AWS EC2에 구축한 MLOps 서버의 구축 과정에 대한 내용을 작성합니다.
AWS의 프리티어로 제공되는 사양으로는 이 정도 수준의 MLOps 구축에는 한계가 있습니다.
구체적인 학습 코드에 대한 내용보다는 MLOps에 초점을 두고 작성하려고 합니다.
학습 코드에 대한 자세한 설명은 다음 글에서 다룰 예정입니다.
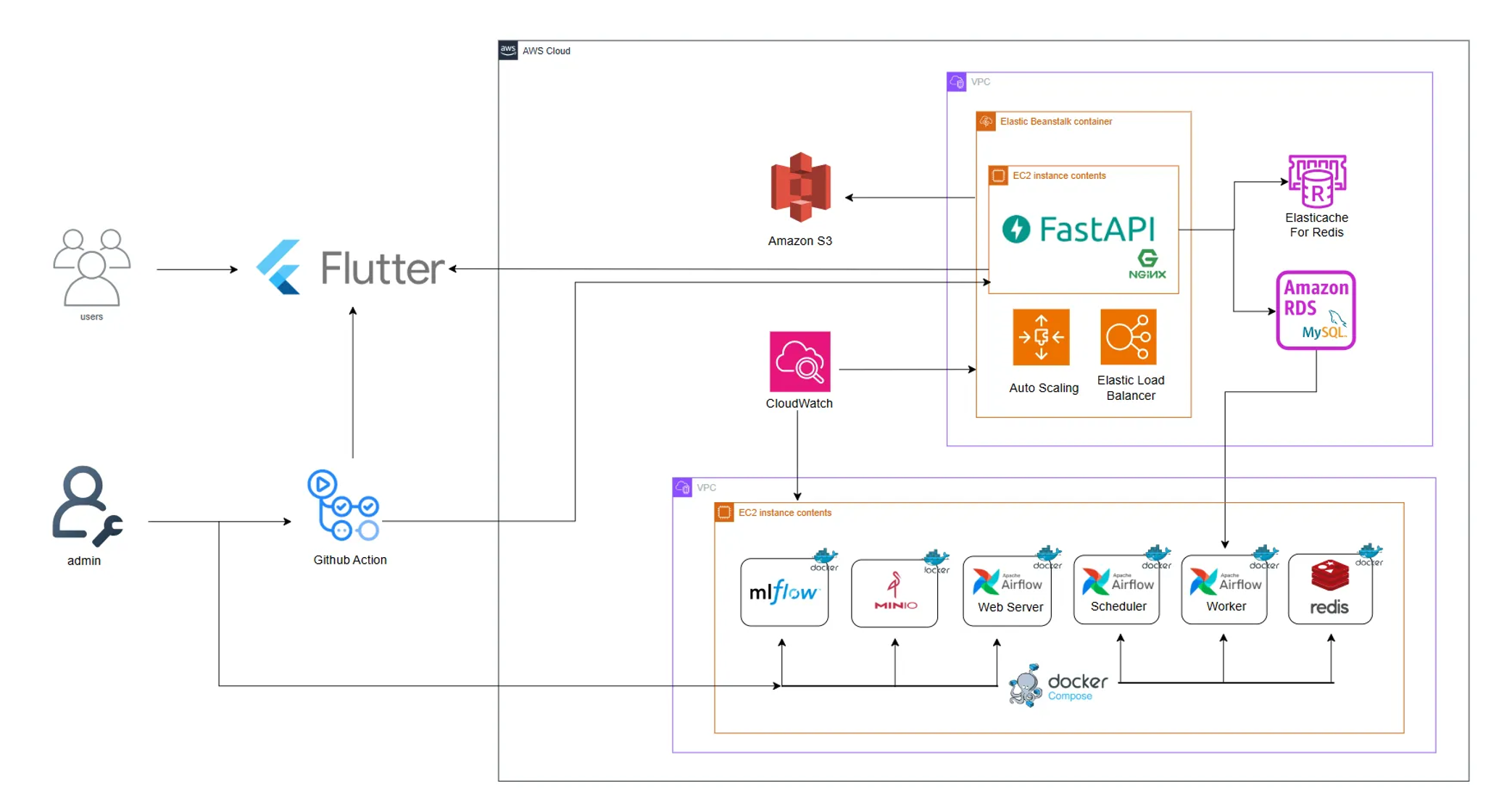
실제 AWS에서 구축했던 시스템 아키텍처 구조도는 위와 같습니다.
구현 중 Airflow에서 CeleryExecutor 대신 LocalExecutor를 사용하는 것으로 변경되어 아래 아키텍처에서 Airflow Worker, Redis 컨테이너는 구현되지 않았습니다.
MLOps
저는 Bllossom-llama-3.2-ko 모델의 주기적인 학습 자동화를 위한 mlops를 구축하였습니다.
주요 내용은 다음과 같습니다.
1. Airflow를 활용한 학습 파이프라인 스케줄링
- DAG를 정의하고, 모델 학습 파이프라인을 주기적으로 실행되도록 구성했습니다.
