Exploring Dual Encoder Architectures for Question Answering
딥러닝에서 검색모델은 아주 초기에 인코더 하나만 가지고 진행했었다. 이후 인코더가 두 개 붙는 검색모델이 등장했다.
여기에서는 MSMARCO, NQ, SQuAD, TriviaQA, HotpotQA, SearchQA 데이터를 들어서 듀얼모델에서 share 지점에 따라 점수가 변화되는 양상을 보여준다.
- SDE & ADE
SDE (Siamese Dual Encoder): Weight share 하는 구조
ADE (Asymmetric Dual Encoder): Weight share 하지 않는 구조

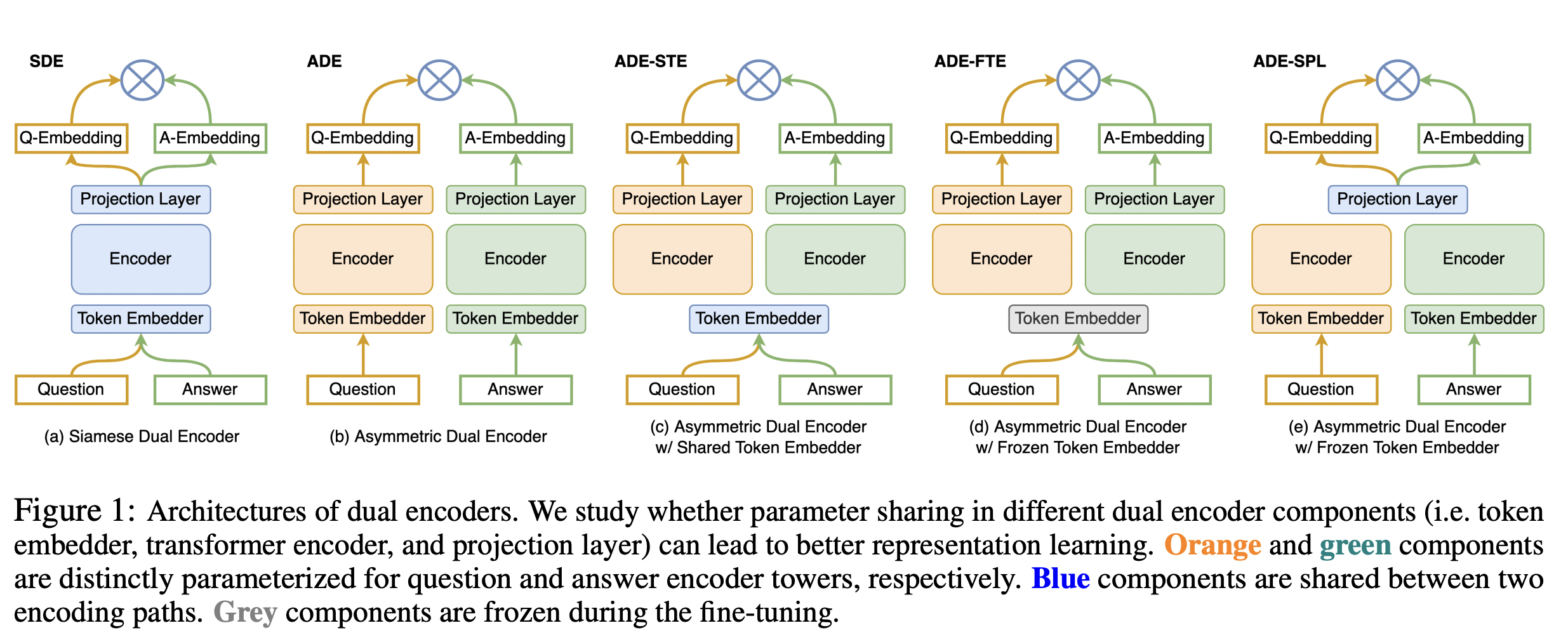 여기에 있는 다섯 개의 그림은 기본적으로 이미 학습된 언어모델로 초깃값을 가지고 finetuning하는 방식으로 학습이 진행된다. 파란색은 쉐어한다는 것을 말한다. (a)와 다르게 (b)는 weight share 하지 않고 있는 것을 그림을 통해서 볼 수 있다. (c)는 임베딩만을 같이 사용하고 있다. (d) 임베딩을 고정하고 학습하는 방식이다. (e)는 projection layer를 공유한다.
