
DeepSpeed
DeepSpeed
마이크로소프트에서 개발한 오픈 소스 딥러닝 최적화 라이브러리로, 대규모 모델의 학습과 추론을 빠르고 효율적으로 수행할 수 있도록 합니다.
- 효율적인 분산 학습: PyTorch 기반의 경량 래퍼로, 기존 PyTorch 코드를 크게 변경하지 않고도 분산 학습, 혼합 정밀도 학습, 하이퍼파라미터 관리 등을 쉽게 적용할 수 있습니다.
- ZeRO(Zero Redundancy Optimizer): 모델 파라미터, 옵티마이저 상태, 그래디언트 등을 GPU 간에 분산 저장하여 메모리 사용량을 최소화합니다.
- 모델 및 데이터 병렬화: 모델을 여러 GPU에 분산시켜 단일 GPU 메모리 한계를 극복하고, 데이터 병렬 처리를 효율적으로 수행합니다.
- 고속 학습 및 비용 절감: 커널 최적화, 효율적인 통신, 혼합 정밀도 지원 등 다양한 최적화 기법을 통해 학습 속도를 높이고 비용을 절감합니다.
- 대규모 모델 지원: 많은 파라미터를 가진 초대형 모델의 학습이 가능합니다.
구체적인 DeepSpeed 장점들은 아래 링크에서 자세히 확인할 수 있습니다.
DeepSpeed Training Overview and Features
ZeRO(Zero Redundancy Optimizer)
DeepSpeed에서 핵심적인 메모리 최적화 기술로, 대규모 딥러닝 모델 학습에서 GPU 메모리 사용량을 획기적으로 줄여주는 역할을 합니다.
기존 데이터 병렬 처리에서는 각 GPU가 전체 모델의 파라미터, 옵티마이저 상태, 그래디언트를 모두 복제하여 저장합니다.
ZeRO는 파라미터, 옵티마이저 상태, 그래디언트를 각 GPU에 분할해 저장함으로써, 메모리 중복을 없애고 효율성을 극대화합니다.

단계별 최적화
ZeRO는 점진적으로 최적화 단계를 적용할 수 있습니다.
각 단계가 이전 단계의 최적화를 포함하며, 단계가 높아질수록 더 많은 메모리 절감 효과를 얻을 수 있습니다.
(1) ZeRO-1: 옵티마이저 상태 분산(Optimizer State Partitioning)
- 메모리 절감: 최대 4배 감소
- 핵심 원리:
- 옵티마이저 상태를 GPU 수에 따라 분할 저장
- 순전파, 역전파 단계에서는 전체 모델 파라미터를 메모리에 유지
- 최적화 단계에서만 분산 데이터 사용
- 통신 비용: 기본 데이터 병렬 처리와 동일
"zero_optimization": {
"stage": 1
}(2) ZeRO-2: ZeRO-1 + 그래디언트 분산(Gradient Partitioning)
- 메모리 절감: 최대 8배 감소
- 핵심 기술:
- 그래디언트 계산 즉시 reduce-scatter 방식으로 분산 (기존 all-reduce 방식보다 메모리 효율적)
- 중간 결과 캐싱(activation recomputation)을 통해 추가 메모리 최적화
- 통신 최적화:
- 버킷팅(bucketing) 기법으로 통신 횟수 감소
- overlap_comm 옵션으로 통신-계산 병렬 처리
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu"
}
}(3) ZeRO-3: ZeRO-2 + 파라미터 분산(Parameter Partitioning)
- 메모리 절감: 최대 1/N(GPU 수) 만큼 감소
- 주요 기능:
- 필요한 시점에만 파라미터를 동적으로 로드 (on-demand parameter loading)
- CPU 또는 NVMe 디스크로 오프로드 가능 (ZeRO-Infinity)
- 통신 비용: ZeRO-2 대비 약 50% 증가, 하지만 초대규모 모델 학습 가능
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "nvme",
"nvme_path": "/local_nvme"
}
}| 항목 | ZeRO-1 | ZeRO-2 | ZeRO-3 |
|---|---|---|---|
| 분산 대상 | 옵티마이저 상태 | 옵티마이저 상태 + 그래디언트 | 옵티마이저 상태 + 그래디언트 + 파라미터 |
| 메모리 절감 효과 | 최대 4배 | 최대 8배 | 최대 N(GPU 수)배 |
| 통신 오버헤드 | 기본 데이터 병렬 수준 | ZeRO-1과 동일 | ZeRO-2 대비 약 50% 증가 |
| 지원 모델 크기 | 약 100B 파라미터 | 약 500B 파라미터 | 약 1T+ 파라미터 |
단계 선택
- ZeRO-1: 단일 노드 멀티 GPU 환경에서 100B 이하 모델에 적합
- ZeRO-2: 다중 노드 환경에서 500B급 모델 학습에 최적화
- ZeRO-3: 1T(1조) 이상 파라미터 모델 학습에 적합
Offload
GPU 메모리가 부족한 상황에서 모델 학습에 필요한 일부 데이터를 GPU 외부 메모리(CPU RAM 또는 NVMe SSD)로 이전함으로써 메모리 사용량을 줄이고 훨씬 큰 모델 학습을 가능하게 하는 기술입니다.
