CeyMo : See more on road - A novel benchmark dataset for road marking detection 논문 리뷰
자율주행 Perception
목록 보기
19/19
road marking detection을 위한 dataset과 road marking을 탐지하는 내용에 관한 논문이다.
0. Abstract
- ceymo dataset
- 11 class
- 4706개의 road marking이 포함된 2887 image
- 1920 x 1080 해상도
- polygon, bounding box, segmentation 3가지의 annotation
1. introduction
기존 연구
후보 영역 생성 → 머신러닝 기반 알고리즘 사용
최근 연구
- end-to-end 딥러닝 기반 instance segmentation, semantic segmentation 네트워크 사용
- 빠르고 효율적 but! 연구 부족
본 연구
instance segmentation 및 객체 감지 기반 접근 방법 사용
- instance segmentation → mask RCNN
- object detection → SSD
- inverse perspective transform (IPT) 함께 사용
2. related work
기존 공개 road marking detection dataset + detection 알고리즘 분석
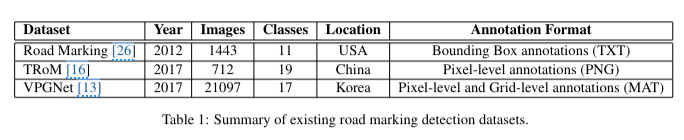
2.1 Datasets
- A Practical System for Road Marking Detection and Recognition의 dataset
- 11 class
- 1443개의 annotation
- 800 x 600 해상도
- bounding box에 대한 정보
- 이미지 처리 기반 접근 방식, 별도의 train, test set 제공x, 평가 기준 명확x
- TRoM (Tsinghua Road Marking Dataset)
- 19 class (차선 + road marking)
- 712개의 이미지
- 픽셀 수준의 sementic segmentation annotation이 PNG로 제공
- 데이터셋의 수 적음, annotation과 평가가 sementic segmentation 기반이라 다양한 mark 감지에 제한적
- VPGNet
- 2만개의 이미지
- 17 class (but! road marking 관련은 8개 class, 5만개의 instance가 other road marking으로 라벨링)
- 차선의 소실점을 포함한 차선, road marking의 픽셀 수준 및 grid 수준 annotation이 MAT 파일 형식으로 제공
- 평가 : IoU
- 차선 위주
2.2 알고리즘
고전적인 방법
- 대부분 고전적인 이미지 처리 기술 + 간단한 머신러닝
- 일반적인 detection pipeline : 이미지 전처리 → ROI 생성 → 특징 추출 및 머신러닝 알고리즘
- 원본 이미지를 IPT하여 보정하는 것은 일반적으로 사용되는 전처리 기술
- IPT 대신 차선 정보를 사용하여 검색 영역을 축소할 수 있다고 제안 (Fast symbolic road marking and stop-line detection for vehicle localization 논문) → but! 차선 탐지 정확도에 직접적으로 의존하기 때문에 성능 제한될 수 있음
- A practical system for road marking detection and recognition 논문
- Maximally stable extremal regions (MSER)은 가능한 후보 영역으로 사용됨
- histogram of oriented gradients (HOG) feature descriptor가 각 클래스에 대한 template pool을 구축하는데 사용됨
- 추론 시에 각 이미지는 모든 템플릿 이미지와 비교되어 클래스가 할당됨
- 그러나 복잡한 시나리오에서는 일반적으로 supervised 학습 방법이 템플릿 매칭 방법보다 더 잘 수행됨
- MSER 영역과 HOG 특징은 SVM 분류기와 함께 사용되어 symbol 기반 road marking 인지에 사용됨
- 별도의 OCR 알고리즘은 텍스트 기반 도로 표지판을 인식하는데 사용됨
- 그러나 서로 다른 road marking에 대해 다른 접근 방식을 가지로 있는 것은 계산 중복성을 초래할 수 있음
