[NLP 논문리뷰] Improved Universal Sentence Embeddings with Prompt-based Contrastive Learning and Energy-based Learning
(질문) energy based, 창욱님 질문
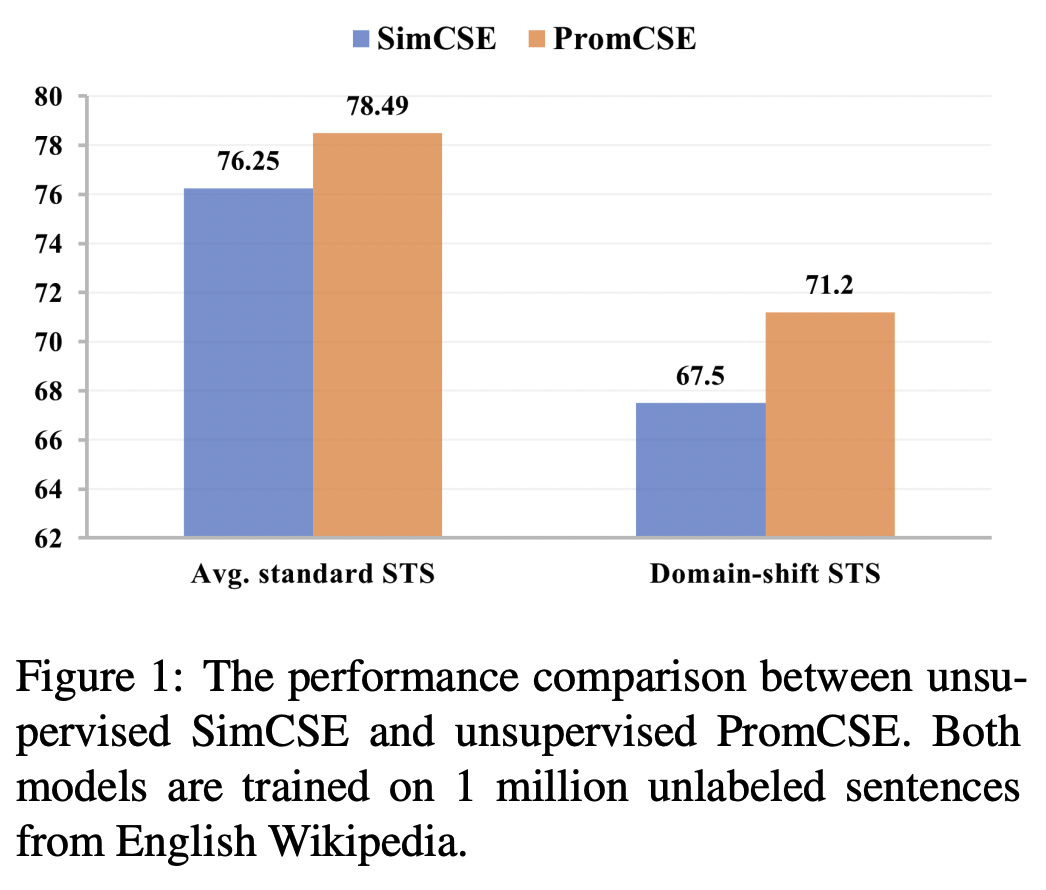
STS task에서 또 다른 SOTA 모델이 등장하였다. (ACL 2023 main)
여기서는 기존 STS task에 사용되는 contrastive 방법이 두 가지 한계가 있다고 보았다.
1. Over-parameterization of PLMs
2. 지도학습에서 기존 방식으로는 hard negative을 충분히 이용하지 못하고 있음.
위 문제를 해결하기 위해서 아래와 같이 두 가지 방법을 이용하였다.
1. Small-scale soft prompt (PLMs fixed)
2. Energy-based Learning
PromCSE
Prompt-based Contrastive Learning
파라미터가 많은 경우 모델 튜닝이 과적합의 문제를 일으킬 수 있다는 점을 지적하고 있다. 이런 경우에 domain shift에는 유리하면서 파인튜닝 성능과 비슷한 성능을 보이는 Prompt tuning(a frozen PML with Soft Prompt) 이 연구되어왔다. 일반적인 언어에 대해서 잘 이해하고 있는 핵심적인 부분을 유지하면서 문제를 해결하는 방식이라고 할 수 있다.
