AI - Scikitlearn
학습 내용
mglearn
파이썬의 대표적인 머신러닝 라이브러리인 Scikit-learn의 개발자 중 한명인 '파이썬 라이브러리를 활용한 머신러닝'의 저자가 해당 교재를 편리하게 학습하고자 만든 라이브러리이며 테스트에 쓸 데이터를 생성하거나 시각화도 할 수 있다.
필수 패키키지가 아니라서 설치를 해야 한다.
pip install mglearn# 지도 학습 알고리즘
import mglearn
X, y = mglearn.datasets.make_forge() #인위적으로 분류 데이터를 만든다
mglearn.discrete_scatter(X[:,0], X[:,1], y)
plt.xlabel('First')
plt.ylabel('Second')
plt.legend()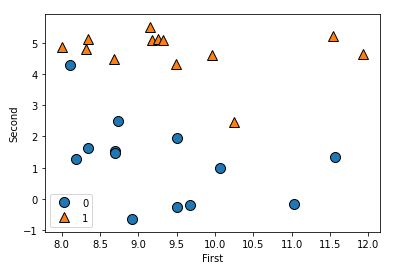
X, y = mglearn.datasets.make_wave(n_samples=40) #샘플 개수 지정
plt.plot(X, y, 'o') #X,y의 좌표를 지정하고 마크는 o를 사용
plt.ylim(-3,3)
plt.xlabel('Feature')
plt.ylabel('Label')
print(X.shape)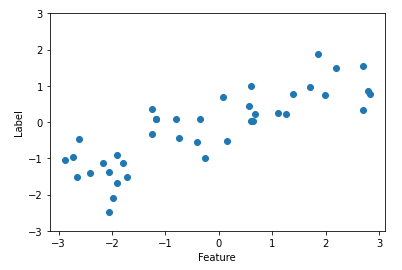
breast_cancer 데이터 다루기
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer() #데이터를 가져혼다
print(cancer.keys())
결과)
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
#'data'에 중요한 데이터들이 넘파이 배열로 들어있다, feature
#target y값, label
#DESCR 데이터에 대한 설명#data의 모양보기
cancer.data.shape
결과)
(569, 30)
#30가지에 요소에 의해 정의되고 있으며 569개의 데이터가 있다.# label인 target의 데이터 확인
cancer.target
결과)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 0,
1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0,
...중략...
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1])
#mlignant(양성), #benign(음성) 숫자로 표기
#target의 이름 확인
cancer.target_names
결과)
array(['malignant', 'benign'], dtype='<U9')#양성과 음성을 결정짓는 특성
cancer.feature_names
결과)
array(['mean radius', 'mean texture', 'mean perimeter', 'mean area',
'mean smoothness', 'mean compactness', 'mean concavity',
'mean concave points', 'mean symmetry', 'mean fractal dimension',
'radius error', 'texture error', 'perimeter error', 'area error',
'smoothness error', 'compactness error', 'concavity error',
'concave points error', 'symmetry error',
'fractal dimension error', 'worst radius', 'worst texture',
'worst perimeter', 'worst area', 'worst smoothness',
'worst compactness', 'worst concavity', 'worst concave points',
'worst symmetry', 'worst fractal dimension'], dtype='<U23')
#30가지 요소가 정의되어 있으며 이 요소들에 의해서 결정된다k-NN 알고리즘 (k-Nearest Neighbors)
가장 가까운 이웃으로 값을 예측한다
#plot_knn_classification : classification 알고리즘에 의해서 어떻게 최근접 알고리즘이 동작하는지 보여줌
mglearn.plots.plot_knn_classification(n_neighbors=1) #이웃을 한 개로 설정- 결과
