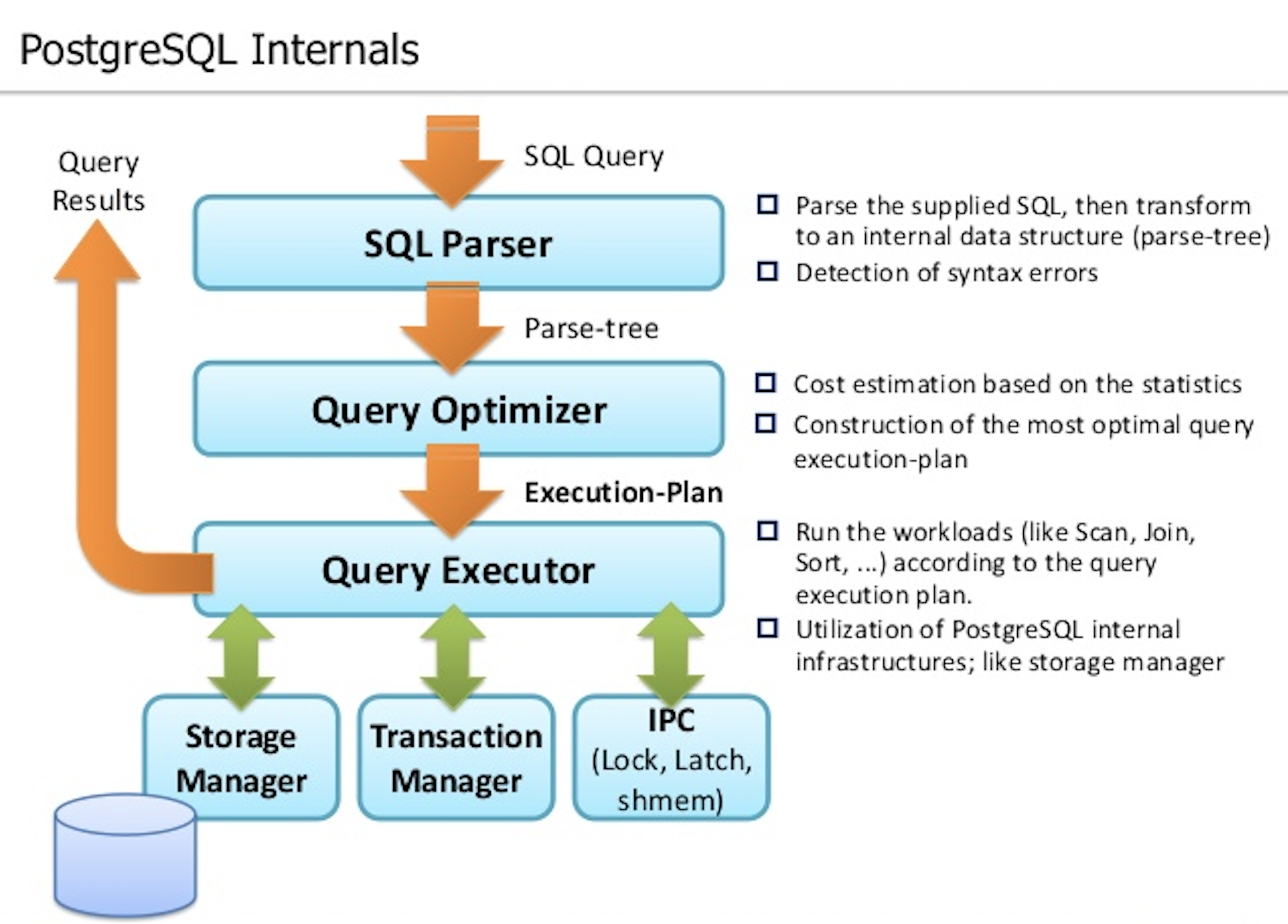
Postgresql의 Query Optimizer 동작 원리에 대해서 알아보겠습니다.
Query Optimizer의 동작원리를 이해하기 위해서는 CBO, 통계정보, 실행계획, 액세스 방법, 조인 순서, 조인 방법 등을 알아야 합니다. 이번 게시물에서는 CBO에 대해 알아보고 간단한 실습을 해보겠습니다.
