혼공머신 5주차
- Chapter 6) 비지도 학습
6-1 군집 알고리즘
문제 : 타깃을 모르는 사진을 종류별로 분류하기
- 비지도학습 : 타깃이 없을 때 사용하는 머신러닝 알고리즘
- 군집 : 비슷한 샘플끼리 그룹으로 모으는 작업
- 클러스터 : 군집 알고리즘에서 만든 그룹
1) 데이터 준비하기 : 사과, 바나나, 파인애플 각 100개 샘플
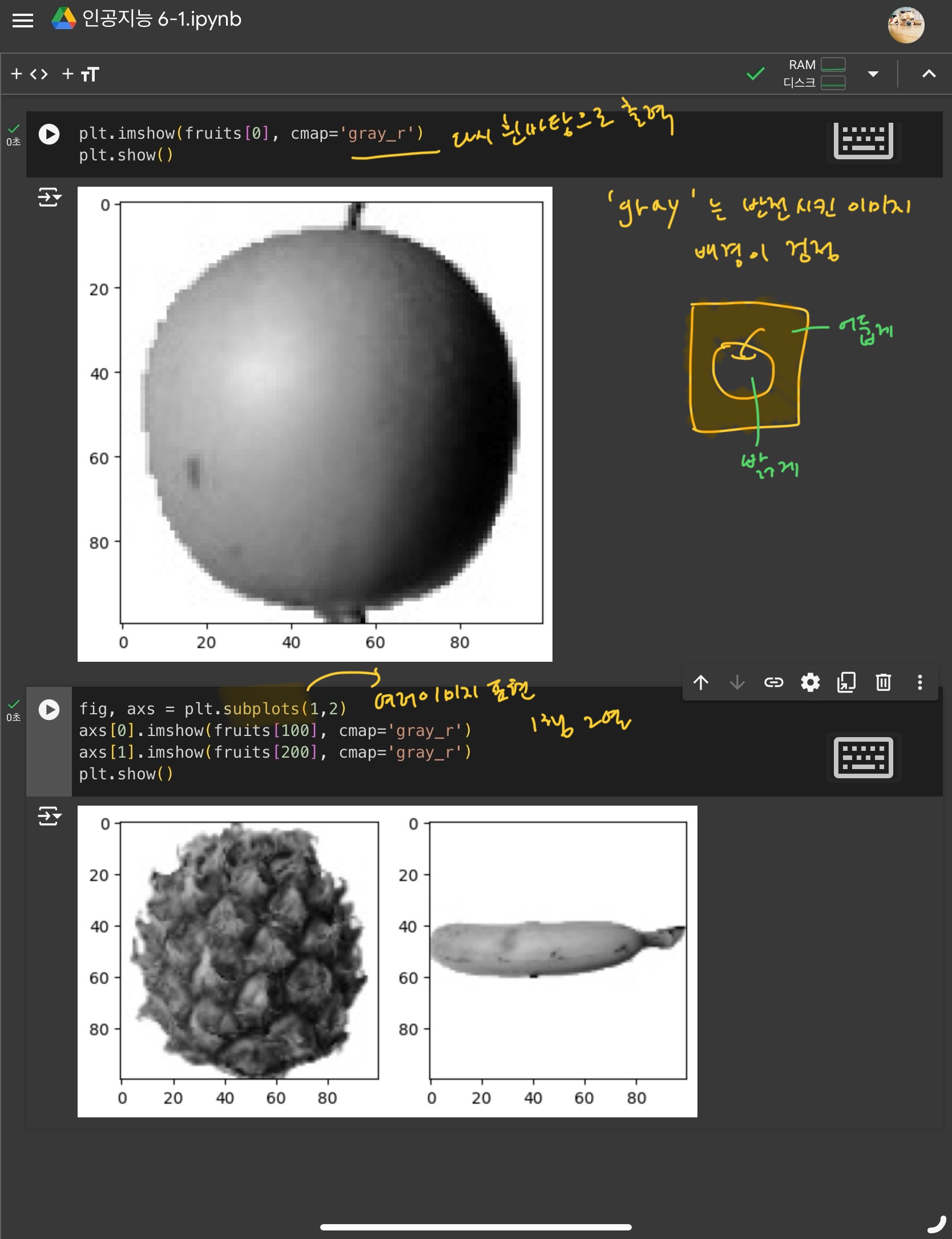
2) 픽셀값 분석하기
과일의 픽셀을 분석하여 구분해보기
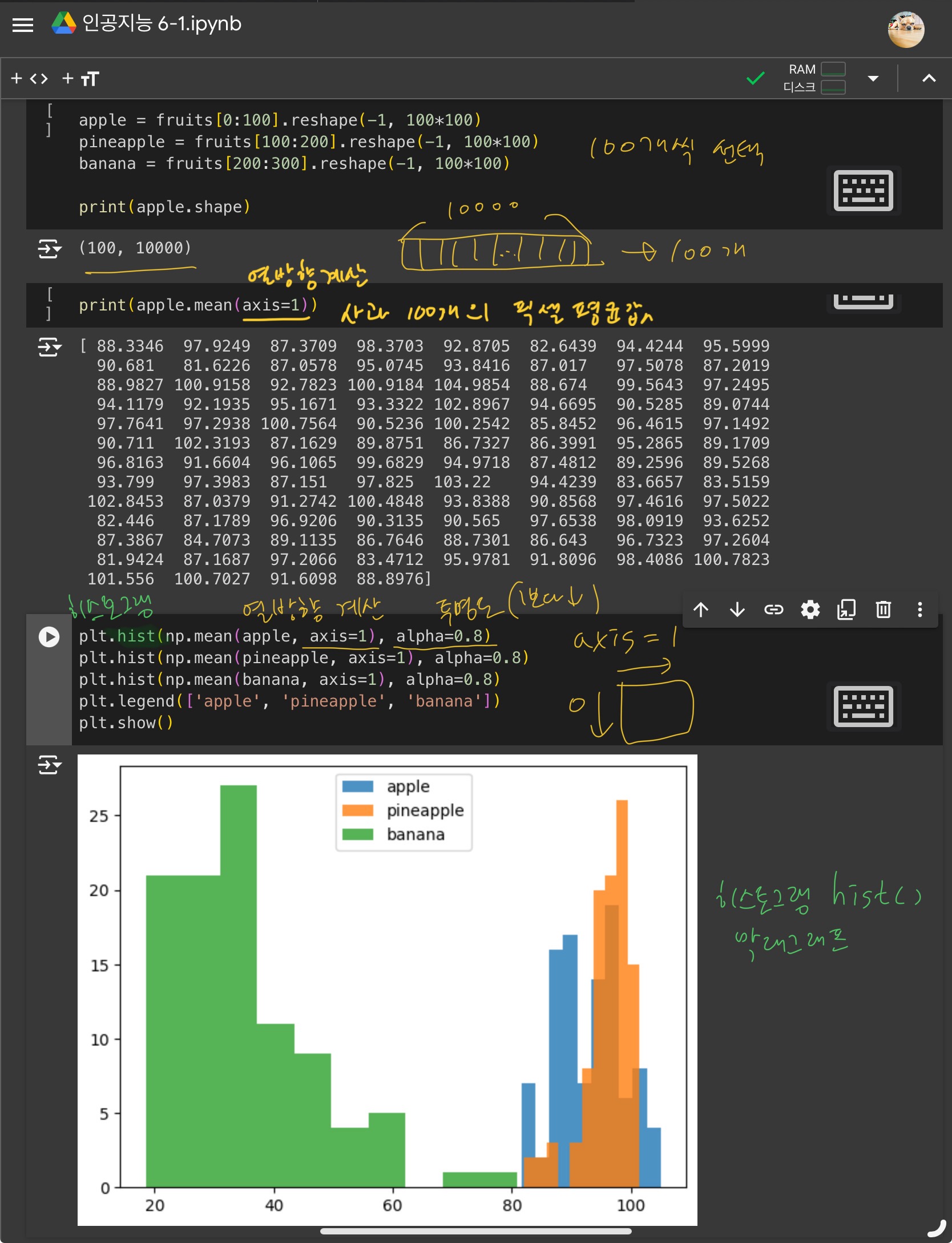
