AutoEncoder
- 입력 데이터를 효율적으로 압축, 복원하기 위해 사용되는 인공 신경망의 한 종류
- Encoder + Decoder로 구성
- Encoder : 입력 데이터를 저차원의 잠재 공간(latent space)으로 압축
- Decoder : 잠재 공간의 표현을 다시 원본 데이터로 복원
- 압축, 복원 과정을 통해 입력 데잍터에 대한 중요한 특성 학습
- 비지도 학습 가능 (정답 = 입력값)
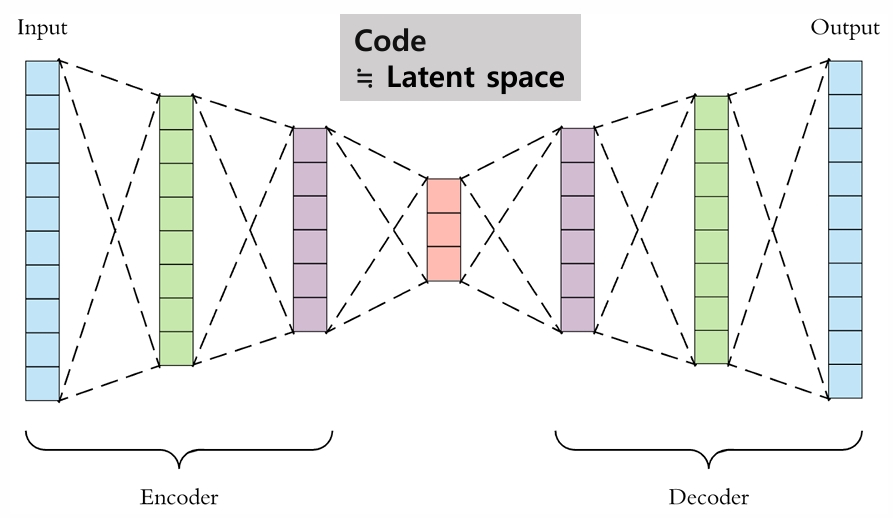
AutoEncoder 구조
-
Encoder
입력 데이터(이미지, 텍스트)를 더 낮은 차원의 잠재 공간으로 매핑
데이터의 중요한 특성 및 패턴 추출- 차원 축소
- Representation Learning (특징을 자동으로 추출할 수 있도록 학습하는 과정)
- 일반적으로 Encoder 부분을 더 많이 사용
- 필요 : 고차원 벡터, 차원의 저주
불필요한 정보가 많음을 의미 → 모델 성능 및 학습 효율 저하
- 차원 축소
-
Decoder
잠재 공간의 표현을 원본 데이터와 같거나 비슷한 형태로 복원- Generative Model
-
Code (≒ Latent Space)
입력 데이터의 압축된 표현을 담고 있는 공간
각 차원은 입력 데이터의 중요한 특성을 나타냄- 입력 데이터의 압축 표현, 벡터
- Encoder와 Decoder 사이의 데이터
- 데이터의 중요한 특성 반영
- 입력 데이터의 중요한 특성을 캡처하며, 데이터의 차원을 축소
- 차원의 저주 완화, 계산 효율성 ↑
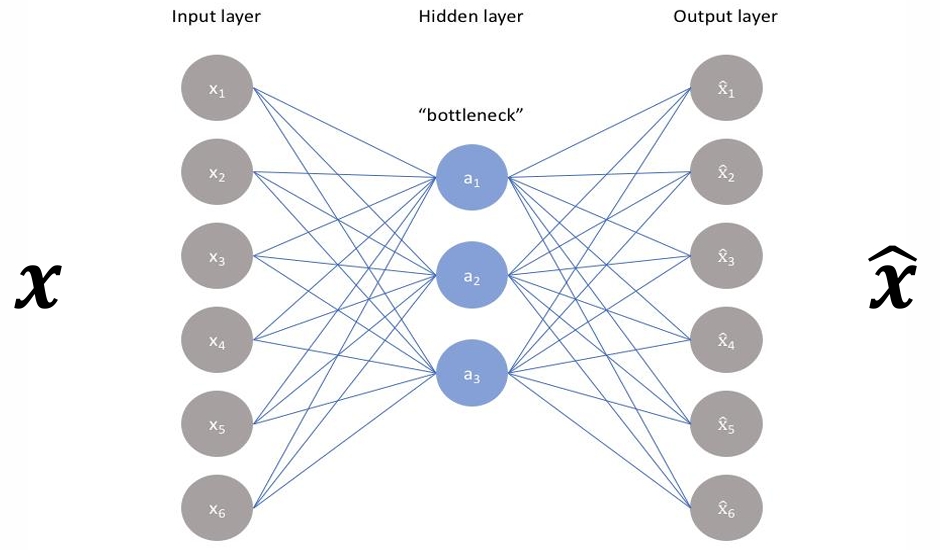
AutoEncoder - 종속변수
정답 (모형을 통해 예측되는 값) = 입력값
Autoencoder - 비용함수
- 모델 학습
입력과 출력(복원된 입력 데이터)의 차이(오차)를 최소화 - 비용 함수
재구성 과정에서 발생하는 오차 측정, 이 오차를 최소화하는 방향으로 모델의 가중치 조정 - 비용 함수를 최소화함으로싸 입력 데이터의 중요한 특성을 잘 보존하는 잠재 공간의 표현 학습
→ 데이터의 압축, 노이즈 제거, 차원 축소 등에 활용 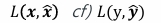
- L : MSE or Cross Entropy
AutoEncoder - 적용
- 데이터 압축
입력 데이터를 압축, 복원 → 효율적인 데이터 저장 및 전송에 사용 - 차원 축소
