
1. 기본환경 : Google Colab or Jupyter
1. 학습내용
- make_forge, make_wave 데이터셋으로 분포 확인
- 최근접 이웃(KNN)
- train/test로 쪼개기(spilt)
- 훈련 데이터 및 테스트 데이터 정확도 판별
- 웨이브 데이터셋 - 회귀 분석
- 선형 회귀 분석
- 릿지(규제) 회귀 분석
- 라쏘(규제) 회귀 분석
2. 주요코드
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
!pip install mglearn
# 지도 학습 알고리즘
import mglearn
X, y = mglearn.datasets.make_forge() #데이터 생성(X = feature, y = label(색이나 모양))
mglearn.discrete_scatter(X[:,0], X[:,1], y) #X0 : 가로축 , X1 : 세로축
plt.xlabel('First')
plt.ylabel('Second')
plt.legend()
print(X.shape)
X, y = mglearn.datasets.make_wave(n_samples=40) #샘플 갯수
plt.plot(X, y, 'o')
plt.ylim(-3, 3)
plt.xlabel('Feature')
plt.ylabel('Label')
print(X.shape)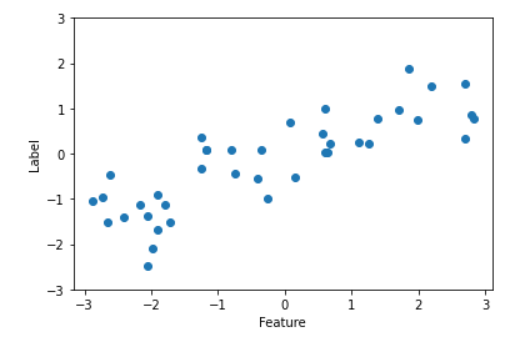
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
print(cancer.keys())
# cancer.target #양성 malignant #음성 benign
# cancer.target_names
# cancer.feature_names
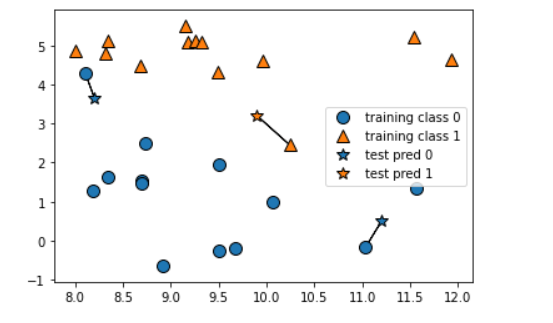
mglearn.plots.plot_knn_classification(n_neighbors=1)
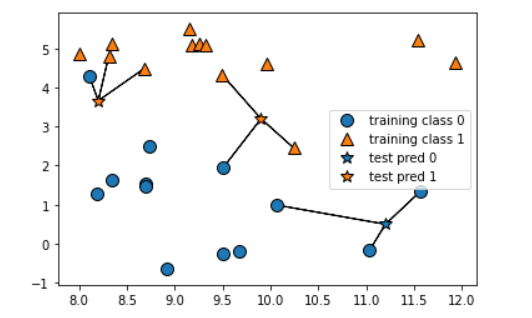
mglearn.plots.plot_knn_classification(n_neighbors=3) # 보통 과반수를 위해서 홀수로 숫자를 지정한다
from sklearn.model_selection import train_test_split #train 및 test로 쪼갠다
X, y = mglearn.datasets.make_forge()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
from sklearn.neighbors import KNeighborsClassifier #분류로 클래시파이어 사용
clf = KNeighborsClassifier(n_neighbors=1)
clf.fit(X_train, y_train)
fig, axes = plt.subplots(1,3, figsize=(10,3)) #fig 그림판 자체의 객체, subplots 그림을 여러개, figsize 그림사이즈, axes 축
for n_neighbors, ax in zip([1,3,9], axes):
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=0.4)
mglearn.discrete_scatter(X[:,0], X[:,1], y, ax=ax)
plt.xlabel('First')
plt.ylabel('Second')

from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=66)
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1, 11)
for n_neighbors in neighbors_settings:
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train, y_train)
training_accuracy.append(clf.score(X_train, y_train)) #학습 정확도
test_accuracy.append(clf.score(X_test, y_test)) #테스트 정확도
