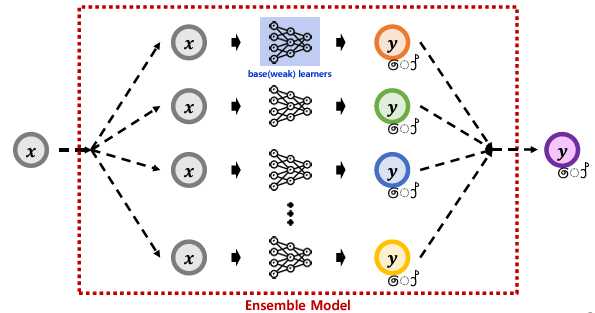
앙상블 (Ensemble)
-여러 개의 개별 모델을 생성하고 조합하여 최적의 모델로 일반화하는 기법
-weak learner들을 결합하여 strong learner를 만드는 방식
weak learner (약한 학습기)
혼자서는 데이터의 패턴을 완벽하게 학습하지 못하지만 여러 개를 조합함으로써 강한 예측 성능을 낼 수 있는 모델
Diversty of Base Learners
-
Manipulating the training data (데이터셋 조정)
→ bootstrap sampling, cross-validation, AdaBost algorithm -
Manipulating the input features (입력 변수 조정)
→ Random Forest
-
Manipulating the output features (출력 타겟 조정)
→ Label Transformation, Target Smoothing, Class Imbalance Adjustment -
Injecting randomness (무작위성 부여) ⇒ 모델이 데이터의 복잡성을 더 잘 포착, 과적합 방지, 일반화 성능 향상
→ Neural Networks
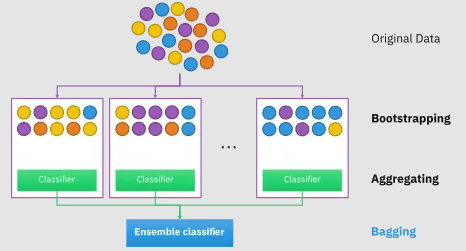
배깅 (Bagging)
-Bootstrap Aggregating의 약자
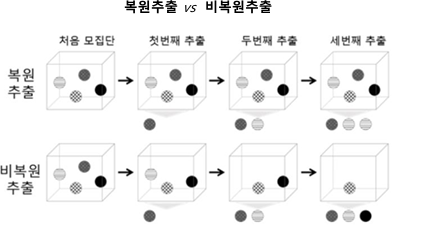
-훈련 데이터셋에서 여러 번의 복원 추출(Bootstrap)을 통해 다양한 모델을 생성하고 각각 독립적으로 학습시킨 후 결과를 통합하는 방법 ex) Random Forest
-Categorical Data(분류)는 투표 방식으로 집계, Continuous Data(회귀)는 평균으로 집계
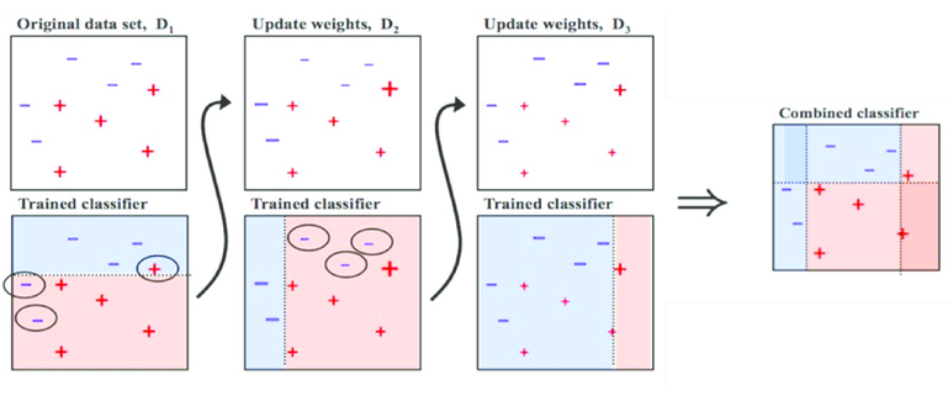
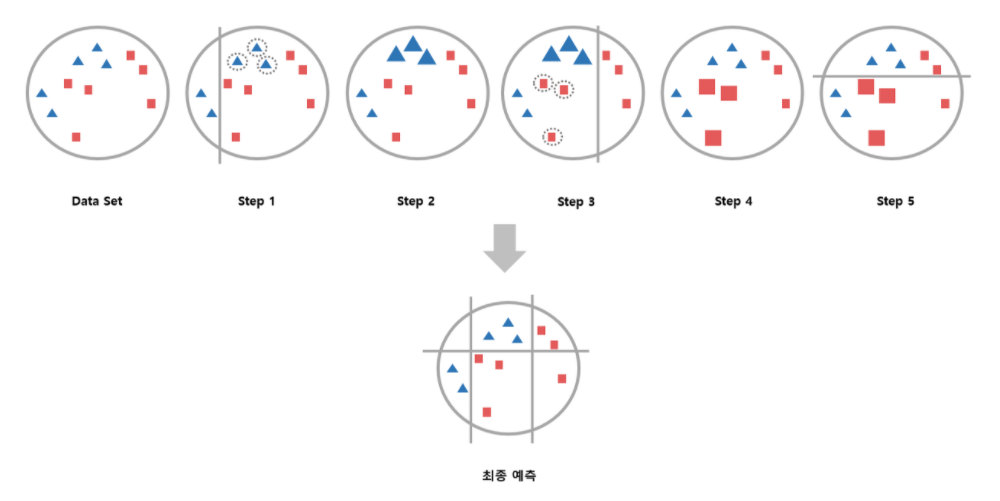
부스팅 (Boosting)
