8주차 WIL
평가 지표
지도 학습 모델의 성능을 재는 평가 지표는 크게 이진 분류의 평가 지표와 다중 분류의 평가 지표로 나뉩니다.
이진 분류의 평가 지표
이진 분류에는 양성 클래스와 음성 클래스가 있습니다.
- 에러의 종류
1. 거짓 양성 : 음성인데 양성으로 잘못 분류
2. 거짓 음성 : 양성인데 음성으로 잘못 분류
불균형 데이터셋 : 한 클래스가 다른 것보다 훨씬 많은 데이터셋!
오차 행렬
오차행렬은 이진 분류 평가 결과를 나타낼 때 가장 널리 사용하는 방법 중 하나입니다.
- 2x2배열의 행은 정답 클래스, 열은 예측 클래스에 해당합니다.
- 각 항목의 숫자는 행의 클래스가 얼마나 많이 열의 클래스로 분류되었는지 나타냅니다.
- 대각 행렬은 정확히 분류된 경우, 다른 항목은 한 클래스의 샘플들이 다른 클래스로 잘못 분류된 경우입니다.
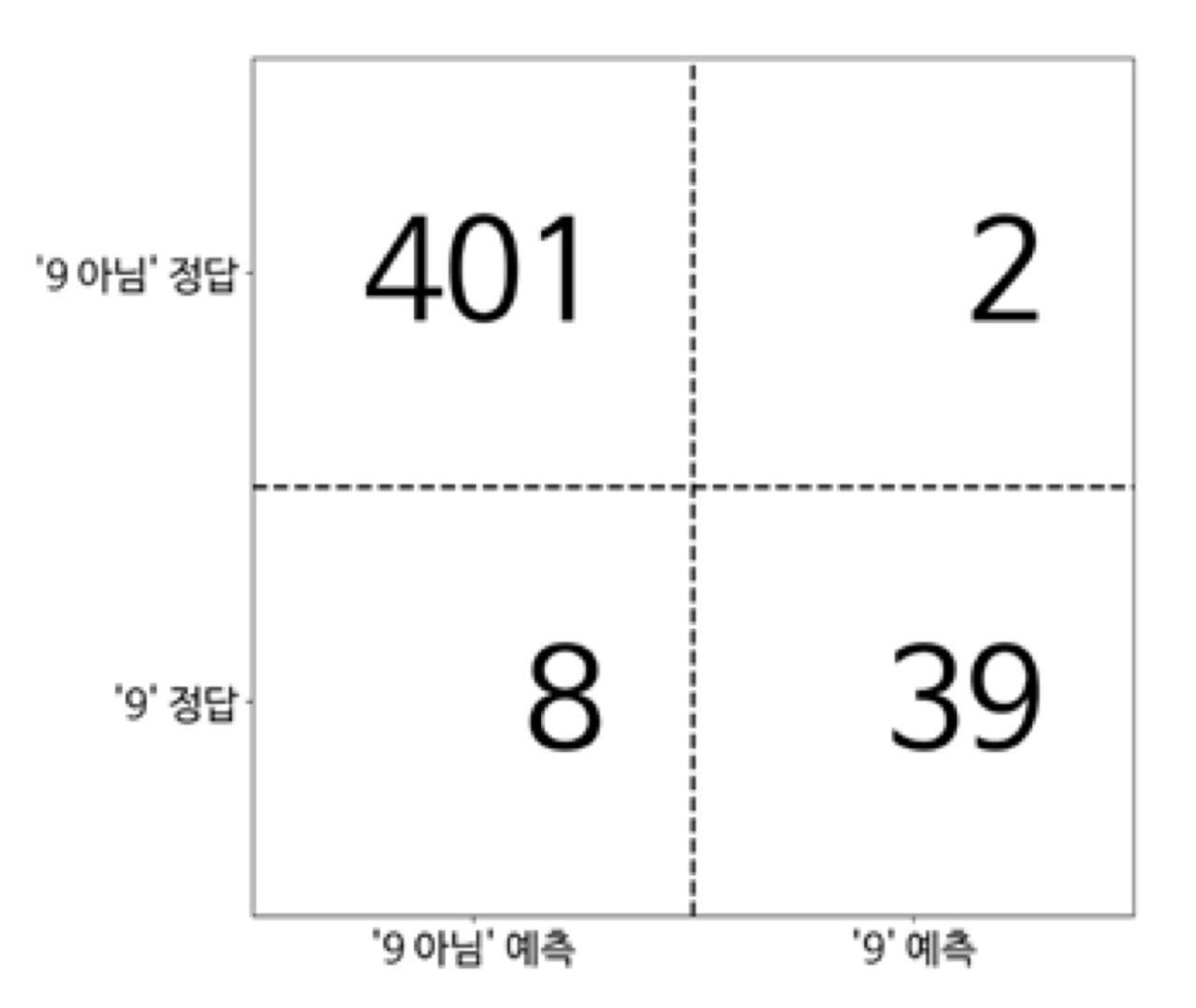
-- '9 아님'을 양성 클래스라고 했을 때 --
위 그림에서 9가 아니라고 예측했는데 실제로는 9가 아니었던 샘플이 401개입니다. (진짜 양성)
또 실제로 9였던 샘플이 8개 입니다. (거짓 양성)
양성 클래스를 올바르게 분류한 샘플을 진짜 양성(TP)