2. 모델 실험 및 버전 관리를 위한 MLflow 연동
- MLflow를 컨테이너화하여 학습 파라미터, 메트릭, 아티팩트를 관리했습니다.
3. MinIO 기반 모델 아티팩트 저장소 구성
- AWS S3 인터페이스를 따르는 MinIO를 사용하여 학습된 모델 파일과 tokenizer 등을 저장했습니다.
4. Docker-Compose 기반 로컬 개발 환경 통합 관리
- Airflow, MLflow, Postgres, MinIO를 각각의 컨테이너로 분리하여 관리하였고, .env 파일을 통해 민감 정보와 환경 설정을 외부화했습니다.
- 환경 변경 시 빠르게 재배포가 가능하며, 구성 요소 간 의존성을 명확히 관리할 수 있도록 설계했습니다.
5. 학습 코드 변경 시 자동 반영을 위한 볼륨 마운트 설정
- train 디렉토리를 Airflow 컨테이너에 마운트하여 학습 코드 수정 시 바로 DAG에 반영되도록 하였습니다.
시작
작업을 위한 디렉토리를 먼저 생성하겠습니다.
mkdir mlops
cd mlops
mkdir dags
mkdir logs
mkdir train- 사전에 작성해둔 학습 코드들을
train폴더 안에 위치시킵니다. - 저는
update_learn.py파일의update_learning함수를 실행하면 학습이 진행되도록 구성했습니다. train폴더를 모듈로 인식할 수 있도록 하기 위해train폴더 안에 내용이 비어있는__init__.py파일을 생성합니다.
Docker Compose
Docker Desktop 설치
Docker와 Docker Compose를 사용하기 위해 Docker Desktop을 설치합니다.
Docker Desktop 설치 페이지
설치가 완료되면 버전이 정상적으로 출력되는지 확인합니다.
docker -v
docker compose versionDocker 커스텀 이미지 생성
MLflow와 Airflow 컨테이너에는 여러 추가 라이브러리가 필요하기 때문에, 각각의 이미지를 커스터마이징하여 필요한 패키지를 사전에 설치하도록 구성했습니다.
mlops 폴더 안에 Dockerfile.mlflow, Dockerfile.airflow 파일을 생성합니다.
# Dockerfile.mlflow
FROM ghcr.io/mlflow/mlflow:v2.22.0
RUN pip install psycopg2-binary boto3mlflow 공식 이미지 중 2.22.0 버전을 사용하였습니다.
PostgreSQL과의 연동을 위한 psycopg2-binary와 아티팩트 연동을 위한 boto3를 설치하도록 하였습니다.
# Dockerfile.airflow
FROM apache/airflow:2.8.4-python3.10
USER root
RUN apt-get update && \
apt-get install -y libmpich-dev libopenmpi-dev
USER airflow
RUN pip install --no-cache-dir mpi4py
RUN pip install --no-cache-dir mlflow psycopg2-binary python-dotenv numpy pandas openai torch bitsandbytes optuna datasets transformers peft accelerate requests boto3 deepspeed공식 Apache Airflow 이미지 2.8.4-Python 3.10 버전을 사용하였습니다.
먼저, mpi4py 패키지를 설치하기 위한 libmpich-dev, libopenmpi-dev를 root 권한으로 설치합니다.
다시 Airflow 기본 사용자로 복귀하여 패키지 설치를 진행합니다.
모델 학습 시 필요한 여러 패키지들을 설치하는 명령어를 작성합니다.
Postgres DB 초기화
PostgreSQL 컨테이너는 최초 실행 시 /docker-entrypoint-initdb.d/ 디렉터리에 있는 .sql 또는 .sh 파일을 자동 실행합니다.
MLflow와 Airflow에서 각각 별도의 DB가 필요하므로, init.sql에 다음과 같이 DB 생성 명령을 추가하였습니다
CREATE DATABASE airflow;
CREATE DATABASE mlflow;Docker Compose 설정
이제는 docker-compose.yml 파일을 생성합니다.