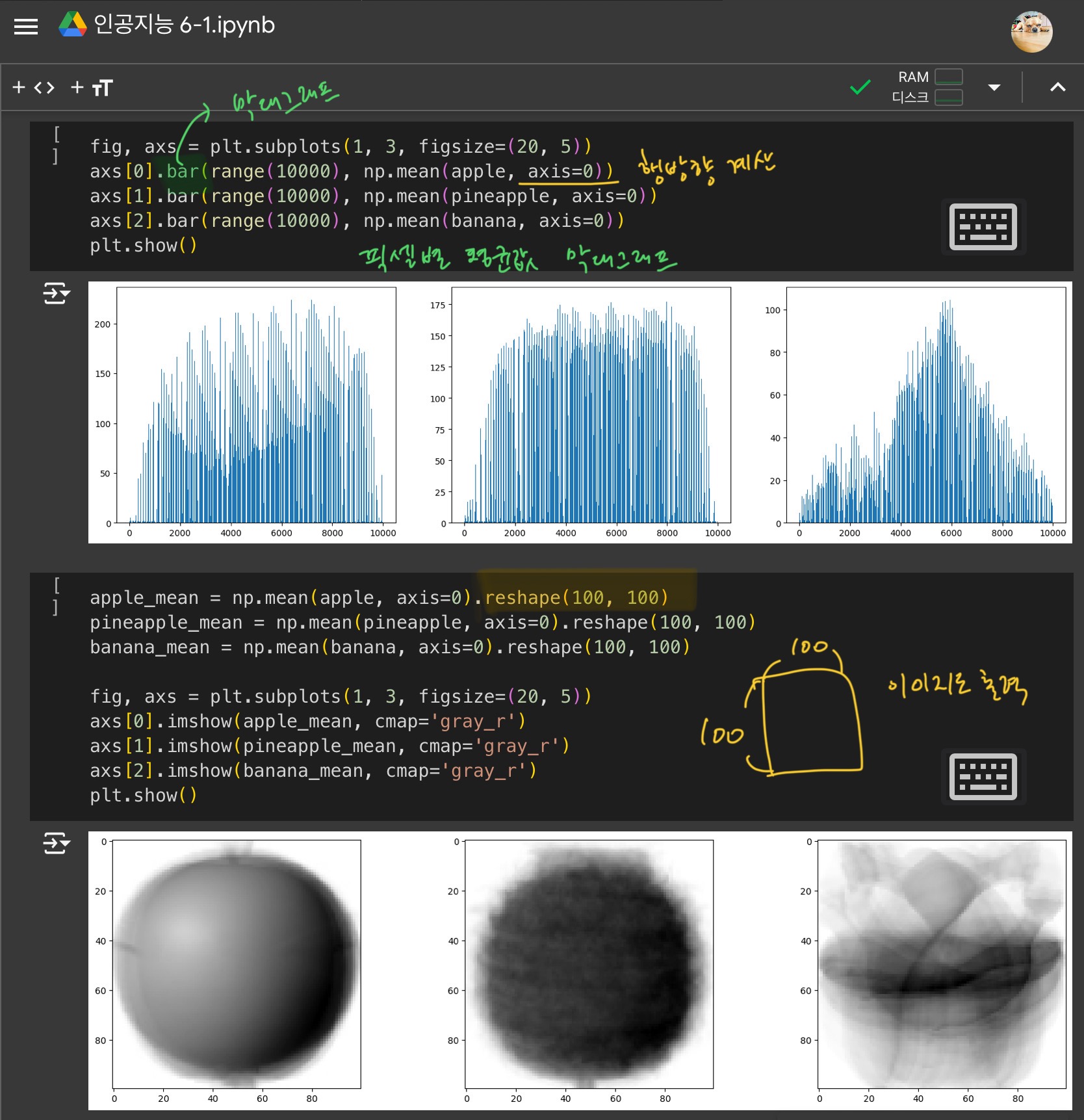
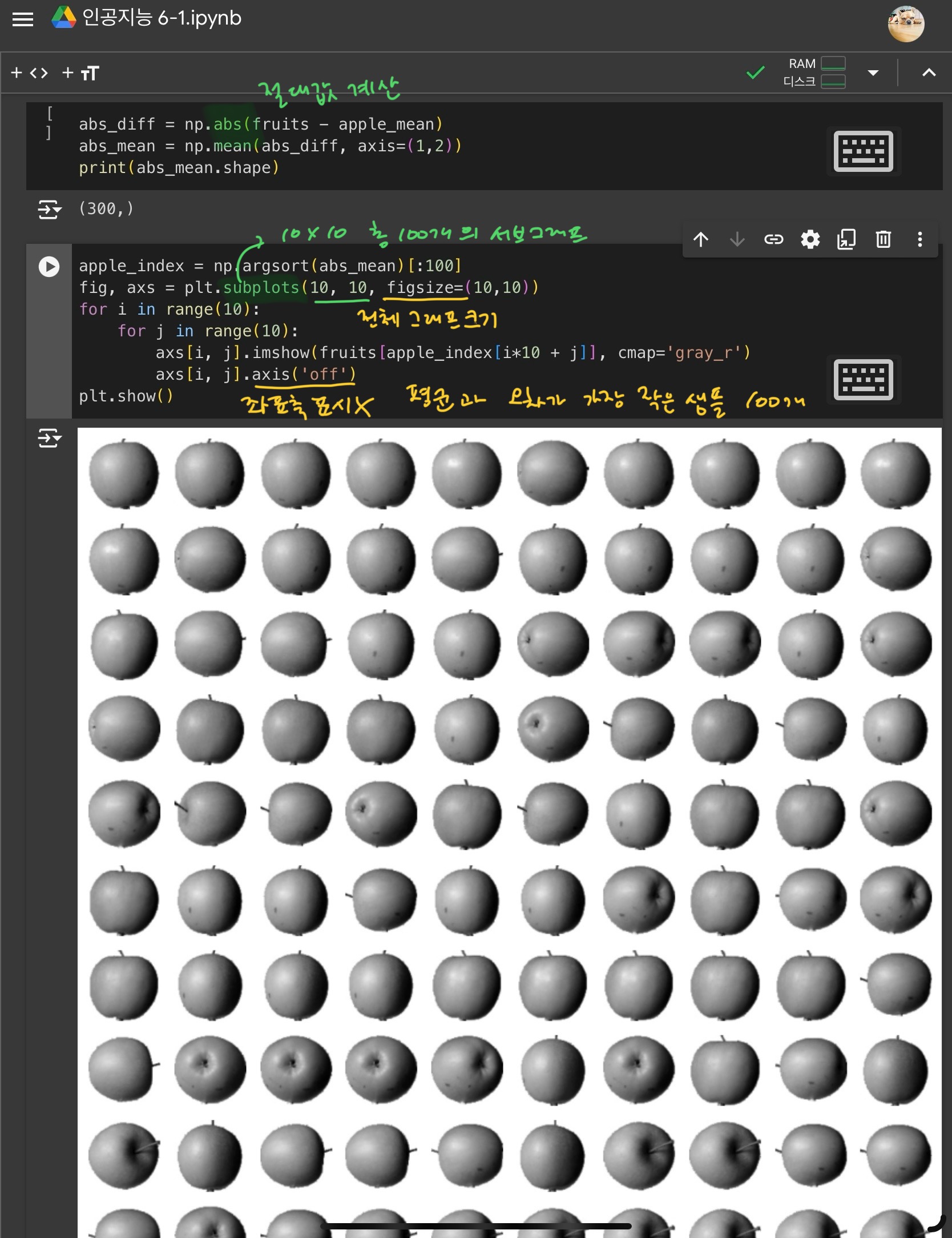
3) 평균값과 가까운 사진 고르기
절대값을 이용하여, 평균값과 가까운 사진을 고른다.