양성 클래스를 잘못 분류한 샘플을 거짓 양성(FP)
음성 클래스를 올바르게 분류한 샘플을 진짜 음성(TN)
음성 클래스를 잘못 분류한 샘플을 거짓 음성(FN)
오차 행렬의 결과를 요약하는 방법 중 하나는 정확도로 표현하는 것입니다.
- 정확도 = TP+TF / TP+FP+TN+FN
정밀도, 재현율, f-점수
정확도뿐만 아니라 정밀도, 재현율, f-점수로도 오차 행렬의 결과를 요약할 수 있습니다.
-
정밀도(양성 예측도) = 𝑇𝑃/(𝑇𝑃+𝐹𝑃)
양성으로 예측된 것 중에 얼마나 많은 샘플이 진짜 양성인지 측정 -
재현율(민감도, 적중률, 진짜 양성 비율) = 𝑇𝑃/(𝑇𝑃+𝐹𝑁)
전체 양성 샘플 중 진짜 양성으로 올바르게 분류된 샘플의 비율.
- 정밀도 최적화와 재현율 최적화는 상충함
if 모든 샘플이 양성(TP 또는 FP)으로 분류되면
TN과 FN은 0이 되고 따라서 재현율은 1로 완벽함
그러나 FP값이 커지므로 정밀도는 작아짐
f-점수는 정밀도와 재현율을 다시 하나로 요약해줍니다.
- f-점수 : 정밀도와 재현율의 조화 평균
F(f1-점수) = 2×(정밀도∙재현율)/(정밀도+재현율)
임계값
양성 확률이 임계 값보다 크거나 같으면 샘플은 양성(TP, NP)로 분류
