
🤔 처음엔 그냥 간단하게 만들려고 했었는데,,,
저도 처음엔 "일단 빠르게 만들자!"라는 생각으로 UX 해적단 프로젝트를 시작했습니다. Express로 간단하게 API 서버 만들고, 데이터는 JSON 파일로 관리하고, 이미지는 무료 호스팅 사이트에 올려둬야징~ 했었죠,, 당연히 기획자/디자이너 분들도 그 정도면 충분하다고 하셨었습니다.
ux 해적단 프로젝트를 풀스택으로 개발하며 포스팅에도 작성했었지만, 처음에 정말 작게 시작한 프로젝트였고, 스터디 내용을 아카이빙 하는 것이 중심이었습니다.
그치만 서비스를 운영하다 보니까... 문제가 하나씩 보이기 시작했습니다.
초기 버전의 문제점들
- 📦 아티클이 30개만 넘어가도 초기 로딩이 너무 느림 (전체 데이터를 한 번에 가져오니까)
- 🖼️ 이미지 로딩 속도가 들쭉날쭉 (외부 호스팅 사이트 의존)
- 😅 이미지 호스팅 사이트의 오류로 인한 우리 사이트 오류 발생
- 🔍 필터링, 검색, 정렬 기능을 추가하고 싶은데 JSON으로는 한계
- 🚨 동시에 여러 요청이 오면 데이터 손실 위험
특히 관리자 페이지에서 아티클을 추가하는데, 가끔 저장이 안 되는 일이 발생했습니다. 알고 보니 JSON 파일 쓰기 작업이 겹쳐서 생긴 문제였습니다...
그래서 결국 "이거 제대로 뜯어고쳐야겠다"는 결론에 도달했습니다.
🎯 리팩토링 목표 세우기
리팩토링을 시작하기 전에, 명확한 목표를 정했습니다:
| 목표 | 기존 방식 | 개선 방향 |
|---|---|---|
| 성능 | 전체 데이터 로딩 → 느림 | 페이지네이션, 필터링 |
| 안정성 | JSON 파일 → 동시성 문제 | DB 사용 |
| 이미지 | 외부 호스팅 → 속도 불안정 | S3 + CloudFront |
| 확장성 | Express → 구조 없음 | NestJS 모듈화 |
| 타입 안정성 | JavaScript → 런타임 에러 | TypeScript 전면 도입 |
🔄 단계별 리팩토링 과정
1단계: Express → NestJS 마이그레이션
처음에는 "그냥 Express에서 TypeScript만 쓸까?" 싶었는데, 프로젝트 구조를 고민하다 보니 NestJS를 쓰게 되었습니다.
회사 인턴 하면서 확장성 등을 위해 NestJS를 express 대신 도입했던 적이 있었는데, 처음 배울 때에는 데코레이터 등의 개념이 어려웠지만, 사용하다보니 익숙해지고 조금씩 이해가 되었던 상태였기에 조금 더 멀리 보고 기왕 할 거 nest로 제대로 리팩하기로 하였습니다.
(사실 중간에 생각보다 일이 커져서 좀 후회함..... 그치만 배포까지 완료한 지금은 너무 만족합니다 ㅎ)
NestJS를 선택한 이유
// Before: Express (구조 없음)
app.get('/api/articles', (req, res) => {
const articles = JSON.parse(fs.readFileSync('articles.json'));
res.json(articles);
});
// After: NestJS (모듈화, DI, 타입 안정성)
@Controller('articles')
export class ArticlesController {
constructor(private readonly articlesService: ArticlesService) {}
@Get()
async getArticles(@Query() filters: ArticleFilterOptions) {
return this.articlesService.getArticlesWithFilters(filters);
}
}
NestJS를 도입하면서 좋았던 점:
- 의존성 주입(DI): 서비스 간 의존 관계를 명확하게 관리
- 모듈 시스템: 기능별로 깔끔하게 분리
- Swagger 자동 생성: API 문서 작성 시간 절약
- 데코레이터 기반: 코드가 훨씬 읽기 쉬워짐
2단계: JSON → Supabase 데이터 마이그레이션
이게 제일 큰 작업일 거라고 생각했는데, 처음 설계할 때 확장성을 고려해뒀던 게 여기서 빛을 발했습니다. JSON을 사용하긴 했었지만 정말 erd처럼 구현해뒀었기에, 큰 문제가 없었던 것 같습니다.
기존 JSON 구조 (example)
{
"articles": [
{
"id": "article_001",
"title": "...",
"keywordId": "keyword_001",
"productId": "product_001",
"authorId": "author_001",
"images": [...]
}
],
"keywords": [...],
"products": [...],
"authors": [...]
