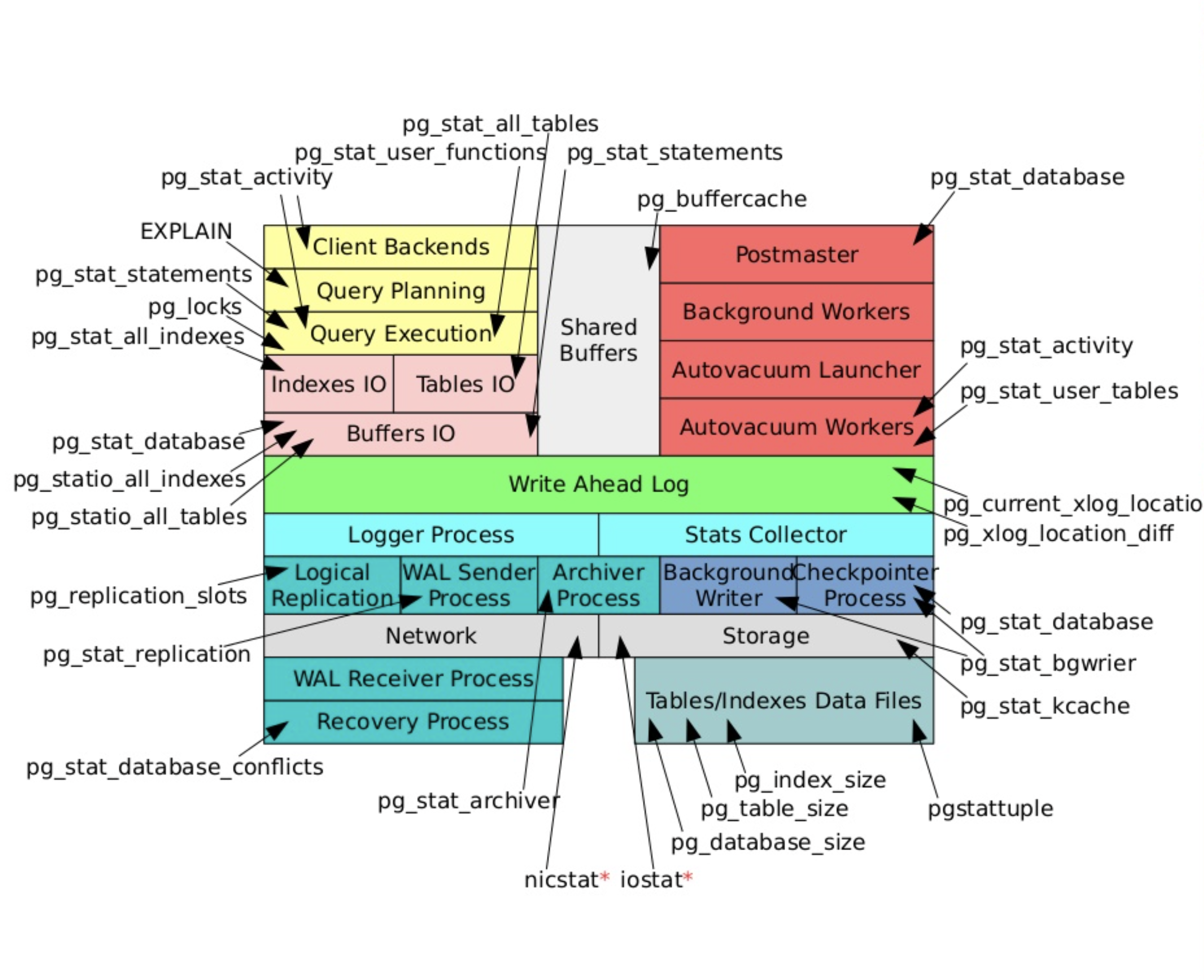
이미지 출처 : https://www.slideshare.net/alexeylesovsky/deep-dive-into-postgresql-statistics-54594192
Postgresql의 Query Optimizer 동작 원리에 대해서 알아보겠습니다.
