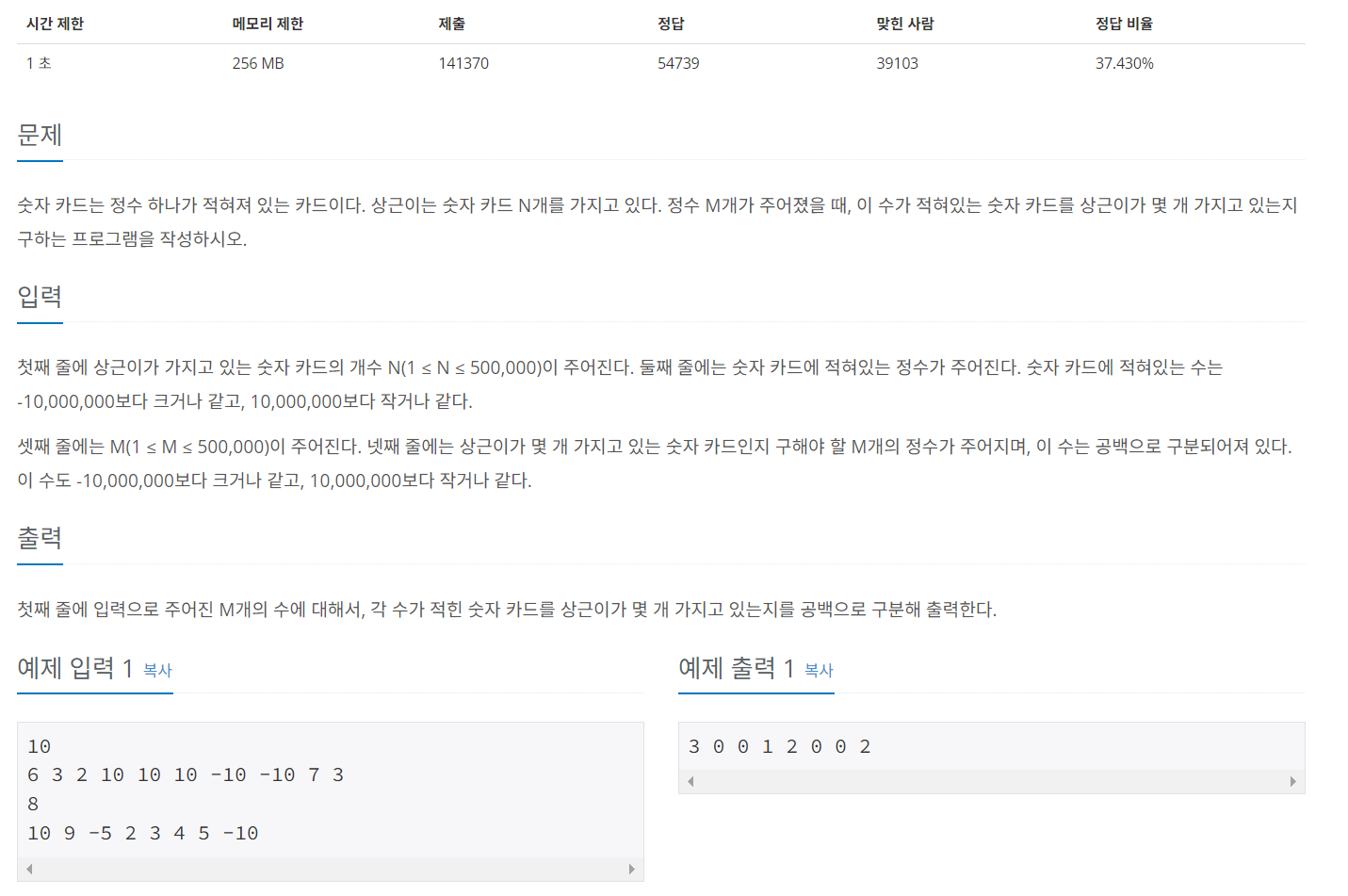
문제 url:
숫자 카드2
문제:
🤔 문제 알아보기
이전의 숫자 카드문제와 매우 유사해서, 문제 알아보기는 이전 문제 내용으로 대신하겠다.
백준 10815번: 숫자 카드
다른게 존재한다면, 중복 숫자가 생겼으며, 중복 개수만큼 출력하는데,
해당 문제는 코드와 함께 본다면 어렵지 않을 것이라 생각한다.