6-2 k-평균
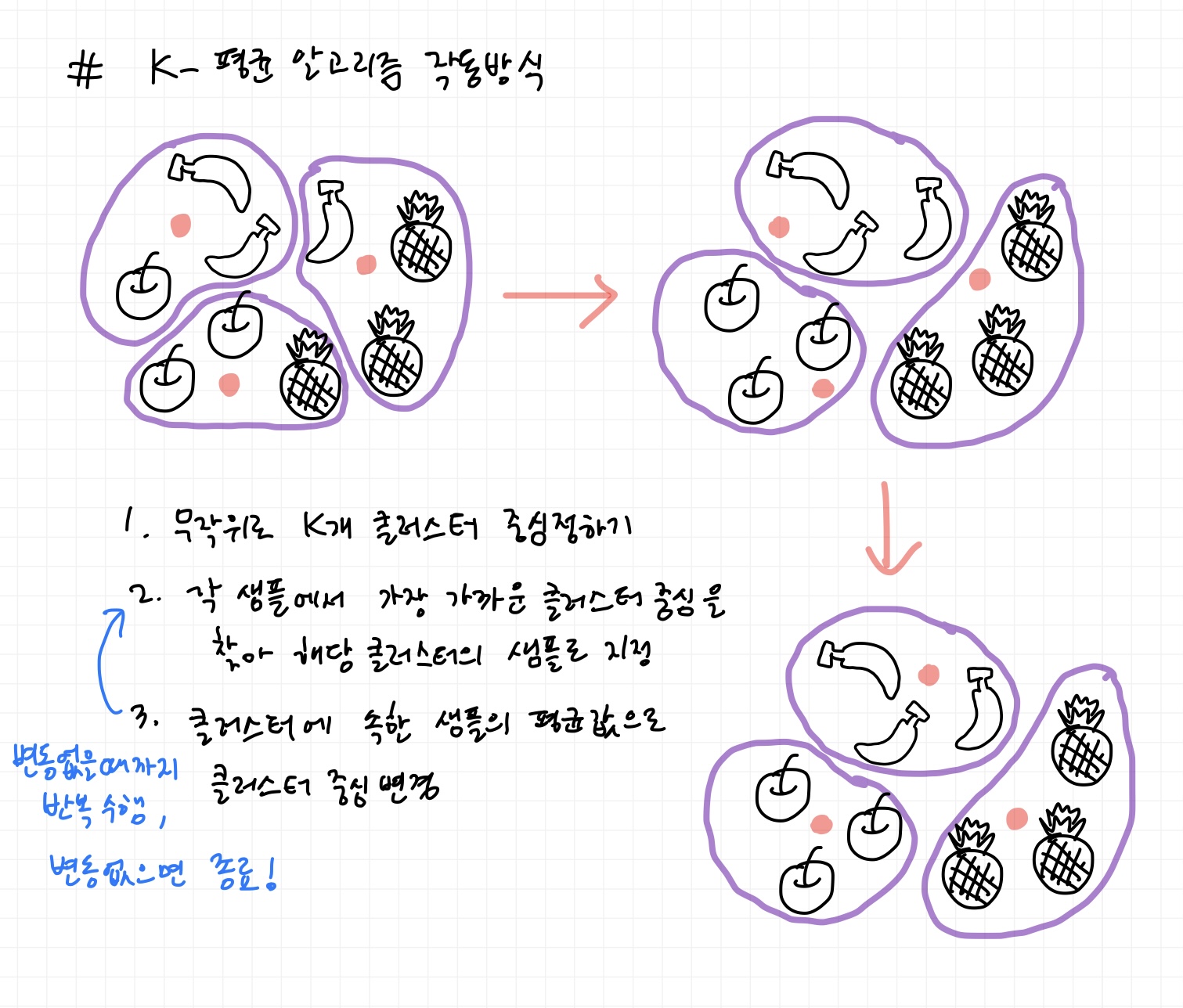
1) k-평균 알고리즘
- k-평균 알고리즘 : 평균값을 자동으로 찾아주는 알고리즘으로, 최적의 클러스터를 구성하는 알고리즘
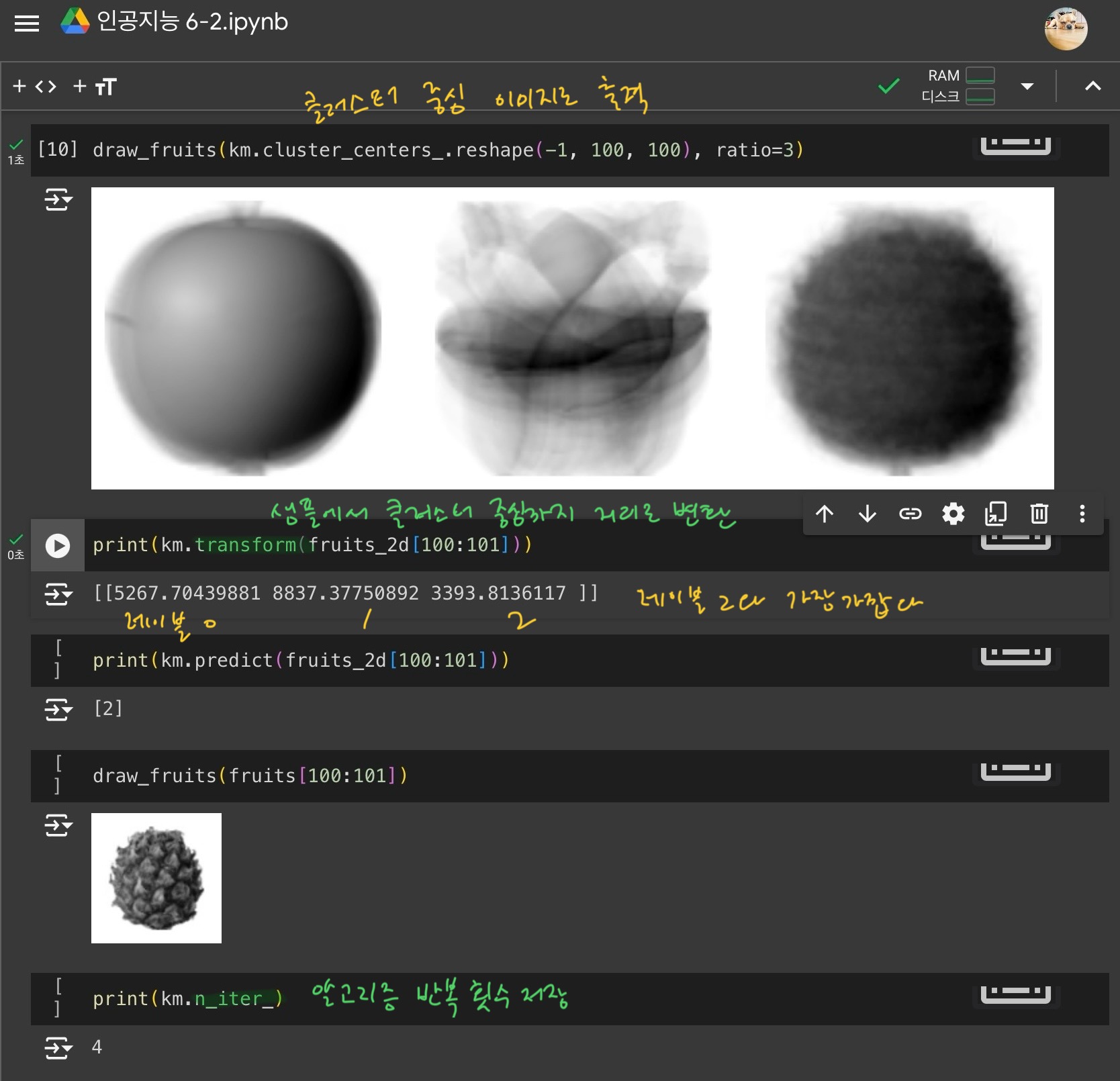
- 클러스터 중심(센트로이드) : k-평균 알고리즘이 만든 클러스터에 속한 샘플의 특성 평균값