# docker-compose.yml
version: "3.9" # Docker Compose 버전
services:
# Postgres
postgres:
image: postgres:13 # Airflow와 MLflow의 메타데이터를 저장할 Postgres 13 이미지 사용
container_name: postgres # 컨테이너 이름 설정
restart: always # 컨테이너가 꺼져도 항상 재시작되도록 설정
environment:
POSTGRES_USER: ${POSTGRES_USER} # Postgres 사용자명
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD} # Postgres 비밀번호
volumes:
- postgres-db-volume:/var/lib/postgresql/data # DB 데이터를 보존할 볼륨 마운트
- ./init.sql:/docker-entrypoint-initdb.d/init.sql # 초기 설정 SQL 스크립트 마운트
healthcheck:
test: ["CMD-SHELL", "pg_isready -U $$POSTGRES_USER"] # DB가 실행 가능한 상태인지 확인
interval: 10s # 헬스체크 주기
retries: 5 # 최대 재시도 횟수
# MinIO
minio:
image: minio/minio # S3 호환 오브젝트 스토리지인 MinIO 이미지 사용
container_name: minio # 컨테이너 이름 설정
restart: always # 컨테이너가 꺼져도 항상 재시작되도록 설정
ports:
- "9000:9000" # S3 API 포트
- "9001:9001" # 웹 콘솔 포트
environment:
MINIO_ROOT_USER: ${MINIO_USER} # 관리자 계정
MINIO_ROOT_PASSWORD: ${MINIO_PASSWORD} # 관리자 비밀번호
command: server /data --console-address ":9001" # 데이터 경로 설정 및 웹 콘솔 포트 지정
volumes:
- minio-data:/data # MinIO 데이터 보존을 위한 볼륨 마운트
# MLflow (모델 실험 관리)
mlflow:
build:
context: . # 현재 디렉토리를 컨텍스트로 사용하여 Dockerfile 빌드
dockerfile: Dockerfile.mlflow # 커스텀 MLflow Dockerfile 사용
container_name: mlflow # 컨테이너 이름 설정
restart: always # 컨테이너가 꺼져도 항상 재시작되도록 설정
ports:
- "5050:5000" # MLflow UI 접속 포트
environment:
MLFLOW_TRACKING_URI: ${MLFLOW_TRACKING_URI} # MLflow가 사용할 Tracking 서버 주소
MLFLOW_BACKEND_STORE_URI: ${MLFLOW_BACKEND_STORE_URI} # 실험 메타데이터 저장용 DB 주소
MLFLOW_ARTIFACT_ROOT: ${MLFLOW_ARTIFACT_ROOT} # 모델 파일 저장 위치
MLFLOW_S3_ENDPOINT_URL: ${MLFLOW_S3_ENDPOINT_URL} # MinIO 엔드포인트
AWS_ACCESS_KEY_ID: ${AWS_ACCESS_KEY_ID} # MinIO 계정
AWS_SECRET_ACCESS_KEY: ${AWS_SECRET_ACCESS_KEY} # MinIO 비밀번호
command: > # MLflow 서버 실행 명령어
mlflow server
--backend-store-uri ${MLFLOW_BACKEND_STORE_URI}
--default-artifact-root ${MLFLOW_ARTIFACT_ROOT}
--host 0.0.0.0
--port 5000
depends_on:
postgres:
condition: service_healthy # Postgres가 헬시 상태일 때 실행
minio:
condition: service_started # MinIO가 시작된 후 실행
# Airflow 웹 서버 (웹 UI)
airflow-webserver:
build:
context: . # 현재 디렉토리를 컨텍스트로 사용하여 Dockerfile 빌드
dockerfile: Dockerfile.airflow # 커스텀 Airflow Dockerfile 사용
container_name: airflow-webserver # 컨테이너 이름 설정
restart: always # 컨테이너가 꺼져도 항상 재시작되도록 설정
ports:
- "8080:8080" # Airflow 웹 UI 접속 포트
environment:
AIRFLOW__CORE__EXECUTOR: ${AIRFLOW_EXECUTOR} # 사용할 Executor 타입
AIRFLOW__CORE__LOAD_EXAMPLES: ${AIRFLOW_LOAD_EXAMPLES} # 예제 DAG 로드 여부
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: ${AIRFLOW_SQL_ALCHEMY_CONN} # Airflow DB 연결 주소
AIRFLOW__LOGGING__LOGGING_MASK_SECRETS: "False" # 로그에서 민감정보 마스킹 여부
_AIRFLOW_WWW_USER_USERNAME: ${AIRFLOW_ADMIN_USERNAME} # 관리자 유저 이름
_AIRFLOW_WWW_USER_PASSWORD: ${AIRFLOW_ADMIN_PASSWORD} # 관리자 비밀번호
_AIRFLOW_WWW_USER_FIRSTNAME: ${AIRFLOW_ADMIN_FIRSTNAME} # 관리자 이름
_AIRFLOW_WWW_USER_LASTNAME: ${AIRFLOW_ADMIN_LASTNAME} # 관리자 성
_AIRFLOW_WWW_USER_EMAIL: ${AIRFLOW_ADMIN_EMAIL} # 관리자 이메일
MLFLOW_BACKEND_STORE_URI: ${MLFLOW_BACKEND_STORE_URI} # 실험 메타데이터 저장용 DB 주소
command: > # DB 마이그레이션 -> 관리자 유저 없으면 생성 -> 웹서버 실행
bash -c "airflow db migrate && \
if ! airflow users list | grep -q ${AIRFLOW_ADMIN_USERNAME}; then \
airflow users create --username ${AIRFLOW_ADMIN_USERNAME} --firstname ${AIRFLOW_ADMIN_FIRSTNAME} --lastname ${AIRFLOW_ADMIN_LASTNAME} --role Admin --email ${AIRFLOW_ADMIN_EMAIL} --password ${AIRFLOW_ADMIN_PASSWORD}; \