-> 임계값 낮으면 양성 클래스 비율 높아짐
-> 임계값 높으면 음성 클래스 비율 높아짐

정밀도-재현율 곡선
모든 임계값을 조사해보거나, 한 번에 정밀도나 재현율의 모든 장단점을 살펴봄
from sklearn.metrics import precision_recall_curve - 타깃 레이블과 decision_function이나 predict_proba 메서드로 계산한 예측 불확실성 이용
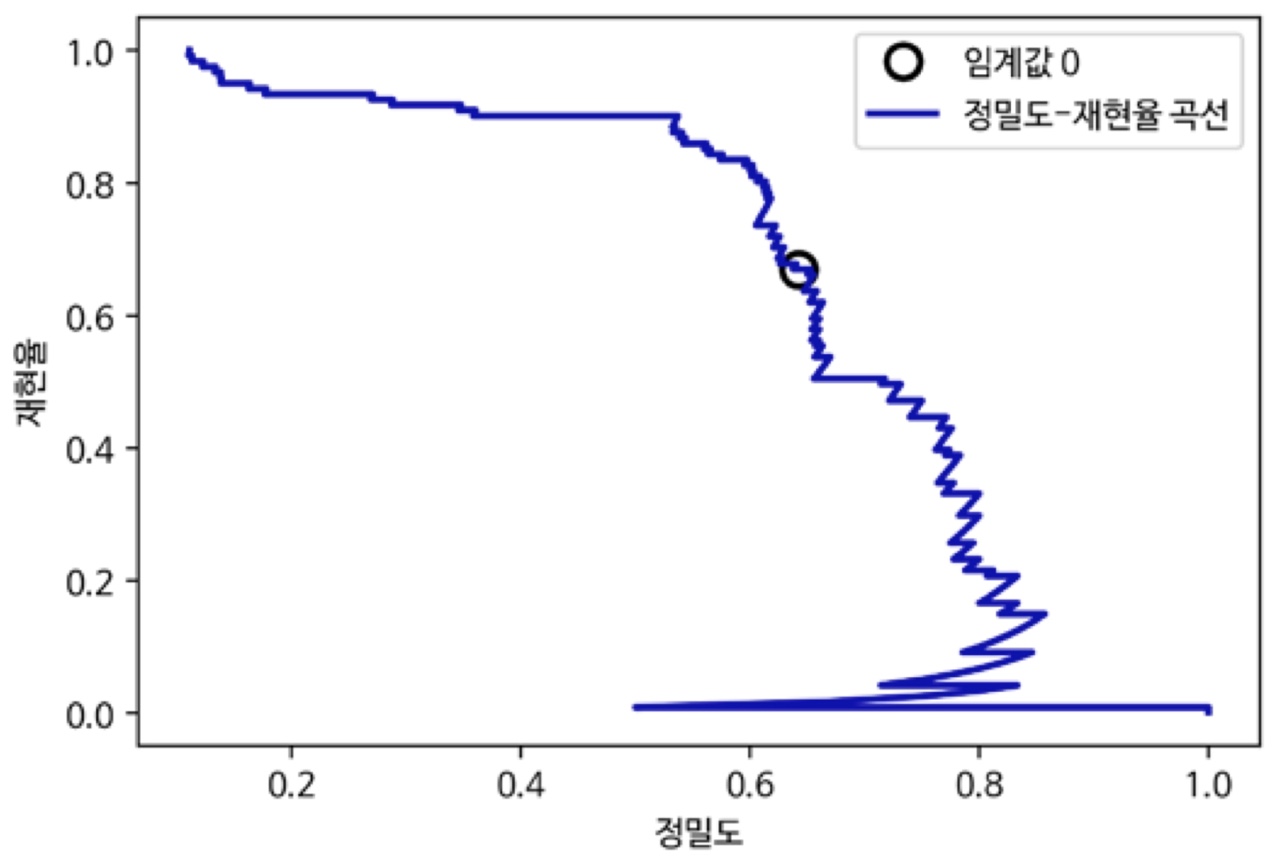
- 곡선의 각 포인트는 decision_function의 가능한 모든 임계값에 대응함
- 기본 임계값인 0지점 기준으로 임계값이 변함에 따라 재현율과 정밀도가 상충함을 알 수 있음
- 곡선이 정밀도와 재현율이 모두 높은 지점인 오른쪽 위로 갈수록 더 좋은 분류기임
전체 곡선에 담긴 정보를 요약하기 위해 곡선의 아랫부분 면적을 계산하여 평균 정밀도를 구할 수 있습니다.
ROC, AUC
ROC곡선은 여러 임계값에서 분류기의 특성을 분석하는 데 널리 사용하는 도구입니다.
정밀도-재현율 곡선처럼 분류기의 모든 임계값을 고려하지만, 정밀도와 재현율 대신 진짜 양성 비율(재현율)에 대한 거짓 양성 비율을 나타냅니다.