≒ PCA(주성분 분석), 데이터의 차원 축소 (비선형 차원 축소 가능) - 노이즈 제거
입력 데이터 노이즈 제거 → 중요 특성 추출 - 추천 시스템
- 이상치 탐지
정상적인 데이터를 사용하여 AutoEncoder 학습
→ 새로운 데이터를 Encoding 및 Decoding 하는 과정에서 발생하는 재구성 손실을 이용하여 이상치를 탐지
차원 축소
- PCA
- Linear dimensionality reduction
- 분산 정보를 이용해서 분산이 많은 순으로 수직인 축을 찾고 해당 축에 대해서 Linear projection을 통해 새로운 벡터를 구함
- AutoEncoder
- Non-linear activation function을 사용하는 경우 → Non-linear dimensionality reduction
- Linear activation function을 사용하는 경우 PCA와 유사
- Autoencoder ⊃ PCA
노이즈 제거
- Compared to AutoEncoder
- 원 입력값에 노이즈를 추가해서 입력값으로 사용

- AutoEncoder는 노이즈가 제거된 원본 입력값을 예측 (즉, 정답은 원 입력값)
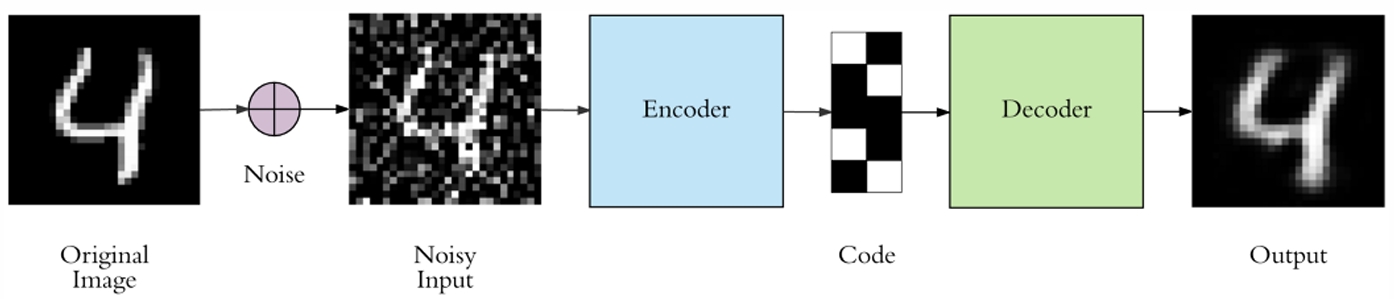
- 원 입력값에 노이즈를 추가해서 입력값으로 사용
추천 시스템
- 사용자의 선호나 아이템의 특성을 압축된 형태로 표현
- 비슷한 사용자들의 행동을 기반으로 사용자의 선호도를 학습, 이를 바탕으로 개인화된 추천을 생성
- 사용자-아이템 상호작용 행렬 사용
- 사용자-아이템 상호작용 데이터를 받아 사용자의 기존 상호작용에서 중요한 특성을 포착하여 잠재 공간에 압축
- CODE : 사용자의 숨겨진 선호 표현
- 누락된 값을 예측하고 각 사용자에 대해 가장 높은 예측 점수를 가진 아이템 추천
- 사용자의 평점, 클릭, 구매 이력 등의 다양한 데이터와 콘텐츠 기반 필터링, 협업 필터링 등의 다양한 방식의 조합으로 구현 가능
이상치 탐지
- 정상 관측치만을 이용해서 학습
- 이상치를 포함한 데이터에 적용해서 예측, 비용함수 계산
- 정상 관측치를 이용한 학습 모형에서 이상치 데이터의 비용함수의 값이 크다는 점 이용 (AE의 재구성 오차 기반)
- 비용함수 값을 이용해서 이상치 탐지
재구성 오차가 특정 임계값(Threshold) 이상인 경우 이상치로 간주

ML/DL Study,기록📝