(한솔 : BERT 정도의 경우 파인튜닝과 과적합을 연결짓는 것이 적절한지에 대해 충분히 더 논의되어야한다고 생각함)
이렇게 학습을 진행해서, 특정 작업에 대한 어휘를 외우고 나서도 가짜 상관관계를 통해 문제를 해결하는 것을 방지할 수 있도록 하였다.
- Frozen PLM
- Prepended soft prompt
- 여기에서 soft prompt는 continuous vector를 PLM 입력값 앞에 붙이는 것을 말한다.
Prompt 넣는 것에도 다양한 방식이 있는데, 여기에서는 아래와 같은 그림처럼 input 자체에 붙이기 보다는 trainable 한 값들을 레이어마다 넣어주는 방식을 취한다.
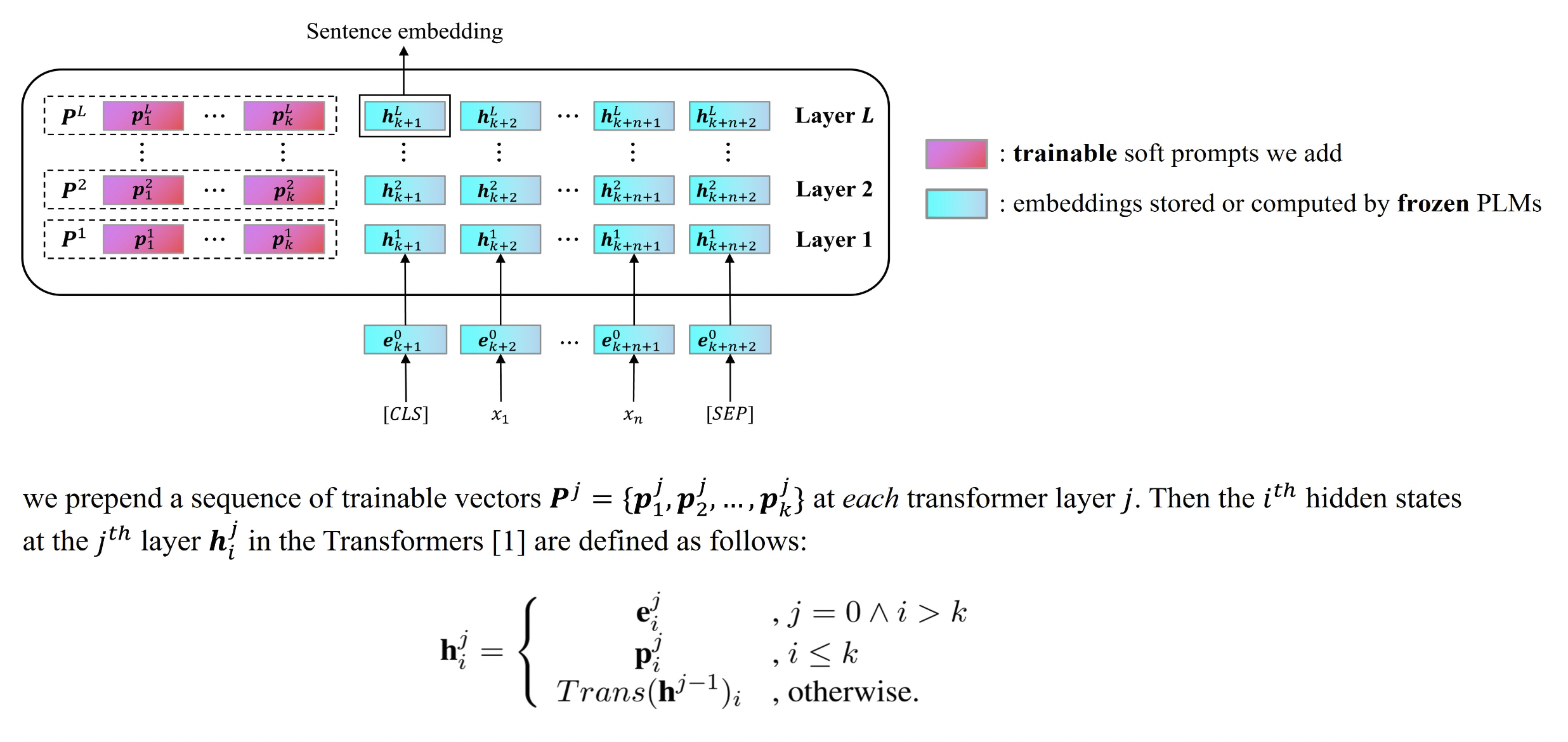
Prompt initialization : Soft prompt 에서 초깃값이 굉장히 중요하다고 하지만 이 연구에서는 거의 영향을 끼치지는 않음을 appendix에서 밝혔다.