fi && \
airflow webserver"
volumes:
- ./dags:/opt/airflow/dags # DAG 스크립트 경로
- ./logs:/opt/airflow/logs # 로그 저장 경로
- ./train:/opt/airflow/train # 학습 코드 경로
depends_on:
postgres:
condition: service_healthy # Postgres가 헬시 상태일 때 실행
# Airflow 스케줄러 (DAG 실행 일정 관리)
airflow-scheduler:
build:
context: . # 현재 디렉토리를 컨텍스트로 사용하여 Dockerfile 빌드
dockerfile: Dockerfile.airflow # 커스텀 Airflow Dockerfile 사용
container_name: airflow-scheduler # 컨테이너 이름 설정
restart: always # 컨테이너가 꺼져도 항상 재시작되도록 설정
environment:
AIRFLOW__CORE__EXECUTOR: ${AIRFLOW_EXECUTOR} # 사용할 Executor 타입
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: ${AIRFLOW_SQL_ALCHEMY_CONN} # Airflow DB 연결 주소
AIRFLOW__LOGGING__LOGGING_MASK_SECRETS: "False" # 로그에서 민감정보 마스킹 여부
MLFLOW_TRACKING_URI: ${MLFLOW_TRACKING_URI} # MLflow가 사용할 Tracking 서버 주소
MLFLOW_BACKEND_STORE_URI: ${MLFLOW_BACKEND_STORE_URI} # 실험 메타데이터 저장용 DB 주소
MLFLOW_ARTIFACT_ROOT: ${MLFLOW_ARTIFACT_ROOT} # 모델 파일 저장 위치
MLFLOW_S3_ENDPOINT_URL: ${MLFLOW_S3_ENDPOINT_URL} # MinIO 엔드포인트
AWS_ACCESS_KEY_ID: ${AWS_ACCESS_KEY_ID} # MinIO 계정
AWS_SECRET_ACCESS_KEY: ${AWS_SECRET_ACCESS_KEY} # MinIO 비밀번호
S3_BUCKET_NAME: ${S3_BUCKET_NAME} # 사용할 버킷 이름
MINIO_URL: ${MINIO_URL} # MinIO 주소
command: ["airflow", "scheduler"] # Airflow 스케줄러 실행
volumes:
- ./dags:/opt/airflow/dags # DAG 스크립트 경로
- ./logs:/opt/airflow/logs # 로그 저장 경로
- ./train:/opt/airflow/train # 학습 코드 경로
depends_on:
- airflow-webserver # 웹 서버가 실행된 이후 실행
volumes: # 위에서 선언한 볼륨들을 정의
postgres-db-volume: # Postgres 데이터 보존용 볼륨
minio-data: # MinIO 오브젝트 데이터 보존용 볼륨1. Postgres (Airflow, MLflow 메타데이터 DB)
- Airflow와 MLflow의 백엔드 DB로 사용되었습니다. (로그, 상태, 메타데이터 저장)
- 데이터가 휘발되지 않도록 postgres-db-volume으로 데이터 지속화하였습니다.
2. MinIO (S3 호환 객체 저장소)
- MLflow의 모델 아티팩트 저장소로 사용되었습니다. (모델 파일 저장)
- MinIO 웹 콘솔이 9001 포트에서 접근 가능하도록 커맨드를 지정하였습니다.
- /data 폴더를 minio-data라는 Docker 볼륨에 마운트합니다.
3. MLflow (모델 실험 관리 도구)
- 실험을(모델 학습, 하이퍼파라미터 등) 관리합니다.
- 5050 포트로 외부에서 접속하도록 설정하였습니다.
4. Airflow Webserver (DAG 관리용 UI)
- DAG을 시각적으로 관리할 수 있는 웹 UI 제공합니다.
- 먼저, DB 초기 마이그레이션하고 Admin 유저가 없으면 생성합니다. 이후, 웹 서버를 실행합니다.
- 볼륨
- ./dags: DAG 스크립트 저장
- ./logs: 실행 로그 저장
- ./train: 학습 파이프라인 코드 포함 (Airflow DAG 내 import)
- postgres가 먼저 실행되어야 실행됩니다.
5. Airflow Scheduler (DAG 실행 스케줄 관리)
- DAG을 주기적으로 실행하는 역할을 합니다.
- webserver와 동일하게 DAG, 로그, 학습 코드를 공유합니다.
- webserver가 먼저 실행되어야 실행됩니다.
6. volumes (데이터 보존)
- postgres-db-volume: Postgres DB의 데이터를 보존합니다.
- minio-data: MinIO에 저장된 모델 파일 등의 데이터를 보존합니다.
.env 설정
.env 파일도 생성하여 환경변수들을 작성합니다.
# .env
# PostgreSQL 설정
POSTGRES_USER=nolli
POSTGRES_PASSWORD=nolli1234
# MinIO 설정
MINIO_USER=nolli
MINIO_PASSWORD=nolli1234
S3_BUCKET_NAME=nolli-bucket
MINIO_URL=http://minio:9000
# MLflow 설정
MLFLOW_TRACKING_URI=http://mlflow:5000
MLFLOW_BACKEND_STORE_URI=postgresql+psycopg2://nolli:nolli1234@postgres:5432/mlflow
MLFLOW_ARTIFACT_ROOT=s3://nolli-bucket/artifacts
MLFLOW_S3_ENDPOINT_URL=http://minio:9000
AWS_ACCESS_KEY_ID=nolli
AWS_SECRET_ACCESS_KEY=nolli1234
# Airflow 설정
AIRFLOW_EXECUTOR=LocalExecutor
AIRFLOW_LOAD_EXAMPLES=False
AIRFLOW_SQL_ALCHEMY_CONN=postgresql+psycopg2://nolli:nolli1234@postgres:5432/airflow
# Airflow 관리자 설정
AIRFLOW_ADMIN_USERNAME=nolli
AIRFLOW_ADMIN_PASSWORD=nolli1234
AIRFLOW_ADMIN_FIRSTNAME=Nolli
AIRFLOW_ADMIN_LASTNAME=Kim
AIRFLOW_ADMIN_EMAIL=nolli@abc.com
# NOLLI 서버 URL
NOLLI_URL=http://nolli.~~MLflow
train 폴더의 학습 코드에 mlflow 코드를 추가해줍니다.