plt.plot(neighbors_settings, training_accuracy, label='training accuracy')
plt.plot(neighbors_settings, test_accuracy, label='test accuracy')
plt.legend()
plt.xlabel('n_neighbors')
plt.ylabel('Accuracy')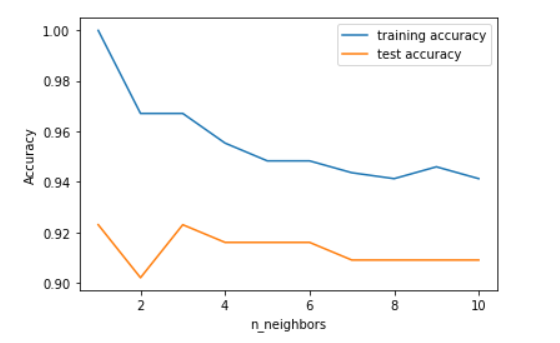
mglearn.plots.plot_knn_regression(n_neighbors=1)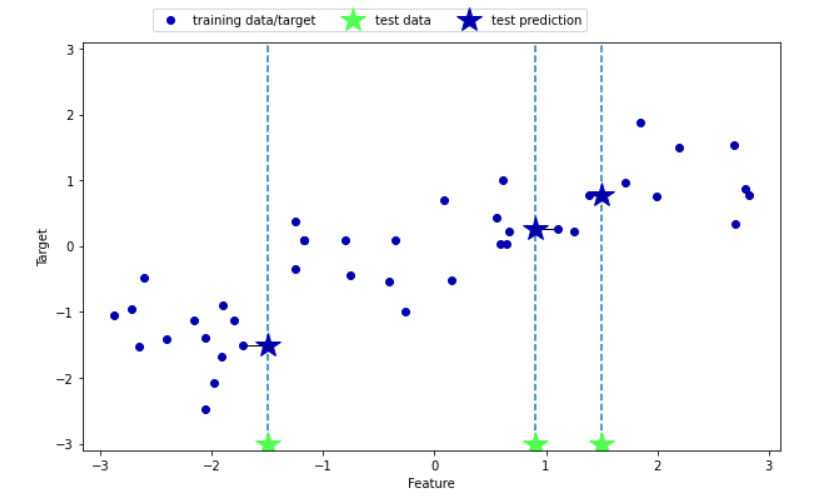
mglearn.plots.plot_knn_regression(n_neighbors=3)
from sklearn.neighbors import KNeighborsRegressor
X, y = mglearn.datasets.make_wave(n_samples=40)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
reg = KNeighborsRegressor(n_neighbors=3)
reg.fit(X_train, y_train)
reg.predict(X_test)
reg.score(X_test, y_test)fig, axes = plt.subplots(1, 3, figsize = (15, 4))
line = np.linspace(-3, 3, 1000).reshape(-1, 1)
for n_neighbors, ax in zip([1,3,9], axes):
reg = KNeighborsRegressor(n_neighbors=n_neighbors)
reg.fit(X_train, y_train)
ax.plot(line, reg.predict(line)) #선연결
ax.plot(X_train, y_train, '^', markersize=8) #삼각형
ax.plot(X_test, y_test, 'v', markersize=8) #초록삼각형끼리 연결했을때 얼마나 선이랑 수렴하는지에 따라 정확도가 달라짐
ax.set_xlabel('feature')
ax.set_ylabel('target')
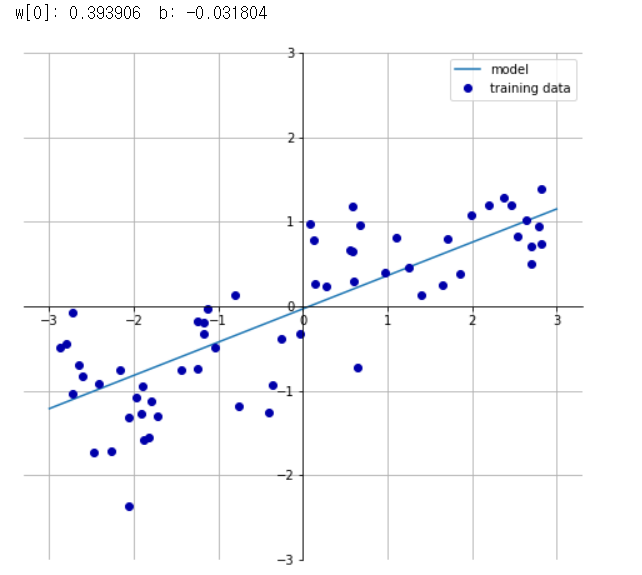
mglearn.plots.plot_linear_regression_wave()
from sklearn.linear_model import LinearRegression
X, y = mglearn.datasets.make_wave(n_samples=60)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42) #쪼개고
lr = LinearRegression().fit(X_train, y_train) #학습을 시켜놓는다
print(lr.score(X_train,y_train)) #훈련 정확도
print(lr.score(X_test, y_test)) #테스트 정확도
print(lr.coef_) #기울기
print(lr.intercept_) #절편
X, y = mglearn.datasets.load_extended_boston()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
lr = LinearRegression().fit(X_train, y_train)
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))
# Ridge / 릿지(회귀) *규제(제약)가 추가됨
from sklearn.linear_model import Ridge
ridge = Ridge().fit(X_train, y_train)
print(ridge.score(X_train, y_train))
print(ridge.score(X_test, y_test))
ridge10 = Ridge(alpha = 10).fit(X_train, y_train) #알파값이 높을수록 제약이 높음 그래서 학습이 잘됨 (alpha10은 자유도 높음)
print(ridge10.score(X_train, y_train))
