
Links
A. Youtube
- Demo Video https://www.youtube.com/watch?v=EPOi7vhCWR0
B. Github
Members
| Name | Major | |
|---|---|---|
| Kim Useong | Information System | jeneve1@hanyang.ac.kr |
| Park Hankyu | Information System | official03x@hanyang.ac.kr |
| Chi Sangyun | Information System | csy9604@hanyang.ac.kr |
| Michael Sklors | Information System | skmi1013@h-ka.de |
I. Introduction
StudyBNB?
StudyBNB는 NUGU AI 스피커를 이용한 공부 기록 분석 및 암기 앱 서비스입니다. StudyBNB는 AI 스피커 및 스마트폰 앱을 통해 사용자의 학습 시간을 기록하며, 학습 시간 데이터를 이용하여 학습 습관을 분석합니다.
StudyBNB는 기존 타이머 앱들과는 다르게 AI 스피커 지원, StudyMate 매칭 기능, 그리고 Note-taking 기능이라는 세 가지 차별점을 가지고 있습니다.
- StudyBNB는 AI 스피커를 통해 학습 시간 기록이 가능하기에 집에서 공부할 때 편하게 이용 가능하고, 자칫 스마트폰을 통해 타이머 앱을 실행하려다 다른 앱을 사용하며 시간을 허비할 염려가 없습니다.
- StudyBNB는 매칭 기능을 제공합니다. 똑같은 과목을 공부하고 비슷한 학습 패턴을 가진 StudyMate와 경쟁하며 학습 의욕을 불태울 수 있습니다.
- StudyBNB는 Note-taking 기능을 제공하여 외워야 할 개념, 문제, 영단어 등을 DB 내에 저장하여 AI 스피커를 통해 재생시켜 들으며 암기할 수 있습니다.
이처럼 StudyBNB는 사용자가 좋은 컨디션으로 효율적이고도 밀도 높은 학습을 할 수 있게 도와주고, 학습 의욕을 고취시키는 '함께 학습하는 친구'같은 소프트웨어가 될 것입니다.
도입 배경
효과적인 공부를 위해서 가장 중요한 것은 무엇일까요? 본인에게 맞는 커리큘럼과 꾸준함, 그리고 기록입니다. 학생들은 공부를 하지만 본인이 어떤 과목에 얼마나 투자를 했는지 잘 알지 못합니다. 또한 책상 앞에서 노트북이나 휴대폰을 하는 등 딴 짓을 하다 보면 시간 관리가 얼마나 중요한지 깨닫게 되죠. 더해서 시험 기간에는 공부에 지나치게 몰입해서 쉬는 것도 잊어버리는 비효율적인 공부를 하곤 합니다.
저희는 이러한 학습의 비효율성을 확인하고, 사용자들의 학습 효율 증진에 도움을 줄 수 있는 인공지능 기반 소프트웨어 StudyBNB를 개발하였습니다. 학생들은 StudyBNB를 이용하며 본인의 공부 습관을 점검할 수 있고, 좋은 컨디션을 유지하면서 공부에 집중할 수 있습니다.
StudyBNB는 사용자의 발화를 AI 스피커를 통해 인식하여, 학습 시간을 기록하고, 자신의 학습 상태와 그룹 내 구성원들의 학습 상태를 확인할 수 있습니다. 또한 StudyBNB는 StudyMate 기능을 제공합니다. 사용자로부터 '나이, 성별, 관심 학습 분야, 현재 성적' 등의 데이터를 입력 받고 타이머 기능에서 '1일 평균 학습시간', '1회 평균 학습시간', '평균 쉬는 시간' 등의 학습 패턴 데이터를 얻을 수 있습니다. 그리고 사용자는 상기된 데이터들을 이용한 AI 분석을 통해 자신과 유사한 StudyMate와 매칭됩니다. 사용자는 이렇게 매칭된 StudyMate의 학습 시간과 공부 상태를 확인할 수 있으며, 이를 통해 학습 자극을 받을 수 있습니다.
