 없습니다. ❌워크로드마다 VPA 개체 구성이 필요합니다. 즉각적인 결과⚡ ✅결과를 즉시 얻음(프로메테우스가 실행 중인 경우) ❌데이터 수집 및 권장 사항 제공에 시간 필요 보고📊 ✅자세한 CLI 보고서 ❌지원되지 않음 확장성🔧 ✅몇 줄의 Python으로 나만의 전략 추가 ⚠️제한된 확장성 맞춤 측정항목📏 🔄향후 버전에서 지원 ❌지원되지 않음 커스텀 리소스🎛️ 🔄향후 버전에서 지원(예: GPU) ❌지원되지 않음 설명 가능성📖 🔄향후 버전에서 지원(Robusta에서 추가 그래프를 보내드립니다) ❌지원되지 않음 자동 확장🔀 🔄향후 버전에서 지원 ✅추천 자동 적용 -
설치방법
-
설치오류..
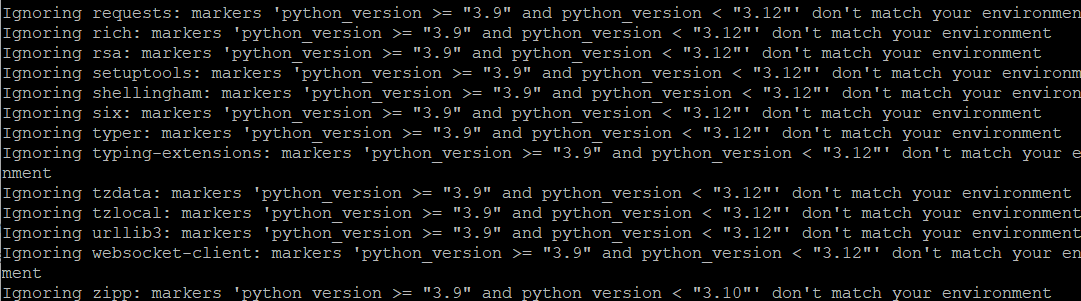
파이썬을 3.9이상만 이용이 가능해서 업그레이드를 시도했지만 계속된 실패로 설치를 하지 못했습니다.. ㅠ
-
CA - Cluster Autoscaler
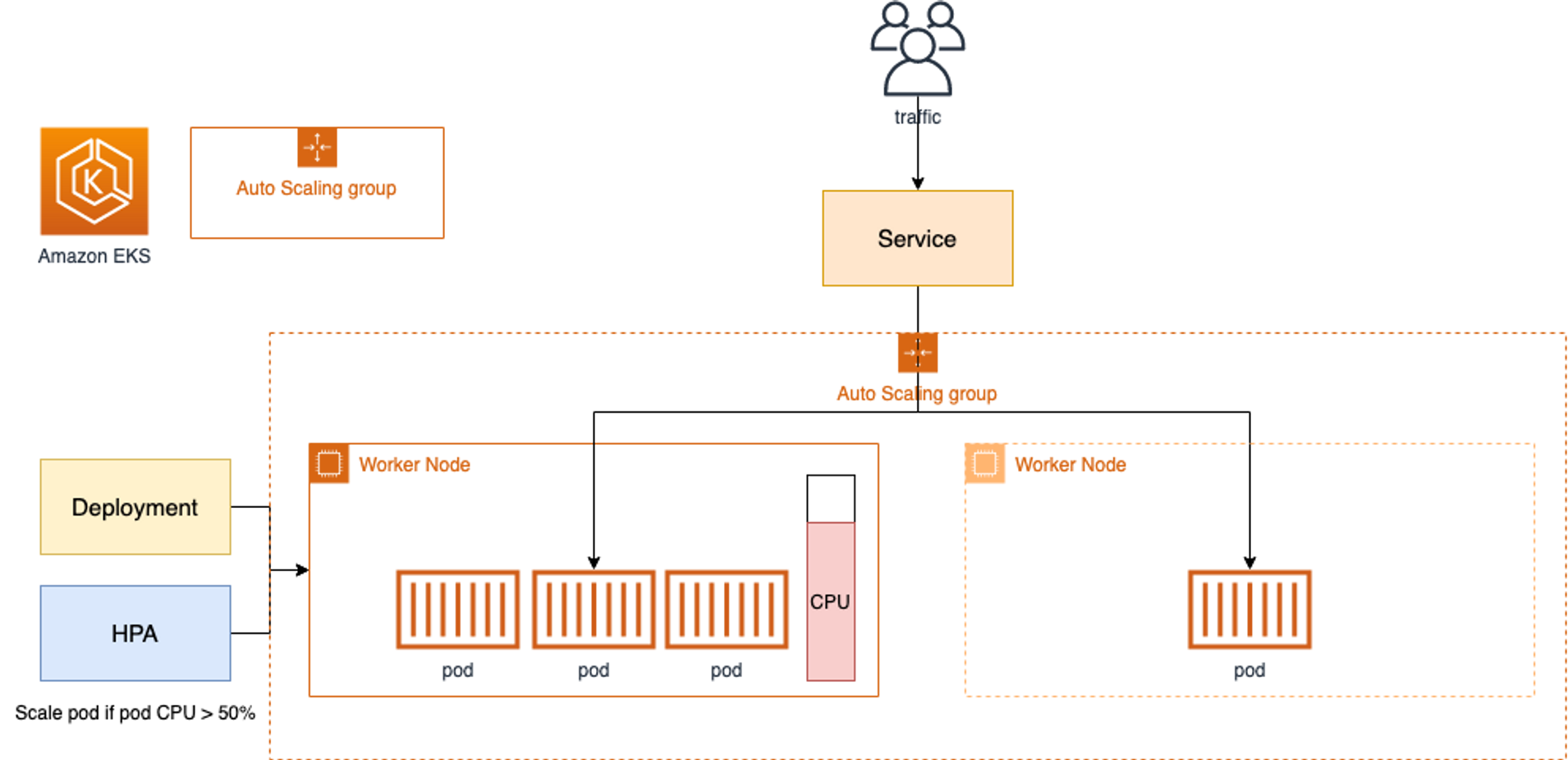
Cluster Autoscaler는 Amazon EC2 Auto Scaling 그룹을 활용하여 노드 그룹을 관리합니다.
- 일반적으로
Deployment에서 실행됩니다 - Cluster Autoscaler(CA)는 pending 상태인 파드가 존재할 경우, 워커 노드를 스케일 아웃합니다.
- 특정 시간을 간격으로 사용률을 확인하여 스케일 인/아웃을 수행합니다. 그리고 AWS에서는 Auto Scaling Group(ASG)을 사용하여 Cluster Autoscaler를 적용합니다.
CA를 설정하기 전 EKS 노드(EC2)에서 아래 태그가 들어가있는지 확인을 합니다.
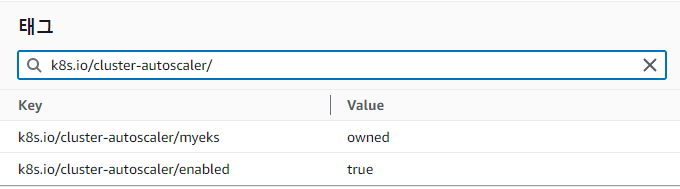
- Key: k8s.io/cluster-autoscaler/myeks 와 Value: owned
- CA가 해당 리소스를 소유하고 있음을 표시
- Key: k8s.io/cluster-autoscaler/enabled 와 Value: 'true'
- CA가 현재 활성화되어 있는 상태
Auto Scaling Group(ASG)을 사용하여 Cluster Autoscaler를 적용하므로 현재 ASG 정보를 확인해보겠습니다.
**aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table**
ASG의 max사이즈를 6개로 수정하겠습니다.
**export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 6
#확인
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table**
그리고 CA를 배포하겠습니다.
# 배포 : Deploy the Cluster Autoscaler (CA)
curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
sed -i "s/<YOUR CLUSTER NAME>/$CLUSTER_NAME/g" cluster-autoscaler-autodiscover.yaml
kubectl apply -f cluster-autoscaler-autodiscover.yaml
# (옵션) cluster-autoscaler 파드가 동작하는 워커 노드가 퇴출(evict) 되지 않게 설정
kubectl -n kube-system annotate deployment.apps/cluster-autoscaler cluster-autoscaler.kubernetes.io/safe-to-evict="false"CA의 작동을 확인하기 위해서 샘플 앱을 배포하고 갯수를 늘려보겠습니다.