- 이러한 두가지 방법 모두 HOG 특징 추출을 포함하며 이는 시간이 많이 소요됨
- Road marking detection and classification using machine learning algorithms 논문
- Binarized normed gradients (BING) objectiveness 추정 알고리즘은 가능한 road marking 영역 제안을 생성하는데 사용
- PCANet 및 SVM integrated classifier는 road marking을 인지하는데 사용
- 이 방법의 단점은 BING이 일반적으로 더 큰 영역을 제안하기 때문에 위치 정확도가 낮음
- 로지스틱 회귀를 PCANet과 함께 사용되어 분류 정확도 향상
- 얕은 CNN도 road marking인식을 위한 분류기로 소개됨
- MSER 영역을 식별한 후에는 밀도 기반 클러스터링 알고리즘을 사용하여 제안된 road marking 영역을 병합하여 분류기를 위한 road marking 영역을 얻음
- 영역 제안을 얻기 위해 많은 전처리 기술 사용하고 PCANet 또는 얕은 CNN 분류기는 인식 부분에만 사용됨
딥러닝 기반 방법
- road marking detection 분야에서 딥러닝 기반 네트워크가 널리 사용되지는 않았다
- Benchmark for road marking detection: Dataset specification and performance baseline 논문
- ResNet-101와 피라미드 pooling 앙상블을 결합한 합성곱 신경망 모델을 사용하여 차선, road marking을 semantic segmentation으로 얻음
- 이는 TRoM dataset에서 평균 결과 달성
- VPGNet
- 차선, road marking을 동시에 감지하기 위한 CNN 기반 아키텍처
- road marking 탐지를 grid 최귀 작업으로 다루고 grid sampling 및 box clustering을 후처리 기술로 사용하여 grid cell 병합
- 그러나 이는 주로 차선 탐지 및 소실점 예측 작업에 더 많이 집중
3. benchmark dataset
3.1 data annotation
- 11 class
- polygon 좌표 JSON
- bounding box XML
- 픽셀 수준의 segmentation mask PNG

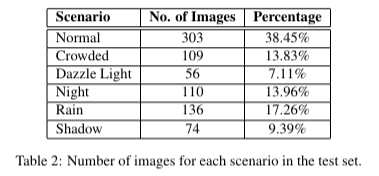
3.2 dataset 통계
- 2887장의 이미지 (2099개, 788개 → train, test)
- 클래스 불균형이 있음
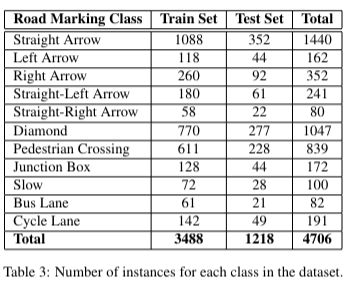
- test set 이미지는 6가지 시나리오로 구성
- 정상, 혼잡, 눈부심, 야간, 비, 그림자 (normal, crowded, dazzle light, night, rain and shadow)
3.3 평가 martix
- F1 score와 Macro F1 score 사용
- 예측과 실제 사이의 교차 영역 값이 계산되며 IoU가 0.3보다 크면 해당 예측이 true로 간주됨
- F1 score
- macro F1 score는 11 class의 F1 score의 평균
- macro F1 score는 dataset에 나타나는 빈도에 관계없이 모든 class에 동일한 중요도 부여
4. 방법
- 2가지 접근 방법
- object detection 방법
- instance segmentation 방법
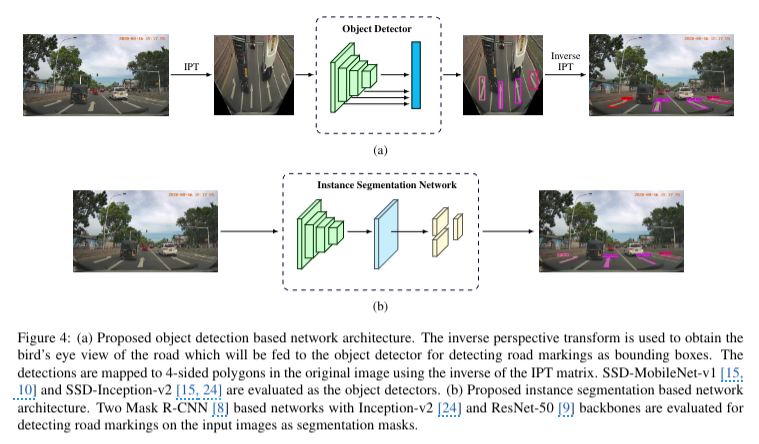
4.1 Object detection approach
- BEV 변환
- 먼저 inverse perspective transform(IPT)를 사용하여 bird eye view로 변환
- IPT는 캡쳐된 이미지의 투시 왜곡을 줄이고 더 넓은 영역의 배경을 제거하여 road marking이 더 두드려지게 만듦
- IPT는 관련 homography matirx인 M이 주어진 homography transformation
- 즉, 한 후 하는 계산 과정
- 모델
- BEV 이미지에서 road marking을 감지하기 위해 end-to-end object detector 모델이 사용됨
- MobileNet-v1 backbone을 사용하는 SSD와 Inception-v2 backbone을 사용하는 SSD의 성능 평가
- 500 x 500 해상도의 이미지가 입력됨
- bounding box로 road marking 감지 결과 출력
