
1. R이란?
- R은 통계 및 데이터 분석을 위한 프로그래밍 언어 및 환경으로, 특히 통계학, 데이터 마이닝, 머신 러닝 등과 관련된 작업에 많이 사용된다.
- 데이터 사이언스 분야에서 자주 쓰이고 데이터 분석에 특화된 언어이다.
- 또한 오픈소스이기 때문에 쉽게 배울 수 있다.
- 오픈 소스
- 데이터 시각화
- 통계 분석 및 모델링
- 데이터 조작 및 전처리
2. R 설치
cran : https://cran.r-project.org/
- Download R for Windows
- base
- Download
- 한국어로 해도 되는데 번역이 매끄럽진 않음
- 쭉 Next해서 설치
- 쭉 Next
- create a quick launch shortcut은 바탕화면에 생성하는거. 체크해주자
3. RStudio 설치
- 다운 받고 util 폴더에 넣어놓자
- 다음으로 쭉 진행해서 설치

- 폰트 사이즈 등 변경
- 커스텀 할 수 있다.
- 버전 관리
- 작업 디렉토리(작업공간은 아니다.) 세팅해주고 apply, ok

- 새로운 프로젝트 생성
- 이게 생겨야한다.
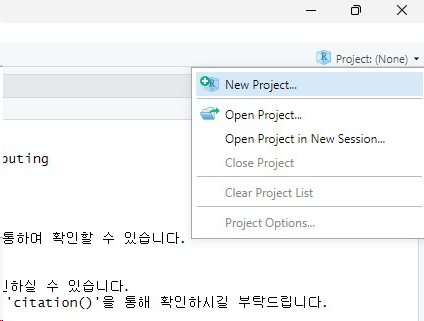
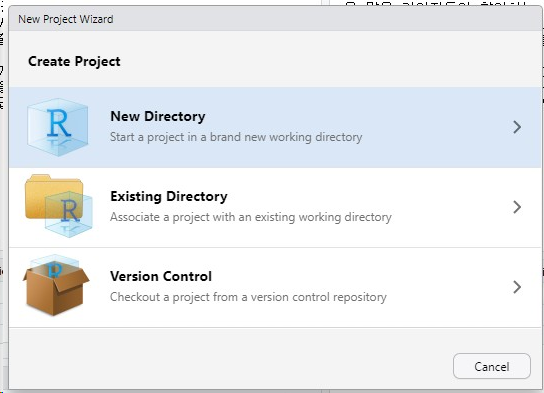
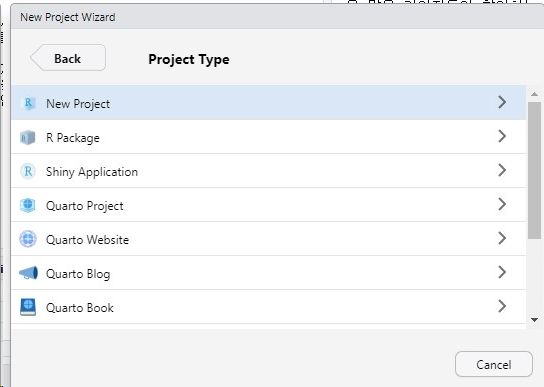
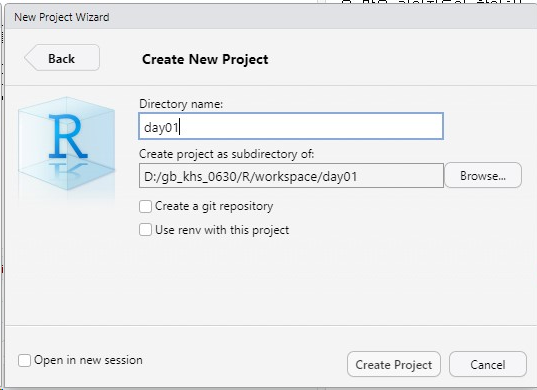
- 프로젝트 환경세팅
- UTF-8로 세팅
- getwd() : 현재 작업 위치 확인
- ctrl + s로 저장하면 R확장자로 저장된다.
- R은 직관적이다.
- 코드를 치고 ctrl + Enter 하면 consol창에 바로 나온다.
4. 숫자
- 정수(Integer), 실수(double)
- 매우 큰 수와 작은 수는 'E', 'e'를 활용하여 표기한다.
- Inf는 무한대, NaN(Not a Number)은 숫자가 아님을 뜻한다.
5. 문자
- 작은 따옴표와 큰 따옴표는 문자의 시작과 끝을 나타낸다.

6. 논리값
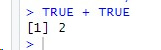
- 참/거짓을 표현하기 위해 TRUE/FALSE를 사용한다.
- 대소문자는 명확히 구분한다.



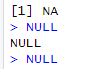
- 값이 비어있는 결측값 표기에는 NA 또는 NULL을 사용한다.
7. 연산자
7-1. 할당연산자
- 특정 객체(Object)에 값을 할당하기 위한 연산자
- "=", "<-" 는 용법의 차이가 거의 없다.
