딥러닝
신경망과 딥러닝
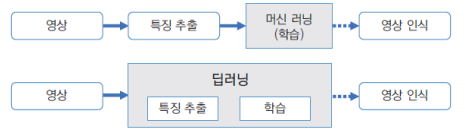
딥러닝(deep learning)은 2000년대부터 사용되고 있는 심층 신경망(deep neural network)의 또 다른 이름임
신경망(neural network)은 인공 신경망(artificial neural network)이라고도 불림
이는 사람의 뇌 신경 세포(neuron)에서 일어나는 반응을 모델링하여 만들어진 고전적인 머신 러닝 알고리즘임
딥러닝이란 신경망을 여러 계층(layer)으로 쌓아서 만든 머신 러닝 알고리즘 일종임
컴퓨터 비전 분야에서 딥러닝 기술이 크게 주목받고 있는 이유는 객체 인식, 얼굴 인식, 객체 검출, 분할 등의 다양한 영역에서 딥러닝이 적용된 기술이 기존의 컴퓨터 비전 기반 기술보다 월등한 성능을 보여 주고 있기 때문임
OpenCV DNN 모듈
OpenCV dnn 모듈은 이미 만들어진 네트워크에서 순방향 실행을 위한 용도로 설계됨
딥러닝 학습은 기존의 유명한 카페(Caffe), 텐서플로(TensorFlow) 등의 다른 딥러닝 프레임워크에서 진행함
학습된 모델을 불러와서 실행할 때에는 dnn 모듈을 사용하는 방식임
많은 딥러닝 프레임워크가 파이썬 언어를 사용하고 있지만, OpenCV dnn 모듈은 C/C++ 환경에서도 동작할 수 있기 때문에 프로그램 이식성이 높다는 장점이 있음
dnn 모듈은 OpenCV 3.1에 서는 추가 모듈 형태로 지원되었고, OpenCV 3.3 버전부터 기본 모듈에 포함됨
OpenCV dnn 모듈은 이미 널리 사용되고 있는 딥러닝 네트워크 구성을 지원함
최근에 새롭게 개발되고 있는 딥러닝 네트워크도 지속적으로 추가 지원하고 있음
영상 인식과 관련된 AlexNet, GoogLeNet, VGG, ResNet, SqueezeNet, DenseNet, ShuffleNet, MobileNet, Darknet 등의 네트워크가 OpenCV에서 동작됨이 확인됨
객체 검출과 관련해서 는 VGG-SSD, MobileNet-SSD, Faster-RCNN, R-FCN, OpenCV face detector, Mask-RCNN, EAST, YOLOv2, tiny YOLO, YOLOv3 등의 모델을 사용할 수 있음
이외에도 사람의 포즈를 인식하는 OpenPose, 흑백 영상에 자동으로 색상을 입히는 Colorization, 사람 얼굴 인식을 위한 OpenFace 등의 모델도 OpenCV dnn 모듈에서 사용할 수 있음
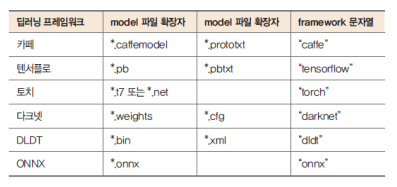
framework 인자에는 모델 파일 생성 시 사용된 딥러닝 프레임워크 이름을 지정함
만약 model 또는 config 파일 이름 확장자를 통해 프레임워크 구분이 가능한 경우에는 framework 인자를 생략할 수 있음
model과 config 인자에 지정할 수 있는 파일 이름 확장자와 framework에 지정 가능한 프레임워크 이름을 표 16-1에 정리함
MNIST 필기체 숫자 인식
필기체 숫자 인식
딥러닝 분야에서는 필기체 숫자 인식 훈련을 위해 MNIST 데이터셋을 주로 사용함
MNIST는 뉴욕 대학교 얀 르쿤(Yann LeCun) 교수가 우편 번호 등의 필기체 숫자 인식을 위해 사용했던 데이터셋으로, 6만 개의 훈련용 영상과 1만 개의 테스트 영상으로 구성되어 있음
각각의 숫자 영상은 28×28 크기로 구성되어 있고, 픽셀 값은 0에서 1 사이의 실수 값으로 정규화 되어 있음
텐서플로로 학습시킨 mnist_cnn.pb 파일을 불러와서 네트워크를 생성함
사용자가 마우스로 그린 필기체 숫자 영상을 네트워크 입력으로 전달하여 그 결과를 예측함
프로그램이 처음 실행되면 검은색으로 초기화된 img 영상이 화면에 나타남
이 위에서 마우스 왼쪽 버튼을 눌러서 숫자를 그린 후 Space 키를 누르면 콘솔 창에 인식 결과가 출력됨
#include "opencv2/opencv.hpp"
#include <iostream>
using namespace std;
using namespace cv;
using namespace cv::dnn;