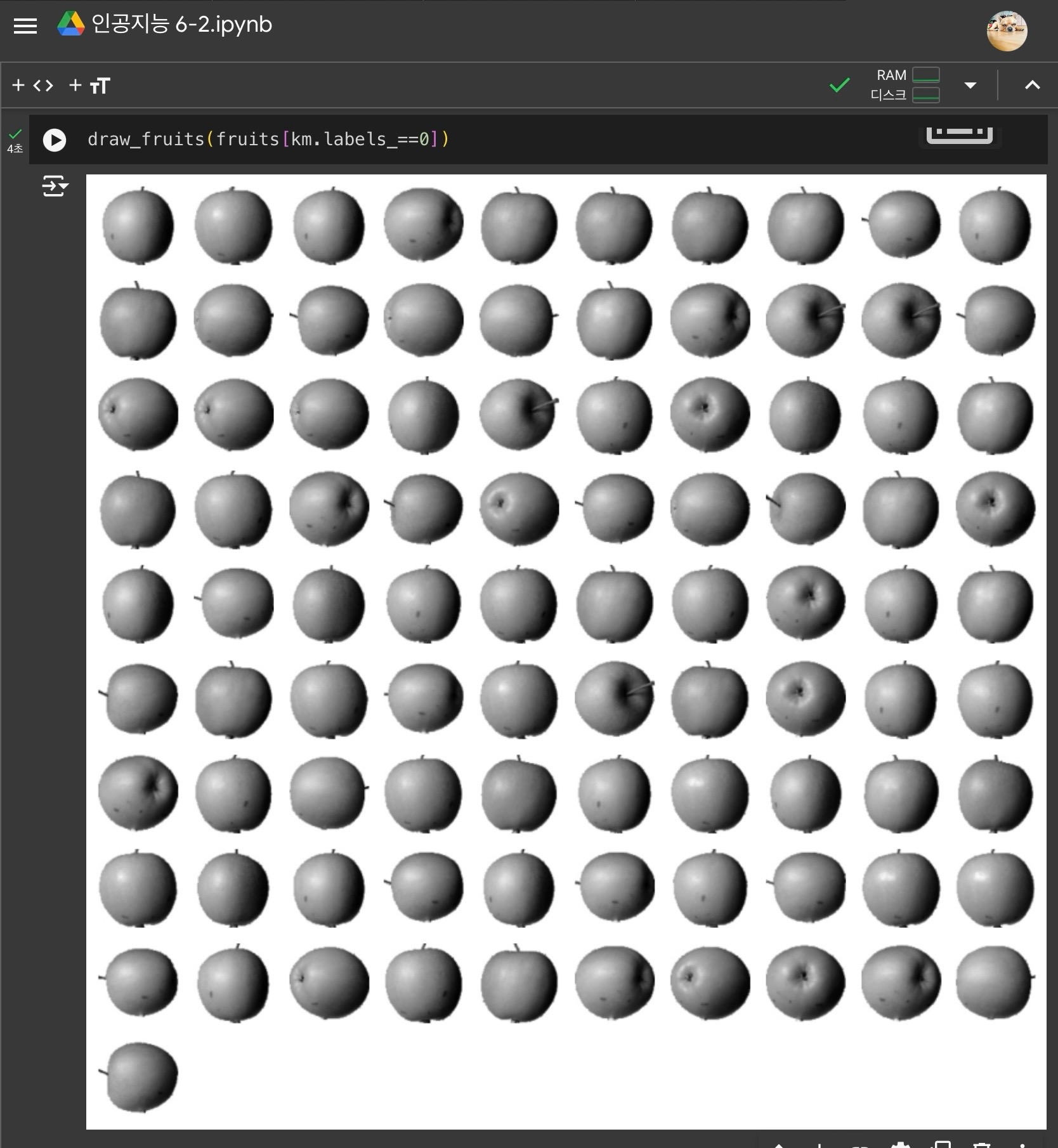
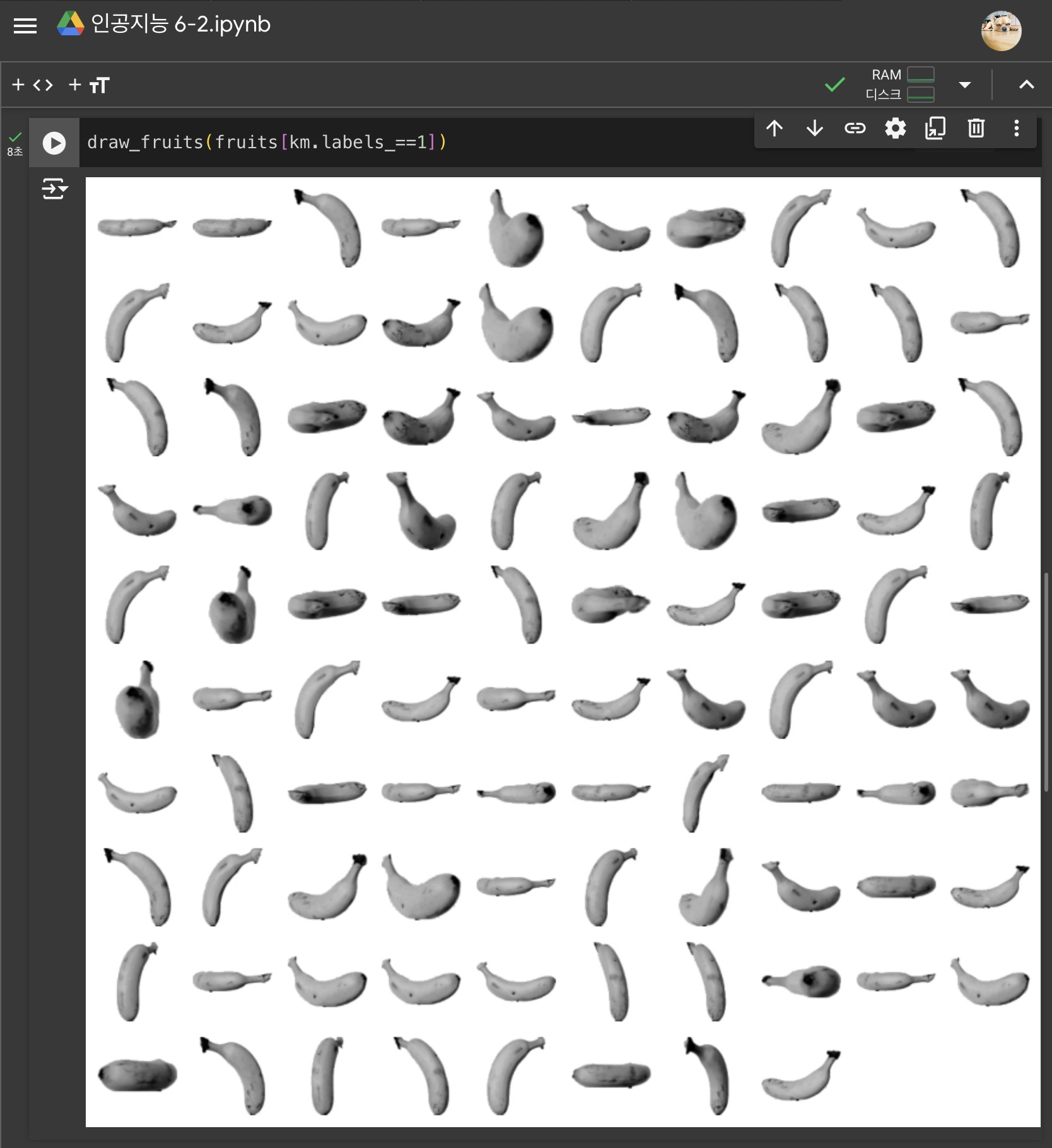
2) KMeans 클래스
k-평균 알고리즘을 구현해주는 클래스
- labels_속성 : 어떤 클러스터에 속하는지 군집결과를 저장

3) 클러스터 중심