여기에 있는 다섯 개의 그림은 기본적으로 이미 학습된 언어모델로 초깃값을 가지고 finetuning하는 방식으로 학습이 진행된다. 파란색은 쉐어한다는 것을 말한다. (a)와 다르게 (b)는 weight share 하지 않고 있는 것을 그림을 통해서 볼 수 있다. (c)는 임베딩만을 같이 사용하고 있다. (d) 임베딩을 고정하고 학습하는 방식이다. (e)는 projection layer를 공유한다.
Experiments
Adafactor optimizer 사용하는데, 역전파를 진행할 때 adam optimizer에 비해 대략 50% 적은 파라미터를 사용한다. 성능은 유사하거나 조금 낮은 옵티마이저이다. (대용량에서 특히 더 잘 사용된다.)
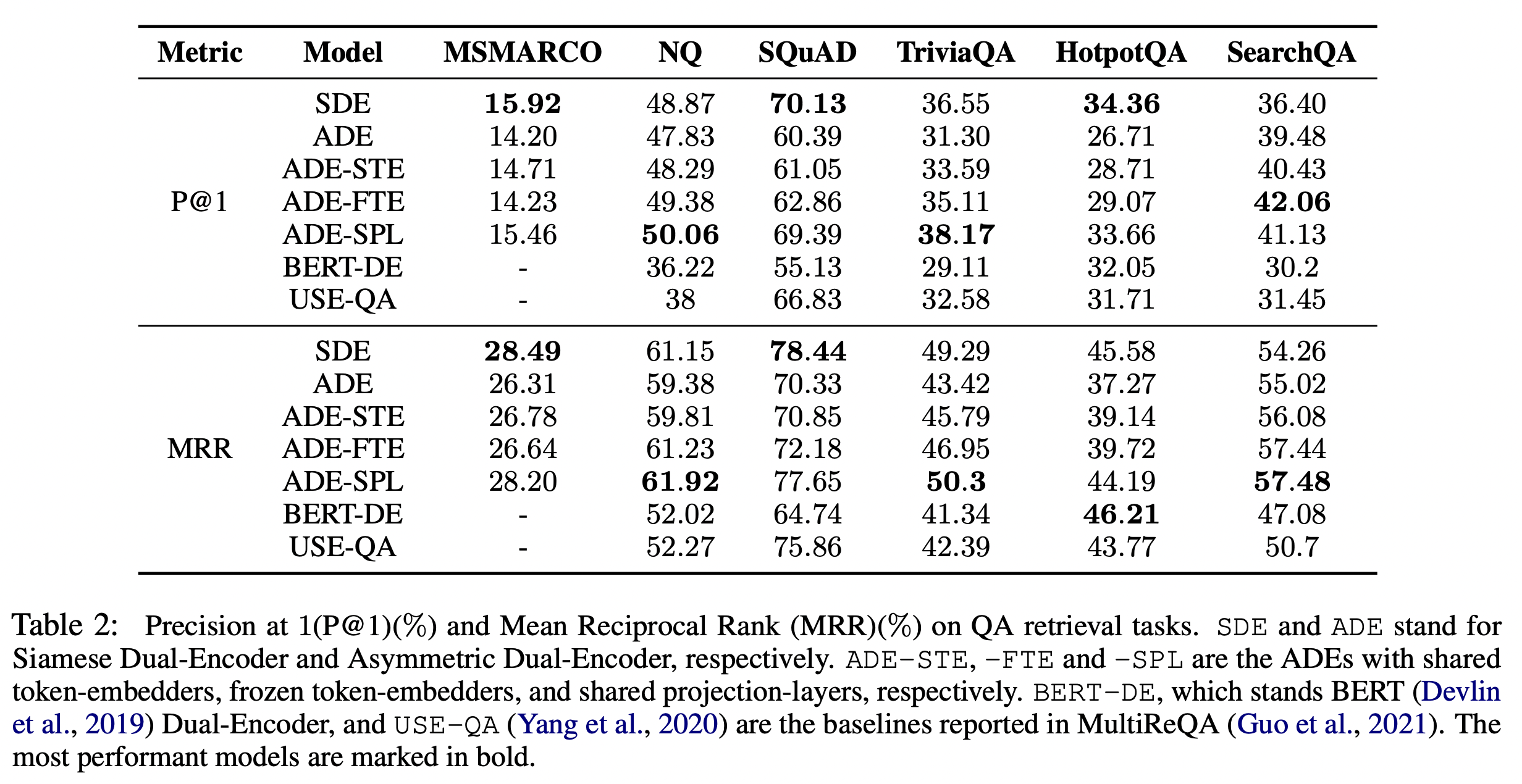
- SDE > ADE 양상을 보여주고 있다.