Query Optimizer의 동작원리를 이해하기 위해서는 CBO, 통계정보, 실행계획, 액세스 방법, 조인 순서, 조인 방법 등을 알아야 합니다. 이번 게시물에서는 통계정보에 대해 알아보고 간단한 실습을 해보겠습니다.
통계 정보
Optimizer는 통계 정보를 기반으로 비용을 계산합니다. 통계 정보 수집 방식 및 통계 정보 확인 방법에 대해서 살펴보겠습니다.
통계 정보 수동 생성
통계 정보는 데이터베이스, 테이블, 컬럼 단위로 생성합니다.
# 데이터베이스
analyze;
# 테이블
analyze t1;
# 컬럼
analyze t1 (c1, c2);
verbose 옵션을 사용하면 수행 내역을 자세히 확인할수 있습니다.
analyze verbose t1;
INFO: analyzing "public.t1"
INFO: "t1": scanned 443 of 443 pages, containing 100000 live rows and 0 dead rows; 30000 rows in sample, 100000 estimated total rows
ANALYZE통계 정보 자동 생성
autovacuum은 통계 정보를 자동으로 수집합니다. 관련 파라미터는 아래와 같습니다.
- autovacuum (기본값 on) : autovacuum 프로세스 사용 여부
- autovacuum_analyze_scale_factor (기본값0.1) : 테이블 내의 레코드 변경 비율
- autovacuum_analyze_threshold (기본값 50) : 최소 변경 레코드 수
create table t2 (c1 integer, c2 integer);
insert into t2 select generate_series(1,10000);select a.relname, a.relpages, a.reltuples, b.last_autoanalyze
from pg_class a, pg_stat_user_tables b
where a.relname = b.relname and a.relname = 't2';
"t2" 45 10000 "2021-04-28 01:58:17.85666+09"insert into t2 select generate_series(1,1000);
select b.last_autoanalyze
from pg_class a, pg_stat_user_tables b
where a.relname = b.relname and a.relname = 't2';
"2021-04-28 01:58:17.85666+09"insert into t2 select generate_series(1,1000);
select a.relname, a.relpages, a.reltuples, b.last_autoanalyze
from pg_class a, pg_stat_user_tables b
where a.relname = b.relname and a.relname = 't2';
"t2" 49 11051 "2021-04-28 02:01:18.007864+09"통계 정보 확인
pg_class
- relpages : 블록 수
- reltuples : 레코드 수
pg_stats
- n_distinct : NDV(Number of Distinct Value)
- correlation : 컬럼 정렬 상태 (-1~1)
- ...
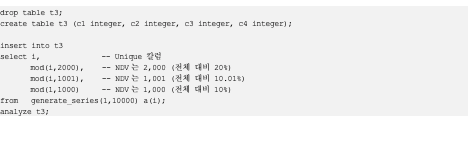
drop table t3;
create table t3 (c1 integer, c2 integer, c3 integer, c4 integer);
insert into t3
select i, -- Unique 칼럼
mod(i,2000), -- NDV는 2,000 (전체 대비 20%)
mod(i,1001), -- NDV는 1,001 (전체 대비 10.01%)
mod(1,1000) -- NDV는 1,000 (전체 대비 10%)
from generate_series(1,10000) a(i);
analyze t3;
select attname, n_distinct
from pg_stats where tablename = 't3';
"c1" -1
"c2" -0.2
"c3" -0.1001
"c4" 1000테이블별 자동 통계 생성 제어
alter table t1 set (autovacuum_analyze_scale_factor = 0.0);
alter table t1 set (autovacuum_analyze_threshold = 100000);alter table t1 set (autovacuum_analyze_scale_factor = 0.1);
alter table t1 set (autovacuum_analyze_threshold = 0);alter table t1 alter column c1 set (n_distinct=-0.2);
alter table t1 alter column c1 reset (n_distinct);"PostgreSQL 9.6 성능이야기", "Orcle, Postgresql, MySQL Core Architecture" 내용을 실습을 통해 정리했습니다.

Data Engineer