- 최종 단계에서 bounding box는 M의 역행렬을 사용하여 원래 이미지 도메인으로 변환됨
4.2 Instance Segmentation Approach
- instance segmentation의 목표는 객체 instance와 그 객체의 픽셀 단위 segmentation mask를 예측하는 것
- Mask R-CNN 네트워크 아키텍처를 inception-V2와 Resnet-50 두 가지 backbone과 함께 사용
- Mask R-CNN은 Faster R-CNN 아키텍처를 확장하여 각 ROI마다 bounding box와 segment mask 예측함
- instance segmentation 네트워크는 일반적으로 추론 속도가 낮기 때문에 추가 전처리 단계 없이 입력 이미지를 낮은 해상도인 500 x 500으로 resize한 후 모델에 직접 입력함
- 네트워크는 road marking에 대한 bounding box와 segmentation mask를 출력함
- 본 논문은 convex hull을 얻을 수 있는 segmentation mask만 평가
5. experiment
5.1 data augmentation
- 클래스 불균형 문제의 영향을 줄이기 위한 단계
- 훈련 중에 부족한 instance 수를 증가시키기 위해 간단한 data augmentation 방법을 사용
- 왼쪽 화살표, 직진-우회전 화살표 클래스가 오른쪽 화살표, 직진-좌회전 화살표 클래스에 비해 상대적으로 적은 instance를 가지고 있음
- 따라서 화살표가 포함된 이미지를 수평으로 뒤집어 (horizontally flip) 대칭된 표지판을 얻음
- 그러나 cycle lane, bus lane, slow road marking 클래스의 instance를 뒤집으면 의미를 잃기 때문에 이러한 instance를 포함한 이미지는 피함
- 또한 탐지 모델을 훈련하는 동안 이미지의 밝기, 채도, 대비, 색조를 무작위로 변경함
5.2 implementation details
- Intel Core i9-9900K CPU & Nvidia RTX-2080 Ti GPU
- TensorFlow로 모델 학습
- SSD-MoblieNet-v1 & SSD-Inception 모델
- RMSProp optimization : 초기 learning rate 0.004, momentum 0.9, batch size 24
- Mask-RCNN-Inception 모델
- momentum 포함한 SGD : 초기 lr 0.0001, momentum 0.9, batch size 4
- Mask-RCNN-ResNet50 모델
- momentum 포함한 SGD : 초기 lr 0.0003, momentum 0.9, batch size 2
6. Result
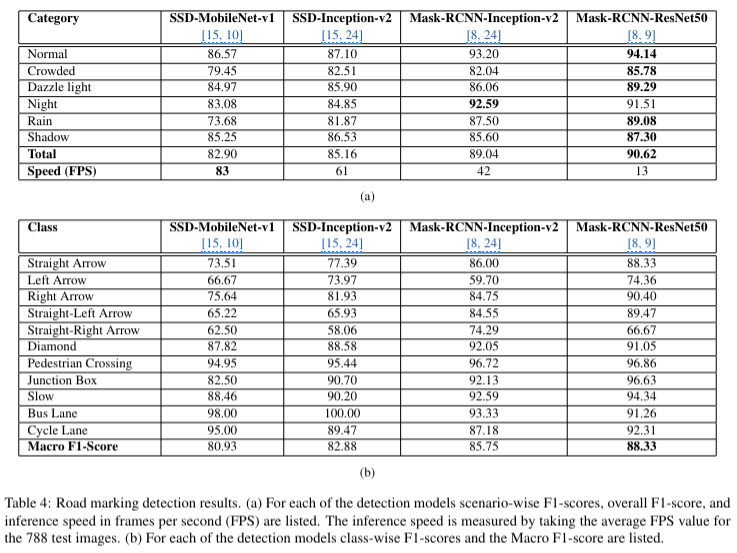
- 표 4a
- 각 모델의 F1 score, 추론 속도(FPS)
- instance segmentation 방식이 object detection 보다 더 나음
- Mask-RCNN-ResNet50 모델이 전체적으로 가장 높은 F1 score를 기록했지만 FPS가 가장 낮음
- Mask-RCNN-Inception-v2 모델을 정확도와 속도 사이의 균형 제공
- SSD 모델은 IPT와 함께 사용될 때 중간 정도의 정확도와 더 높은 추론 속도 보임
- 모든 모델이 normal에서 더 나은 성능을 보이고, 도전 시나리오에서는 F1 score가 비교적 낮음
- 표 4b
- macro F1 score
- 모든 모델의 macro F1 score가 전체 F1 score 보다 약 2%정도 낮다는 것을 알 수 있음 → 모델이 특정 클래스에서 더 잘 작동하는 경향이 있음을 의미
- dataset에서 자주 발견되고 도로의 큰 영역을 차지하는 횡단보도는 모든 모델에서 잘 감지됨
- slow, bus lane, cycle lane 클래스는 dataset에서 비교적 수가 적음 → 하지만 독특한 형태와 특징이 있기 때문에 잘 감지함
- 화살표의 경우 data augmentation을 통해 수를 증가시켰음에도 다른 sign에 비해 정확도가 낮음 → 화살표 클래스들 간의 유사성뿐만 아니라 도로 표면의 차선과도 유사성이 있기 때문일 수도 있음

- Mask R-CNN 모델이 특히 도전적인 시나리오에서 나은 성능을 보임
- segmentation mask는 객체 탐지 방법보다 road marking의 위치를 더 정밀하게 지정함