- 특정 데이터의 경우 ADE-SPL의 경우 더 성능이 좋아진다. (NQ, TriviaQA)
- 이런 것을 보면 위 다섯 개의 모델 중 SDE, ADE-SPL이 다른 모델보다 우위에 있다.
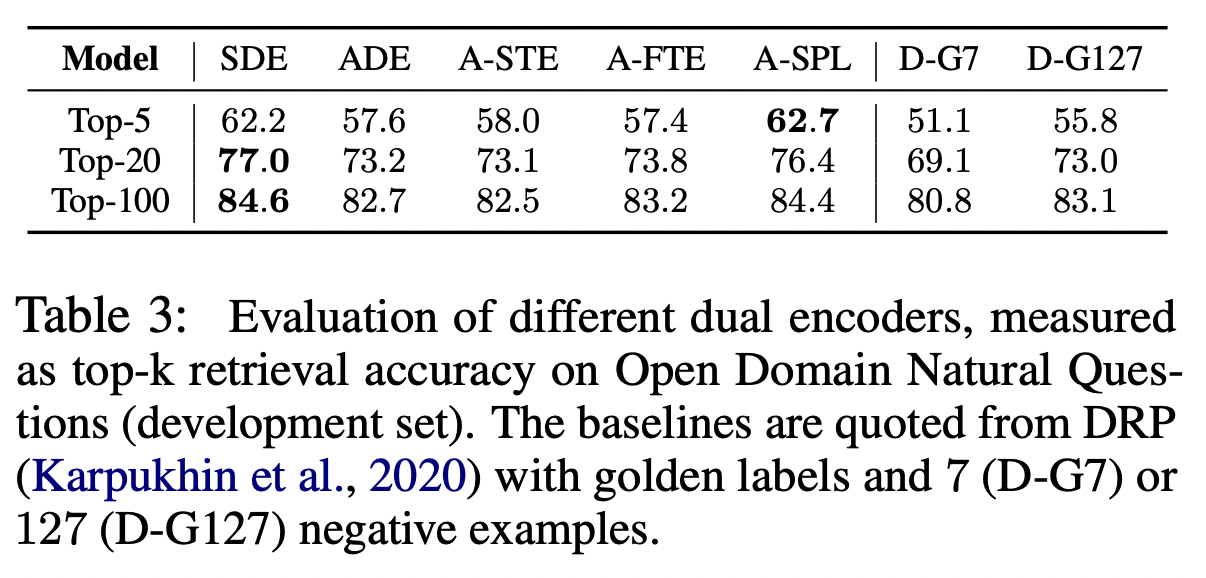
D-G7, D-G127는 오른쪽에 negative sample이 들어간 갯수를 보여주는데, negative를 많이 쓸 수록 성능이 높아진다.
Projection layer를 공유하는 SDE, ADE-SPL은 같은 양상을 가지고 있다. 결국에는 연결 다리가 반드시 필요하다. Token embedding을 쉐어하는 경우에는 성능에 좋은 효과로까지 연결되지 않는다.

표로 점수를 비교해보아도 대체적으로 SDE, ADE-SPL가 전반적으로 좋은 편이고, ADE가 성능이 가장 낮다.
