0. Object Detection Intro
object classification
- 이미지의 object가 무엇인지
- classifier -> output : class_score[K, N]
- K : 예측 object의 수
- N : class의 수
- 마지막 layer의 구조 : [1, 1, class_num]
object localization
- 이미지에서 하나의 object가 무엇인지 + 어디에 있는지
- regressor -> output : [K + 4]
- 객체의 위치에 대한 정보(bounding box) 4개 추가
object detection
- 이미지에서의 여러 object가 무엇인지 + 어디에 있는지
- classifier -> output : class_score[K, N]
- regressor -> output : bounding box offset [K, 4]
- 마지막 layer의 구조 : [H, W, class_num + box_offset + confidence]
- flatten을 수행하지 않아서 위치 정보를 유지한다
1. Object Detection
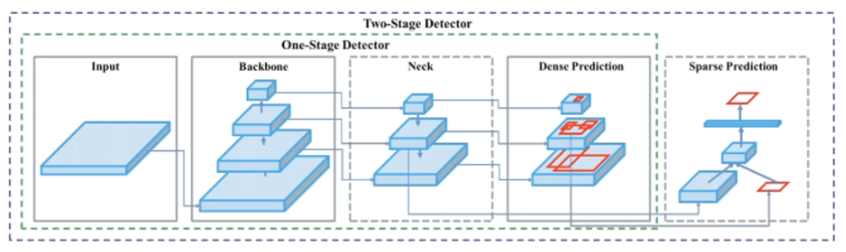
One stage detection
- SSD, YOLO
- 분기가 없다
- 속도가 빠르다
- 정확도가 떨어진다
architecture
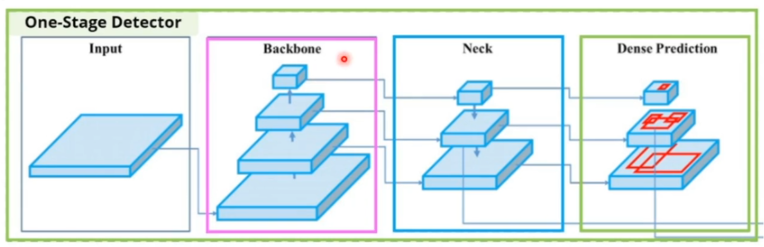
- backbone
- feature extractor
- 위로 갈수록(layer가 깊어질수록) 정보가 추상화된다
- neck
- 서로 다른 resolution feature map을 병합하고 정보를 섞는 과정
- feature pyramid 구조를 갖고 있다
- resolution을 동일하게(upsampling) 만든 후 concat 또는 add를 수행한다
- concat : width, height가 동일한 경우 channel을 붙인다
- add : channel까지 동일한 경우 element끼리 더한다
- dense prediction
- prediction score와 bounding box를 찾는다
- 여러개의 feature map에서 결과가 나온다
- regression layer
two stage detection
- 첫번째 단계에서 object의 위치를 찾는다
- Faster-RCNN
- 연산량이 많다
- 정확도가 높다
architecture
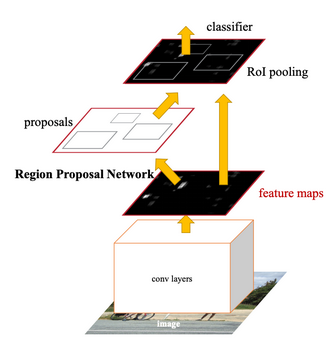
- 첫번째 forward
- CNN을 수행해서 나온 feature map에서 object가 예상되는 부분을 proposal하여 예상되는 object의 영역을 구한다
- 두번째 forward
- 후보 영역들 중에 object를 찾는다