-
현재 node 수

-
샘플 앱 배포 및 scale out
cat <<EoF> nginx.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-to-scaleout spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: service: nginx app: nginx spec: containers: - image: nginx name: nginx-to-scaleout resources: limits: cpu: 500m memory: 512Mi requests: cpu: 500m memory: 512Mi EoF # 배포 및 확인 kubectl apply -f nginx.yaml kubectl get deployment/nginx-to-scaleout #scale out the replicaset to 15 kubectl scale --replicas=15 deployment/nginx-to-scaleout && date -
현재 노드 수
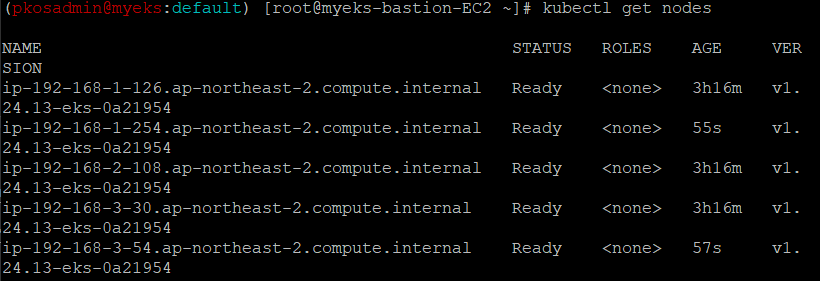

- 2개가 추가로 생성 된 것을 확인할 수 있다.
-
Deployment를 삭제하여 노드 갯수가 축소되는지 확인
# 디플로이먼트 삭제 kubectl delete -f nginx.yaml && date-
삭제 시작

-
삭제완료
노드가 완전히 축소되는데 걸린 시간은 약 11분이 걸렸습니다.
스케일링 속도가 느린 것을 확인할 수 있습니다.
-
CA 문제점
- 하나의 자원에 대해 두군데 (AWS ASG vs AWS EKS)에서 각자의 방식으로 관리
- 관리 정보가 서로 동기화되지 않아 다양한 문제 발생
- EKS에서 노드를 삭제 해도 인스턴스는 삭제 안됨
- 노드 축소 될 때 특정 노드가 축소 되도록 하기 매우 어려움
- pod이 적은 노드 먼저 축소, 이미 드레인 된 노드 먼저 축소
- 특정 노드를 삭제 하면서 동시에 노드 개수를 줄이기 어려움
- 줄일때 삭제 정책 옵션이 다양하지 않음
- 특정 노드를 삭제하면서 동시에 노드 개수를 줄이기 어려움
- 폴링 방식이기에 너무 자주 확장 여유를 확인 하면 API 제한에 도달할 수 있음
- 스케일링 속도가 매우 느림
CPA - Cluster Proportional Autoscaler
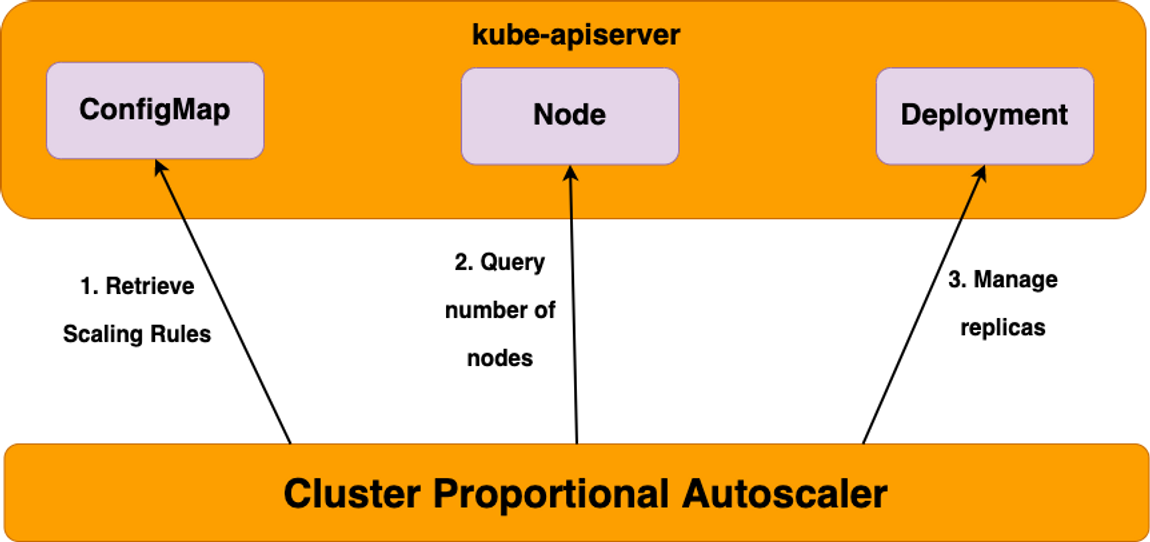
CPA(cluster-proportional-autoscaler)는 노드 개수에 비례(proportional)하여 pod 개수 관리합니다.