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu"
},
"offload_param": {
"device": "nvme",
"nvme_path": "/local_nvme"
}
}주요 오프로드 대상
- 옵티마이저 상태: 파라미터 업데이트에 필요한 옵티마이저 관련 정보를 CPU 메모리로 이동
- 그래디언트, 파라미터: 그래디언트와 파라미터까지 SSD로 이동하면 ZeRO-3에서 초대규모 모델도 처리 가능
오프로드 위치 및 특징
| 오프로드 위치 | 장점 | 단점 |
|---|---|---|
| CPU 메모리 | 빠른 접근 속도, 메모리 용량 증가 | GPU, CPU 간 통신 비용 |
| NVMe(SSD) | 수 TB 이상 저장 가능, 초대규모 모델 지원 | 접근 속도 느림, I/O 병목 가능성 |
DeepSpeed 튜토리얼 진행하기
저는 엔비디아 GPU를 가지고 있지 않아 Colab에서 진행하였습니다.
모델은 이전에도 사용한 적 있는 Bllossom/llama-3.2-Korean-Bllossom-3B 모델입니다.
먼저, Colab에 접속해 새 노트를 생성합니다.
노트 생성 후, 런타임 유형을 GPU로 바꿔줍니다.
이제 다음과 같이 코드를 노트북에 작성합니다.
# 기존 bitsandbytes 제거 후 최신 버전 재설치 (8bit 로딩 지원 라이브러리)
!pip uninstall -y bitsandbytes
!pip install -U bitsandbytes
# 주요 학습 및 추적 관련 라이브러리 설치
!pip install -U transformers accelerate peft deepspeed datasets mpi4py mlflow gputil
# 필수 라이브러리 임포트
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer, DataCollatorForLanguageModeling
from datasets import load_dataset
from peft import get_peft_model, LoraConfig, TaskType
import deepspeed
import mlflow
import time
import psutil
import GPUtil
# SQuAD 데이터셋 일부 로드
dataset = load_dataset("squad", split="train[:1000]")
from pprint import pprint
pprint(dataset[0]) # 샘플 출력
# LoRA 설정: 파라미터 효율화 위한 설정
lora_config = LoraConfig(
r=16,
lora_alpha=16,
target_modules=["q_proj", "v_proj"], # Llama 모델의 주요 어텐션 모듈
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# MLflow 실험 경로 설정
mlflow.set_tracking_uri("file:/content/mlruns")
# 실험 이름 지정
mlflow.set_experiment("DeepSpeed_Comparison")
# GPU 메모리 사용량 측정 함수 정의
def get_gpu_memory_usage():
if torch.cuda.is_available():
gpu = GPUtil.getGPUs()[0]
return gpu.memoryUsed
return 0
# 실험 실행 함수 정의
def run_experiment(use_deepspeed: bool):
print(f"실험 시작: use_deepspeed = {use_deepspeed}")
# GPU 메모리 초기화
torch.cuda.empty_cache()
# 모델 및 토크나이저 로드
model_id = "Bllossom/llama-3.2-Korean-Bllossom-3B"
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True, # 8bit로 로드하여 메모리 절약
torch_dtype=torch.float16,
device_map="auto" # 자동으로 GPU 할당
)
model = get_peft_model(model, lora_config) # LoRA 적용
# 데이터 전처리 함수 정의
def preprocess(examples):
inputs = []
for question, answer in zip(examples["question"], examples["answers"]):
answer_text = answer["text"][0] if answer["text"] else "정답 없음"
full_text = f"질문: {question}\n답변: {answer_text}"
inputs.append(full_text)