Energy-based Hinge Loss
-
Uniformity가 낮다는 점에 주목해서, hard negative를 충분히 사용하고자 다음과 같은 로스를 도입하였다.
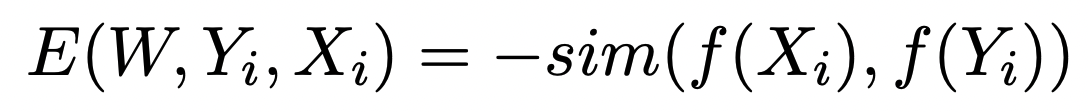
-
Negative로 들어가는 passage들 중 가장 말이 되지않는 passage를 이라고 할 때, Energy-based Hinge (EH) loss를 다음과 같이 만든다.
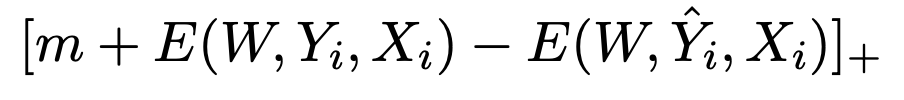
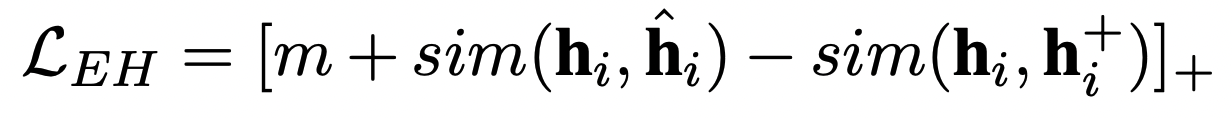
