이 글은 MLOps for MLE를 공부하고 정리한 내용입니다.
이번에는 Docker를 이용해 DB 서버를 생성하고, Docker 컨테이너 안에서 계속해서 데이터를 생성하는 서비스를 구축해보자.
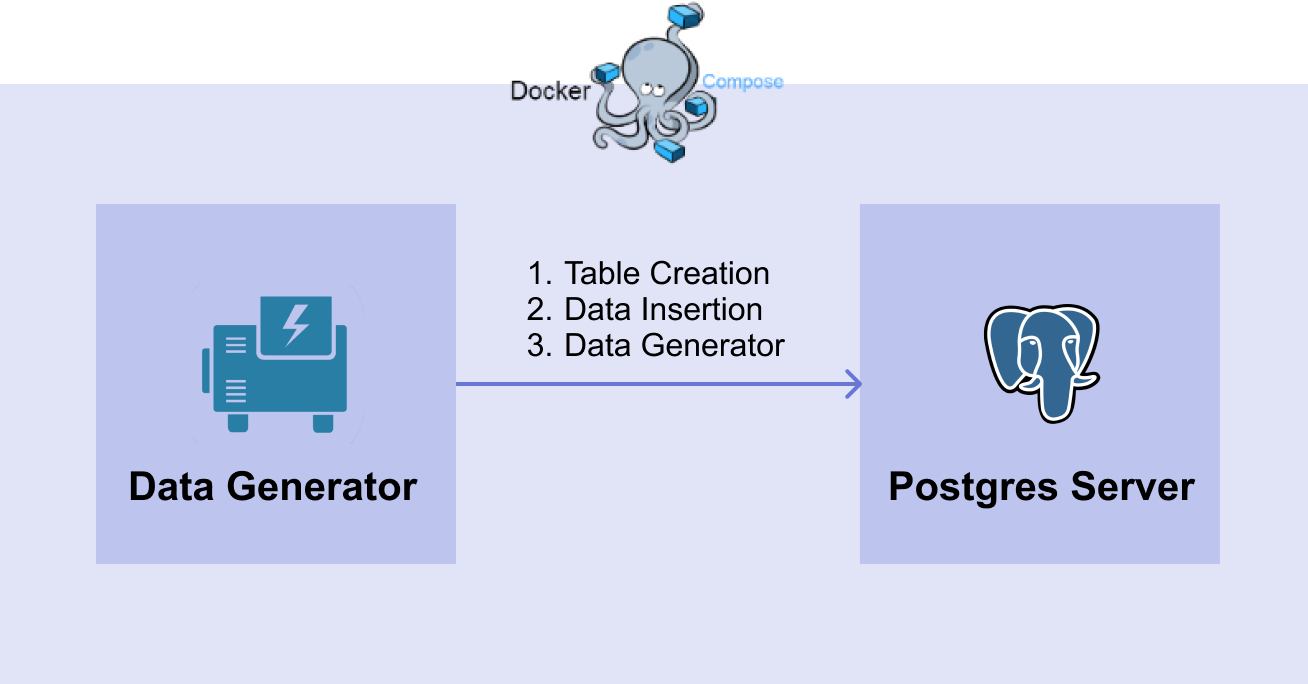
앞으로 진행할 DB Workflow를 그림으로 나타내면 위처럼 그릴 수 있다.
진행 전 Docker가 설치되어 있어야 합니다.
Docker Desktop
위의 링크를 통해 각 OS 에 맞는 Docker desktop 을 설치합니다.
Docker Engine
Ubuntu 에서 desktop 형태가 아닌 engine 형태로 설치하고 싶을 경우, 위의 방법을 통해 설치합니다.
DB 서버
Docker를 이용해 Postgres DB 서버를 생성할 수 있다.
$ docker run -d `
--name postgres-server `
-p 5432:5432 `
-e POSTGRES_USER=root `
-e POSTGRES_PASSWORD=1234 `
-e POSTGRES_DB=mydatabase `
postgres:14.0-d: 컨테이너가 detached 모드로 실행하는 옵션
--name: 컨테이너의 이름을 지정
-p: 컨테이너에서 외부로 노출할 포트 포워딩 (port forwarding)을 설정
-e: 필요한 환경 변수를 설정
POSTGRES_USER -> 유저의 이름
POSTGRES_PASSWORD -> 유저의 비밀번호
POSTGRES_DB -> DB의 이름
postgres:14.0: 사용할 이미지 지정
DB가 정상적으로 생성되었는 지 docker 명령어로 확인해본다.
$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
34fa65e03cd2 postgres:14.0 "docker-entrypoint.s…" About a minute ago Up About a minute 0.0.0.0:5432->5432/tcp postgres-server 다음으로 PostgreSQL DB 서버 접속을 위해 psql를 설치한다.
psql 설치 페이지
설치가 완료되면 DB 서버에 접속한다.