🐱👤 실제 코드 1) 계수 정렬
import java.io.*;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sbd = new StringBuilder();
int N = Integer.parseInt(br.readLine());
int[] count_sort = new int[20000001];
StringTokenizer st = new StringTokenizer(br.readLine());
for(int i = 0; i < N; i++) {
count_sort[Integer.parseInt(st.nextToken()) + 10000000]++;
}
int M = Integer.parseInt(br.readLine());
StringTokenizer st_m = new StringTokenizer(br.readLine());
for(int i = 0; i < M; i++) {
sbd.append(count_sort[Integer.parseInt(st_m.nextToken()) + 10000000]).append(" ");
}
System.out.println(sbd);
}
}
계수 정렬(counting sort)에 대해서 잘 모르는 분은 아래의 링크를 들어가서 읽어보면 좋다
계수 정렬
그래도 계수 정렬를 살짝 언급하자면,
계수 정렬은 말 그대로 배열에 데이터 값이 몇 번 등장했는지 카운트해주는 정렬이다.풀이를 짧게 이야기 하면 계수 정렬은 수의 범위의 영향을 조금 많이 받는데, 해당 데이터 값이 몇 번 등장했는지를 구하는 것이기에 포함된 수의 범위를 모두 표현할 수 있어야 한다.
여기서는 수의 범위(이번 문제는 -10,000,000 <= p <= 10,000,000 의 범위까지 카드 수가 등장할 수 있다고 얘기한다.
그래서 배열의 크기가 20,000,001이다(1은 0의 인덱스를 말한다.)
그렇다면, 10의 값은 즉 , 10,000,009의 인덱스에 들어갈 것이고, 해당 값을 1씩 증가시키면서 몇 번 등장한지를 구할 수 있다.
계수 정렬은 정렬중 O(N)의 시간 복잡도를 가지기 때문에 매우 빠르다.
빠르고 메모리도 효율적인 퀵정렬도 O(N log N)의 시간 복잡도를 가진다.🐱👤 실제 코드 2) HashMap 사용
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sbd = new StringBuilder();
int N = Integer.parseInt(br.readLine());
HashMap<Integer,Integer> card_map = new HashMap<>();
StringTokenizer st_N = new StringTokenizer(br.readLine());
for(int i = 0; i < N; i++) {
int token = Integer.parseInt(st_N.nextToken());
if(card_map.containsKey(token)) {
int value = card_map.get(token); // value값을 뽑아 1씩 증가시키 위해
card_map.put(token, value+1);
} else {
card_map.put(token, 1);
}
}
int M = Integer.parseInt(br.readLine());
StringTokenizer st_m = new StringTokenizer(br.readLine());
for(int i = 0; i < M; i++) {
int token = Integer.parseInt(st_m.nextToken());
if(card_map.containsKey(token)) {
sbd.append(card_map.get(token)).append(" ");
} else {
sbd.append(0).append(" ");
}
}
System.out.println(sbd);
}
}
해당 코드는 따로 분석하지 않겠다. Map 사용법을 아신다면, 금방 이해할 수 있을 것이다.
🐱👤 실제 코드 3) 이진탐색 사용
타 블로그를 참고하면서, 이진탐색으로 풀 수 있는 방법을 찾아 해당 방법도 공부하며 적용 시켜보았다.
먼저 달라진 이진탐색에 대해서 설명해보겠다. 그 전에 이진탐색에 대해서 궁금하신 분은 해당 링크를 먼저 보고 오면 좋다. -> [탐색] 이진 탐색(Binary Search)를 살펴보자
먼저 이전에는 값이 일치하면 true or false값을 return하는 구조였다.
(즉 중앙값과 찾고자 하는 값이 같으면 true, 다르면 false)
하지만 이번에는 정렬된 배열에서 연속으로 중복된 값이 몇번 입력됐는지를 찾아야 하는 문제이기 때문에
찾고자 하는 값의 인덱스 범위를 구해야 한다.
이때 lower_bound 와 upper_bound 개념을 사용할 수 있다.
lower_bound
배열안에서 원소의 값이 찾고자 하는 값보다 크거나 같을 때, 해당 원소의 첫 번쨰 인덱스를 반환한다.
즉, 찾고자 하는 값 이상의 값이 처음 등장하는 인덱스를 말한다.타 블로그의 설명을 더 이야기를 해보면 lower_bound를 하한을 의미한다고 한다.
이를 필자가 이해한 바로 설명하자면, 때려죽어도! 최소한 이 값부터 시작해야 한다는 말이다.
필자도 아직 말로는 이해하지 못했다. 그래서 그림으로 한번 풀어보겠다.