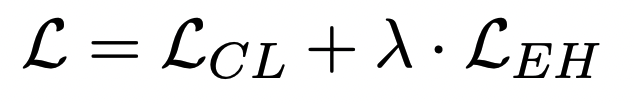
람다는 10으로 설정함
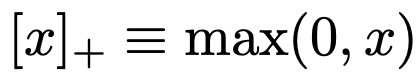
Experiments
STS task
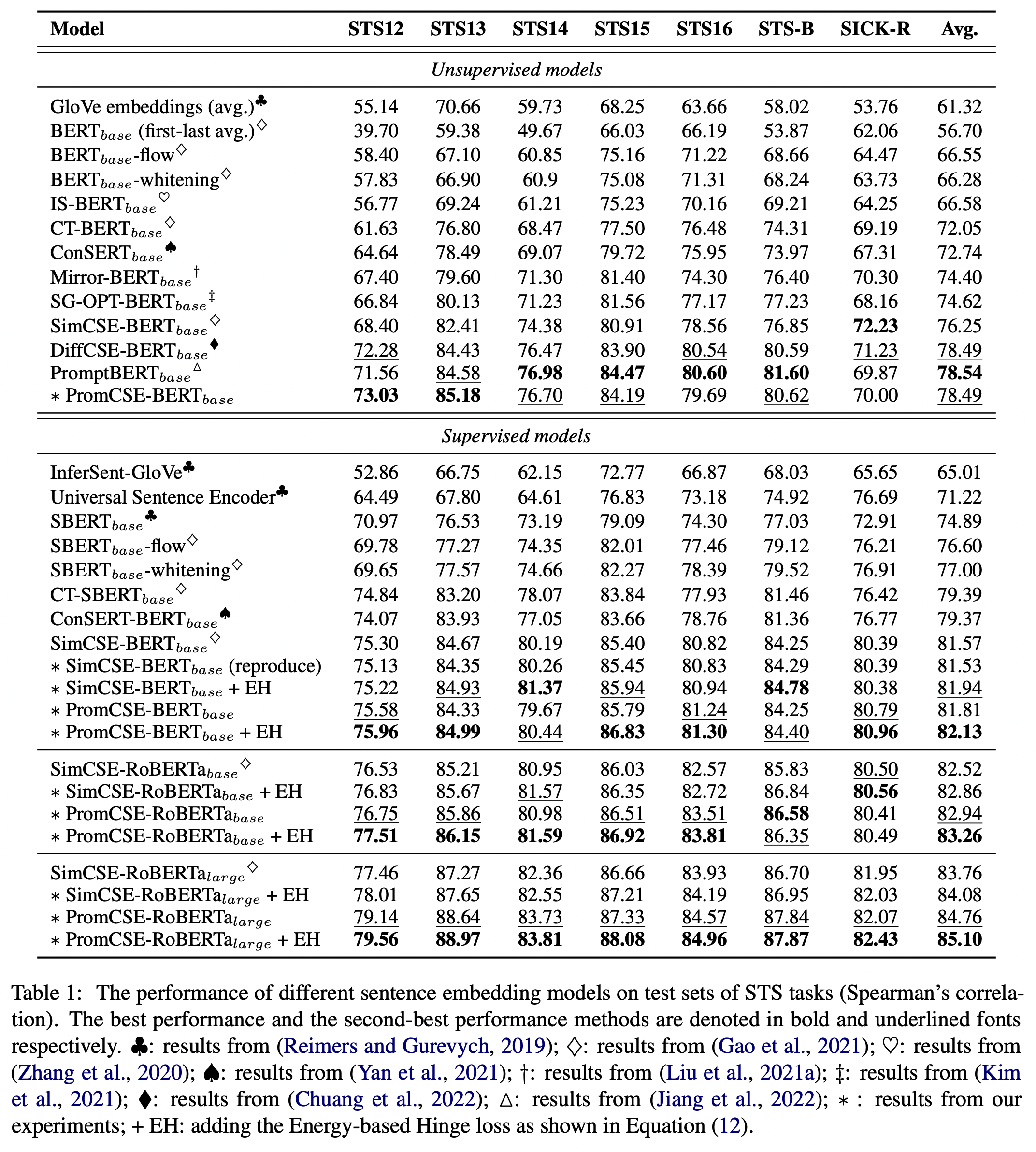
Domain-shifted STS task (CxC)
- 123287 data
- Image caption domain 에서 사용된 text 들을 STS task처럼 사용한다.
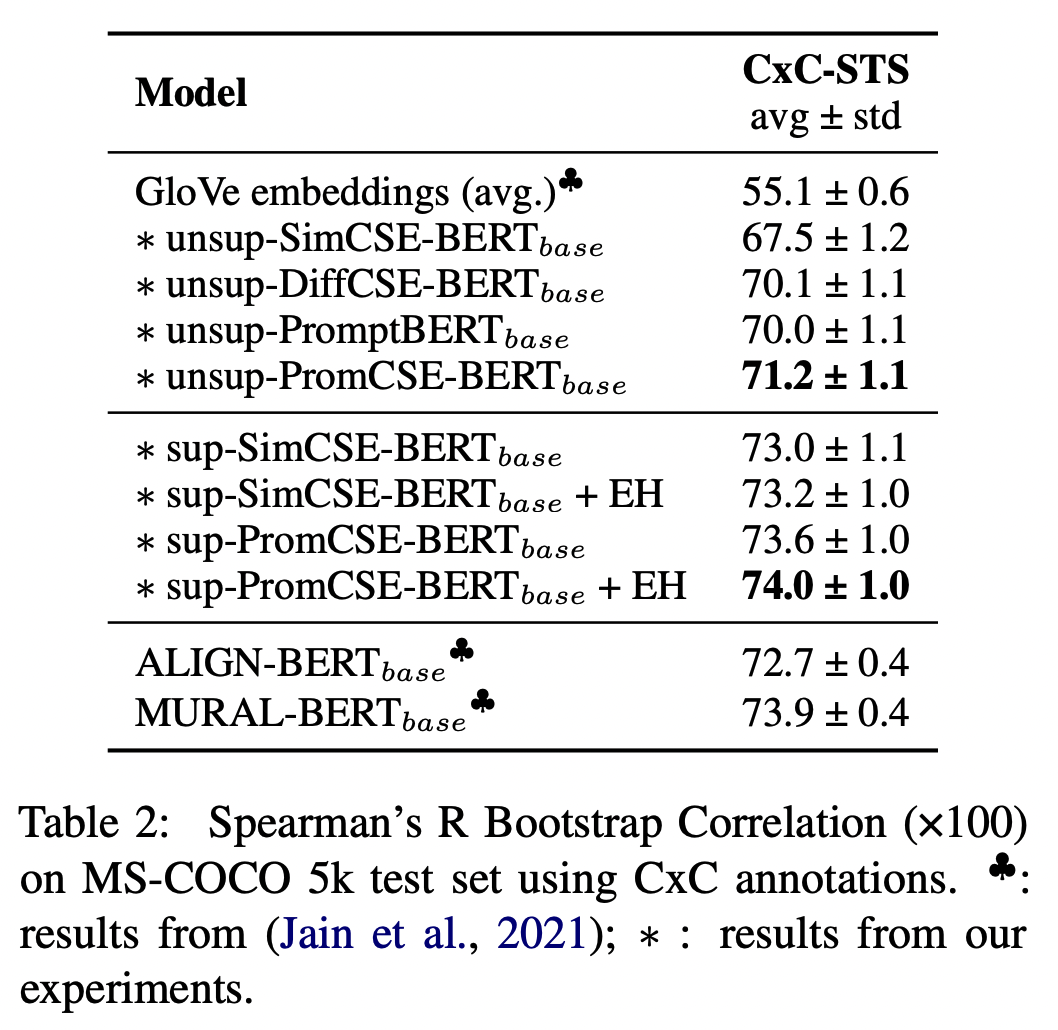
Analysis
Type of Soft Prompt