- 화살표 모양의 연산자를 사용하는 경우 화살표의 머리에 따라 할당하는 방향이 다르다.
- '<<-', '->>'는 전역변수 할당시 사용 가능하다.
x = 1 # x에 1을 대입
x <- 1 # x에 1을 대입
1 -> x # x에 1을 대입
X <<- 1 # x에 1을 대입
1 ->> x # x에 1을 대입
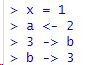
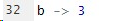
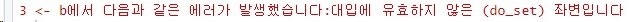
7-2. 산술연산자
- 두 숫자를 연산하기 위해 사용하는 연산자
+ 덧셈
- 뺄셈, 음수부호
* 곱셈
/ 나누기
%/% 몫
%% 나머지
^, ** 지수연산(제곱)7-3. 비교연산자
- 두 자료를 서로 비교하는 참, 거짓 결과를 반환
- 결과는 TRUE, FALSE
- 비교연산자는 기본적으로 1:1 또는 1:n의 비교가 원칙이나, '%in%' 연산자의 경우 n:n의 비교가 가능하다.
== 같다
!= 갖지 않다.
< 미만
> 초과
& 논리(AND)
| 논리 OR)
! 논리부정(
%in% 일치 여부 검사(match)8. 함수
8-1. 기본 함수
- R을 구동한 이후 별도의 조치 없이 사용
- base, status, utils 등 기본 패키지의 함수
8-2. 패키지 함수
- 특정 패키지를 설치 후 불러와야 사용할 수 있는 함수
8-3. 사용자 정의 함수
- 기본 함수, 패키지 함수 등 다양한 요소를 조합해서 사용자가 직접 만든 함수
9. 도움말
- help() : 특정 함수의 설명을 조회하기 위해 사용하는 함수
- ? : help()함수 대응
- help.search() : 특정 단어가 들어간 도움말을 조회할 때 사용하는 함수
- ?? : help.search()함수 대응
10. 패키지
- R의 사용자 정의 함수 또는 별도의 데이터를 묶어놓은 것으로, 라이브러리(lib)라고도 한다.
- 기본 패키지, 공식 패키지, 비공식 패키지가 있다.
- 기본 패키지 : R 설치 시 기본 제공되는 패키지이며, 일부는 R 구동 시 자동으로 불러온다.
- 공식 패키지 : 각종 os에서 동작을 보장하며, RCran 사이트에서 다운로드 가능하다.
- 비공식 패키지 : RCran에서 다운로드 불가능하며, 별도의 웹페이지 접속 또는 패키지 사용이 필요하다.
- 패키지의 함수, 데이터를 사용하기 위해서는 library() 함수를 사용해서 불러오는 것이 일반적이다.
10-1. 패키지 설치하기
- install.packages() 함수를 사용하여 공식 패키지 다운로드
- 압축파일을 바로 설치하는 경우 install.packages() 함수에서 type='source'설정이 필요하다.
- 비공식 패키지 컨택스 다운도드 시 devtools, remotes 패키지를 주로 사용한다.
- 패키지 제거는 remove.packages() 함수로 가능하다.
10-2. 패키지 불러오기
- library() 함수를 사용하여 불러오며 패키지명은 따옴표로 감싸서 명시할 수 있다.
- 패키지가 없다는 에러가 발생할 경우 패키지명을 제대로 입력하지 않았거나 패키지가 설치되지 않은 경우다.
- "::" 기호를 패키지명 뒤에 적게되면 해당 패키지의 함수, 데이터 목록 확인이 수월하며 libarary() 함수없이더 사용 가능하다.
11. 객체
- 보통 데이터를 담아두는 용기에 비유
- 데이터 속성과 구조에 따라 사용할 수 있는 함수가 다르다.
- 대표적으로 1차원 벡터, 메트릭스, 데이터 프레임, 리스트가 존재한다.
- 비어있는 객체도 생성이 가능하다.
11-1. 관련함수
- ls() : 등록된 객체 목록을 출력
- object.size() : 특정 객체의 용량확인 가능
- format() : object.size() 함수의 출력물을 utils 인자를 활용하여 KB, MB등 각 자료 단위로 표기 가능하다.
- rm() : 등록된 객체를 제거하고자 할 때 사용한다.
12. 벡터
12-1. 1차원 백터
- 숫자/문자/논리값 등을 원소로 하는 1차원 객체
- 지정한 순서대로 값이 위치하며 두 개 이상의 서로 다른 속성이 할당되는 경우 하나로 통일한다.
- 문자는 숫자보다 우선시되며, 문자와 숫자를 할당할 경우 숫자도 문자로 자동 변환
- c() 함수로 생성하며 이는 각 원소를 결합한다.
- 1차원 벡터는 각 원소에 별도 이름 지정이 가능하다.
- 'letters'와 'LETTERS'는 사전에 등록되어 있으나 내부 원소 치환 가능하다.