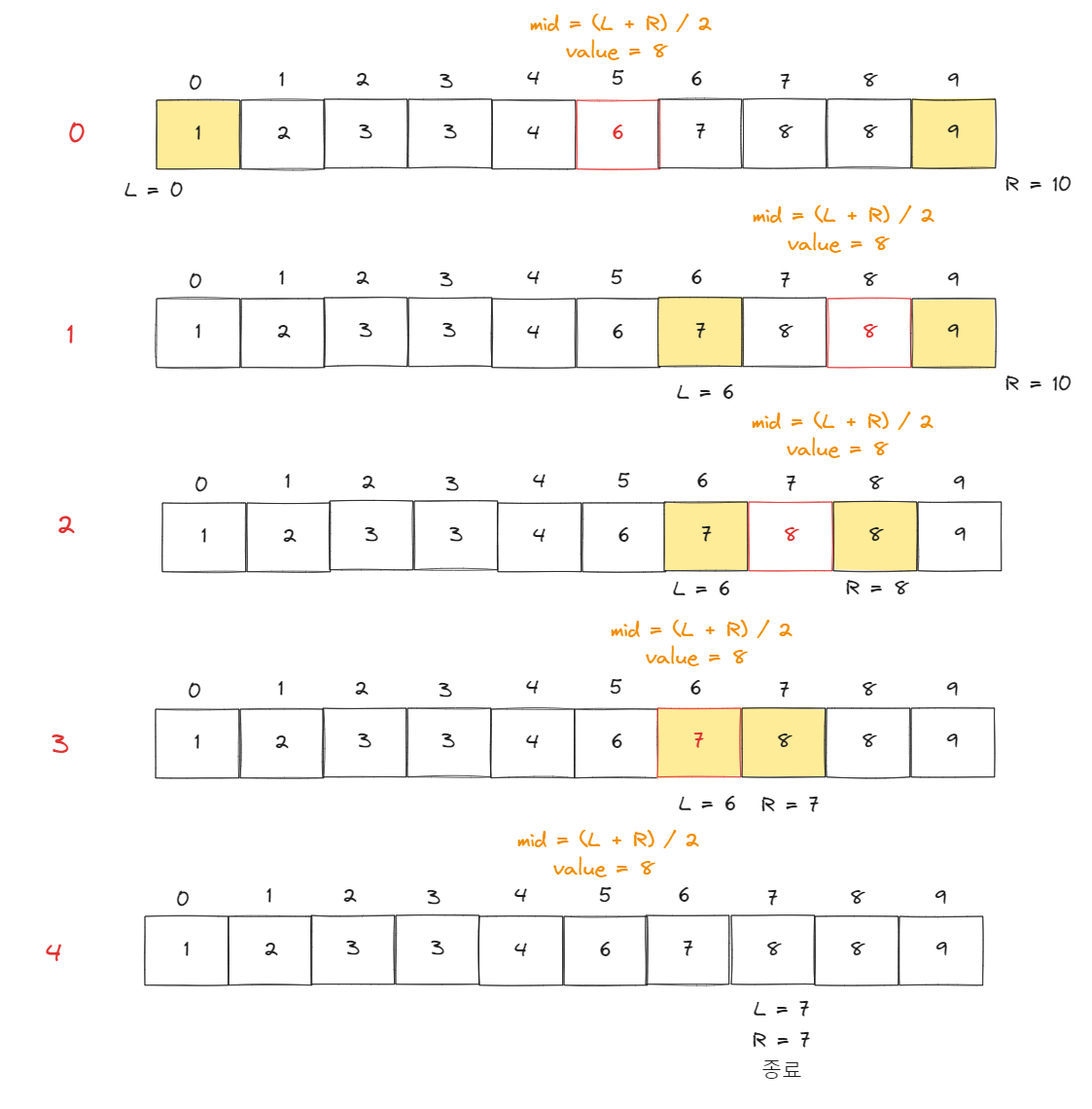
그림으로도 잘 이해가 안될 수 있다. 그래서 더 자세히 설명하면,
먼저, 우리가 찾고자 하는 값을 value, 중앙값을 mid라고 지칭하고 설명하겠다.
또, mid 밑의 값들을 left , mid 위의 값들을 right로 일단 생각해보자
이진탐색을 할 때, value > mid 크다면, 우리는 mid 이하의 값은 볼 필요가 없기 때문에 left를 mid + 1까지 올렸던 것을 봤을 것이다.
그렇다면 현재 그림은 value > mid이다.
그러니 1번 풀이를 보면 left 값을 mid+1까지 올려서 계산한다. 그 후 올려진 left와 right를 이용해 새로운 mid값인 8이 나왔다.
여기서 8은 value과 같은데, 그림을 보다시피 현재 인덱스의 8은 정답이 되면 안된다.