return tokenizer(inputs, truncation=True, padding="max_length", max_length=512)
# 패딩 토큰 설정 및 전처리 적용
tokenizer.pad_token = tokenizer.eos_token
tokenized_dataset = dataset.map(preprocess, batched=True)
tokenized_dataset.set_format(type="torch", columns=["input_ids", "attention_mask"])
# 학습 배치 및 설정
per_device_batch_size = 2
gradient_accum_steps = 4
# DeepSpeed 설정
ds_config = {
"train_batch_size": per_device_batch_size * gradient_accum_steps,
"zero_optimization": {
"stage": 2,
"offload_optimizer": {"device": "cpu"}, # 옵티마이저 상태 CPU로 오프로드
"contiguous_gradients": True
},
"fp16": {"enabled": True}, # FP16 연산 사용
"gradient_accumulation_steps": gradient_accum_steps
} if use_deepspeed else None
# 학습 인자 설정
training_args = TrainingArguments(
output_dir=f"./results_{'ds' if use_deepspeed else 'no_ds'}",
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accum_steps,
learning_rate=2e-4,
num_train_epochs=5,
fp16=True,
logging_steps=50,
save_strategy="epoch",
optim="adamw_torch",
report_to="none", # 로그는 MLflow로만
deepspeed=ds_config # DeepSpeed 설정 전달
)
# Trainer 구성
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
data_collator=DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False) # MLM 비활성화 (Causal LM)
)
# MLflow 실험 기록
with mlflow.start_run(run_name=f"{'With' if use_deepspeed else 'Without'}_DeepSpeed"):
mlflow.log_param("use_deepspeed", use_deepspeed)
mlflow.log_param("batch_size", per_device_batch_size)
mlflow.log_param("gradient_accumulation_steps", gradient_accum_steps)
mlflow.log_param("learning_rate", 2e-4)
start_memory = get_gpu_memory_usage() # 시작 시점 GPU 메모리 사용량
start = time.time() # 학습 시작 시간
train_result = trainer.train() # 학습 실행
end = time.time() # 학습 종료 시간
end_memory = get_gpu_memory_usage() # 종료 시점 GPU 메모리 사용량
# 지표 기록
metrics = train_result.metrics
metrics["train_runtime_sec"] = end - start
metrics["step_runtime_sec"] = metrics["train_runtime_sec"] / metrics["total_flos"] if "total_flos" in metrics else -1
metrics["gpu_memory_used_mb"] = end_memory - start_memory
mlflow.log_metrics(metrics)
# 모델 및 결과 저장
output_dir = f"./model_output_{'ds' if use_deepspeed else 'no_ds'}"
trainer.save_model(output_dir)
mlflow.log_artifacts(output_dir)
# 실험 실행: DeepSpeed OFF -> ON 순서로 두 번 실행
run_experiment(use_deepspeed=False)
run_experiment(use_deepspeed=True)
# MLflow 실험 로그 압축 저장
!zip -r mlruns.zip /content/mlruns코드를 실행하고 나면 다음처럼 mlruns.zip 파일이 생성됩니다.