CBO(=Cost Based Optimizer)
Postgresql는 CBO(=Cost Based Optimizer) 방식을 제공합니다. Query의 비용 계산은 파라미터 및 통계정보를 기반으로 계산한 값 입니다. 파라미터는 IO 및 CPU 비용 파라미터가 있습니다.
Cost Parameter
Cost 계산용 파라미터 및 기본 설정값은 아래와 같습니다.
IO 비용
- seq_page_cost (기본값 1) : Seq Scan 방식으로 1블록을 읽는 비용
- random_page_cost (기본값 4) : Index Scan 방식으로 1블록을 읽는 비용
CPU 비용
- cpu_tuple_cost (기본값 0.01) : Seq Scan 수행시 1개 레코드 액세스 비용
- cpu_index_tuple_cost (기본값 0.05) : Index Scan 수행시 1개 레코드 액세스 비용
- cpu_operator_cost (기본값 0.0025) : Seq/Index Scan 수행시 레코드 1개 필터 처리하는 비용
Seq Scan, Index Scan의 비용을 계산해보겠습니다.
Seq Scan 비용 계산
T1 테이블을 생성하고 10만건의 더미 데이터를 생성합니다. 그리고 통계정보를 수집합니다.
create table t1 (c1 integer, c2 integer);
insert into t1 select i, mod(i,10) from generate_series(1,100000) a(i);
analyze t1;10만건의 데이터가 443개의 블록(=relpages)으로 구성되어있습니다.
select relpages, reltuples from pg_class where relname = 't1';
443 100000T1테이블을 Seq Scan방식으로 전체 읽는 비용은 1443 입니다.
explain select * from t1;
"Seq Scan on t1 (cost=0.00..1443.00 rows=100000 width=8)"위 비용을 파라미터 및 통계정보를 기반으로 계산합니다. 1443 으로 동일하게 확인됩니다.
select relpages * current_setting('seq_page_cost')::float +
reltuples * current_setting('cpu_tuple_cost')::float
from pg_class where relname = 't1';
1443C1컬럼 조건이 추가됨으로써 비용이 1693으로 증가 했습니다.
explain select * from t1 where c1 <= 300;
"Seq Scan on t1 (cost=0.00..1693.00 rows=300 width=8)"
" Filter: (c1 <= 300)"10만건의 데이터를 cpu_operator_cost(=0.0025) 만큼 처리하여 250 만큼의 비용이 증가한것을 확인할수 있습니다. 수식은 아래와 같습니다.
select relpages * current_setting('seq_page_cost')::float +
reltuples * current_setting('cpu_tuple_cost')::float +
reltuples * current_setting('cpu_operator_cost')::float
from pg_class where relname = 't1';
1693C2컬럼 조건을 추가해도 동일하게 250 만큼의 비용이 증가하는것을 확인할수 있습니다.
explain select * from t1 where c1 <= 300 and c2 = 1;
"Seq Scan on t1 (cost=0.00..1943.00 rows=30 width=8)"
" Filter: ((c1 <= 300) AND (c2 = 1))"수식은 아래와 같습니다. 동이하게 1943으로 확인됩니다.
select relpages * current_setting('seq_page_cost')::float +
reltuples * current_setting('cpu_tuple_cost')::float +
reltuples * current_setting('cpu_operator_cost')::float +
reltuples * current_setting('cpu_operator_cost')::float
from pg_class where relname = 't1';
1943Index Scan 비용 계산
Index Scan 비용 계산은 복잡합니다. pageinspect 익스텐션을 설치 후 블럭 덤프를 통해 계산도 필요합니다. 자세한 내용은 참고한 도서를 살펴봐주세요.
create unique index t1_uk on t1(c1);
explain select * from t1 where c1 <= 300;
"Index Scan using t1_uk on t1 (cost=0.29..14.65 rows=306 width=8)"
" Index Cond: (c1 <= 300)""PostgreSQL 9.6 성능이야기", "Orcle, Postgresql, MySQL Core Architecture" 내용을 실습을 통해 정리했습니다.