현재 많은 학생들이 공부를 하면서 필연적으로 암기를 하는 과정을 거치고 있습니다. 하지만 모두 단순히 글을 보는 ‘시각적‘ 암기에 의존할 뿐입니다. StudyBNB는 이러한 시각만 활용하는 암기보다 복합적 감각을 사용하는 암기법에 주목을 했습니다. 소리와 함께 템플릿을 읽는 것은 소리 없이 읽는 것보다 약 3배 이상 더 기억에 오래 남는다는 연구 결과가 있습니다. StudyBNB는 OCR 서비스를 이용하여 틀린 문제나 외워야 할 영단어 등을 간편하게 사진을 찍어 앱과 데이터베이스 내에 저장할 수 있습니다. 데이터는 DB로부터 로드되어 앱을 통해 언제 어디서든 확인 가능하고, NUGU AI 스피커를 이용해 저장된 내용을 재생할 수 있습니다. 이미 암기한 내용은 앱 내의 삭제 기능을 통해 DB에서 지울 수 있구요.
이처럼 StudyBNB는 사용자가 좋은 컨디션으로 효율적이고도 밀도 높은 학습을 할 수 있게 도와주고, 학습 의욕을 고취시키는 '함께 학습하는 친구'같은 소프트웨어가 될 것입니다.
A. Study Timer Checker
- 현재 공부시간을 기록함으로써 본인의 공부 기록을 남길 수 있음
- 공부 시간의 효율적인 관리 가능
- 공부 데이터를 실시간으로 DB에 업로드하여 사용자 별 데이터 분석에 사용
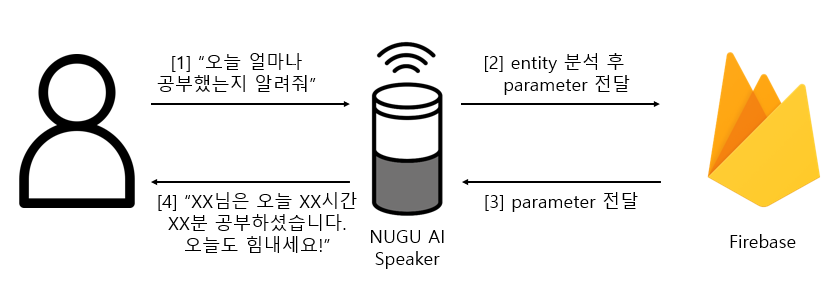
- NUGU AI 스피커를 통해 사용자와 StudyMate의 공부 진행 상황 확인 가능