- Soft prompt를 input-layer에만 넣었을 경우에 두 task에서의 점수가 많이 떨어지는 것을 볼 수 있다.
- PromCSE에서 사용하는 Soft prompt weight share 하더라도 PromCSE 와 비교했을 때 점수가 더 좋지 않았다.
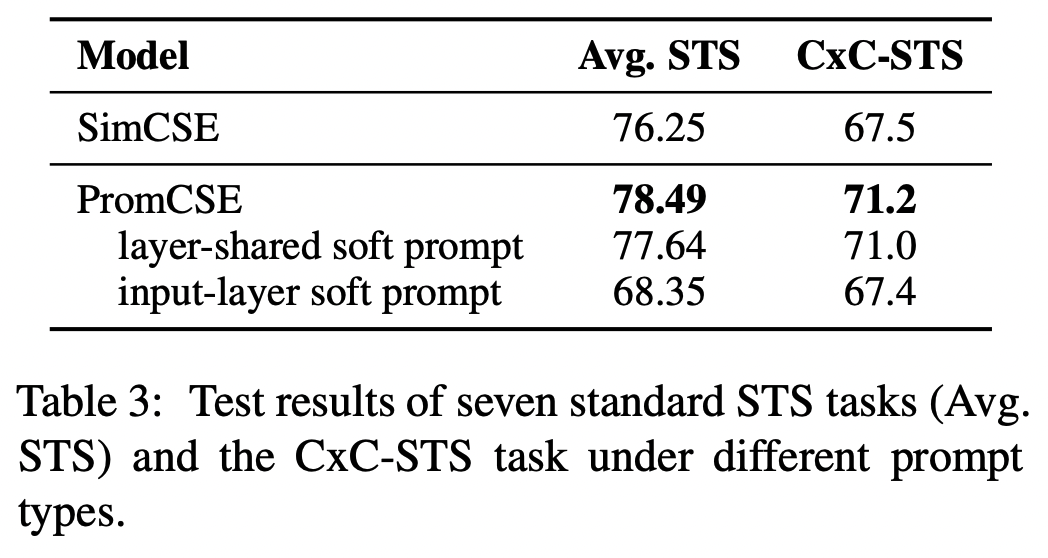
Length of Soft Prompt
- Soft prompts의 길이를 늘릴수록 점수들은 좋아지는 경향성을 보인다.
- length 12 이후에는 어느정도 saturate 된다.
- length 1로만 설정하더라도 SimCSE에 비해서 0.25%, CxC-STS 3% 향상된다.