- 진짜 양성 비율(TPR) = 재현율
- 거짓 양성 비율 : 전체 음성 샘플 중 거짓 양성으로 잘못 분류한 비율, FP / FP+TN
from sklearn.metrics import roc_curve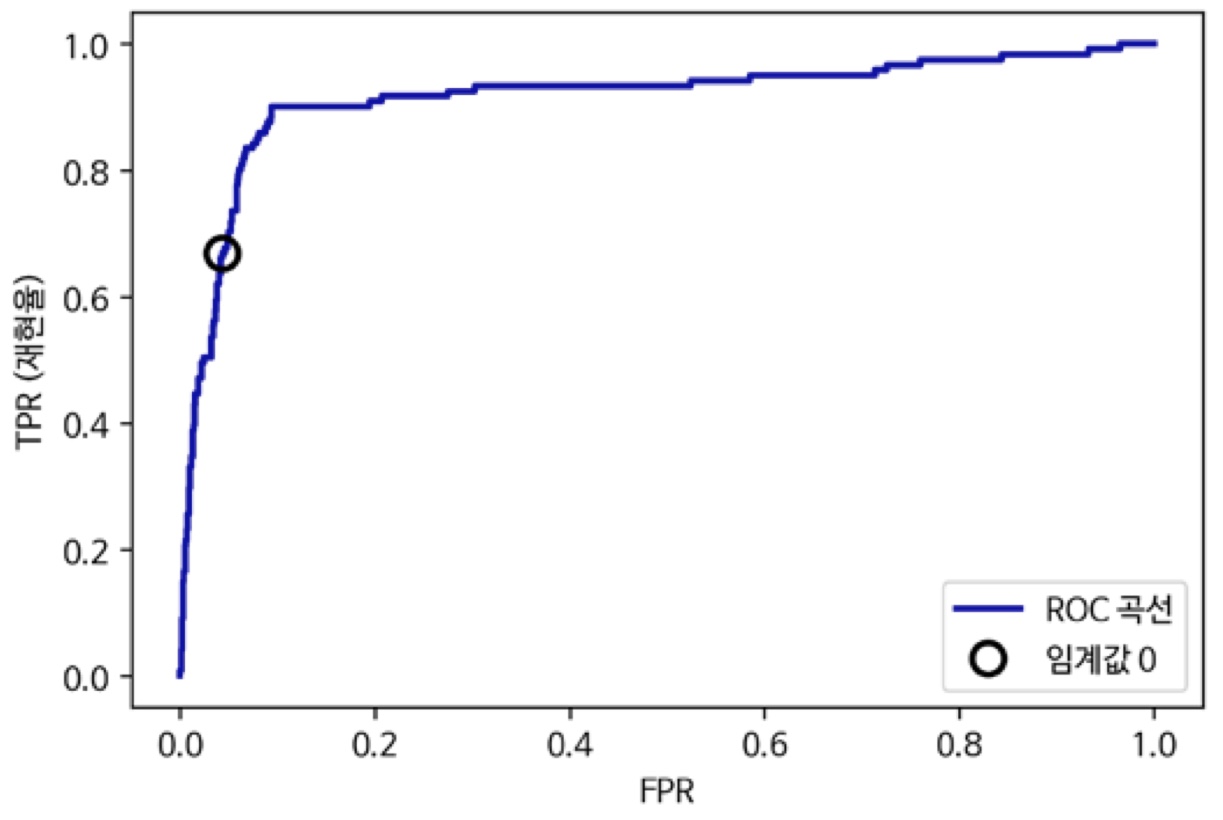
- Roc곡선은 FPR이 낮게 유지되면서 TPR 이 높은 왼쪽 위에 가까울수록 좋음
- 기본 임계값 0인 지점에서 FPR을 좀 늘려서 재현율을 크게 높일 수 있음
ROC에서도 마찬가지로 곡선 아래의 면적값을 이용해서 ROC곡선을 요약할 수 있습니다.
이 면적을 보통 AUC라고 합니다.
- AUC는 0과 1 사이의 값
- 데이터의 불균형에 상관없이 무작위로 예측한 AUC값은 0.5 가 됩니다.
- 그래서 불균형한 데이터셋에서는 정확도보다 AUC가 훨씬 좋습니다.
