AI - Scikit-Learn의 활용
학습 내용
Lasso Regression(회귀) 알고리즘
# Lasso / 라쏘 회귀
from sklearn.linear_model import Lasso
lasso = Lasso().fit(X_train, y_train)
print(lasso.score(X_train, y_train))
print(lasso.score(X_test, y_test))
결과)
0.29323768991114596
0.20937503255272272
#정확도가 매우 떨어진다- 제약 걸기
#alpha로 제약을 건다
lasso001 = Lasso(alpha=0.01).fit(X_train, y_train)
print(lasso001.score(X_train, y_train))
print(lasso001.score(X_test, y_test))
결과)
0.8961122320864717
0.7677995670886714
#제약을 거의 주지 않으니까 정확도가 매우 올라갔다.# alpha=0.01 제약 걸고
# max_iter로 반복하는 횟수 추가
lasso001 = Lasso(alpha=0.01, max_iter=50000).fit(X_train, y_train)
print(lasso001.score(X_train, y_train))
print(lasso001.score(X_test, y_test))
결과)
0.8962226511086498
0.7656571174549986
#결과값이 조금 달라졌다- 제약 줄이기
#제약을 더 줄여본다
lasso00001 = Lasso(alpha=0.0001).fit(X_train, y_train)
print(lasso00001.score(X_train, y_train))
print(lasso00001.score(X_test, y_test))
결과)
0.9420931515237063
0.6976541391663641
# 학습정확도는 올라갔는데 오히려 테스트정확도는 떨어졌다.
# 주어진 학습용 데이터에 최적화되었기 때문에
# 다른 데이터인 테스트 데이터의 정확도는 떨어지게 되었다.# alpha=0.0001 제약
# max_iter 반복하는 횟수 추가
lasso00001 = Lasso(alpha=0.0001, max_iter=50000).fit(X_train, y_train)
print(lasso00001.score(X_train, y_train))
print(lasso00001.score(X_test, y_test))
결과)
0.9507158754515462
0.6437467421273156
#학습 정확도가 조금 올라갔고 테스트 정확도는 조금 내려갔다- 제약 없애기
# 제약을 아예 없애본다
lasso0 = Lasso(alpha=0).fit(X_train, y_train)
print(lasso0.score(X_train, y_train))
print(lasso0.score(X_test, y_test))
결과)
0.9426383219008584
0.6916323869060212
#Lasso(alpha=0.0001)의 결과와 비교하자면
#마찬가지로 학습정확도는 약간 올라갔고 테스트정확도는 약간 떨어졌다.lasso01 = Lasso(alpha=0.1, max_iter=50000).fit(X_train, y_train)
print(lasso01.score(X_train, y_train))
print(lasso01.score(X_test, y_test))
결과)
0.7709955157630054
0.6302009976110041
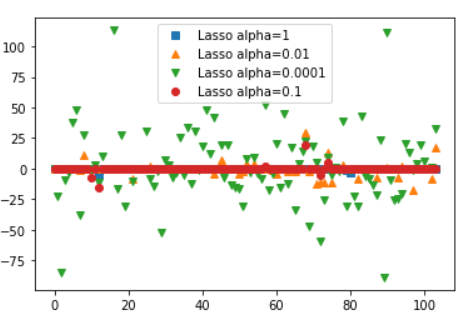
# 둘 다 떨어졌다- lasso에 대한 요소의 결정 개수를 본다.
plt.plot(lasso.coef_, 's', label='Lasso alpha=1')
plt.plot(lasso001.coef_, '^', label='Lasso alpha=0.01')
plt.plot(lasso00001.coef_, 'v', label='Lasso alpha=0.0001')
plt.plot(lasso01.coef_, 'o', label='Lasso alpha=0.1')
plt.legend()- 결과
Logistic Regression
#회귀 알고리즘으로 breast cancer 데이터 분석
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data,
cancer.target,
random_state=42)
logreg = LogisticRegression().fit(X_train, y_train) #제약이 없음, 기본 100번 반복
print(logreg.score(X_train, y_train))
print(logreg.score(X_test, y_test))
결과)
0.9553990610328639
0.958041958041958#반복 횟수 추가
logreg = LogisticRegression(max_iter=5000).fit(X_train, y_train) #5000번 반복
print(logreg.score(X_train, y_train))
print(logreg.score(X_test, y_test))
결과)
0.9624413145539906
0.965034965034965
# 정확도가 조금 올라갔다# 하이퍼 파라미터 C 옵션을 추가
# C는 오류에 대한 허용치, C값이 클수록 알고리즘 내에서 오류를 허용하지 않겠다는 뜻
# C의 디폴트값은 1
logreg100 = LogisticRegression(max_iter=5000, C=100).fit(X_train, y_train)
print(logreg100.score(X_train, y_train))
print(logreg100.score(X_test, y_test))
결과)
0.9788732394366197
0.965034965034965
#제약이 디폴트 값일 때와 비슷한 결과가 나왔다
#디폴트 값(제약 1) 안에서 오류가 잡히고 있다는 뜻# 제약을 0.01로 변경(제약을 약하게)
logreg001 = LogisticRegression(max_iter=5000, C=0.01).fit(X_train, y_train)
print(logreg001.score(X_train, y_train))
print(logreg001.score(X_test, y_test))
결과)
0.9460093896713615
0.972027972027972
#학습 정확도는 조금 떨어졌지만
#테스트 정확도가 더 좋아졌다=> 제약을 약하게 적용하면 학습 정확도는 낮아질지라도 테스트 정확도는 높아질 수 있다.