}
Supabase DB 스키마 설계
실제 저희 서비스의 db를 공개할 수는 없기에, 대략적으로 예시 ERD를 만들어보았습니다.
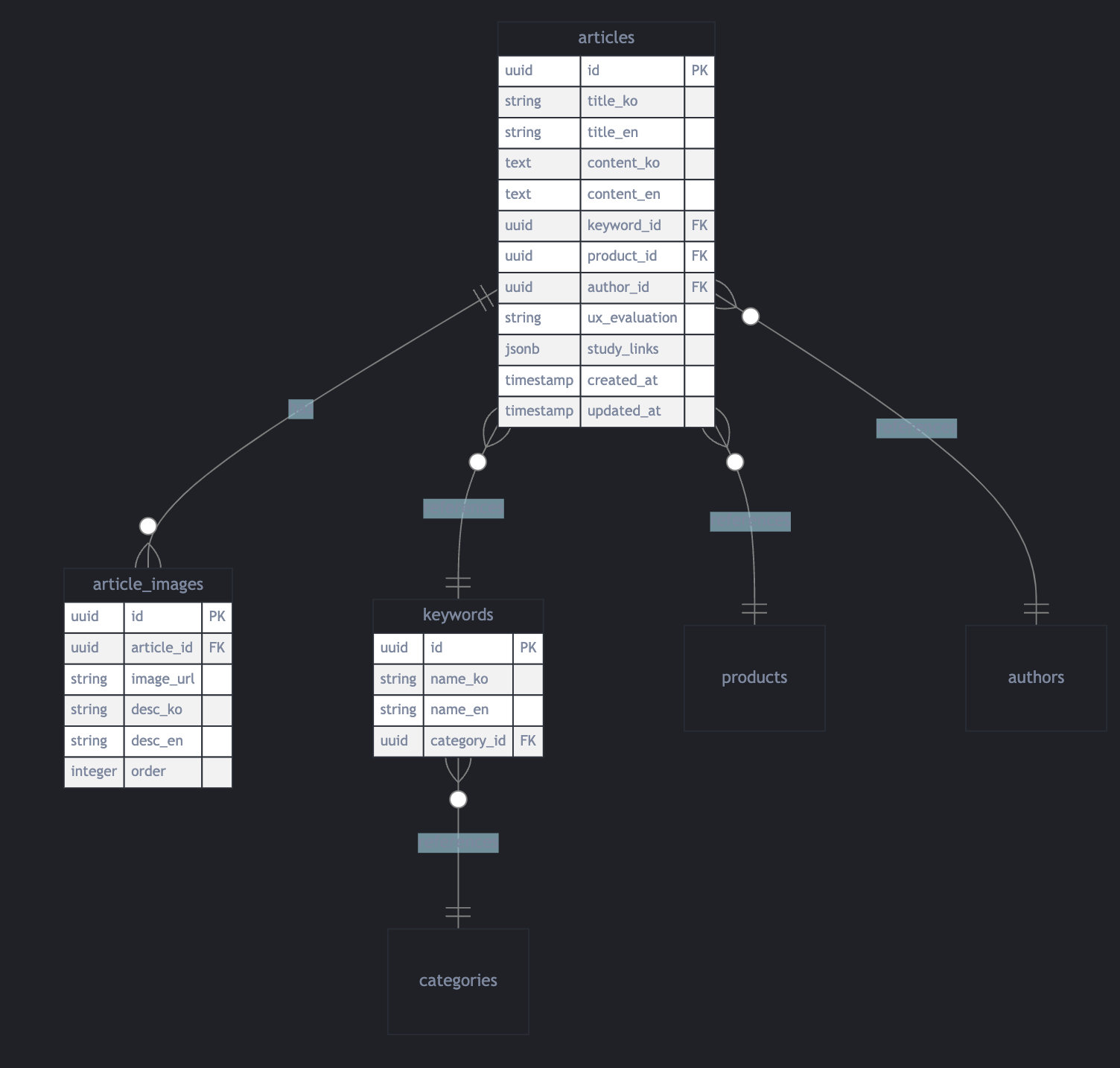
Supabase 서비스 구현
// backend/src/supabase/supabase.service.ts
@Injectable()
export class SupabaseService {
private supabase: SupabaseClient;
constructor(private configService: ConfigService) {
const supabaseUrl = this.configService.get<string>('SUPABASE_URL');
const supabaseKey = this.configService.get<string>('SUPABASE_ANON_KEY');
this.supabase = createClient(supabaseUrl, supabaseKey);
}
async getArticlesWithFilters(filters: {
keywordId?: string;
productId?: string;
page?: number;
limit?: number;
sortBy?: string;
sortOrder?: 'asc' | 'desc';
}) {
let query = this.supabase.from('articles').select(`
*,
authors (*),
products (*),
keywords (
*,
categories (*)
),
article_images (*)
`, { count: 'exact' });
// 필터 적용
if (filters.keywordId) {
query = query.eq('keyword_id', filters.keywordId);
}
// 정렬
const sortBy = filters.sortBy || 'created_at';
const sortOrder = filters.sortOrder || 'desc';
query = query.order(sortBy, { ascending: sortOrder === 'asc' });
// 페이지네이션
if (filters.page && filters.limit) {
const from = (filters.page - 1) * filters.limit;
const to = from + filters.limit - 1;
query = query.range(from, to);
}
const { data, error, count } = await query;
if (error) throw error;
return { data: data || [], total: count || 0 };
}
}
이렇게 바뀌니까 좋았던 점
| 기능 | JSON 파일 시절 | Supabase 도입 후 |
|---|---|---|
| 페이지네이션 | ❌ 전체 로딩 후 프론트에서 처리 | ✅ DB에서 필요한 만큼만 |
| 필터링 | ❌ 전체 데이터에서 필터링 | ✅ 쿼리로 바로 필터링 |
| 검색 | ❌ 비효율적 | ✅ 연산으로 빠르게 |
| 동시성 | ❌ 파일 잠금 문제 | ✅ 트랜잭션 처리 |
| 관계 쿼리 | ❌ 여러 번 조회 필요 | ✅ JOIN으로 한 번에 |
3단계: 이미지 호스팅 → AWS S3 + CloudFront