$ set PGPASSWORD=1234
$ psql -h localhost -p 5432 -U root -d mydatabasePGPASSWORD=: 접속할 유저의 비밀번호
-h : 호스트
-p : 포트
-U : 접속할 유저의 이름
-d : DB 의 이름
접속에 성공하면 다음과 같이 출력된다.
psql(17.2, 14.0 (Debian 14.0-1.pgdg110+1) 서버)
도움말을 보려면 "help"를 입력하십시오.테이블 생성
먼저, 필요한 패키지들을 설치한다.
$ pip install pandas psycopg2-binary scikit-learn이제 psycopg2 패키지를 이용해 Python 코드에서 PostgreSQL DB 서버에 접근해보자.
connect 함수를 아래와 같이 작성해 db_connect라는 connector 인스턴스를 생성한다.
import psycopg2
db_connect = psycopg2.connect(
user="root",
password="1234",
host="localhost",
port=5432,
database="mydatabase",
)이제 PostgreSQL DB에 테이블 생성을 위한 query를 작성하면 다음과 같다.
create_table_query = """
CREATE TABLE IF NOT EXISTS iris_data (
id SERIAL PRIMARY KEY,
timestamp timestamp,
sepal_length float8,
sepal_width float8,
petal_length float8,
petal_width float8,
target int
);"""이렇게 작성한 query를 DB에 전달하기 위해 먼저 Connector에서 cursor를 열고, cursor에 query를 전달한다.
cur = db_connect.cursor()
cur.execute(create_table_query)전달된 query를 실행하기 위해 connector에 commit 한다.
db_connect.commit()Cursor의 사용이 끝나면 cursor를 close한다.
cur.close()테이블 생성하는 코드를 하나로 합쳐 함수 하나로 정의하면 다음과 같다.
def create_table(db_connect):
create_table_query = """
CREATE TABLE IF NOT EXISTS iris_data (
id SERIAL PRIMARY KEY,
timestamp timestamp,
sepal_length float8,
sepal_width float8,
petal_length float8,
petal_width float8,
target int
);"""
print(create_table_query)
with db_connect.cursor() as cur:
cur.execute(create_table_query)
db_connect.commit()DB에 query를 보내는 과정은 하나의 프로세스로 처리되도록 묶었다.
with db_connect.cursor() as cur:
cur.execute(create_table_query)
db_connect.commit()이제 작성한 모든 파이썬 코드를 모아서 table_creator.py이라는 이름으로 하나의 파일에 작성한다.
import psycopg2
def create_table(db_connect):
create_table_query = """
CREATE TABLE IF NOT EXISTS iris_data (
id SERIAL PRIMARY KEY,
timestamp timestamp,
sepal_length float8,
sepal_width float8,
petal_length float8,
petal_width float8,
target int
);"""
print(create_table_query)
with db_connect.cursor() as cur:
cur.execute(create_table_query)
db_connect.commit()
if __name__ == "__main__":
db_connect = psycopg2.connect(
user="root",
password="1234",
host="localhost",
port=5432,
database="mydatabase",
)
create_table(db_connect)이제 파이썬 코드를 실행해본다.
$ python table_creator.py CREATE TABLE IF NOT EXISTS iris_data (
id SERIAL PRIMARY KEY,
timestamp timestamp,
sepal_length float8,
sepal_width float8,
petal_length float8,
petal_width float8,
target int
);생성된 테이블을 DB에 접속해 확인해본다.
$ set PGPASSWORD=1234
$ psql -h localhost -p 5432 -U root -d mydatabase\d를 입력하면 생성된 테이블들의 목록을 확인할 수 있다.
$ mydatabase=# \d List of relations
Schema | Name | Type | Owner
--------+------------------+----------+-------
public | iris_data | table | root
public | iris_data_id_seq | sequence | root
(2 rows)iris_data 테이블에 있는 데이터를 확인해본다.
$ mydatabase=# select * from iris_data; id | timestamp | sepal_length | sepal_width | petal_length | petal_width | target
----+-----------+--------------+-------------+--------------+-------------+--------
(0 rows)아직 데이터를 삽입하지 않았기 때문에 (0 row)로 나오는 것을 확인할 수 있다.
데이터 삽입
데이터셋으로 iris 데이터셋을 사용하기 위해 데이터셋을 불러오고 확인해본다.