weak learner들을 하나씩 연결하여 strong learner를 만드는 방법
- 에이다 부스트 (Ada boost)
weak learner를 순차적으로 적용해 나가는 과정에서 잘 분류된 샘플의 가중치는 낮추고 잘못 분류된 샘플의 가중치는 상대적으로 높여주면서 샘플 분포를 변화
- 그레디언트 부스트 (Gradient boost)
잘못 분류된 샘플의 error를 최적화하는 방식으로 진행
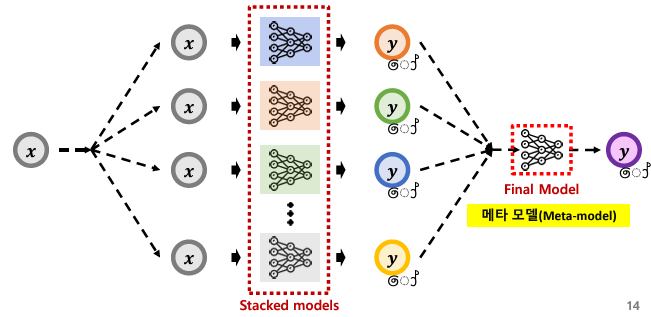
스태킹 (Stacking)
서로 다른 모델들의 예측을 새로운 데이터로 사용하여 최종적인 예측을 위한 또 다른 모델(메타 학습기)을 학습시키는 방법
-
핵심 요소
- 기본 모델
서로 다른 알고리즘을 사용하는 여러 모델이 있음
모델들은 각각 다른 관점에서 데이터를 해석 및 예측 - 메타 모델
기본 모델들의 예측을 기반으로 최종 예측을 수행
어떤 모델의 예측을 더 중시할지 결정하는 방법을 학습
- 기본 모델
-
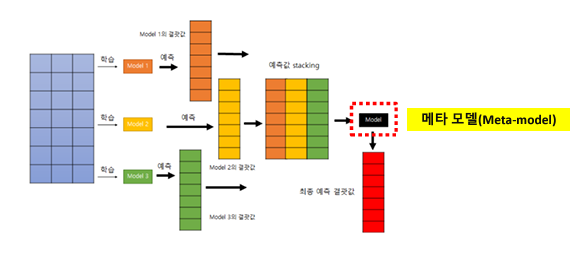
스태킹 과정
- 훈련 데이터 분할
원본 훈련 데이터를 두 개 이상의 서브셋으로 분할, 일반적으로 k-겹 교차 검증 방식 사용
- 기본 모델 훈련
첫 번째 세브셋을 사용하여 여러 기본 모델을 각각 독립적으로 훈련
- 기본 모델 예측
두 번째 서브셋을 사용하여 훈련된 각 기본 모델로부터 예측을 수행, 이 예측들은 메타 모델의 훈련 데이터로 사용
- 메타 모델 훈련
기본 모델드르이 예측을 입력으로, 원래 타깃 레이블을 출력으로 사용하여 메타 모델 훈련
- 최종 예측 수행
테스트 데이터에 대해 기본 모델들의 예측을 수집, 이를 메타 모델에 입력하여 최종 예측 생성
보팅 (Voting)
-
Hard Voting
다수결 원칙과 유사, 예측한 결과값 중 다수의 분류기가 결정한 예측값을 최종 결과값으로 선정 -
Soft Voting
분류기들의 레이블 값 결정 확률을 모두 더한 후 평균을 내서 확률이 가장 높은 레이블 값을 최종 결과값으로 선정