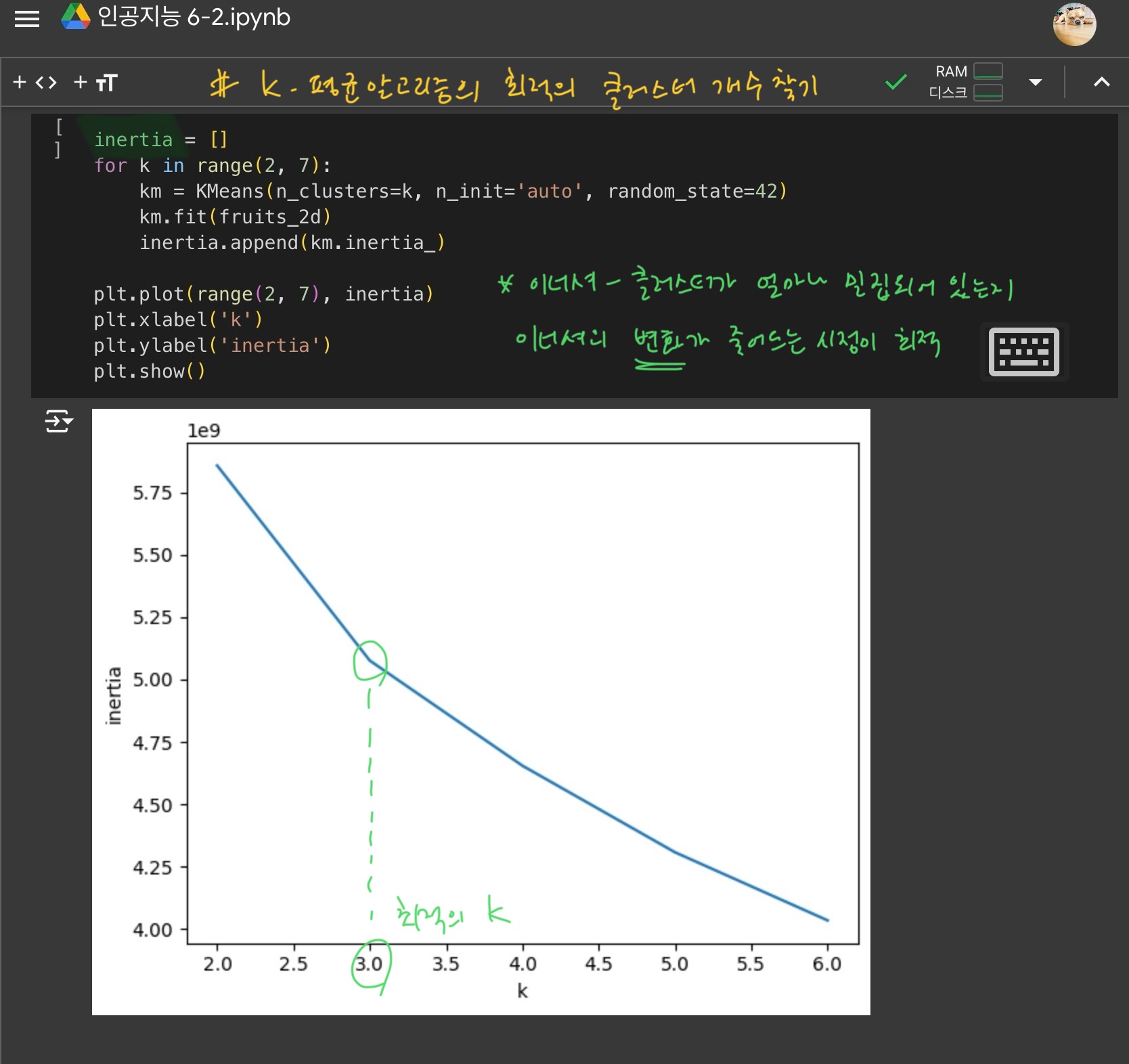
4) 최적의 k 찾기
k-평균 알고리즘은 사전에 클러스터 개수를 지정해야한다.
- 이너셔 : 클러스터가 얼마나 밀집되어 있는지 나타낸다.
- 엘보우방법 : 군집 알고리즘에서 적절한 k값을 찾기 위한 방법으로, 그래프가 꺾이는 지점(이너셔의 변화가 줄어드는 지점)이 최적의 k값이 된다.
6-3 주성분 분석