B. Note-taking
- 청각과 시각 모두를 활용하여 암기력 및 기억력 향상
- 사용자는 문제 이미지와 함께 이미지에 대한 암기 사항을 DB에 업로드
- 데이터는 DB에서 로드되어 App을 통해 어디서든 확인 가능함
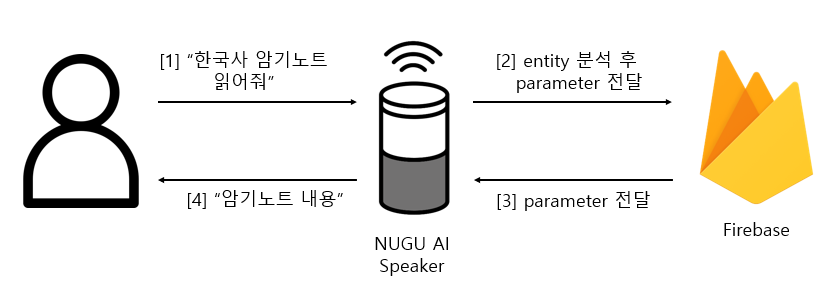
- NUGU AI 스피커를 이용해 언제든지 저장된 내용을 재생 가능
III. Overall Architecture
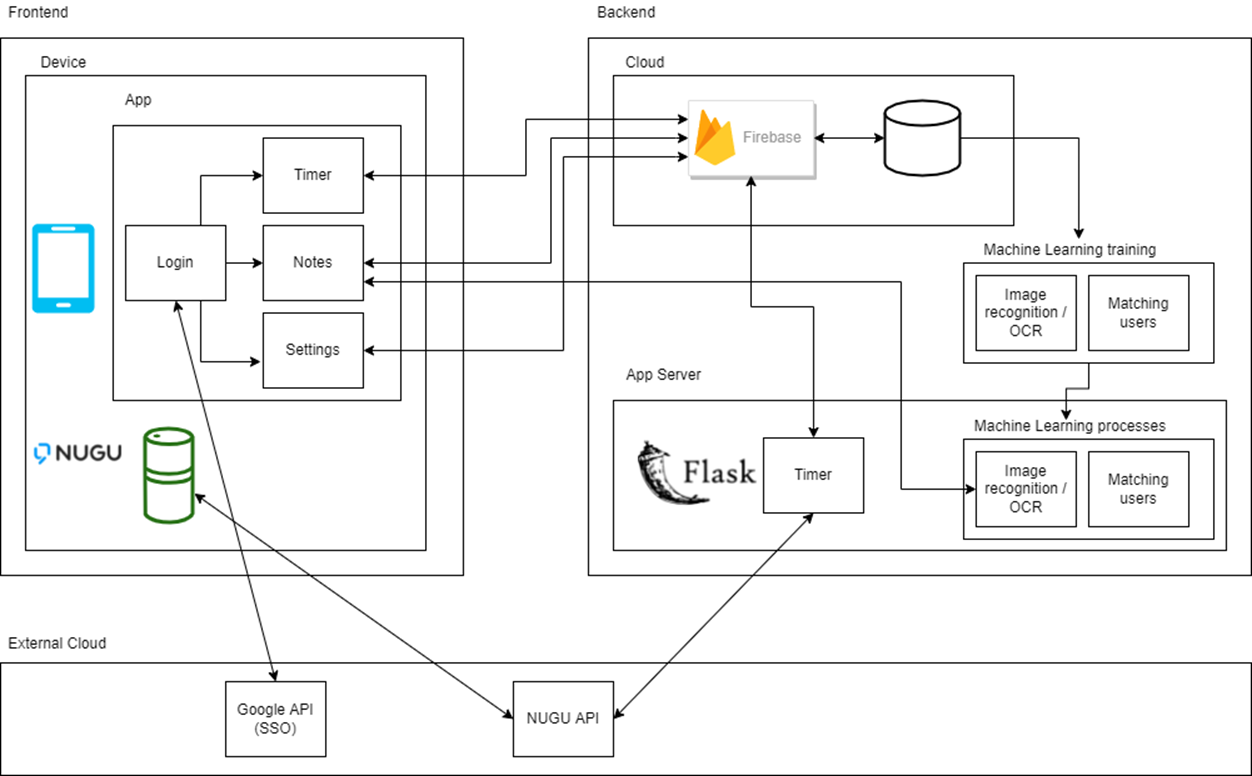
Application
- Tool: Android Studio
- Language: Kotlin
- API: Google Vision API
Server
- Tool: Visual Studio Code
- Language: Python
- Database: Firebase(Firestore)
- Cloud Server: AWS EC2
- Backend: Flask
AI Model
- Tool: Visual Studio Code
- Language: Python
- API: Scikit-learn
IV. Service Scenario
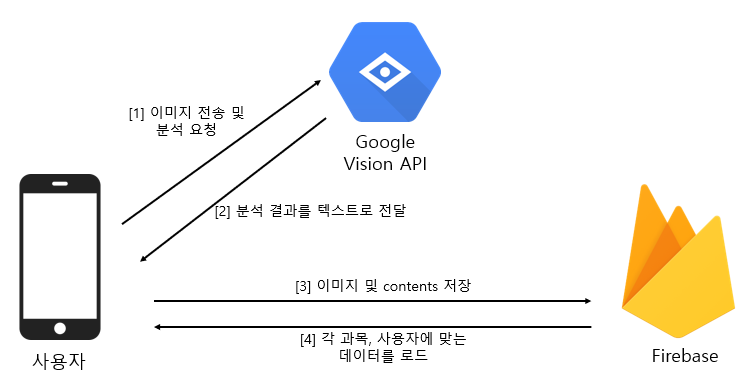
A. Save memo
B. Check study time
C. Play memo
V. Datasets
A. StudyMate