void on_mouse(int event, int x, int y, int flags, void* userdata);
int main()
{
Net net = readNet("mnist_cnn.pb");
if (net.empty())
{
cerr << "Network load failed!" << endl;
return -1;
}
Mat img = Mat::zeros(400, 400, CV_8UC1);
imshow("img", img);
setMouseCallback("img", on_mouse, (void*)&img);
while (true)
{
int c = waitKey(0);
if (c == 27)
{
break;
}
else if (c == ' ')
{
Mat blob = blobFromImage(img, 1 / 255.f, Size(28, 28));
net.setInput(blob);
Mat prob = net.forward();
double maxVal;
Point maxLoc;
minMaxLoc(prob, NULL, &maxVal, NULL, &maxLoc);
int digit = maxLoc.x;
cout << digit << " (" << maxVal * 100 << "%)" << endl;
img.setTo(0);
imshow("img", img);
}
}
return 0;
}
Point ptPrev(-1, -1);
void on_mouse(int event, int x, int y, int flags, void* userdata) //마우스 이벤트 조작
{
Mat img = *(Mat*)userdata;
if (event == EVENT_LBUTTONDOWN)
{
ptPrev = Point(x, y);
}
else if (event == EVENT_LBUTTONUP)
{
ptPrev = Point(-1, -1);
}
else if (event == EVENT_MOUSEMOVE && (flags & EVENT_FLAG_LBUTTON))
{
line(img, ptPrev, Point(x, y), Scalar::all(255), 40, LINE_AA, 0);
ptPrev = Point(x, y);
imshow("img", img);
}
}코드를 작성하면 아래와 같이 마우스 왼쪽 버튼을 눌러서 숫자를 그리고, 스페이스 키를 누르면 콘솔 창에 인식 결과가 출력이 됨
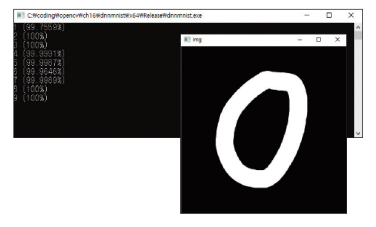
정확도가 많이 떨어지는 모습을 볼 수 있음 > 과거의 데이터를 사용하였기 때문
구글넷 영상 인식
구글넷 영상 인식
딥러닝이 컴퓨터 비전 분야에서 크게 발전할 수 있었던 이유 중에는 ILSVRC(ImageNet Large Scale Visual Recognition Competition) 대회의 영향도 있음
ILSVRC는 영상 인식과 객체 검출 등의 성능을 겨루는 일종의 알고리즘 경진 대회로서 2010년부터 매년 개최되고 있음
ILSVRC는 ImageNet이라는 대규모 영상 데이터베이스를 이용함
특히 영상 인식 분야에서는 1000개의 카테고리로 분류된 100만 개 이상의 영상을 사용하여 성능을 비교함
이 대회에서 2012년에 알렉스넷(AlexNet)이라는 딥러닝 알고리즘이 기존 컴퓨터 비전 및 머신 러닝 기반의
알고리즘보다 월등히 높은 성능을 나타냄
컴퓨터 비전 분야에 딥러닝 열풍이 시작됨[Krizhevsky12]
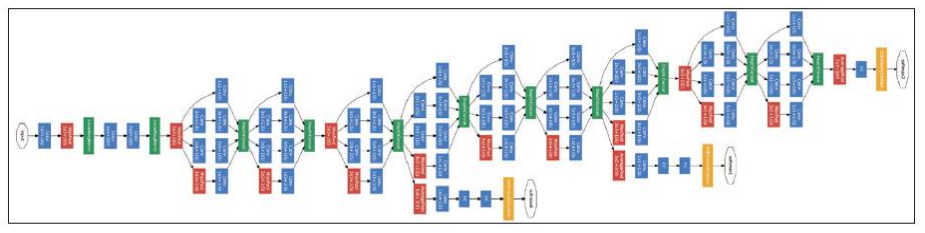
구글넷(GoogLeNet)은 구글(Google)에서 발표한 네트워크 구조
2014년 ILSVRC 영상 인식 분야에서 1위를 차지함[Szegedy15]
구글넷은 총 22개의 레이어로 구성됨
이는 동시대에 발표되었던 딥러닝 네트워크 구조 중에서 가장 많은 레이어를 사용한 형태임
레이어를 매우 깊게 설계하였지만 완전 연결 레이어가 없는 구조를 통해 기존의 다른 네트워크보다 파라미터 수가 훨씬 적은 것이 특징임
구글넷은 특히 다양한 크기의 커널을 한꺼번에 사용하여 영상에서 큰 특징과 작은 특징을 모두 추출할 수 있도록 설계됨