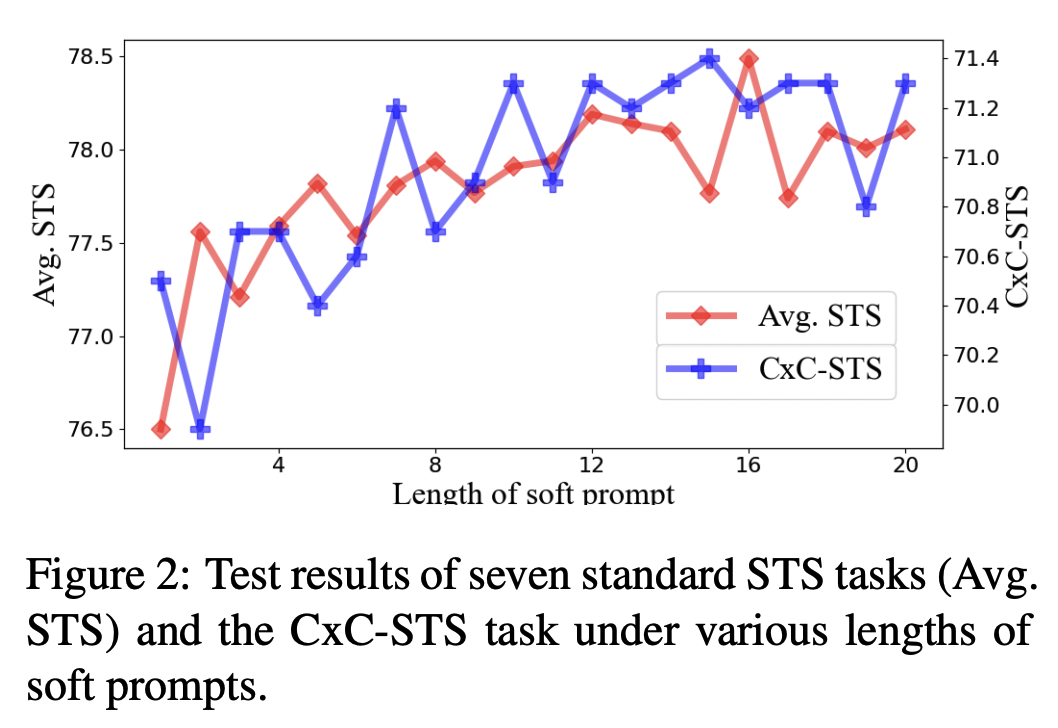
Margin
- 여기에서 m은 Energy-based Hinge loss에서 사용되는 m이다.
- m이 너무 작으면 영향을 매우 적게 미치게 되고, m이 너무 커지면 negative와의 거리를 과하게 멀도록 만들기 때문에 문제가 된다.

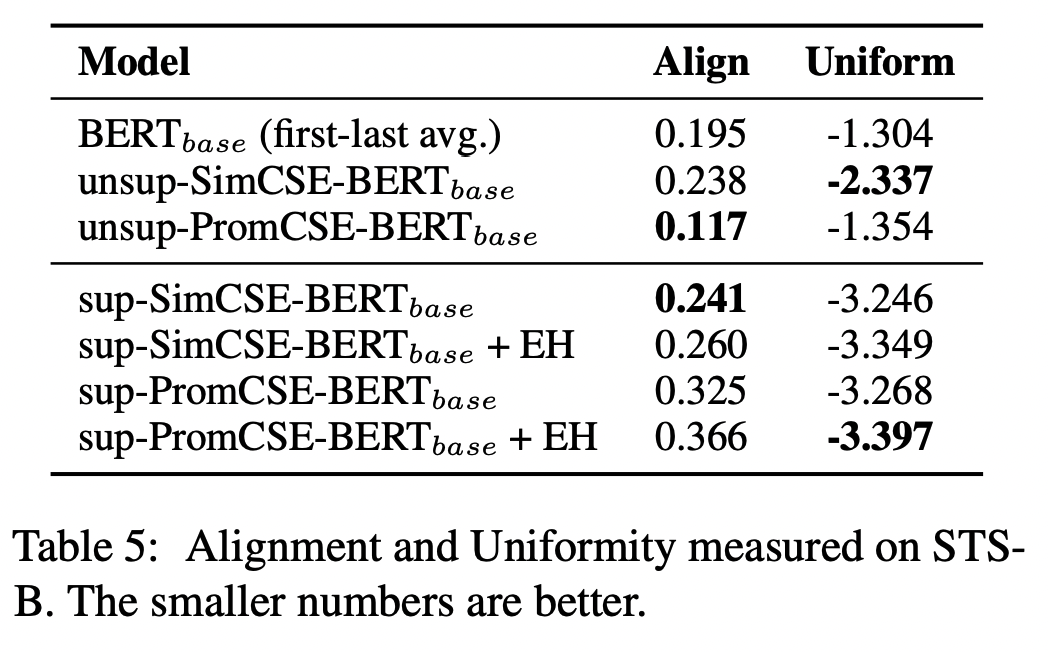
Alignment and uniformity
- SimCSE를 비롯해서 이후 STS task의 논문들은 이 두 가지를 같이 측정해주는데, alignment는 sentence representation에서 비슷한 의미의 문장이라면 가까운 거리에 위치한다는 것을 의미하고, uniformity는 다른 의미의 문장이 먼 거리의 벡터로 존재한다는 것을 말한다.