from sklearn.metrics import roc_auc_curve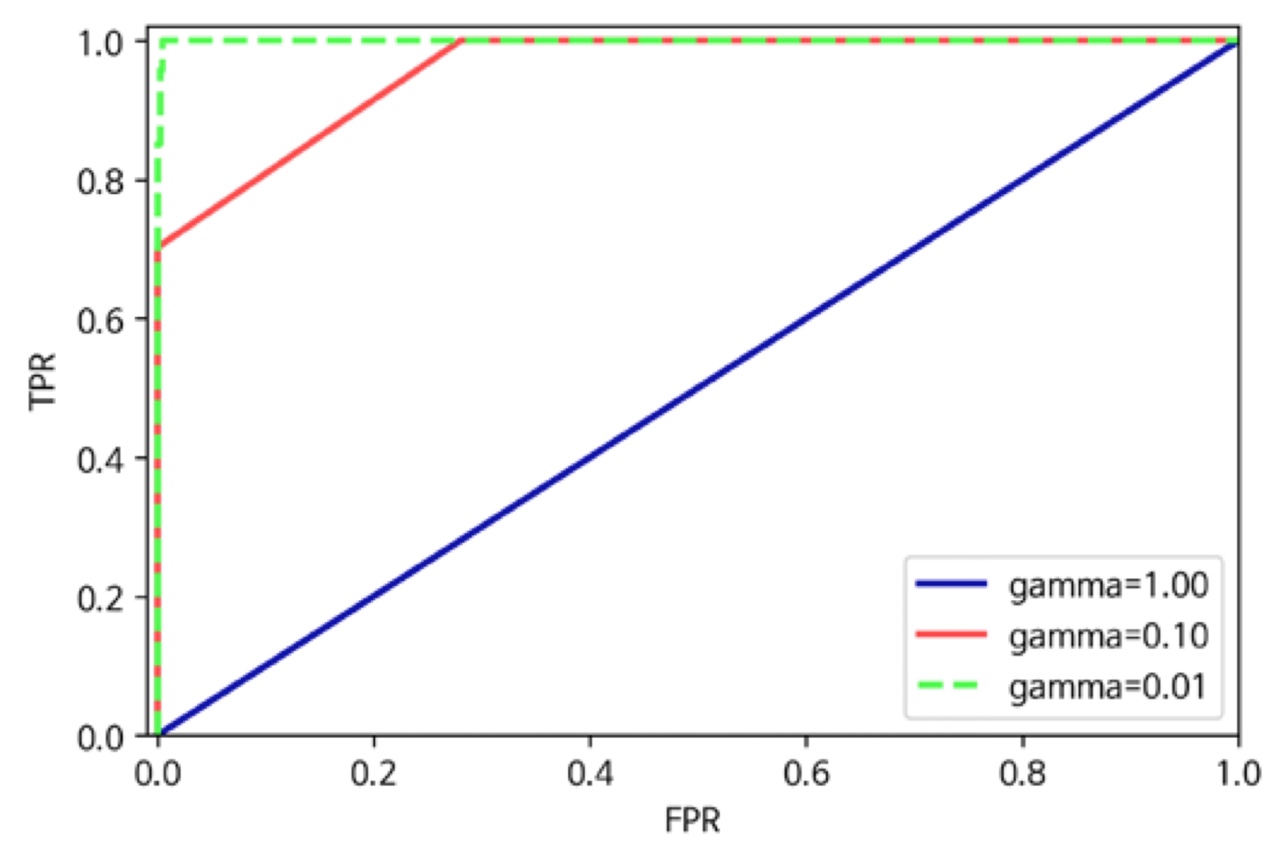
서로 다른 gamma에 대한 SVM의 ROC 곡선입니다.
(지금까지의 곡선은 모두 SVM으로 그린 곡선입니다.)
※ 세가지 감마값에 대한 정확도는 모두 0.9입니다.
gamma=1 일 때 AUC=0.5
gamma=0.1 일 때 AUC=0.94
gamma=1 일 때 AUC=1
그래서 불균형 데이터셋에는 AUC를 사용하는 게 좋습니다.
다중 분류의 평가 지표
다중 분류의 평가 지표는 기본적으로 방금까지 살펴본 이진 분류 평가 지표에서 유도되었지만, 모든 클래스에 대해서 평균을 낸 것입니다.
다중 분류의 정확도 또한 전체 샘플분의 정확히 분류된 샘플의 비율로 계산합니다.
다중 분류에서 불균형 데이터셋을 위해 가장 널리 사용하는 평가 지표는 다중 분류 버전의 f1- 점수입니다.
다중 클래스용 f1-점수는 한 클래스를 양성, 나머지를 음성으로 간주하여 클래스마다 f1-점수를 계산하고 클래스별 점수를 평균을 냅니다.
평균을 내는 방법은 여러가지입니다.
macro 평균 : 클래스별 f1-score에 가중치를 주지 않음. 합의 평균
weighted 평균 : 클래스별 샘플 수로 가중치를 두어 f1-score 점수의 평균을 계산
micro 평균 : 모든 클래스의 FP, FN, TP의 총 수로 정밀도, 재현율, f1-score를 계산
회귀의 평가 지표
회귀의 평가 지표는 R^2으로 충분합니다.
수고하셨습니다~!