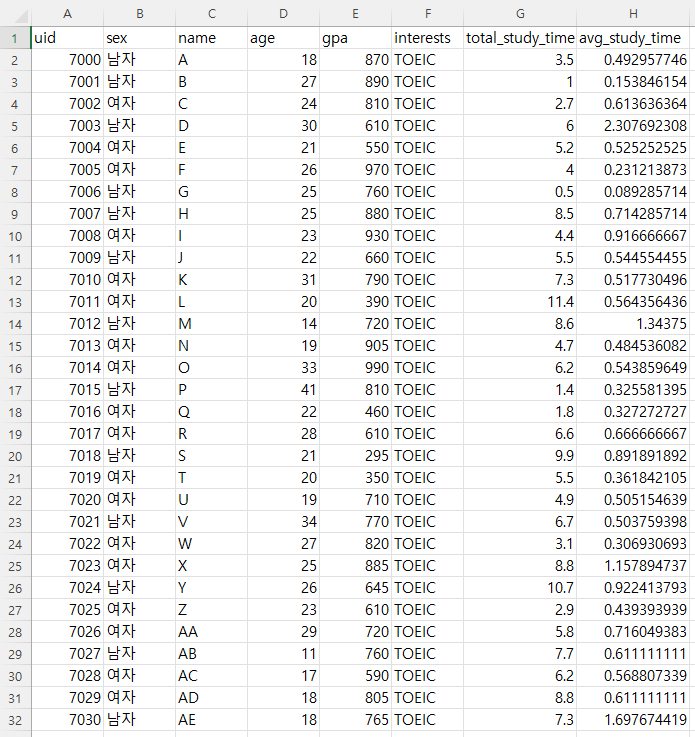
StudyBNB는 Firebase DB 내의 사용자의 '1일 평균 학습시간, 1일 평균 휴식 횟수' 등의 데이터를 이용하여 StudyMate 매칭 기능을 제공합니다.
하지만, 이러한 사용자 개인의 학습 시간 및 휴식 횟수에 대한 데이터는 일반적으로 쉽게 구할 수 없었습니다. 따라서, 저희는 가상의 더미 데이터를 만들어 매칭 기능의 정확성을 점검하는 데 이용하였습니다. 실제 상용화 시에는 사용자들의 관심 과목이 다양할 테지만, 저희는 현재 기능 테스트를 위한 더미 데이터를 만들었기에, 모든 사용자들의 관심 과목을 'TOEIC'으로 통일하여 TOEIC 한 과목에 대한 분석만을 수행하기로 하였습니다.
B. Note-taking
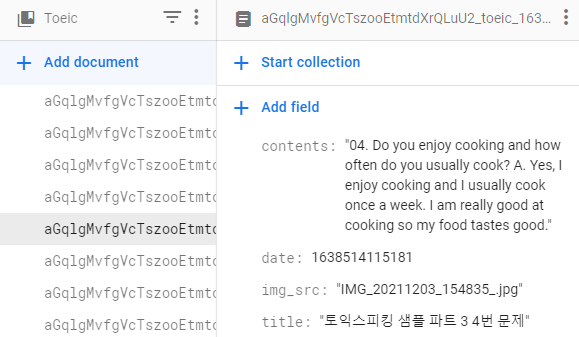
StudyBNB는 사용자가 올린 이미지를 텍스트로 변환하는 OCR(Optical character recognition, 광학 문자 인식)기능을 제공합니다.
구글 Firebase에서 제공하는 ML Kit의 텍스트 인식 API를 사용하여 라틴어 기반의 모든 텍스트를 인식할 수 있습니다. 텍스트 인식을 통해 번거로운 텍스트 입력을 자동화 할 수 있으며, 유저는 추출한 텍스트의 편집이 가능합니다. 이러한 데이터는 사용자가 Note-taking 기능을 통해 암기 노트를 작성할 때, DB에 있는 Firestore에 업로드됩니다.