# 벡터
c(1,2,3)
c(1,2,3,"a")
> # 벡터
> c(1,2,3)
[1] 1 2 3
> c(1,2,3,"a")
[1] "1" "2" "3" "a"
>
# 이름 있는 벡터
c(A = 100)
c("A" = 100)
vec = c("A"=100, "B"=200, "C"=300)
> # 이름 있는 벡터
> c(A = 100)
A
100
> c("A" = 100)
A
100
> vec = c("A"=100, "B"=200, "C"=300)
>
# R은 1부터 시작한다.
vec[1]
vec[1:2]
vec[3]
vec[c(1,2)]
> # R은 1부터 시작한다.
> vec[1]
A
100
> vec[1:2]
A B
100 200
> vec[3]
C
300
> vec[c(1,2)]
A B
100 200
>
# 첫번째, 세번째 요소 출력
vec[c(1,3)]
> # 첫번째, 세번째 요소 출력
> vec[c(1,3)]
A C
100 300
>
# 재할당
vec[2] = 'kkk'
vec
vec1 = c(3,4,5)
vec2 = c(8,9)
vec_concat = c(vec1, vec2)
vec_concat
> # 재할당
> vec[2] = 'kkk'
> vec
A B C
"100" "kkk" "300"
>
> vec1 = c(3,4,5)
> vec2 = c(8,9)
> vec_concat = c(vec1, vec2)
> vec_concat
[1] 3 4 5 8 9
>
>
# names
# 1차원 벡터의 각 원소에 할당된 원소의 이름을 확인 또는 변경
vec_new = c("A"=22, "B"=33)
vec_new
names(vec_new)
names(vec_new)[1]
names(vec_new)[c(1:2)]
names(vec_new)[1:2]
names(vec_new)[2] = "user"
vec_new
> # names
> # 1차원 벡터의 각 원소에 할당된 원소의 이름을 확인 또는 변경
> vec_new = c("A"=22, "B"=33)
> vec_new
A B
22 33
>
> names(vec_new)
[1] "A" "B"
> names(vec_new)[1]
[1] "A"
> names(vec_new)[c(1:2)]
[1] "A" "B"
> names(vec_new)[1:2]
[1] "A" "B"
> names(vec_new)[2] = "user"
> vec_new
A user
22 33
>
# seq : from과 to로 시작과 끝을 지정하고, by로 숫자 증분을 지정한다.
?seq()
seq(1,4)
seq(1,4,1)
seq(from=1, to=4, by=1)
seq(from=1, to=4, by=0.5)
> # seq : from과 to로 시작과 끝을 지정하고, by로 숫자 증분을 지정한다.
> ?seq()
> seq(1,4)
[1] 1 2 3 4
> seq(1,4,1)
[1] 1 2 3 4
> seq(from=1, to=4, by=1)
[1] 1 2 3 4
> seq(from=1, to=4, by=0.5)
[1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0
>
# rep() : 1차원 벡터를 지정한 규칙 기반으로 복제
rep(2:4,2)
rep(x=2:4,times=2)
> # rep() : 1차원 벡터를 지정한 규칙 기반으로 복제
> rep(2:4,2)
[1] 2 3 4 2 3 4
> rep(x=2:4,times=2)
[1] 2 3 4 2 3 4
>
rep(2,2:4)
# 인자명까지 같이 전달하면 순서가 바뀌어도 문제없다.
rep(times=2, x=2:4)
> #rep(2,2:4)
> # 인자명까지 같이 전달하면 순서가 바뀌어도 문제없다.
> rep(times=2, x=2:4)
[1] 2 3 4 2 3 4
>
# length : 길이확인
length(c(4,5,8))
length(c('a','b'))
> # length : 길이확인
> length(c(4,5,8))
[1] 3
> length(c('a','b'))
[1] 2
>
letters
letters[1:4]
LETTERS
LETTERS[2:5]
> letters
[1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s" "t" "u" "v" "w" "x"
[25] "y" "z"
> letters[1:4]
[1] "a" "b" "c" "d"
> LETTERS
[1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N" "O" "P" "Q" "R" "S" "T" "U" "V" "W" "X"
[25] "Y" "Z"
> LETTERS[2:5]
[1] "B" "C" "D" "E"
>
# unique : 객체의 중복된 원소를 제거하여 고유한 원소를 남긴다.
vec_dup = c(1,1,3,5,5,6)
length(vec_dup)
unique(vec_dup)
length(vec_dup)
length(unique(vec_dup))
> # unique : 객체의 중복된 원소를 제거하여 고유한 원소를 남긴다.
> vec_dup = c(1,1,3,5,5,6)
> length(vec_dup)
[1] 6
> unique(vec_dup)
[1] 1 3 5 6
> length(vec_dup)
[1] 6
> length(unique(vec_dup))
[1] 413. :
- 1씩 증가, 감소하는 등차수열 생성
# :
3:5
1:4
c(1,2,3,4)
3:-3
1.5:4
> # :
> 3:5
[1] 3 4 5
> 1:4
[1] 1 2 3 4
> c(1,2,3,4)
[1] 1 2 3 4
> 3:-3
[1] 3 2 1 0 -1 -2 -3
> 1.5:4
[1] 1.5 2.5 3.5
> 
개발자