- 이 논문에서 제시하는 Energy-based Hinge loss는 지도학습의 경우에만 덧붙여져서 사용되는데, hard negative들을 더 멀리 떨어뜨리려는 의도를 가진 것처럼 실제로 Uniform 수치가 더 내려간 것을 확인할 수 있다.
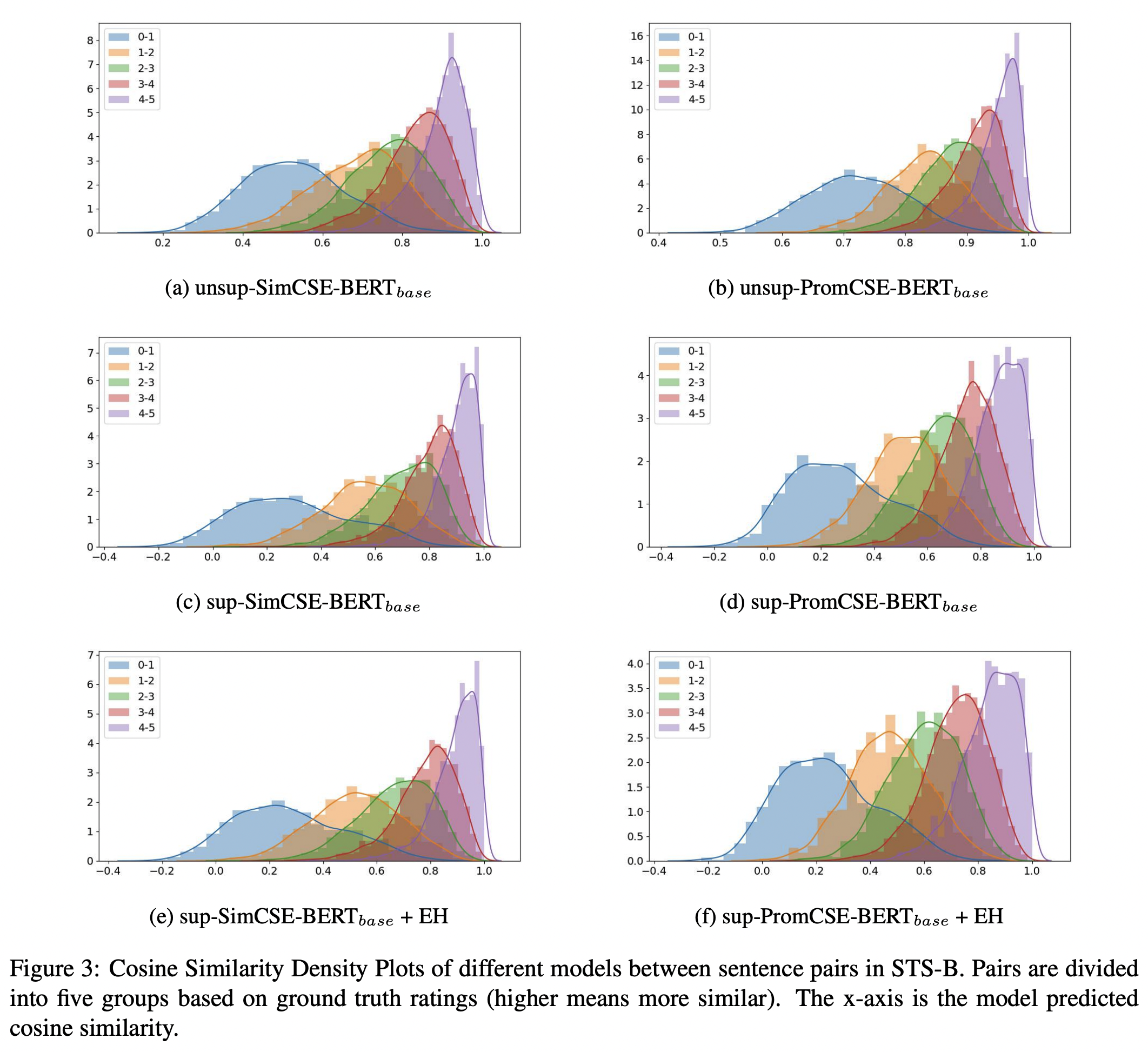