VI. Methodology
A. StudyMate
- 왜 K-mean Clustering인가 저희는 매칭 알고리즘으로 K-mean Clustering 기법을 사용하였습니다. 저희는 많은 사용자들 중 같은 과목을 학습하는 사용자들 중 가장 유사한 두 사용자를 하나의 매칭 그룹으로 만들고 싶었습니다. 사용자 정보에 대한 label이 따로 존재하지 않았으므로, 저희는 머신러닝 기법들 중 Clustering을 이용하여 사용자들을 여러 군집으로 나눈 후, 각각의 군집에서 무작위로 두 사용자를 택하여 매칭시키는 방법을 택하기로 하였습니다. Clustering 기법들 중 하나인 K-mean Clustering 기법은 군집의 수를 미리 정할 필요가 없고, 유클리드 거리 기반으로 유사 군집을 탐색하기 때문에 저희가 원하는 바대로, 유사도 높은 두 개체를 매칭시키기에 적합하다고 생각했습니다.
- 데이터 정규화 raw data를 그대로 Clustering에 사용하는 것과 데이터 정규화를 거치고 난 후 Clustering을 진행하는 것은 큰 차이가 있습니다. raw data를 그대로 사용할 경우, scale이 더 큰 feature의 영향력이 그렇지 않은 feature의 영향력보다 지나치게 커질 수 있습니다. 우리는 그러한 현상을 방지하고자 정규화 과정을 거치기로 했습니다.
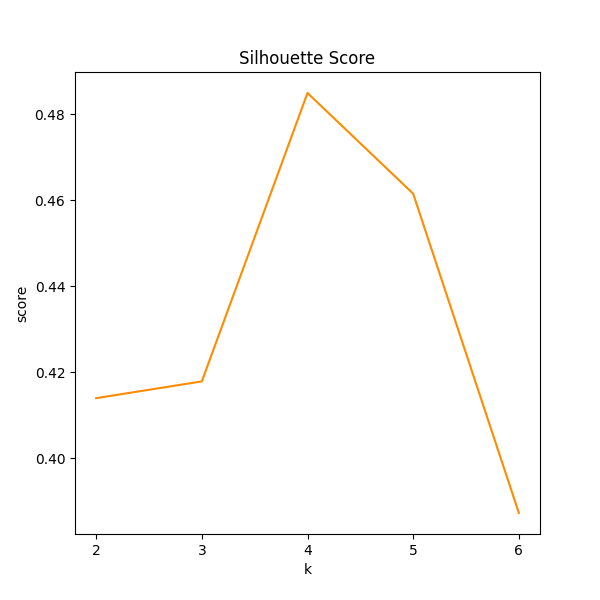
sdscaler = StandardScaler() df[['total_study_time', 'avg_study_time']] = sdscaler.fit_transform(df[['total_study_time', 'avg_study_time']]) - 최적의 K 찾기 군집의 수를 미리 정하지 않아도 K-mean Clustering은 동작하지만, 만약 K의 범위를 정하지 않는다면 두 가지 문제가 생길 수 있습니다. 만일 K가 너무 적은 숫자가 될 경우 거의 모든 사용자가 같은 군집에 속하게 되어, 이 매칭 알고리즘을 돌리는 이유가 없어질 지도 모릅니다. 반대로 K가 너무 큰 숫자가 될 경우 사용자들이 매우 많은 군집으로 분화되어 많은 사용자가 매칭이 이루어지지 않는 경우가 많이 생길 수도 있습니다. 한 군집에 사용자가 홀수 명 있을 경우 한 명의 사용자는 매칭에 실패하게 되기 때문입니다. 따라서 저희는 K의 범위를 정하고 그 범위 내에서 전체 사용자를 가장 특색 있는 군집으로 나눌 수 있는, 최적의 K를 찾기로 했습니다. K가 너무 적은 값도 너무 큰 값도 아닌 적당한 값을 가지게 하기 위해, 2 K 의 범위를 만족하는 자연수 K 중 가장 높은 Silhouette Score를 가지는 K를 최적의 K로 간주하기로 하였습니다.