OpenCV에서 구글넷 인식 기능을 사용혀려면 다른 딥러닝 프레임워크를 이용하여 미리 훈련된 모델 파일과 구성 파일이 필요함
카페 프레임워크를 이용하여 학습된 구글넷 모델 파일은 다음 링크에서 내려받을 수 있음
http://dl.caffe.berkeleyvision.org/bvlc_googlenet.caffemodel
카페에서 훈련된 네트워크 구조를 표현한 구성 파일은 모델 주 깃허브 페이지에서 내려받을 수 있음
https://github.com/BVLC/caffe/blob/master/models/bvlc_googlenet/deploy.prototxt
구글넷 인식 기능을 제대로 구현하려면 모델 파일과 구성 파일 외에 인식된 영상 클래스 이름이 적힌 텍스트 파일이 추가로 필요함 (classification_classes_ILSVRC2012.txt) > 라벨 네임이라고 이해하면 됨
이 파일에는 1000개의 영상 클래스 이름이 한 줄씩 적혀 있음
구글넷 예제 프로그램을 만들기 위해 필요한 세 파일을 정리하면 다음과 같음
학습 모델 파일 : bvlc_googlenet.caffemodel
구성 파일 : deploy.prototxt
클래스 이름 파일 : classification_classes_ILSVRC2012.txt
영상에 포함된 주된 객체를 판단함
해당 객체 이름과 판단 확률을 영상 위에 문자열로 출력함
#include "opencv2/opencv.hpp"
#include <iostream>
#include <fstream>
using namespace std;
using namespace cv;
using namespace cv::dnn;
int main(int argc, char* argv[])
{
//load an image
Mat img;
if (argc < 2)
img = imread("cats.jpg", IMREAD_COLOR);
else
img = imread(argv[1], IMREAD_COLOR);
if (img.empty())
{
cerr << "image load failed!" << endl;
return -1;
}
//load network
Net net = readNet("bvlc_googlenet.caffemodel", "deploy.prototxt");
if (net.empty())
{
cerr << "network load failed!" << endl;
return -1;
}
//load class names
ifstream fp("classification_classes_ILSVRC2012.txt");
if (!fp.is_open())
{
cerr << "class file load failed!" << endl;
return -1;
}
vector<String> classNames;
string name;
while (!fp.eof())
{
getline(fp, name);
if (name.length())
classNames.push_back(name);
}
fp.close();
//inference
Mat inputBlob = blobFromImage(img, 1, Size(224, 224), Scalar(104, 117, 123));
net.setInput(inputBlob, "data");
Mat prob = net.forward();
//check results & display
double maxVal;
Point maxLoc;
minMaxLoc(prob, NULL, &maxVal, NULL, &maxLoc);
String str = format("%s (%4.2lf%%)", classNames[maxLoc.x].c_str(), maxVal * 100);
putText(img, str, Point(10, 30), FONT_HERSHEY_SIMPLEX, 0.8, Scalar(0, 0, 255));
imshow("img", img);
waitKey();
return 0;
}위 코드를 실행하면 아래와 같은 결과를 얻을 수 있다.
매칭되는 단어는 구글넷에 등록되어 있는 1000개의 단어 중 가장 유사한 단어를 가져온다

lynx : 스라소니...
catamount : 퓨마...