오른쪽 옵션 버튼을 눌러 다운로드하고 압축을 풀어줍니다.

터미널로 압축 해제한 폴더로 이동한 후, 아래 명령어로 MLflow 웹 서버를 실행합니다.
mlflow ui --backend-store-uri mlruns --host 0.0.0.0 --port 5050localhost:5050에 접속하여 실험이 정상적으로 기록되었는지 확인합니다.
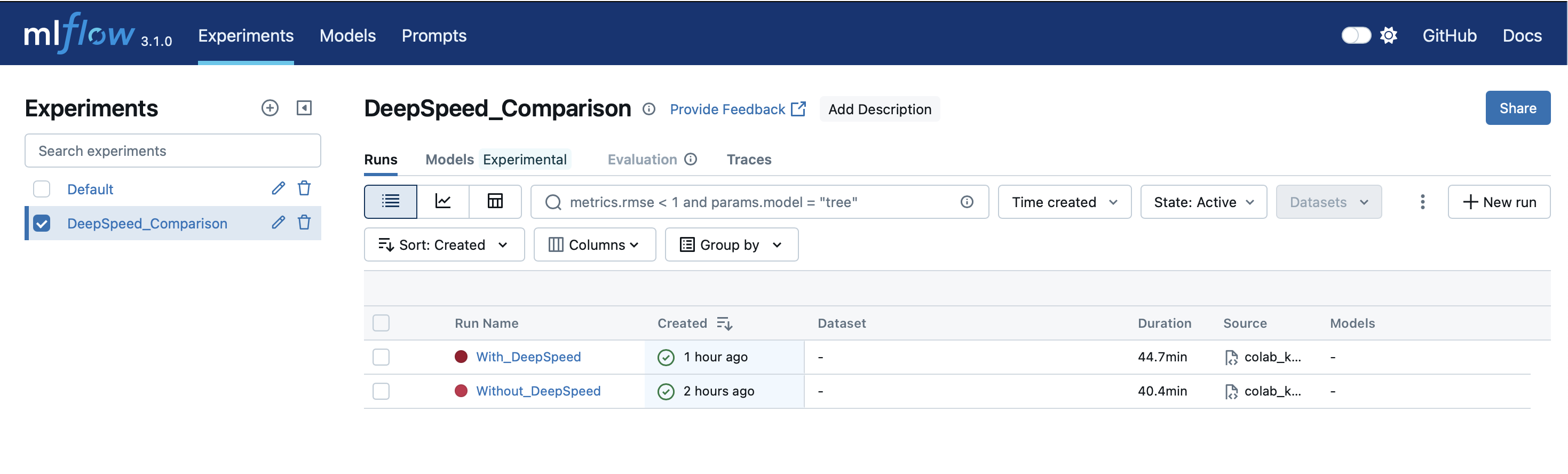
두 Run을 모두 선택하고 Compare 버튼을 눌러 비교해봅니다.
메트릭을 보면 기록된 정보들을 확인할 수 있습니다.