def findBestK(df): sil = [] kmax = round(math.sqrt(len(df))) for k in range(2, kmax + 1): kmeans = KMeans(n_clusters = k).fit(df[['total_study_time', 'avg_study_time']]) labels = kmeans.labels_ sil.append(silhouette_score(df[['total_study_time', 'avg_study_time']], labels, metric = 'euclidean')) return (2 + sil.index(max(sil))) - K-mean Clustering 찾아낸 최적의 K를 이용하여, K-mean Clustering을 진행하였습니다.
def kmean(df, k): kmeans = KMeans(n_clusters = k).fit(df[['total_study_time', 'avg_study_time']]) labels = kmeans.labels_ return labels - 각각의 Cluster 내에서 매칭하기 Clustering 결과인 각각의 군집 내에서 랜덤하게 두 사용자를 골라 매칭시켰습니다. 만약, 군집이 홀수 명의 사용자로 구성된다면, 마지막 한 명의 사용자는 매칭에 실패하게 됩니다.
def match(lists): couples = [] for list in lists: if len(list) % 2: list.pop() random.shuffle(list) for i in range(0, len(list), 2): temp_arr = [] temp_arr.append(df_uid[list[i]]) temp_arr.append(df_uid[list[i+1]]) couples.append(temp_arr) return couples
B. Note-taking
- OCR in Android Application 앱 내에서 OCR의 구현 방식은 다음과 같습니다. 이미지 속 텍스트를 인식하기 위해선
Bitmap또는media.Image,ByteBuffer, 바이트 배열 또는 기기의 파일에서FirebaseVisionImage객체를 만듭니다. 그런 다음FirebaseVisionImage객체를FirebaseVisionTextRecognizer의processImage메서드에 전달하고, 태스크가 수행되면 이미지는 텍스트로 변환됩니다.