Cosine similarity Density plot (Appendix)
- STS-B task에서의 다섯 레벨에 따른 분포 (논문에 추가적인 설명이 없음)
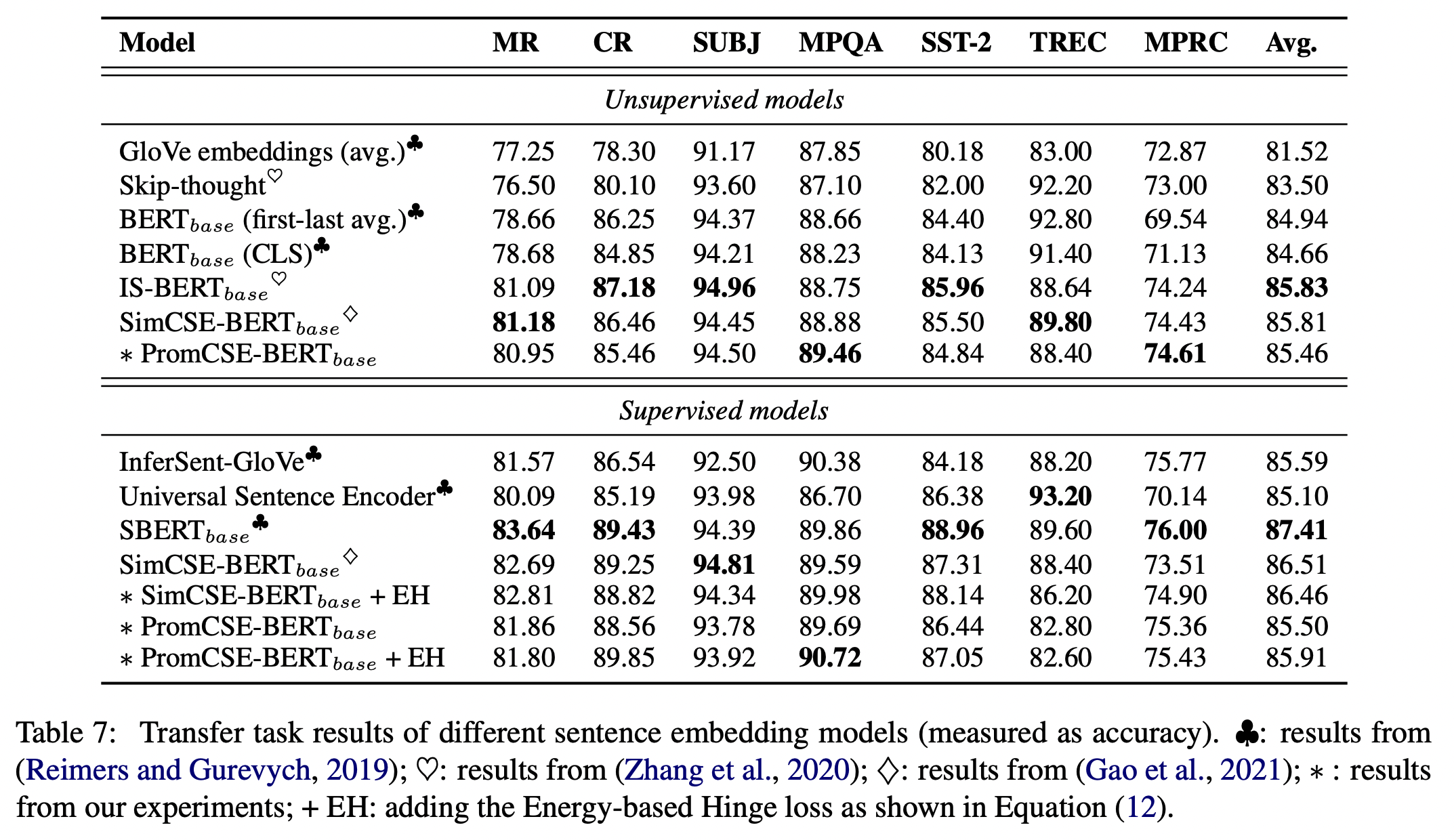
추가로 Transfer task (Appendix)
- 기존 SimCSE의 점수를 뛰어넘지 못했다.