그래서 lower_bound를 할 때에는 value <= mid로 하여 하한선까지 계산하는 것이다.
현재 그림은 value <= mid에 속하는 데, 이때는 left보다는 right를 내려서 계산해야 한다. 그래서 right = mid로 하면 2번 째 그림이 될 수 있다.
하지만, 나중에 코드를 보면 이해하겠지만 left와 right가 서로 일치할 때 반복문을 종료하도록 로직을 구성했기 때문에 mid가 원하는 위치에 멈췄어도, 계속 진행한다.
그러면 다시 right가 mid인 7까지 내려오고, 중앙값을 다시 계산하게 되면 3번 그림처럼 6번째 인덱스 즉, 7의 값을 가진다. 이렇게 되면
value > mid가 된다. 이럴 때 우리는 left를 올리기로 위에서 설명했다.
그럼 마지막 그림(4번)처럼 left가 7번쨰 인덱스가 되고, right도 7번쨰 인덱스가 되면서 종료된다.
설명도 이해하기 어려울 수 있다. 그래도 이제 코드를 보면 위의 말이 무슨 말인지 이해할 수 있을 것이다.
static int lower_bound(int[] arr, int value) {
int left_idx = 0;
int right_idx = arr.length;
// 두 개의 인덱스가 같을 때 반복문이 종료된다.
while(left_idx < right_idx) {
// 중앙값 인덱스 구하기
int mid = (left_idx + right_idx) /2;
// 작거나 같다인 이유는, value가 존재하는 위치까지 이동
// 또한 lower_bound는 하한을 구하는 로직으로
// 제일 첫 번째 인덱스를 구해야 하기 때문
if(value <= arr[mid]) {
right_idx = mid;
}
else {
// 중앙값 < value가 더 클 경우
// 마지막 인덱스에서 일치하고자 하는 값 첫 번째에 오기 위해
// 사용되는 로직
left_idx = mid + 1;
}
}
return left_idx;
}upper_bound
배열안에서 원소의 값이 찾고자 하는 값보다 클 때, 찾고자 하는 값보다 큰 수의 첫 번째 인덱스를 반환
즉, 찾고자 하는 값을 넘기는(초과하는) 값의 첫 번째 인덱스를 의미한다.또 타 블로그의 설명을 이야기 해본다면, upper_bound는 상한을 의미한다.
이는 구하고자 하는 값의 상위의 값이라고 필자는 이해했다.
역시 그림과 코드를 함께 비교하면서 이해해보자
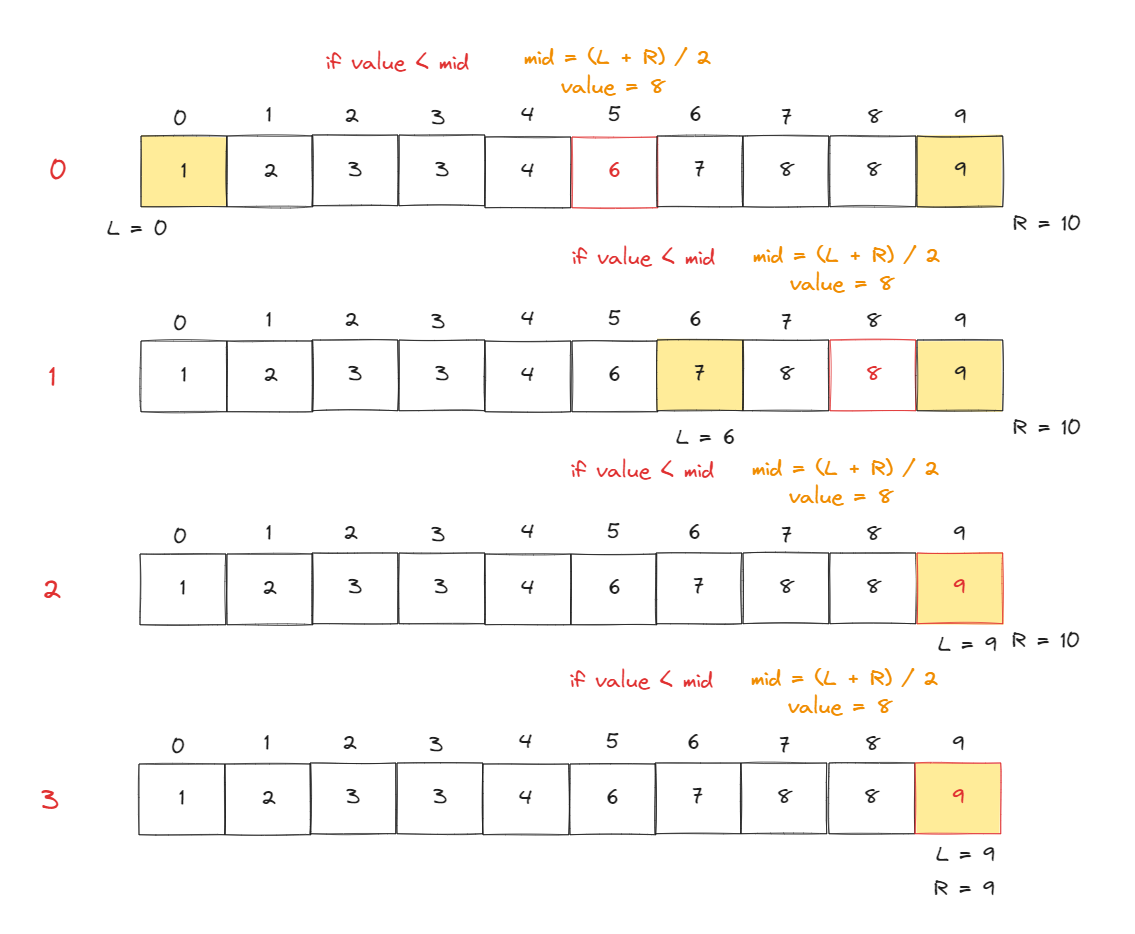
해당 문제도 그림으로 보면 이해가 안된다. 그럼 코드와 함께 비교해보자
static int upper_bound(int[] arr, int value) {
int left_idx = 0;
int right_idx = arr.length;
// 왼쪽과 오른쪽이 같아질 때까지 반복
while(left_idx < right_idx) {
int mid = (left_idx + right_idx) /2;
if(value < arr[mid]) {
right_idx = mid;
} else {
left_idx = mid + 1;
}
}
return left_idx;
}즉, 그렇다면 이제 중복된 원소의 개수를 구하려면 어떻게 하면 될까?
upper_bound는 찾고자하는 값보다 큰 첫 번째 인덱스의 값이고
lower_bound는 찾고자하는 값 이상의 첫 번째 인덱스 값이니깐