# model_trainer.py
...
def train_model(experiment_name, model, tokenizer, tokenized_train_dataset, tokenized_validation_dataset):
# MLflow 실험 설정
mlflow.set_experiment(experiment_name)
with mlflow.start_run(): # MLflow 실행 시작
# MLflow에 학습 파라미터 기록
hyperparams = {
"learning_rate": 2e-4,
"batch_size": 4,
"num_train_epochs": 3
}
mlflow.log_params(hyperparams)
...
print("모델 학습 시작...")
trainer.train()
print("모델 학습 완료!")
# 학습 후 성능 평가
train_metrics = trainer.evaluate()
print(f"학습 평가 결과: {train_metrics}")
mlflow.log_metrics(train_metrics)
...
mlflow.log_artifact(model_save_path)
mlflow.log_artifact(f"{experiment_name}/config.json")
mlflow.log_artifact(f"{experiment_name}/logs")
torch.cuda.empty_cache()
return model- mlflow.set_experiment(experiment_name)
- 실험 이름을 지정하여, 여러 실험을 그룹화합니다.
- with mlflow.start_run()
- MLflow의 실행 컨텍스트를 시작합니다.
- 이 블록 안에서 기록되는 모든 정보(파라미터, 메트릭, 아티팩트 등)는 하나의 실험에 저장됩니다.
- mlflow.log_params(hyperparams)
- 학습에 사용한 하이퍼파라미터(learning_rate, batch_size, num_train_epochs 등)를 MLflow에 기록합니다.
- mlflow.log_metrics(train_metrics)
- 학습 후 평가 결과(정확도, 손실 등 주요 성능 지표)를 MLflow에 저장합니다.
- mlflow.log_artifact(model_save_path)
- 학습이 끝난 후 저장된 모델 파일을 MLflow에 아티팩트로 업로드합니다.
MinIO
학습이 완료된 후 MinIO에 배포하는 코드도 작성합니다.
# upload_to_minio.py
import os, boto3
def upload_model_to_minio(model_path, s3_model_path):
local_model_path = f'{model_path}/finetuned_model'
tokenizer_path = f'{model_path}/finetuned_tokenizer'
s3 = boto3.client(
"s3",
endpoint_url=f"http://{os.environ["MINIO_URL"]}",
aws_access_key_id=os.environ["AWS_ACCESS_KEY_ID"],
aws_secret_access_key=os.environ["AWS_SECRET_ACCESS_KEY"]
)
# safetensors 및 adapter_config.json
safetensors_files = [os.path.normpath(os.path.join(local_model_path, f)) for f in os.listdir(local_model_path) if f.endswith(".safetensors")]
adapter_config_files = [os.path.normpath(os.path.join(local_model_path, f)) for f in os.listdir(local_model_path) if f.endswith("adapter_config.json")]
tokenizer_files = [os.path.normpath(os.path.join(tokenizer_path, f)) for f in os.listdir(tokenizer_path) if f.endswith("tokenizer.json")]
# config.json 확인
config_path = os.path.normpath(os.path.join(model_path, "config.json"))
config_files = [config_path] if os.path.exists(config_path) else []
# 업로드할 파일 목록
model_files = safetensors_files + adapter_config_files + tokenizer_files + config_files
bucket_name = os.environ["S3_BUCKET_NAME"]
for file_path in model_files:
abs_path = os.path.abspath(file_path)
if os.path.exists(abs_path):
file_name = os.path.basename(file_path)
# Multipart Upload 대신 put_object 사용
with open(abs_path, "rb") as data:
s3.put_object(Bucket=bucket_name, Key=f"{s3_model_path}/{file_name}", Body=data)
print(f"Uploaded: {bucket_name}/{s3_model_path}/{file_name}")
else:
print(f"파일 없음: {abs_path}")
print(f"Model uploaded to MinIO: {bucket_name}/{s3_model_path}").safetensors,adapter_config.json,tokenizer.json,config.json파일을 MinIO의 지정한 버킷에 업로드합니다.boto3라이브러리를 활용해 MinIO 서버와 연결합니다.- 모델 관련 여러 파일들을 한 번에 찾아 업로드하며,
put_object메서드를 이용해 빠르고 안정적으로 객체를 저장합니다.
Airflow
Flow
구성하고 있는 MLOps의 목표는 아래와 같습니다.