- 클러스터 크기에 따라 자동 확장되어야 하는 애플리케이션에 적합
CPA helm 차트를 추가해보겠습니다.
- CPA는 규칙이 설정되어있지 않으면 helm 차트가 릴리즈가 되지 않습니다!
# helm 차트 추가 helm repo add cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler helm repo update # CPA규칙을 설정하고 helm차트를 릴리즈 필요 helm upgrade --install cluster-proportional-autoscaler cluster-proportional-autoscaler/cluster-proportional-autoscaler
실습을 진행하기 위해서 nginx deployment를 replica 1로 설정하여 배포하겠습니다.
cat <<EOT > cpa-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
resources:
limits:
cpu: "100m"
memory: "64Mi"
requests:
cpu: "100m"
memory: "64Mi"
ports:
- containerPort: 80
EOT
# 배포
kubectl apply -f cpa-nginx.yaml그리고 CPA의 규칙을 설정합니다. ⇒(helm 차트 values에서 config와 options필드로 설정)
# CPA 규칙 설정
cat <<EOF > cpa-values.yaml
config:
ladder:
nodesToReplicas:
- [1, 1]
- [2, 2]
**- [3, 3]
- [4, 3]**
- [5, 5]
options:
namespace: default
target: "deployment/nginx-deployment"
EOF
- 노드개수 1개 -> pod 1개 실행
- 노드개수 2개 -> pod 2개 실행
- 노드개수 3개 -> pod 3개 실행
- 노드개수 4개 -> pod 3개 실행
- 노드개수 5개 -> pod 5개 실행helm차트를 릴리즈 하여, CPA를 설치해보겠습니다.
helm upgrade --install cluster-proportional-autoscaler -f cpa-values.yaml cluster-proportional-autoscaler/cluster-proportional-autoscaler
현재 node가 3개로 구성되어있으므로 pod도 3개로 구성되어 있는 것을 확인할 수 있습니다.

node를 증가 시켜서 pod도 따라서 증가하는지 확인해보겠습니다.
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 5 --desired-capacity 5 --max-size 5
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table증가한 것을 확인할 수 있습니다.

Karpenter : K8S Native AutoScaler & Fargate
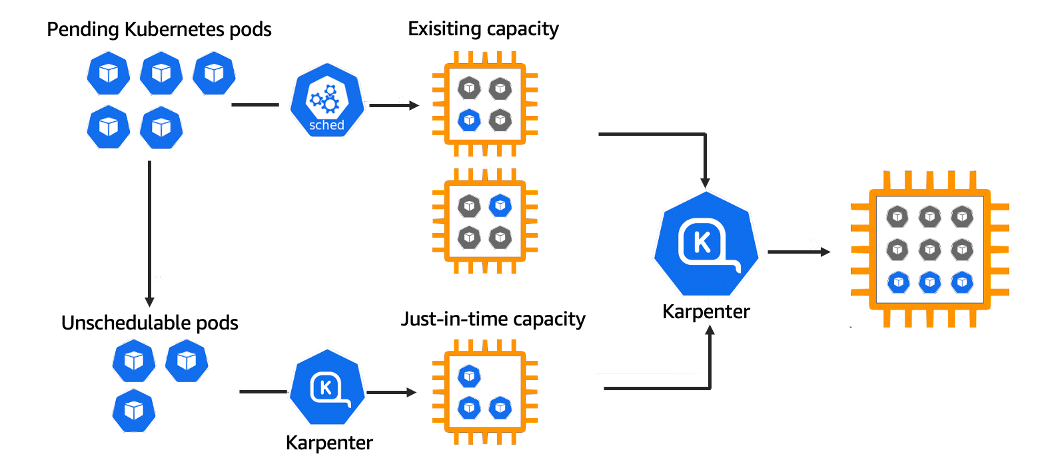
Karpenter는 AWS로 구축된 유연한 오픈 소스의 고성능 Kubernetes 클러스터 오토스케일러입니다.
애플리케이션 로드의 변화에 대응하여 적절한 크기의 컴퓨팅 리소스를 신속하게 실행함으로써 애플리케이션 가용성과 클러스터 효율성을 개선 가능합니다.
