데이터 샘플링(Data Sampling)
전체 모집단으로부터 일부 데이터를 추출하여 분석하는 과정
확률적 Sampling
-모집단의 각 구성원이 선택될 확률이 사전에 알려져 있는 방법
-통계적 분석이 보다 신뢰할 수 있고, 결과를 모집단 전체에 일반화할 수 있음
-
단순 무작위 샘플링 (Simple Random Sampling)
-모집단에서 임의로 샘플을 선택하는 가장 기본적인 방법
-모집단의 크기가 N인 경우 크기가 n인 모든 가능한 샘플을 동일한 확률로 추출 -
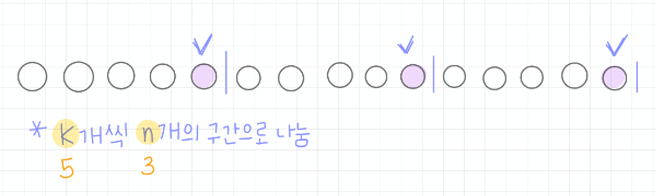
체계적 샘플링 (Systematic Sampling)
-첫 번째 샘플을 무작위로 선택한 후 그 다음 샘플은 사전에 정해진 간격으로 선택
-모집단에 대한 데이터 목록이 정렬되어 있거나 데이터에 규칙적인 패턴이 있는 경우 유용
-
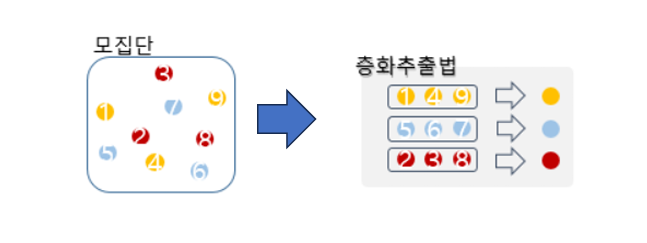
층화 샘플링 (Stratified Sampling)
-모집단을 비슷한 특성을 가진 여러 개의 층으로 나눈 후 각 층에서 단순 무작위 샘플링
-모집단의 크기가 N인 경우 크기가 n인 모든 가능한 샘플을 동일한 확률로 추출
-
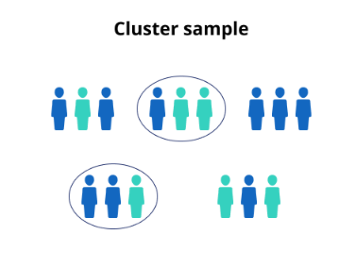
군집 샘플링 (Cluster Sampling)
-모집단을 여러 군집으로 나눈 후 일부 군집을 무작위로 선택, 선택된 군집의 모든 구성원 조사
-모집단의 크기가 N인 경우 크기가 n인 모든 가능한 샘플을 동일한 확률로 추출
비확률적 Sampling
-모집단의 구성원이 선택될 확률이 사전에 알려지지 않은 방법
-주로 탐색적 연구나 예비 조사에서 사용되며, 결과를 일반화하는 데 한계가 있을 수 있음
- 편의 샘플링 (Convenience Sampling)
접근하기 쉬운 표본을 샘플로 선택 - 판단 샘플링 (Judgment Sampling) or 목적 샘플링 (Purposive Sampling)
연구자의 판단에 따라 특정 기준을 충족하는 표본 선택 - 눈덩이 샘플링 (Snowball Sampling)
샘플 구성원들이 다른 구성원들을 추천하는 방식으로 샘플 확정
Sampling 기법 선택
-
데이터의 특성과 분포
- 데이터 크기와 복잡성
대규모나 복잡한 데이터 세트의 경우, 계산 비용을 줄이고 효율성 증가를 위해 샘플링 진행 - 데이터 분포
데이터에 편향(bias)이 있는 경우 층화샘플링 같은 방법을 사용하여 각 범주의 데이터가 샘플에 균등하게 표현되도록 함 - 클래스 불균형
대부분의 데이터가 한 클래스에 속해 있고 다른 클래스는 소수만 존재하는 경우, 오버샘플링 또는 언더샘플링 기법 고려
- 데이터 크기와 복잡성
-
연구 목적 및 모델 요구 사항
- 정확도 대 효율성
고정밀도가 필수적인 경우, 더 많은 데이터를 포함시키거나 층화샘플링을 적용하여 대표성을 높여야, 빠른 프로토타이핑이 목적이라면 더 간단한 샘플링 방법 사용 가능 - 모델의 종류
사용하는 머신러닝 모델에 따라 샘플링 전략을 달리 해야 하는 경우 고려
- 정확도 대 효율성
-
실행 시간 및 리소스 제약
- 계산 리소스
제한된 계산 리소스를 가진 경우, 효율적인 샘플링을 통해 데이터 크기를 줄이고 모델 학습 시간을 단축. 적절한 샘플링을 통해 메모리 문제 방지
- 계산 리소스
-
샘플링 편향 방지
- 대표성 유지
-샘플링 과정에서 데이터의 대표성을 유지
-샘플이 모집단의 특성을 충분히 반영하지 못 하면 모델의 일반화 능력이 저하될 수 있음
- 대표성 유지
-
재현성 및 검증
- 샘플링 과정의 재현성
실험의 재현성을 위해 샘플링 과정을 명확히 문서화하고 고정된 시드값을 사용하여 샘플링 수행 - 교차 검증
샘플링 된 데이터에 대해 교차 검증을 수행하여 모델 성능을 검증하고 샘플링이 모델 성능에 미치는 영향을 평가
- 샘플링 과정의 재현성

ML/DL Study,기록📝