사실 이걸 위해 전체 리팩토링이 진행된 것과 다름 없었습니다. 무료 호스팅 사이트를 쓰다 보니 가끔 이미지가 안 뜨거나, 로딩이 엄청 느린 경우가 있었거든요.
실제 QA에 첨부해주신 이미지인데, 이런 식으로 이미지 자체가 로드되지 않는 경우가 꽤 있었습니다.
S3 서비스 구현
뭐 s3와 연동하는 건 크게 어렵지 않으니 참고 용으로만 코드를 남겨두겠습니다.
이런 식으로 S3와 연동할 수 있게 해주었고, 관리자 페이지에서 업로드하는 이미지를 S3에 저장해두도록 하였습니다.
@Injectable()
export class S3Service {
private s3: AWS.S3;
private bucketName: string;
private cloudfrontDomain: string;
constructor(private configService: ConfigService) {
AWS.config.update({
accessKeyId: this.configService.get('AWS_ACCESS_KEY_ID'),
secretAccessKey: this.configService.get('AWS_SECRET_ACCESS_KEY'),
region: this.configService.get('AWS_REGION'),
});
...
}
async uploadFile(file: any, key: string): Promise<string> {
...
}
generateImageKey(originalName: string): string {
...
}
}
CloudFront로 전세계 빠른 이미지 전송
사실 이렇게 저장한 S3 데이터를 supabase의 db와 연동하는 것만으로도 충분하긴 했지만, 저희 서비스가 이미 외국에서도 많은 접속량을 받아오고 있었고, 디자이너 분도 해외 취업 등에 관심이 있었기에 외국 타겟팅도 해보고 싶었습니다.
S3만 쓰면 한국에서는 빠른데, 다른 나라에서 접속하면 느릴 수 있다는 것을 알게 되었고, 그래서 CloudFront를 앞단에 두고, CDN으로 이미지를 캐싱하도록 했습니다.
(사실 CloudFront를 도입한 가장 큰 이유는 제가 aws의 새로운 서비스를 사용해보고 싶었습니다,,ㅎ)
사용자 요청
↓
CloudFront (가장 가까운 엣지 서버)
↓ (캐시 없으면)
S3 버킷
4단계: API 구조 개선
이후 api를 개선하였는데, 원래는 그냥 데이터를 받아오고, 보내는 정도의 역할만 해주었다면,
이제 페이지네이션, 필터링, 정렬을 모두 API 레벨에서 처리할 수 있도록 하였습니다.
아주 조금이지만 보안도 조금 더 신경써보았구요,,,,ㅎ,,,,
개선된 API 예시
// 기본 조회
GET /api/articles?page=1&limit=10
// 키워드로 필터링
GET /api/articles?keywordId=keyword_001&page=1&limit=10
// 정렬
GET /api/articles?sortBy=created_at&sortOrder=desc
// 복합 필터
GET /api/articles?keywordId=keyword_001&uxEvaluation=Good UX&page=1&limit=10&sortBy=created_at
응답 형식
{
"articles": [...],
"total": 156,
"page": 1,
"limit": 10,
"totalPages": 16,
"hasMore": true
}
이렇게 백엔드에 좀 더 힘을 주니 확실히 프론트에서 처리해야 하는 처리량이 줄어들었습니다.