이전에 생성한 테이블과 column명을 일치시켜야 한다.
import pandas as pd
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True, as_frame=True)
df = pd.concat([X, y], axis="columns")
rename_rule = {
"sepal length (cm)": "sepal_length",
"sepal width (cm)": "sepal_width",
"petal length (cm)": "petal_length",
"petal width (cm)": "petal_width",
}
df = df.rename(columns=rename_rule)
print(df) sepal_length sepal_width petal_length petal_width target
0 5.1 3.5 1.4 0.2 0
1 4.9 3.0 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5.0 3.6 1.4 0.2 0
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 2
146 6.3 2.5 5.0 1.9 2
147 6.5 3.0 5.2 2.0 2
148 6.2 3.4 5.4 2.3 2
149 5.9 3.0 5.1 1.8 2
[150 rows x 5 columns]데이터를 로드해 가져오는 내용도 함수로 만들어본다.
def get_data():
X, y = load_iris(return_X_y=True, as_frame=True)
df = pd.concat([X, y], axis="columns")
rename_rule = {
"sepal length (cm)": "sepal_length",
"sepal width (cm)": "sepal_width",
"petal length (cm)": "petal_length",
"petal width (cm)": "petal_width",
}
df = df.rename(columns=rename_rule)
return dfdata라는 변수에 iris 데이터가 있다고 가정하고 iris_data 테이블에 데이터를 삽입하는 query를 작성해보자.
insert_row_query = f"""
INSERT INTO iris_data
(timestamp, sepal_length, sepal_width, petal_length, petal_width, target)
VALUES (
NOW(),
{data.sepal_length},
{data.sepal_width},
{data.petal_length},
{data.petal_width},
{data.target}
);"""VALUES에 들어있는 순서대로 각 column에 데이터가 저장된다.
데이터에 있는 모든 column들을 확인하고 싶다면 squeeze를 이용하면 편하다.
data = df.sample(1).squeeze()
print(data)sepal_length 5.8
sepal_width 2.7
petal_length 4.1
petal_width 1.0
target 1.0
Name: 67, dtype: float64이제 이전에 작성한 query를 DB에 전달하는 코드와 합쳐 함수로 만들면 다음과 같다.
def insert_data(db_connect, data):
insert_row_query = f"""
INSERT INTO iris_data
(timestamp, sepal_length, sepal_width, petal_length, petal_width, target)
VALUES (
NOW(),
{data.sepal_length},
{data.sepal_width},
{data.petal_length},
{data.petal_width},
{data.target}
);"""
print(insert_row_query)
with db_connect.cursor() as cur:
cur.execute(insert_row_query)
db_connect.commit()데이터를 불러오고 테이블에 데이터를 삽입하는 함수를 모두 모아 data_insertion.py 파일에 저장한다.
import pandas as pd
import psycopg2
from sklearn.datasets import load_iris
def get_data():
X, y = load_iris(return_X_y=True, as_frame=True)
df = pd.concat([X, y], axis="columns")
rename_rule = {
"sepal length (cm)": "sepal_length",
"sepal width (cm)": "sepal_width",
"petal length (cm)": "petal_length",
"petal width (cm)": "petal_width",
}
df = df.rename(columns=rename_rule)
return df
def insert_data(db_connect, data):
insert_row_query = f"""
INSERT INTO iris_data
(timestamp, sepal_length, sepal_width, petal_length, petal_width, target)
VALUES (
NOW(),
{data.sepal_length},
{data.sepal_width},
{data.petal_length},
{data.petal_width},
{data.target}
);"""
print(insert_row_query)
with db_connect.cursor() as cur:
cur.execute(insert_row_query)
db_connect.commit()
if __name__ == "__main__":
db_connect = psycopg2.connect(
user="root",
password="1234",
host="localhost",
port=5432,
database="mydatabase",
)
df = get_data()
insert_data(db_connect, df.sample(1).squeeze())현재 이 코드는 insert_data(db_connect, df.sample(1).squeeze())로 iris 데이터셋의 가장 위 데이터 하나만 삽입하는 것으로 되어있다.
이제 이 파이썬 코드를 이용해 DB의 iris_data 테이블에 데이터를 삽입해보자.
$ python data_insertion.py INSERT INTO iris_data
(timestamp, sepal_length, sepal_width, petal_length, petal_width, target)
VALUES (
NOW(),
6.9,
3.1,
5.4,
2.1,
2.0
);데이터가 정상적으로 삽입되었는 지 확인하기 위해 DB에 접속한다.
$ set PGPASSWORD=1234
$ psql -h localhost -p 5432 -U root -d mydatabaseiris_data 테이블의 모든 데이터를 조회하는 query를 실행한다.
$ mydatabase=# select * from iris_data; id | timestamp | sepal_length | sepal_width | petal_length | petal_width | target
----+----------------------------+--------------+-------------+--------------+-------------+--------
1 | 2025-01-16 07:20:51.776736 | 6.9 | 3.1 | 5.4 | 2.1 | 2
(1 row)데이터가 정상적으로 한 줄이 추가된 것을 확인할 수 있다.