DecisionTreeClassifier / Tree 계열 분류 알고리즘
from sklearn.tree import DecisionTreeClassifier #의사결정 나무
from sklearn.datasets import load_breast_cancer #유방암 데이터 사용
cancer = load_breast_cancer()
# 데이터를 쪼개는 작업, 데이터 준비
X_train, X_test, y_train, y_test = train_test_split(cancer.data,
cancer.target,
random_state=42)
tree = DecisionTreeClassifier() # 트리 알고리즘을 디시즌 트리로 만들어본다
tree.fit(X_train, y_train) #실제 학습시키는 코드
#훈련 정확도, 테스트 정확도 테스트
print(tree.score(X_train, y_train))
print(tree.score(X_test, y_test))
결과)
1.0
0.9440559440559441
#정확도가 굉장히 높게 나온다
#경계를 아주 잘 학습했다는 것을 알 수 있다.군집이 일정한 경우는 회귀(Regression)로 접근 가능한데
경계가 불문명한 경우는 트리 알고리즘(Clasification)이 잘 맞다
- Depth 테스트
#depth 최대 횟수를 지정 (과접합을 막음)
tree = DecisionTreeClassifier(max_depth=4, random_state=0)
tree.fit(X_train, y_train)
print(tree.score(X_train, y_train))
print(tree.score(X_test, y_test))
결과)
0.9953051643192489
0.951048951048951
# 학습데이터 정확도는 조금 떨어졌지만 테스트 데이터 정확도는 조금 올라갔다
# 새로운 데이터에 대한 유연함이 증가하였다는 뜻
# => 뎁스를 4단계로 했을때 결과가 오히려 좋았다는 것을 볼 수 있다- 결과를 트리로 그려서 확인하기
#트리를 그리는 패키지 plot_tree
from sklearn.tree import plot_tree
plt.figure(figsize=(13,10)) # 사이즈 조정
plot_tree(tree, class_names=['A','B'], filled=tree, fontsize=10,
feature_names=cancer.feature_names)
plt.show()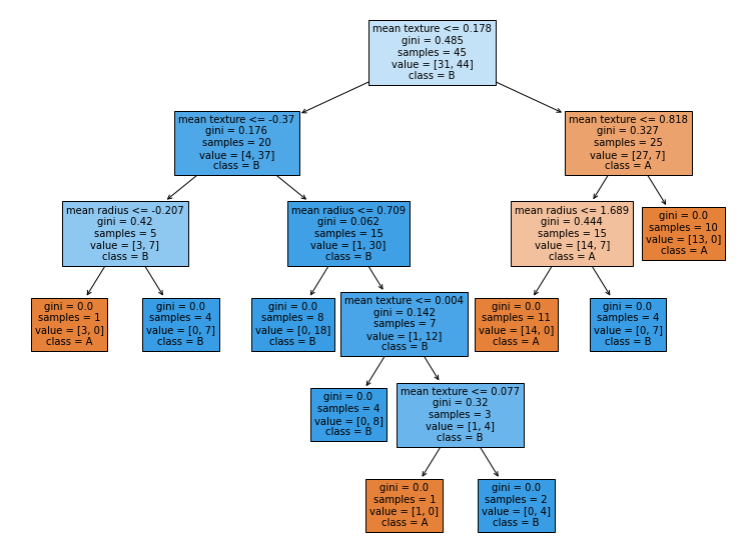
학습 후기
오늘은 학습데이터에 대한 과적합을 막기 위한 제약을 거는 방법들을 배웠다.
과적합은 알고리즘에 데이터를 학습시킬 때 과도하게 학습시켜서 학습 데이터에만 너무 딱 맞게 되어 버린 것를 말하는데 이를 방지하기 위해 알고리즘에 제약을 건다.
각 알고리즘에 맞는 제약을 걸어 테스트해보며 최적의 모델을 찾아가는 것이다.
알고리즘을 쓰는 건 아직도 어렵지만 이제는 과접합이 어떤건지 어떻게 해결할 수 있는지는 확실히 이해했다.
그리고 이제 조금 회귀와 분류 알고리즘의 특성을 알 것 같다.

열심히 하는 중