API로 메인 서버에 데이터 요청 → 모델 학습 → MLflow에 기록 → MinIO에 저장
이 과정을 Airflow의 DAG를 통해 주기적으로 자동화하는 것이 목표입니다.
Executor
- 처음에는 CeleryExecutor를 사용해 분산 작업을 할 수 있다는 것을 보고 학습을 분산해서 빠르게 할 수 있는 것인가? 하는 생각을 했습니다.
- Redis를 메시지 큐로 사용하여 근사하게 구현해보려고 하였으나.. 분산 작업이 모델을 분산 학습을 진행할 수 있다는 의미는 아니었습니다.
- Nolli의 학습 코드는 하나의 작업만 진행되면 충분하기 때문에 Celery Executor를 사용하는 것은 오버스펙임이 분명해 보였습니다.
- CeleryExecutor를 사용하더라도 워커는 하나만 필요할 뿐이고, 메시지 큐도 쓸모 없어집니다.
- 이에 서비스 스펙에 맞게 LocalExecutor를 사용하는 것으로 진행하였습니다.
DAG 작성
train_dag.py 파일을 dags 폴더 안에 생성합니다.
import sys
sys.path.append("/opt/airflow/train") # Airflow 작업용 모듈이 위치한 경로를 sys.path에 추가
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
import update_learn
with DAG(
dag_id='model_training', # DAG의 ID
description='Nolli MLOps 구현', # DAG에 대한 설명
schedule_interval='@monthly', # DAG 실행 주기를 매월 1회로 설정
start_date=datetime(2025, 1, 1), # DAG가 처음 실행될 날짜 지정
catchup=False, # 이전 실행을 모두 수행하지 않고 최신 스케줄만 실행하도록 설정
max_active_runs=1, # 동시에 실행 가능한 DAG 인스턴스 수를 1개로 제한
concurrency=1, # 동시에 실행 가능한 task 수를 1개로 제한
) as dag:
task = PythonOperator( # PythonOperator를 사용해 Python 함수를 실행하는 태스크 정의
task_id='train_model_task', # 태스크의 고유 ID 설정
python_callable=update_learn.update_learning, # 실행할 함수 지정
provide_context=True, # Airflow 실행 컨텍스트를 함수에 전달할지 여부
)sys.path.append(”/opt/airflow/train”)를 통해 파이썬 모듈 검색 경로에/opt/airflow/train를 추가함으로써, DAG 파일에서train폴더의 모듈을 정상적으로 import할 수 있도록 설정했습니다.PythonOperator를 사용하여, Airflow가 파이프라인의 모델 학습 함수update_learn.update_learning를 태스크로 실행하도록 구성했습니다.schedule_interval=’@monthly’로 설정하여 주 단위로 자동적으로 학습이 진행되도록 구현했습니다.
실행
빌드 후 컨테이너를 실행합니다.
docker-compose build
docker-compose up -d컨테이너들이 정상적으로 올라왔는지 확인합니다.
docker pslocalhost:5050에 접속해 MLflow 웹 서버에 접속합니다.
다음으로는 localhost:9001에 접속해 MinIO 웹 서버에 접속합니다.
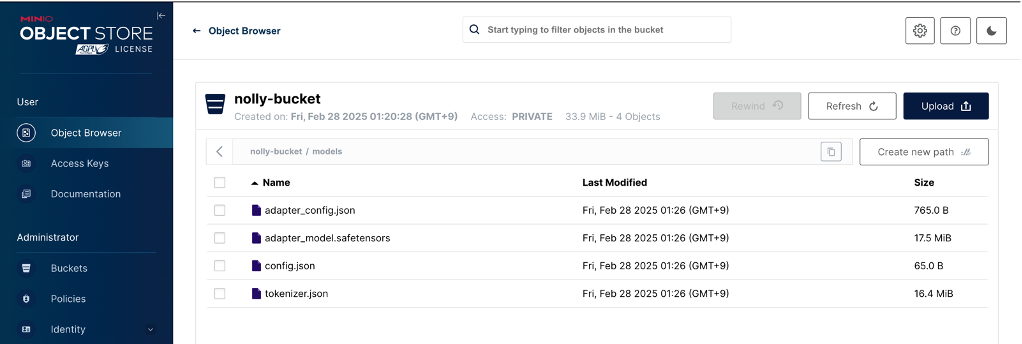
로그인 후, 설정에 맞는 버킷을 생성해줍니다.