print(ridge10.score(X_test, y_test))ridge01 = Ridge(alpha = 0.1).fit(X_train, y_train)
print(ridge01.score(X_train, y_train))
print(ridge01.score(X_test, y_test))#제약(alpha)을 많이 걸면 데이터가 튀지않음(편차가 적어짐)
plt.plot(ridge.coef_, 's', label='Ridge alpha=1')
plt.plot(ridge10.coef_, '^', label='Ridge alpha=10')
plt.plot(ridge01.coef_, 'v', label='Ridge alpha=0.1')
plt.legend()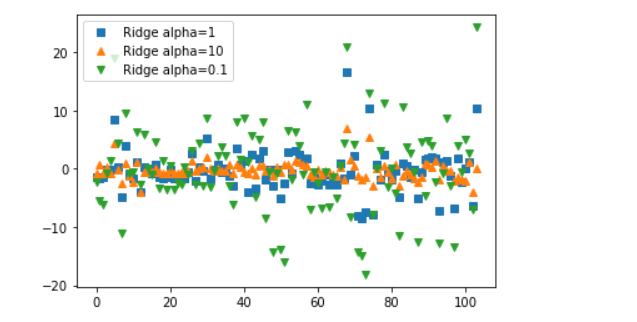
# Lasso(라쏘) 회귀 알고리즘
from sklearn.linear_model import Lasso
lasso = Lasso().fit(X_train, y_train)
print(lasso.score(X_train,y_train)) #각각 확인해볼것
print(lasso.score(X_test,y_test)) #각각 확인해볼것
lasso001 = Lasso(alpha=0.01).fit(X_train, y_train)
print(lasso001.score(X_train,y_train)) #각각 확인해볼것
print(lasso001.score(X_test,y_test)) #각각 확인해볼것
lasso00001 = Lasso(alpha=0.0001).fit(X_train, y_train)
print(lasso00001.score(X_train,y_train)) #각각 확인해볼것
print(lasso00001.score(X_test,y_test)) #각각 확인해볼것
lasso0 = Lasso(alpha=0).fit(X_train, y_train)
print(lasso0.score(X_train,y_train)) #각각 확인해볼것
print(lasso0.score(X_test,y_test)) #각각 확인해볼것
#분류에 대한 선형 모델
from sklearn.linear_model import LogisticRegression #LogisticRegression은 회귀 기법을 이용해서 분류(classification)하는 거
from sklearn.svm import LinearSVC #
X, y = mglearn.datasets.make_forge() #샘플데이터 생성
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
for model, ax in zip([LinearSVC(), LogisticRegression()], axes):
clf = model.fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=False, eps=0.5, alpha=0.7, ax=ax)
mglearn.discrete_scatter(X[:,0], X[:,1], y, ax=ax)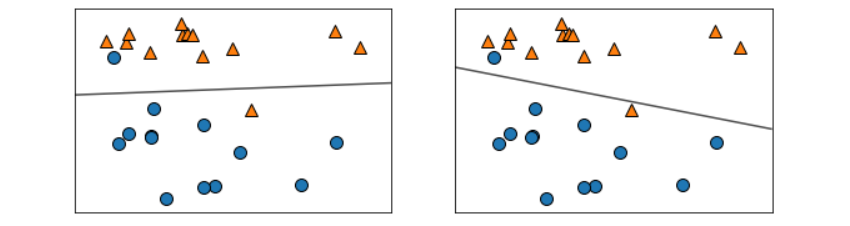
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=42)
logreg = LogisticRegression(max_iter = 5000).fit(X_train, y_train)
print(logreg.score(X_train, y_train)) #확인!
print(logreg.score(X_test, y_test)) #확인!mglearn.plots.plot_linear_svc_regularization()
#정규화(다음 수업에 더 자세히 설명해주신다고 함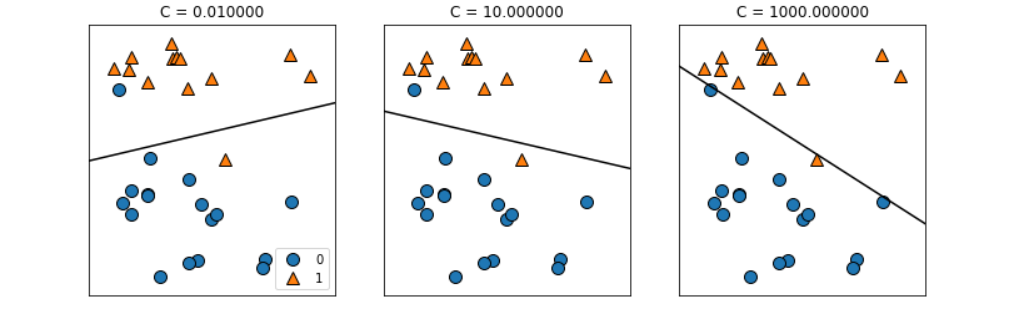
3. 금일소감
- 분류 및 회귀 이론 어려움
- 코드 자체를 하나하나 이해하기보다는 크게 봐야함
- 다 외우면 좋지만 그것보다는 구글링의 중요성이 절실
- 실제로 클라우드 이용하면 ML알아서 자동화됨

필요하다면 공부하는 개발자, 한승준