if(requestCode == 0 && resultCode == Activity.RESULT_OK && data != null){
selectedPhotoUri = data.data
val bitmap = MediaStore.Images.Media.getBitmap(contentResolver, selectedPhotoUri)
if(bitmap != null){
img_btn.setImageBitmap(bitmap)
}else{
val icon = BitmapFactory.decodeResource(getResources(), R.drawable.photo_default)
img_btn.setImageBitmap(icon)
}
// Create a FirebaseVisionImage object from your image/bitmap.
val firebaseVisionImage = FirebaseVisionImage.fromBitmap(bitmap!!)
val firebaseVision = FirebaseVision.getInstance()
val firebaseVisionTextRecognizer = firebaseVision.onDeviceTextRecognizer
// Process the Image
val task = firebaseVisionTextRecognizer.processImage(firebaseVisionImage)
task.addOnSuccessListener { firebaseVisionText: FirebaseVisionText ->
//Set recognized text from image in our TextView
val text = firebaseVisionText.text
contents_view!!.setText(text)
}
}VII. Evaluation & Analysis
A. StudyMate
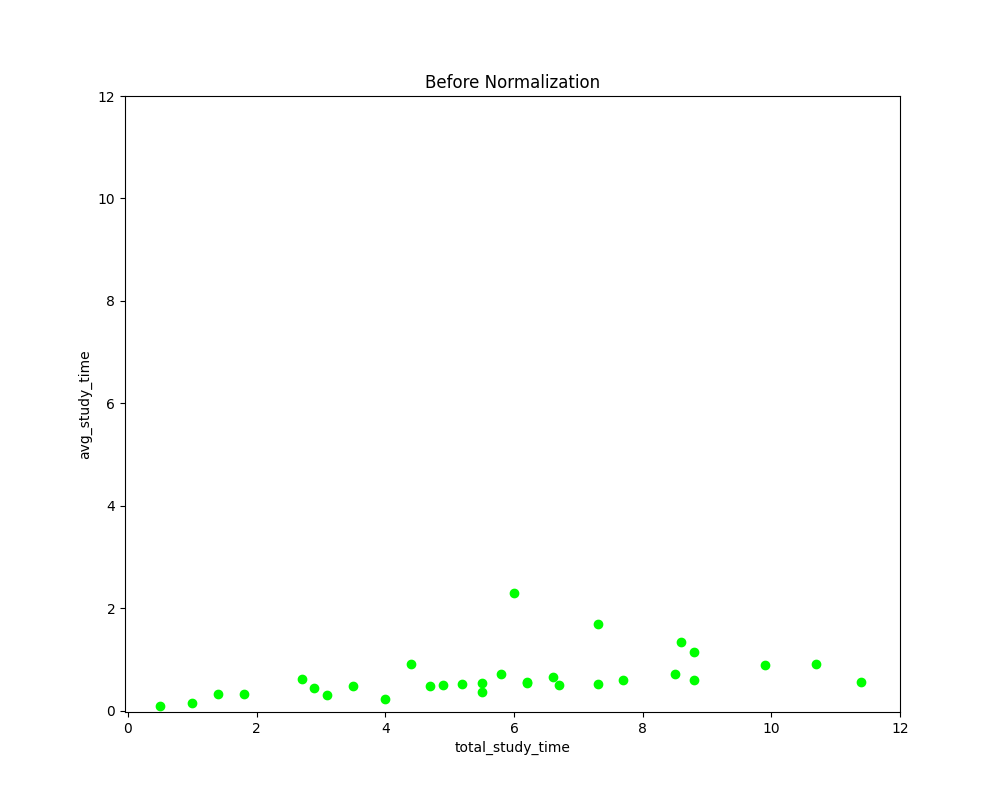
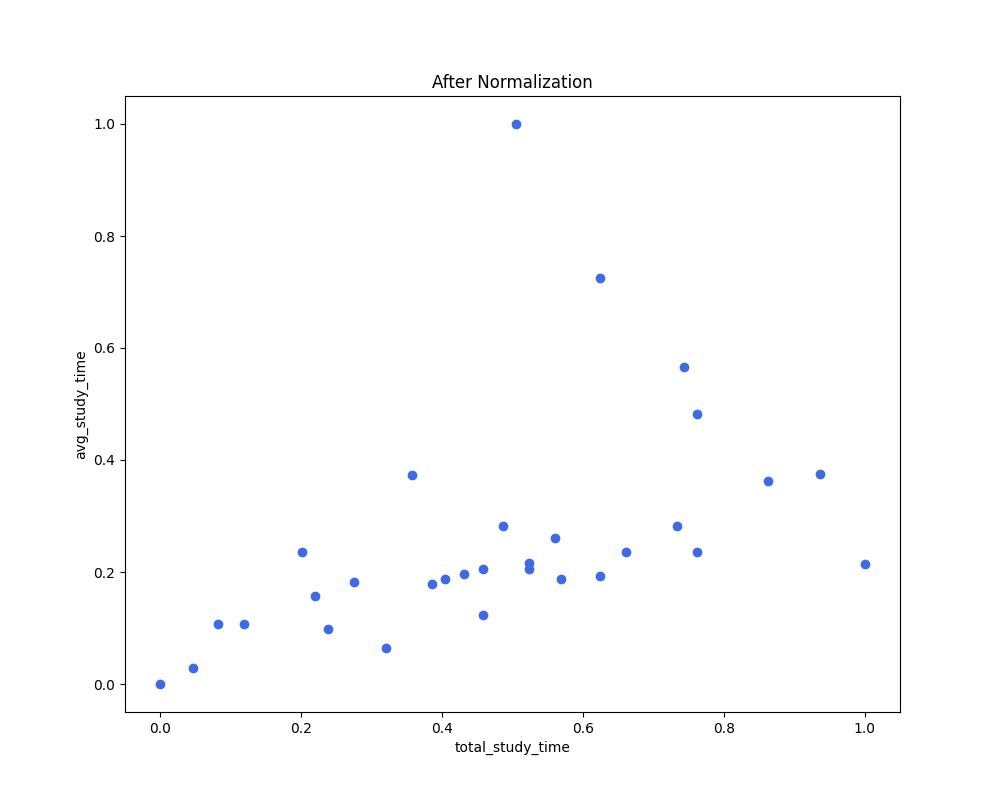
- 정규화 이전/이후 정규화 이전에는 'total_study_time'의 scale이 'avg_study_time'에 비해 매우 큰 반면, 정규화 이후에는 두 feature가 같은 scale을 보여준다는 것을 확인할 수 있습니다.