- 운영 오버헤드를 최소화
- Karpenter는 프로비저너 (및 노드 템플릿 )를 사용하여 이를 선언적으로 수행하므로Kubernetes API를 통해 사용할 워크로드를 관리하는 것과 동일한 방식으로 사용 가능한 노드 집합을 관리
- **컴퓨팅 비용 절감**
- 워크로드를 통합하고 필요한 노드 수를 줄여 클라우드 비용을 줄이는 측면에서 Cluster Autoscaler보다 더 공격적
- Pod에 적합한 인스턴스 중 가장 저렴한 인스턴스로 증설
- 사용 안하는 노드를 자동으로 정리, 일정 기간이 지나면 노드를 자동으로 만료
- 노드를 줄여도 다른 노드에 충분한 여유가 있다면 자동으로 정리
- 큰 노드 하나가 작은 노드 여러개 보다 비용이 저렴하다면 자동으로 합
- **애플리케이션 가용성 향상**
- Karpenter는 1분 이내에 지속적으로 새 노드를 프로비저닝
- 작동방식
- 모니터링 → (스케줄링 안된 Pod 발견) → 스펙 평가 → 생성 ⇒ Provisioning
- 모니터링 → (비어있는 노드 발견) → 제거 ⇒ Deprovisioning
실습을 진행하면서 Karpenter가 얼마나 좋은지 확인해보겠습니다..
- 설치
# 카펜터 설치를 위한 환경 변수 설정 및 확인 export CLUSTER_ENDPOINT="$(aws eks describe-cluster --name ${CLUSTER_NAME} --query "cluster.endpoint" --output text)" export KARPENTER_IAM_ROLE_ARN="arn:aws:iam::${AWS_ACCOUNT_ID}:role/${CLUSTER_NAME}-karpenter" echo $CLUSTER_ENDPOINT $KARPENTER_IAM_ROLE_ARN # 카펜터 설치 helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter --version ${KARPENTER_VERSION} --namespace karpenter --create-namespace \ --set serviceAccount.annotations."eks\.amazonaws\.com/role-arn"=${KARPENTER_IAM_ROLE_ARN} \ --set settings.aws.clusterName=${CLUSTER_NAME} \ --set settings.aws.defaultInstanceProfile=KarpenterNodeInstanceProfile-${CLUSTER_NAME} \ --set settings.aws.interruptionQueueName=${CLUSTER_NAME} \ --set controller.resources.requests.cpu=1 \ --set controller.resources.requests.memory=1Gi \ --set controller.resources.limits.cpu=1 \ --set controller.resources.limits.memory=1Gi \ --wait - 확인
이제 Provisioner를 생성해야합니다.
Karpenter는 레이블 및 선호도와 Pod 속성을 기반으로 스케줄링 및 프로비저닝 결정을 내립니다.
-
노드를 시작하는 데 사용되는 리소스를 검색하기 위해 해
securityGroupSelector및 를 사용 -
ttlSecondsAfterEmpty값은 빈 노드를 종료하도록 Karpenter를 구성 -
Provisioner를 생성
cat <<EOF | kubectl apply -f - apiVersion: karpenter.sh/v1alpha5 kind: **Provisioner** metadata: name: default **spec**: requirements: - key: karpenter.sh/capacity-type operator: In values: ["**spot**"] limits: resources: cpu: 1000 providerRef: name: default **ttlSecondsAfterEmpty**: 30 --- apiVersion: karpenter.k8s.aws/v1alpha1 kind: **AWSNodeTemplate** metadata: name: default spec: subnetSelector: karpenter.sh/discovery: ${CLUSTER_NAME} securityGroupSelector: karpenter.sh/discovery: ${CLUSTER_NAME} EOF # 확인 kubectl get awsnodetemplates,provisioners
이제 테스트용 pod인 pause 파드를 배포 시켜서 테스트를 해보겠습니다.
#pause pod
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 0
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
**requests:
cpu: 1**
EOF-
배포하기 전 상태
-
오토스케일링 확인 0 → 5
진짜 빠르게 되는 것을 확인할 수 있다.. 신세계..
kubectl scale deployment inflate --replicas 5
- 스팟 인스턴스로 되었는지도 확인해보자.

- 스팟 인스턴스로 되었는지도 확인해보자.
-
deployment 삭제 5→0
kubectl delete deployment inflate정말 빠르게 사라진다.. 한 15초..?