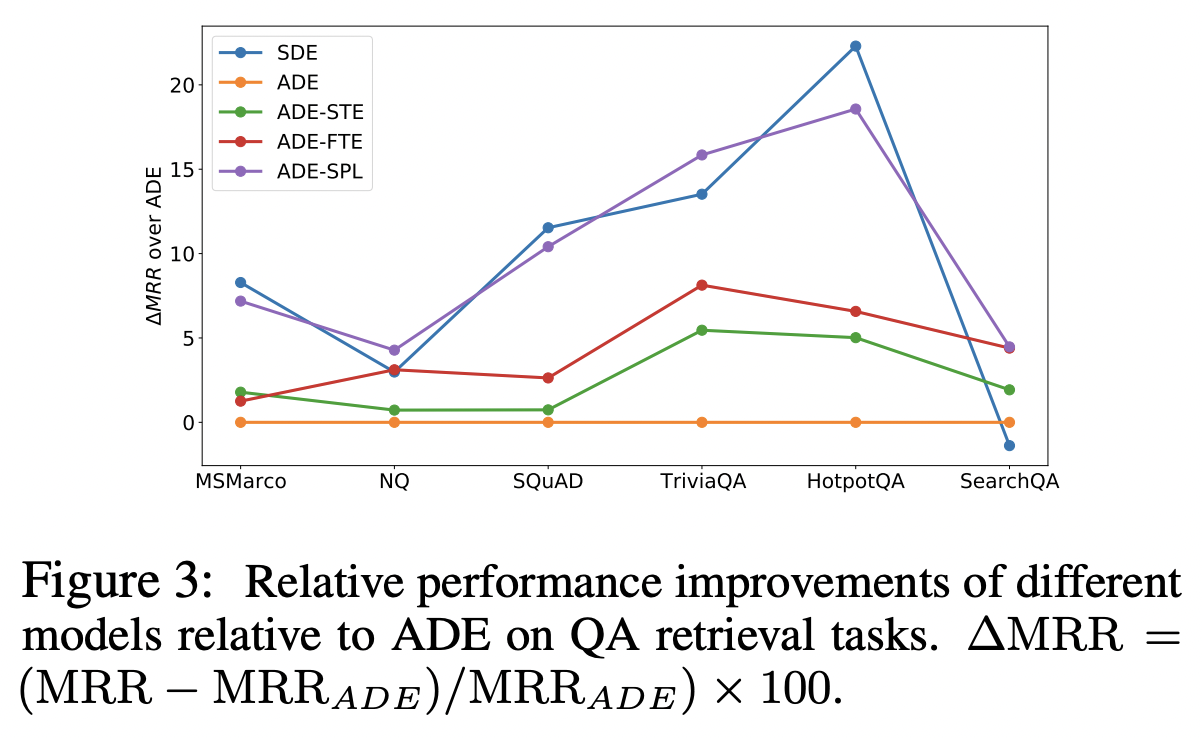
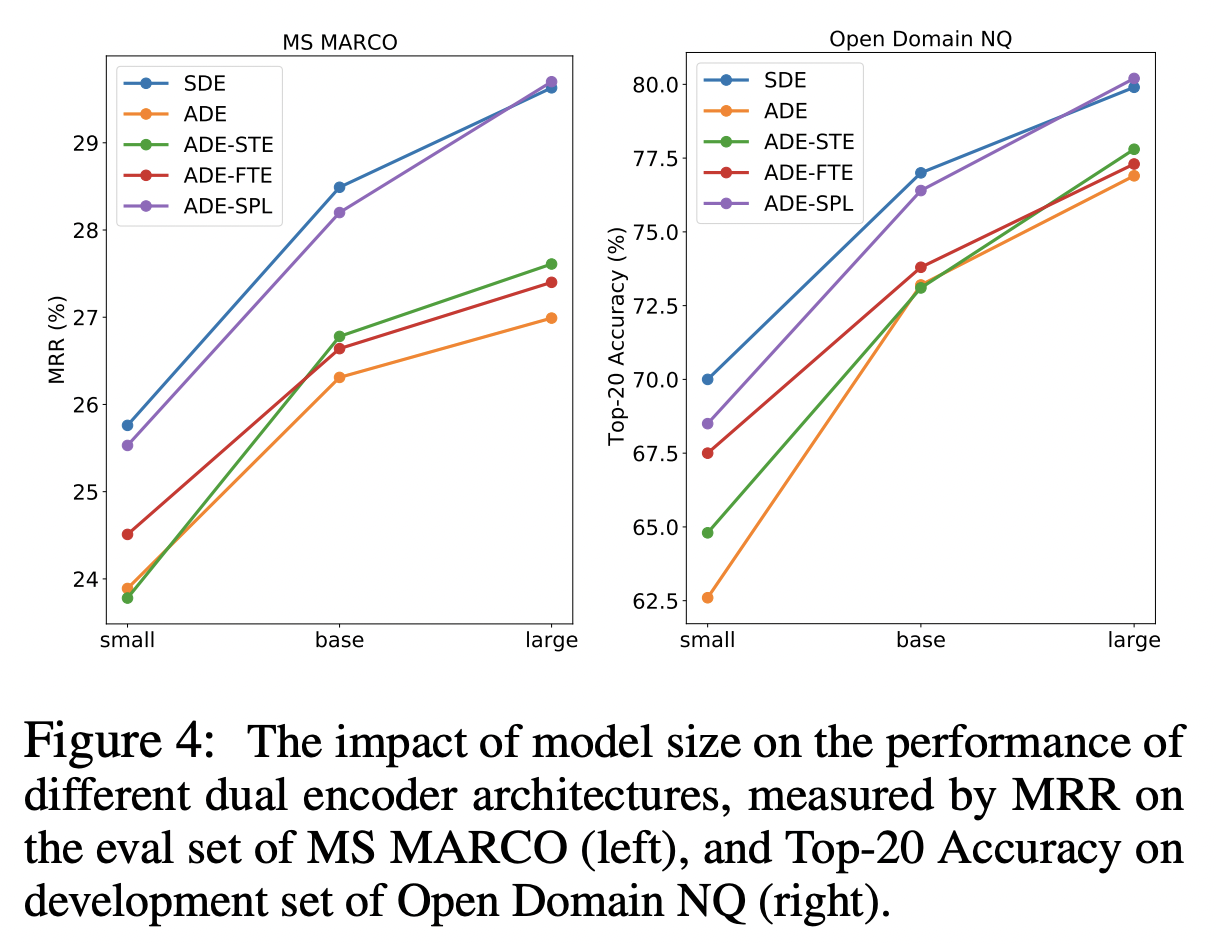
모델의 크기가 클수록 성능은 올라간다.