- Silhouette Score 최선의 K를 판별하는 Silhouette Score입니다. 해당 case에는 K=4로 설정하는 것이 좋다는 것을 알 수 있습니다.
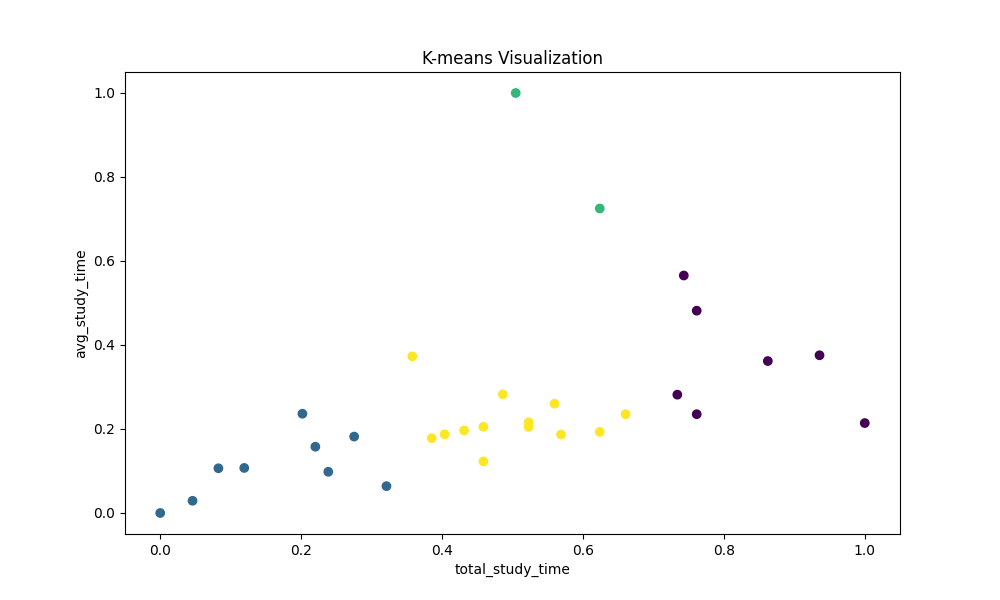
- K-mean Clustering K-mean Clustering의 결과를 시각화한 graph입니다. 각각의 군집이 다른 색으로 표현됩니다.
B. Note-taking
- 이미지 내의 텍스트와 이미지를 변환한 텍스트의 유사도를 비교/분석하여 데이터 인식 정확도에 대해 점검하였습니다.
- 데이터 약 30개 정도를 모아 데이터 인식 정확도를 분석한 결과, 약 98.6% 정도의 정확성을 보였습니다.
VIII. Conclusion
- Presentation Video
https://www.youtube.com/watch?v=kBrq5Cp0K_0
저희는 처음 개발 계획을 시작했을 때, StudyMate와 Note-taking의 두 가지 AI 기반 서비스를 탑재하여 스마트폰 앱과 AI 스피커의 두 가지 경로로 서비스하려고 계획하였습니다.
하지만, 제한된 개발 능력과 시간적 제약 때문에 처음 계획과는 약간 수정된 결과물을 낼 수 밖에 없었습니다. 여러 부분들 중 StudyMate 기능을 앱 내에 완전히 구현하지 못했다는 점이 제일 아쉬운 점입니다. 또한, 보다 다양한 과목과 그룹 기능을 추가하지 못한 것도 아쉽습니다. 만일 기존 계획대로 서비스를 확장시킬 수 있다면, 조금 더 기능적으로 완성된 소프트웨어로 만들 수 있을 것 같습니다.