SSD 얼굴 인식
SSD 얼굴 인식
download_weights.py 파일은 인터넷에서 얼굴 검출을 위해 미리 훈련된 학습 모델 파일을 내려받음
download_weights.py 파일은 res10_300x300_ssd_iter_140000_fp16.caffemodel 파일과
opencv_face_detector_uint8.pb 파일 두 개를 내려받음
res10_300x300_ssd_iter_140000_fp16.caffemodel 파일은 Caffe 프레임워크에서 훈련된 파일임
opencv_face_detector_uint8.pb 파일은 텐서플로에서 훈련된 파일임
두 학습 모델은 비슷한 성능으로 동작하고, 어느 것을 사용해도 무방함
내려받은 학습 모델 파일은 2016년에 발표된 SSD(Single Shot Detector) 알고리즘을 이용하여 학습된 파일임[Liu16]
SSD는 입력 영상에서 특정 객체의 클래스와 위치, 크기 정보를 실시간으로 추출할 수 있는 객체 검출 딥러닝 알고리즘임
SSD 알고리즘은 원래 다수의 클래스 객체를 검출할 수 있지만 OpenCV에서 제공하는 얼굴 검출은 오직 얼굴 객체의 위치와 크기를 알아내도록 훈련된 학습 모델을 사용함
기본적인 SSD 네트워크는 아래 그림과 같음
이 구조에서 입력은 300×300 크기의 2차원 BGR 컬러 영상을 사용함
이 영상은 Scalar(104, 117, 123) 값을 이용하여 정규화한 후 사용함
12 SSD 네트워크의 출력은 추출된 객체의 ID, 신뢰도(정확성), 사각형 위치 등의 정보를 담고 있음
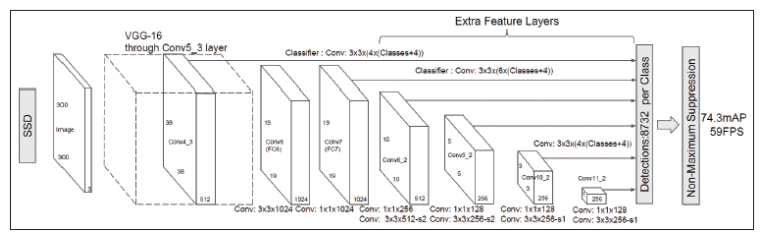
딥러닝을 이용한 얼굴 검출 예제 프로그램은 컴퓨터에 연결된 카메라로부터 들어오는 매 프레임마다 얼굴을 검출함
#include "opencv2/opencv.hpp"
#include <iostream>
using namespace std;
using namespace cv;
using namespace cv::dnn;
const String model = "res10_300x300_ssd_iter_140000_fp16.caffemodel";
const String config = "deploy.prototxt"; //두개의 파일을 폴더 안에 넣음
//const String model = "opencv_face_detector_uint8.pb";
//const String config = "opencv_face_detector.pbtxt";
int main(void)
{
VideoCapture cap(0);
if (!cap.isOpened())
{
cerr << "camera open failed!" << endl;
return -1;
}
Net net = readNet(model, config);
if (net.empty())
{
cerr << "net open failed" << endl;
return -1;
}
Mat frame;
while (true)
{
cap >> frame;
if (frame.empty())
break;
Mat blob = blobFromImage(frame, 1, Size(300, 300), Scalar(104, 177, 123));
net.setInput(blob);
Mat res = net.forward();
Mat detect(res.size[2], res.size[3], CV_32FC1, res.ptr<float>());
for (int i = 0; i < detect.rows; i++)
{
float confidence = detect.at<float>(i, 2);
if (confidence < 0.5)
break;
int x1 = cvRound(detect.at<float>(i, 3) * frame.cols);
int y1 = cvRound(detect.at<float>(i, 4) * frame.rows);
int x2 = cvRound(detect.at<float>(i, 5) * frame.cols);
int y2 = cvRound(detect.at<float>(i, 6) * frame.rows);
rectangle(frame, Rect(Point(x1, y1), Point(x2, y2)), Scalar(0, 255, 0));
String label = format("Face : %4.3f", confidence);
putText(frame, label, Point(x1, y1 - 1), FONT_HERSHEY_SIMPLEX, 0.8, Scalar(0, 255, 0));
}
imshow("frame", frame);
if (waitKey(1) == 27)
break;
}
return 0;
}얼굴 영역을 정확하게 검출하여 녹색 사각형을 그리고, 녹색 사각형 위에 얼굴 검출 신뢰도가 함께 출력된 것을 볼 수 있음
캐스케이드 분류기 기반의 얼굴 검출 방법은 정면 얼굴이 아니면 얼굴 검출에 실패하는 경우가 많음
SSD 딥러닝 기반의 얼굴 검출은 얼굴 일부가 가려지거나 얼굴 옆모습이 입력으로 들어가도 안정적으로 얼굴 영역을 검출하는 것을 확인할 수 있음
얼굴 검출 속도도 캐스케이드 분류기 기반의 방법보다 SSD 딥러닝 기반의 얼굴 검출이 더 빠르게 동작함