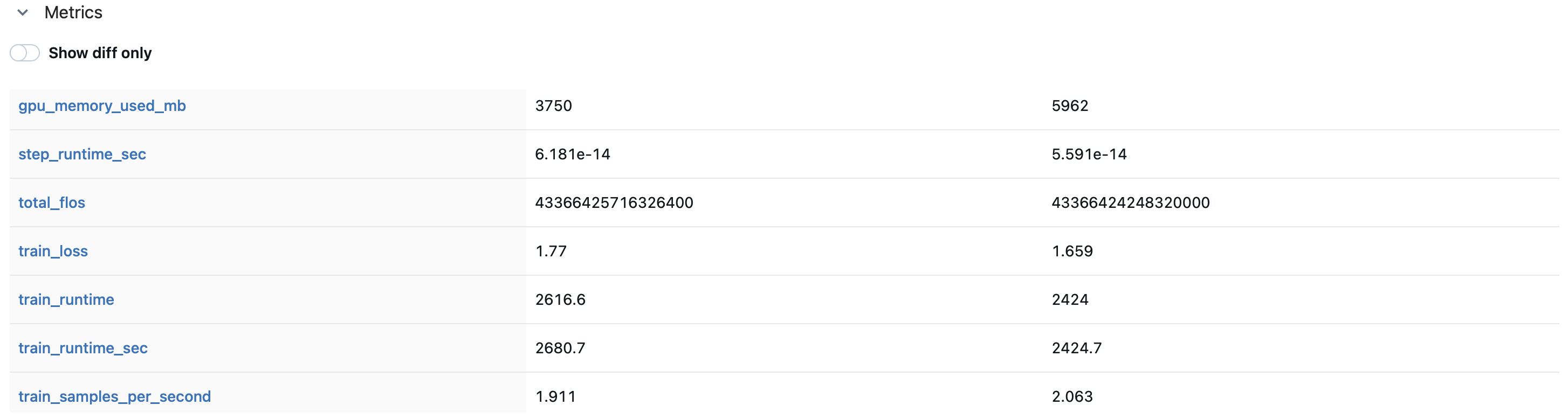
GPU 메모리 사용량
| use_deepspeed | True | False |
|---|---|---|
| gpu_memory_used_mb | 3750 | 5962 |
GPU 메모리 사용량은 DeepSpeed를 사용했을 때 확실히 메모리 사용량이 감소한 것을 확인할 수 있습니다.
학습 속도
| use_deepspeed | True | False |
|---|---|---|
| train_runtime_sec | 2680.7 | 2424.7 |
| train_samples_per_second | 1.911 | 2.063 |
| train_steps_per_second | 0.239 | 0.258 |
학습 속도를 살펴보면 오히려 DeepSpeed가 사용되었을 때 다소 떨어지는 것을 확인할 수 있습니다.
그런데 왜 오히려 DeepSpeed를 적용했을 때 속도가 느려졌을까요?
(1) 모델 크기
DeepSpeed는 초대형 모델에서 메모리 최적화 및 학습 속도 개선 효과를 극대화됩니다. 학습에 사용한 모델은 이미 경량화된 3B 모델이기 때문에 오히려 DeepSpeed가 내부적으로 사용하는 분산 처리와 상태 관리 등의 오버헤드가 오히려 성능 저하 요인이 될 수 있습니다.
(2) 데이터셋 크기
SQuAD 데이터셋 중 train[:1000] 만을 사용하여 실제 학습 반복 횟수가 적고 전체 학습 시간이 짧은 실험 환경이었습니다. DeepSpeed는 초기화와 내부 처리 로직에 일정한 시간과 리소스를 요구하는데, 데이터셋이 작을 경우 이 초기 오버헤드가 학습 전체 시간에서 상대적으로 큰 비중을 차지할 수 있습니다.
(3) CPU offloading
현재 이 설정에서는 옵티마이저 상태와 일부 파라미터를 CPU에 오프로딩합니다. GPU 메모리를 줄이는 데 효과적이지만, CPU와 GPU 간 메모리 전송이 자주 발생하면서 오히려 학습 속도가 느려질 수 있습니다.
(4) 8bit 양자화
이미 모델이 8비트로 양자화되어 있어, GPU 메모리 사용량이 줄어든 상태입니다. 여기에 LoRA까지 적용되어 학습 파라미터 수도 적은 상황에서는 DeepSpeed의 추가적인 메모리 최적화 효과가 크지 않게 나타날 수 있습니다.
결론
이번 코드에서는 짧은 시간과 무료 자원만을 사용해 구현했기 때문에 DeepSpeed로 인한 속도 이점은 확인해 볼 수 없었습니다.
더 큰 모델이나 데이터셋을 대상으로 실험 범위를 확장했을 때 속도에서도 향상을 확인할 수 있을 것 같습니다.