이 둘을 뺸다면? 해당 길이가 중복된 원소의 개수이지 않을까?
upper_bound - lower_bound로 말이다.
만약 value가 배열에 존재하지 않는다면, 결국 upper_bound - lower_bound는 같은 값을 반환받아
0으로 나올 것이다. 그래서 0에 대한 예외처리를 따로 해줄 필요가 없다.그럼 이제 전체 코드를 살펴 보자,
🐱👤 3-2) 이진 탐색 전체 코드
import java.util.Arrays;
import java.util.StringTokenizer;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(br.readLine());
int[] arr = new int[N];
StringTokenizer st = new StringTokenizer(br.readLine(), " ");
for(int i = 0; i < N; i++) {
arr[i] = Integer.parseInt(st.nextToken());
}
Arrays.sort(arr);
int M = Integer.parseInt(br.readLine());
st = new StringTokenizer(br.readLine()," ");
StringBuilder sb = new StringBuilder();
for(int i = 0; i < M; i++) {
int value = Integer.parseInt(st.nextToken());
// upperBound와 lowerBound의 차이 값을 구한다.
sb.append(upper_bound(arr, value) - lower_bound(arr, value)).append(' ');
}
System.out.println(sb);
}
static int lower_bound(int[] arr, int value) {
int left_idx = 0;
int right_idx = arr.length;
// 두 개의 인덱스가 같을 때 반복문이 종료된다.
while(left_idx < right_idx) {
int mid = (left_idx + right_idx) /2;
if(value <= arr[mid]) {
right_idx = mid;
}
else {
// 중앙값 < value가 더 클 경우
// 마지막 인덱스에서 일치하고자 하는 값 첫 번째에 오기 위해
// 사용되는 로직
left_idx = mid + 1;
}
}
return left_idx;
}
static int upper_bound(int[] arr, int value) {
int left_idx = 0;
int right_idx = arr.length;
// 왼쪽과 오른쪽이 같아질 때까지 반복
while(left_idx < right_idx) {
int mid = (left_idx + right_idx) /2;
if(value < arr[mid]) {
right_idx = mid;
} else {
left_idx = mid + 1;
}
}
return left_idx;
}
}🤢 회고
가면 갈수록.. 블로그 글에 열정을 쏟지 않는것 같다.
아무래도 반복되는 패턴의 글을 매번 적다보니 그런것 같은데 그래도 최선을 다해 적으려 노력해보겠다.
사실 쉬운 문제도 포스팅하는데 최소 1시간 이상씩 걸린다
💜 참고자료