2. object 검출 method
Grid
- 각 grid cell 안에서 object 검출
- gird는 feature map의 pixel 수를 의미
- 만약 feature map의 크기가 13x13 이면 gird 크기도 13x13
grid 안에서 object 찾는 방법
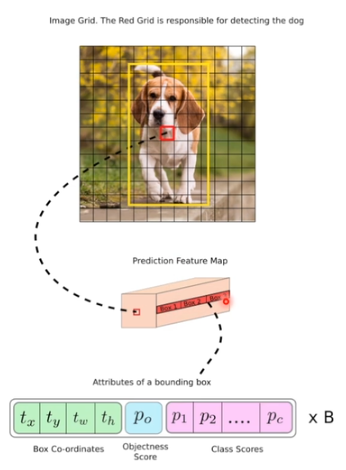
- 채널수 : box 수에 비례하게 생성
- 각 box의 channel 값
- box coordinates : box 정보를 담고있는 x, y, w, h 정보
- objectness score : 해당 grid에 object 존재 여부
- class score : class 별로의 확률값
- 한개의 grid안에는 3개의 box를 예측할 수 있다
Anchor
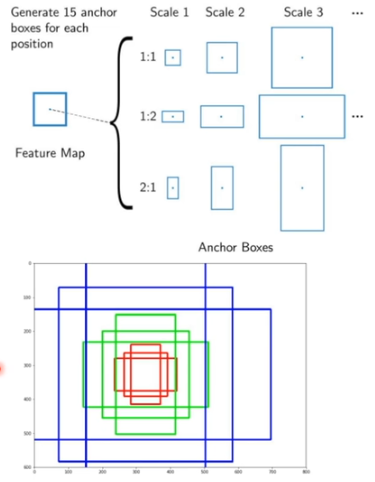
- 객체를 찾을 때 anchor를 이용
- 하나의 object에 하나의 anchor가 매칭된다
- bounding box shape를 미리 지정해 놓은 것
- grid안에 anchor가 3개 또는 5개씩 있고 이 anchor를 기반으로 bounding box를 예측
bounding box, objectness score, class score

- bounding box
- 객체의 위치
- x, y, w, h 또는 양끝의 x, y 좌표
- objectness score
- 해당하는 object가 있는지
- 0 또는 1의 값
- class score
- 어떤 object 인지
loss function
softmax
- 합산을 1로 만들어 준다
- 작은 값은 더 작게 해주고, 큰 값은 더 크게 해준다
cross entropy loss
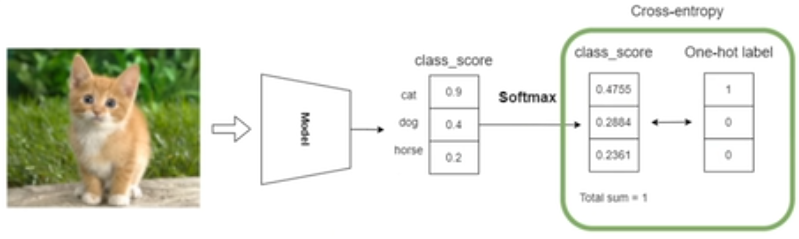
- 반응도
- positive를 잘 검출할수록 loss가 작아진다
MSE loss, MAE loss
- MSE : GT와의 오차 제곱의 평균
- MAE : 절대값 차이의 평균
IOU
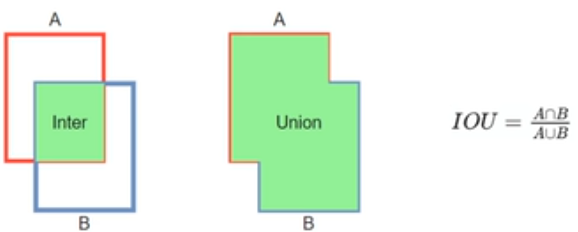
- Intersection over union
- GT와 예측한 bounding box를 비교
NMS
- Non maximun suppression
- 가장 잘 맞는 bounding box를 제외하고 제거한다
3. prepare data
data annotation
- GT data를 만드는 것 (bounding box, label)
- 하나의 이미지에는 하나의 GT 파일이 있다
- truncation : 이미지 밖으로 객체가 잘리는것
- occlusion : 객체가 가려진 것
dataset
- training set / evaluation set / test set