📊 리팩토링 전후 비교
성능 개선
| 측정 항목 | Before | After | 개선율 |
|---|---|---|---|
| 초기 로딩 시간 | ~3.2초 | ~0.4초 | 87.5% ↓ |
| 이미지 로딩 시간 | ~2.1초 | ~0.3초 | 85.7% ↓ |
| API 응답 시간 | ~800ms | ~120ms | 85% ↓ |
| 메모리 사용량 | ~200MB | ~80MB | 60% ↓ |
사실 리팩토링을 단계별로 진행해서, 리팩토링 완전 전과 후의 성능을 비교하기에는 무리가 있습니다만,,, 확실한 건 유저 분들이 느끼기에도 속도가 많이 개선되었다고 하더라구요. (물론 FE도 함께 리팩했기 때문)
일단 호스팅 사이트를 사용하지 않기 때문에 호스팅 사이트로 인한 오류가 발생하지 않는다는 것, 그리고 자체 db를 구축해서 빠르게 쿼리할 수 있다는 점 등등... 리팩토링 하기를 당연히 너무 잘 한 것 같습니다.
뭐 예를 들자면,, 이런 식으로 프론트에서 처리하던 걸 서버에서 처리해서 보여주는 형식이 된 거죠. (before 코드가 진짜 말이 안되는 건 알지만, 이 플젝은 진짜 정말 토이 프로젝트로 백엔드에 크게 힘을 주지 않으려고 했기 때문에 이렇게 구현해뒀습니다... 이제서야 정상화된 느낌...... 변명하는 거 맞음)
// Before: 전체 데이터를 가져와서 프론트에서 처리
const allArticles = await fetch('/api/articles'); // 200개 전부
const filtered = allArticles.filter(...); // 클라이언트에서 필터링
const sorted = filtered.sort(...); // 클라이언트에서 정렬
const paginated = sorted.slice(0, 10); // 클라이언트에서 페이지네이션
// After: 서버에서 필요한 것만 가져오기
const { articles } = await fetch(
'/api/articles?keywordId=keyword_001&page=1&limit=10&sortBy=created_at&sortOrder=desc'
); // 딱 10개만!
리팩토링하며..
1. 초기 설계의 중요성
처음 JSON 구조를 설계할 때 "나중에 DB로 옮길 수도 있으니까 ID 기반으로 관계를 맺어두자"라고 생각한 게 정말 큰 도움이 되었습니다.
만약 처음부터 이렇게 설계했다면?
{
"articles": [
{
"id": "article_001",
"keyword": { "name": "..." }, // 객체 안에 바로 데이터
"product": { "name": "..." }
}
]
}
이랬으면 DB 마이그레이션이 훨~~~씬 복잡했을 겁니다.
2. 타입 시스템의 위력
NestJS + TypeScript를 쓰면서 런타임 에러가 확 줄었습니다.
// 타입 정의
interface ArticleFilterOptions {
keywordId?: string;
productId?: string;
page?: number;
limit?: number;
sortBy?: string;
sortOrder?: 'asc' | 'desc';
}
// 이제 이런 실수는 컴파일 단계에서 잡힘
const filters = {
sortOrder: 'descending' // ❌ 타입 에러!
};
사실 리팩토링을 통해 얻게 된 이점이 너무 많아서 다 나열하기는 힘들 것 같습니다. 직접 사용해본 유저 분들이 확실하게 이 이점을 느끼신다는 것만으로도 충분하지 않을까 싶어요,,,
처음에는 "빠르게 만들자!"라는 생각으로 시작했지만, 결국 제대로 된 구조로 리팩토링하게 되었습니다. 시간은 좀 걸렸지만, 유저 분들의 긍정적인 피드백이 있었다는 이야기를 들으니 기분은 좋더라고요.ㅎ

특히 "확장 가능한 구조로 처음부터 설계하는 것"의 중요성을 다시 한 번 체감했습니다.
다음 포스팅에서는 FE 리팩토링 작업 내용을 작성해보겠습니다!!
+ 빨라졌다는 사용자의 피드백
저희 사이트에 관심이 많은 분들이 꽤 계신다는 이야기를 들었습니다,,, 이전에 포스팅했던 것처럼 X에서 인기가 꽤 많았던 건 알고 있었는데, 이번 리팩토링 이후 디자이너 분이 이런 연락을 받았다고 하더라구요. ㅎ 덤덤한 척 했지만 괜히 기분 좋음

📌 참고