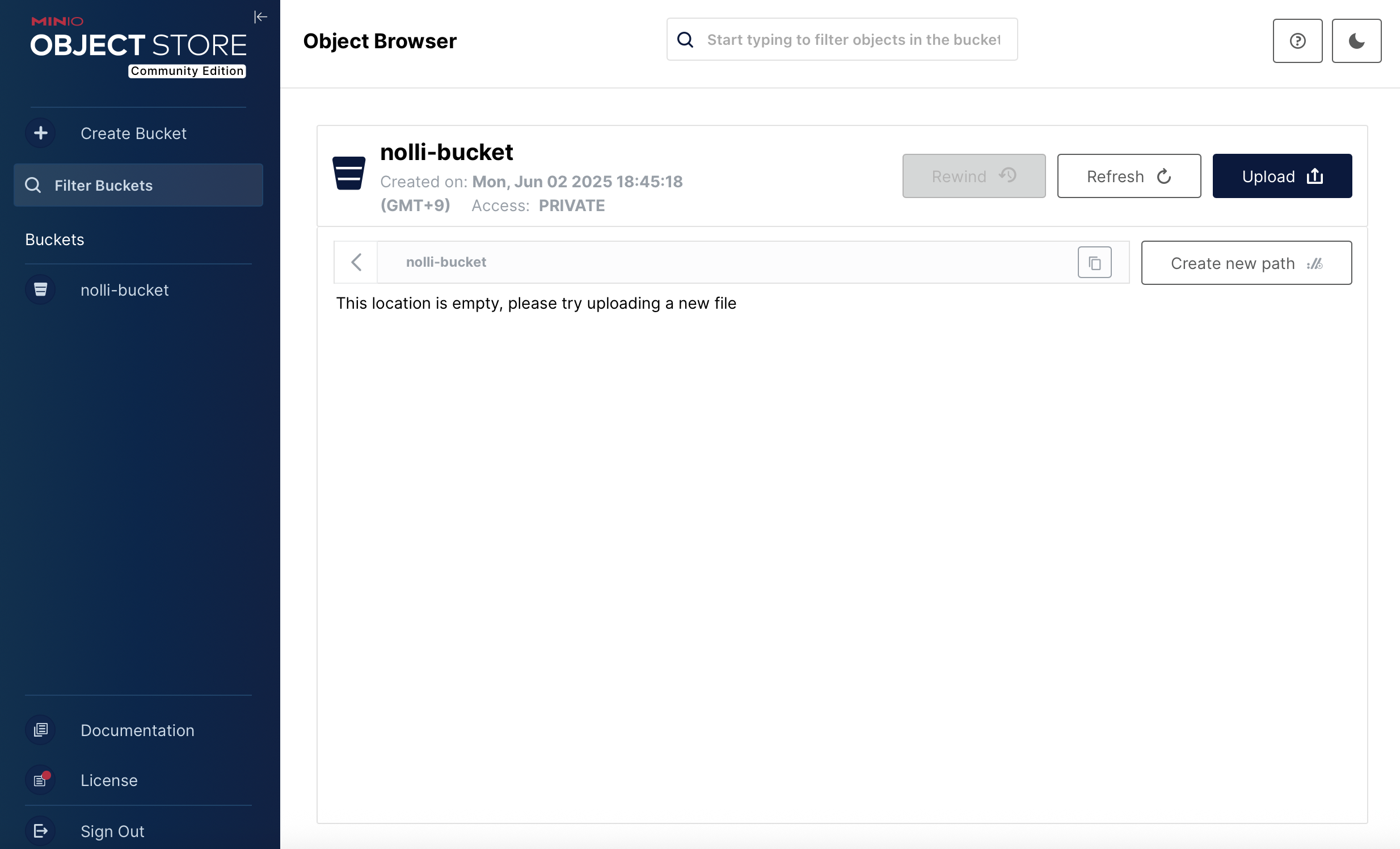
이제, localhost:8080에 접속해 Airflow 웹 서버에 접속합니다.
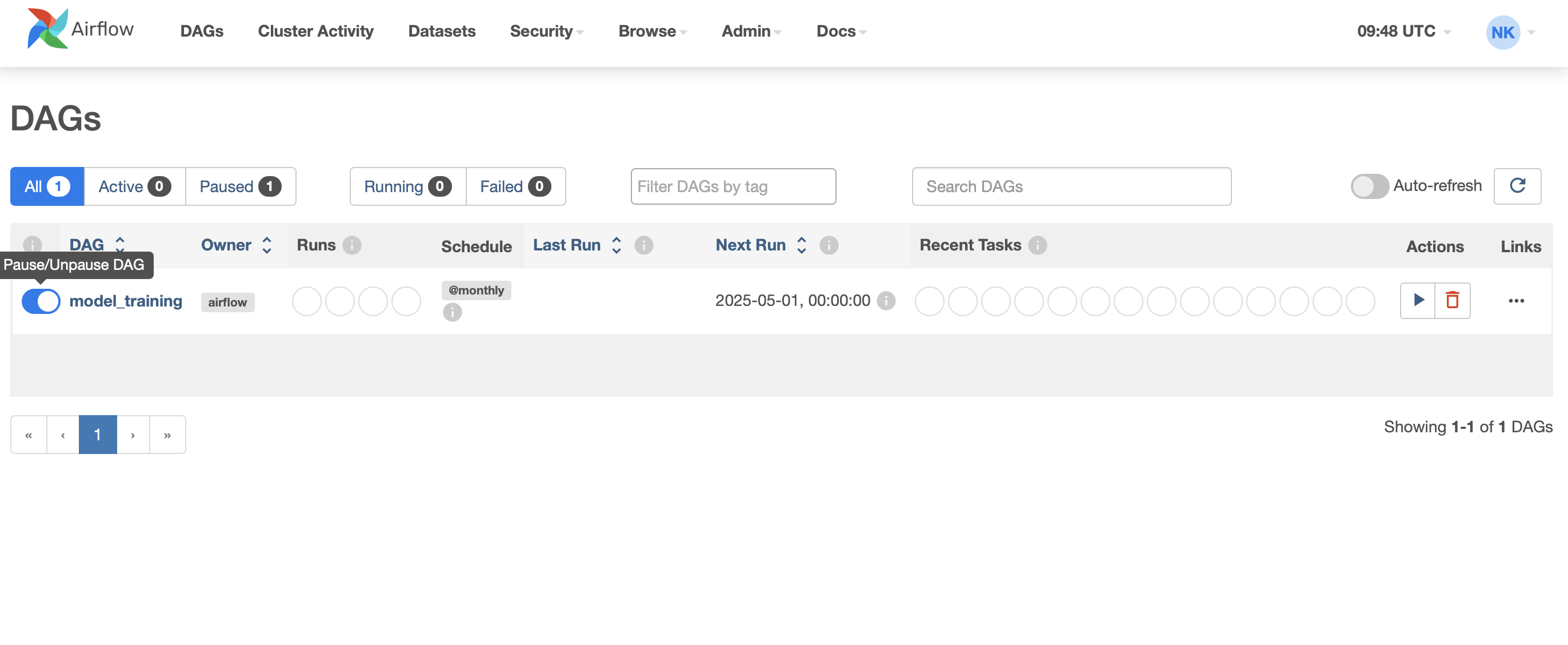
로그인 후, DAG 토글을 눌러 DAG를 활성화시킵니다.