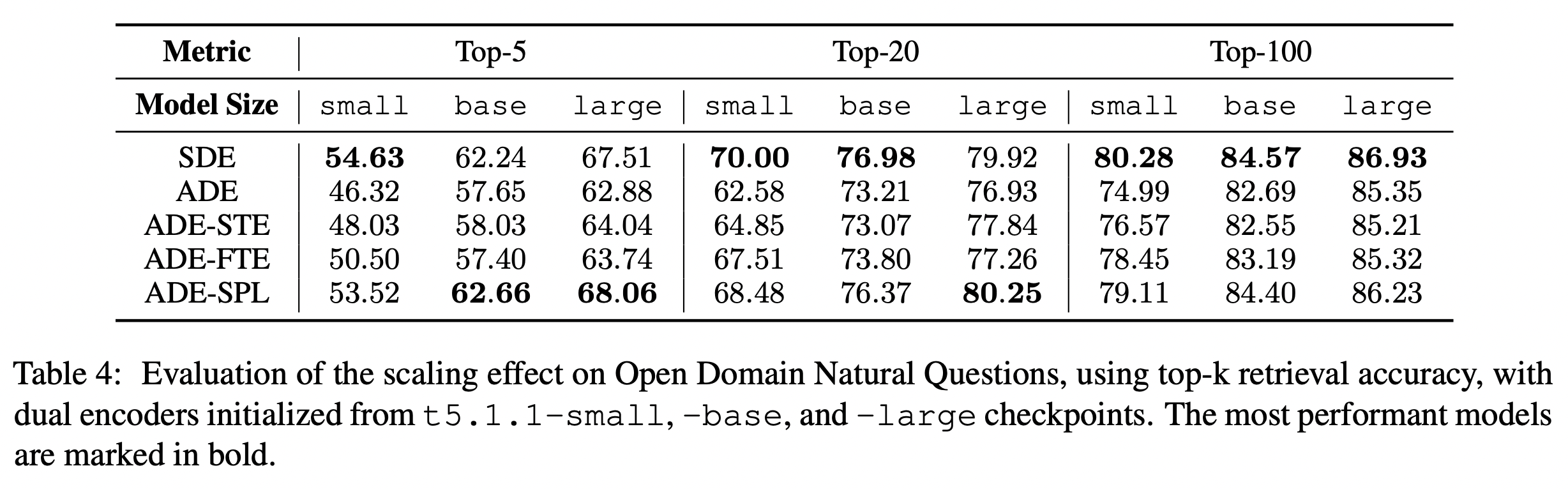
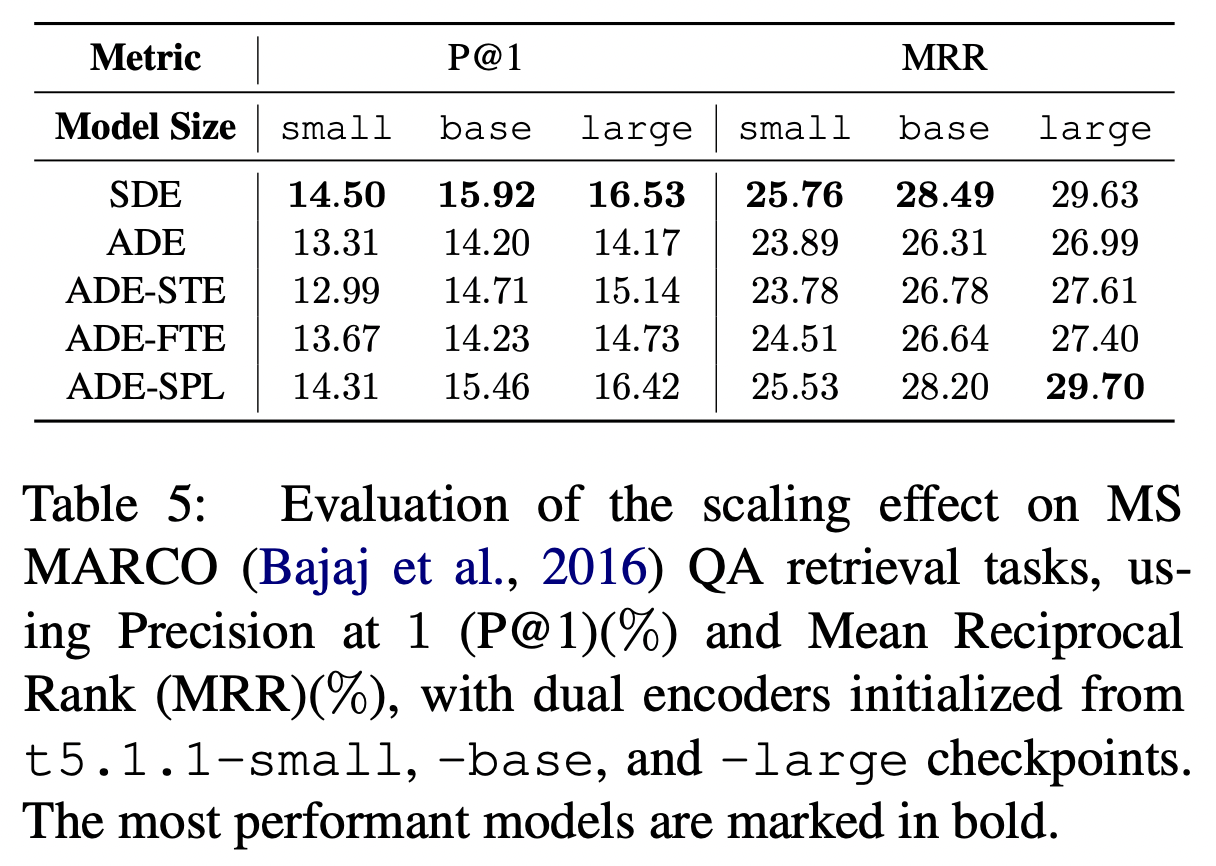
모델이 커질수록 ADE-SPL이 SDE를 우위하는 성능을 가지고 있다.

산미 있는 커피를 좋아하는 자연어처리 엔지니어. 일상 속에서 요가와 따릉이
를 좋아합니다. 인간의 언어를 이해하고 생성하는 AI 기술 발전을 위해 노력하고 있습니다. 🧘♀️🚲☕️💻