테스트 데이터(★)가 근접한 이웃에 의해 값이 결정됨
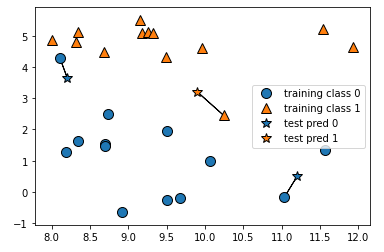
#이웃을 세 개로 설정
mglearn.plots.plot_knn_classification(n_neighbors=3)
#이웃을 세개로 바꾸면 결과가 바뀐다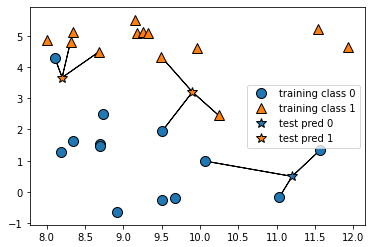
k-NN 알고리즘의 사용 1
from sklearn.model_selection import train_test_split
X,y = mglearn.datasets.make_forge() #X와 y의 데이터 생성
train_test_split(X, y, random_state=0) #실제로 데이터를 쪼개는 작업
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)# 최근접 알고리즘, 분류, 값예측 가능
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3) #최근접 알고리즘을 준비
# 학습을 시킨다
clf.fit(X_train, y_train)# 테스용 데이터 셋으로 테스트
clf.predict(X_test)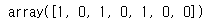
#정확도 확인
clf.score(X_test, y_test)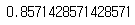
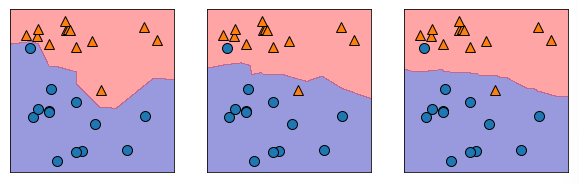
#이웃의 개수마다 다른 분포를 그림으로 표현
fig, axes = plt.subplots(1,3, figsize=(10, 3)) #fig는 그림판 객체
for n_neighbors, ax in zip([1,3,9], axes):
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X, y)
#그림을 그린다, 2차원으로 쪼갠다
mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=0.4)
#점찍기
mglearn.discrete_scatter(X[:,0], X[:,1], y, ax=ax)- 결과해석
최근접알고리즘에서 1개를 했을때는 데이터의 특성이 도드러지게 드러남
2개,3개가 될수록 데이터의 특성이 완화됨을 알 수 있다.
k-NN 알고리즘의 사용 2
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, random_state=66
)
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1,11)
for n_neighbors in neighbors_settings:
#지정된 만큼 반복하면서 훈련한 것을 저장
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train, y_train)
training_accuracy.append(clf.score(X_train, y_train)) #학습 정확도, 훈련정확도
test_accuracy.append(clf.score(X_test, y_test)) #테스트 정확도#학습이 얼마나 잘 되었는지 확인
print(training_accuracy)
print(test_accuracy)
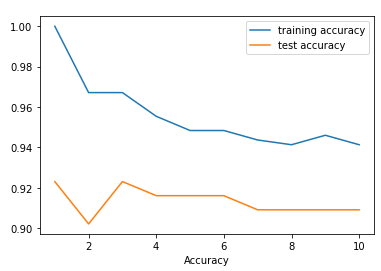
#정확도가 점점 떨어지는 것을 알 수 있다
plt.plot(neighbors_settings, training_accuracy, label='training accuracy') #트레이닝 정확도
plt.plot(neighbors_settings, test_accuracy, label='test accuracy') #테스트 정확도
plt.legend()
plt.xlabel('n neighbors')
plt.xlabel('Accuracy')- 결과
데이터는 3번째가 가장 정확도가 높음을 알 수 있다.
학습 후기
어제 복습으로 헷갈리는 개념을 잘 정리해서인지 오늘은 이해가 안 되서 흐름을 놓치는 일이 적었다. 알고리즘을 코딩으로 하는 작업은 아직 익숙하지 않지만 오늘 수업이 이해가 잘 되서 만족스럽다.
반복적으로 나오는 부분은 먼저 코드를 칠 수 있을 정도로 익숙해졌는데 아직 알고리즘으로 분석하는 것은 어렵다. 추천받은 도서를 구입해서 공부를 더 해야할 것 같다.

열심히 하는 중