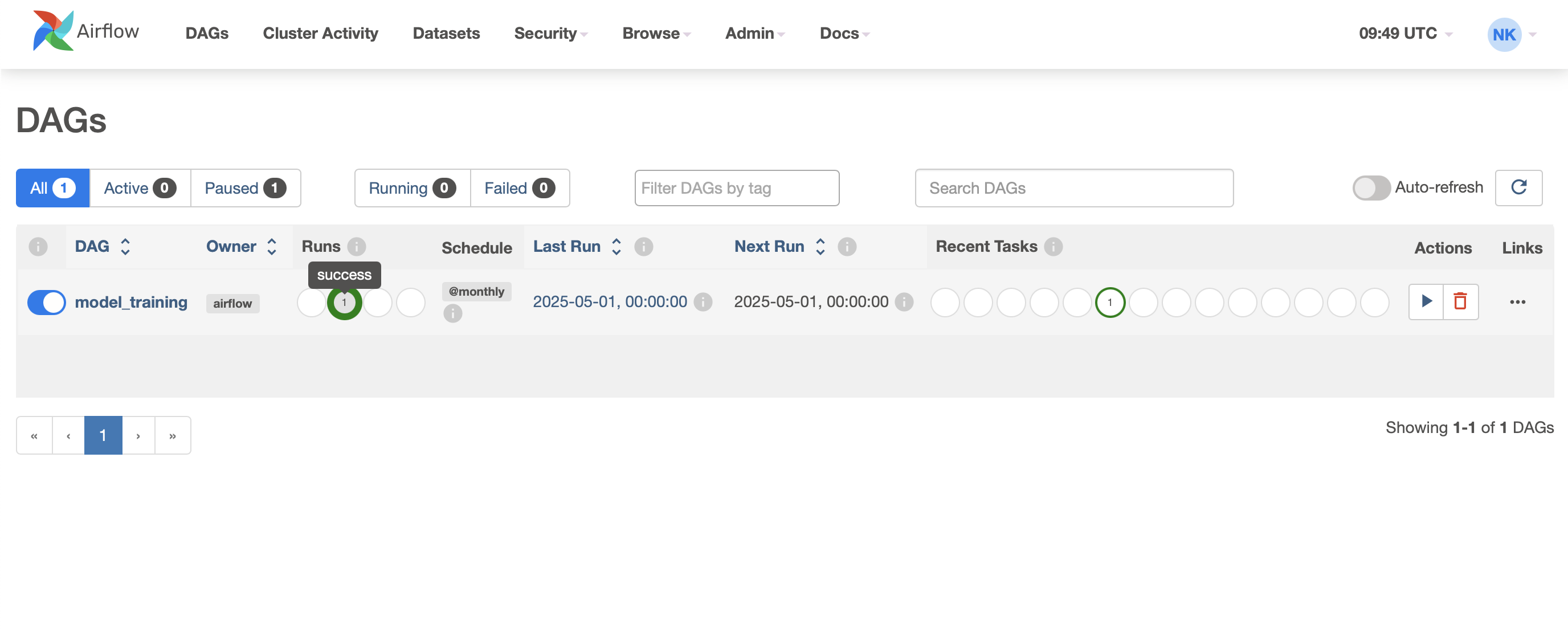
작업이 성공적으로 완료되면, 다음처럼 success 상태를 확인할 수 있습니다.
MLflow에서도 실험이 추가되어 기록된 것을 확인할 수 있습니다.
MinIO에 모델이 정상적으로 배포된 것도 확인할 수 있습니다.