문제 : 업로드 되는 과일 사진들이 너무 많아서 디스크 공간이 부족!
-> 군집에 영향을 주지 않으면서 사진의 용량 줄이기
1) 차원과 차원 축소
- 차원 : 데이터가 가진 속성을 특성이라 하며, 이런 특성을 차원이라고도 부른다.
- 차원축소 : 원본 데이터의 특성을 적은 수의 새로운 특성으로 변환하는 비지도 학습의 한 종류
-> 저장 공간을 줄이고, 시각화 하기 쉽다. (성능향상)
2) 주성분 분석
- 주성분 분석(PCA) : 대표적인 차원 축소 알고리즘으로, 하나의 데이터에서 가장 분산이 큰 방향을 찾는 방법
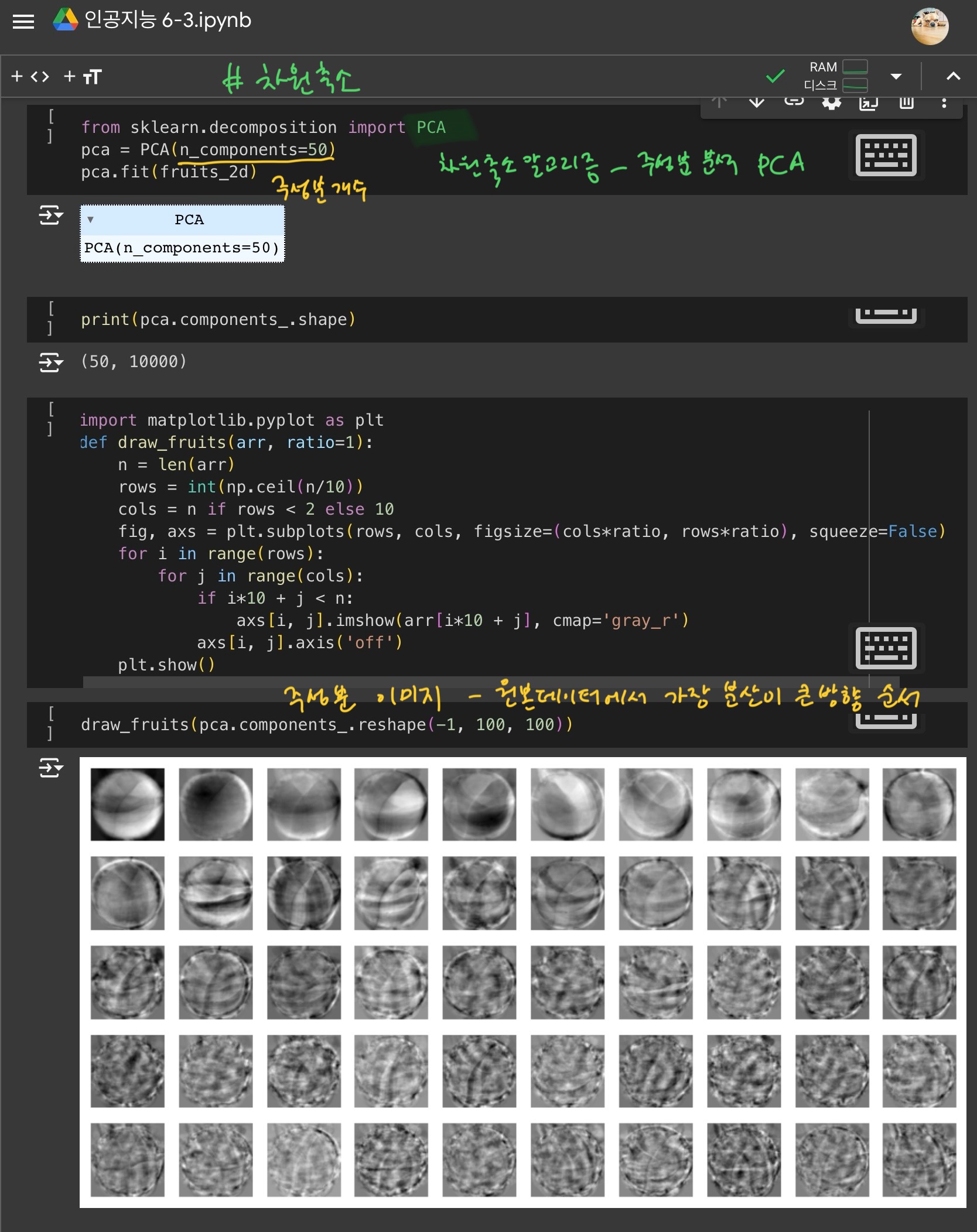
10000개의 특성을 50개로 변환하고, 다시 복원하기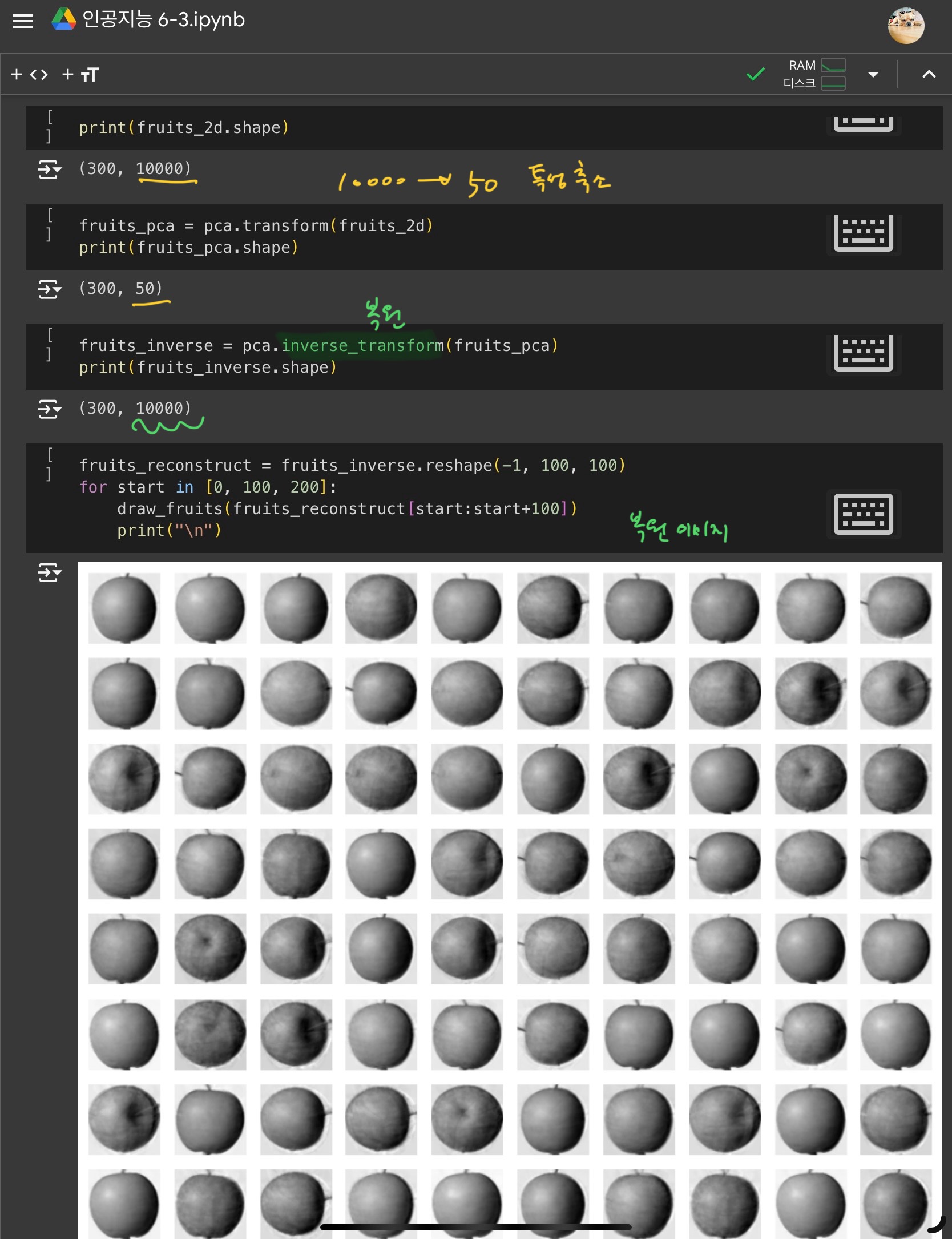
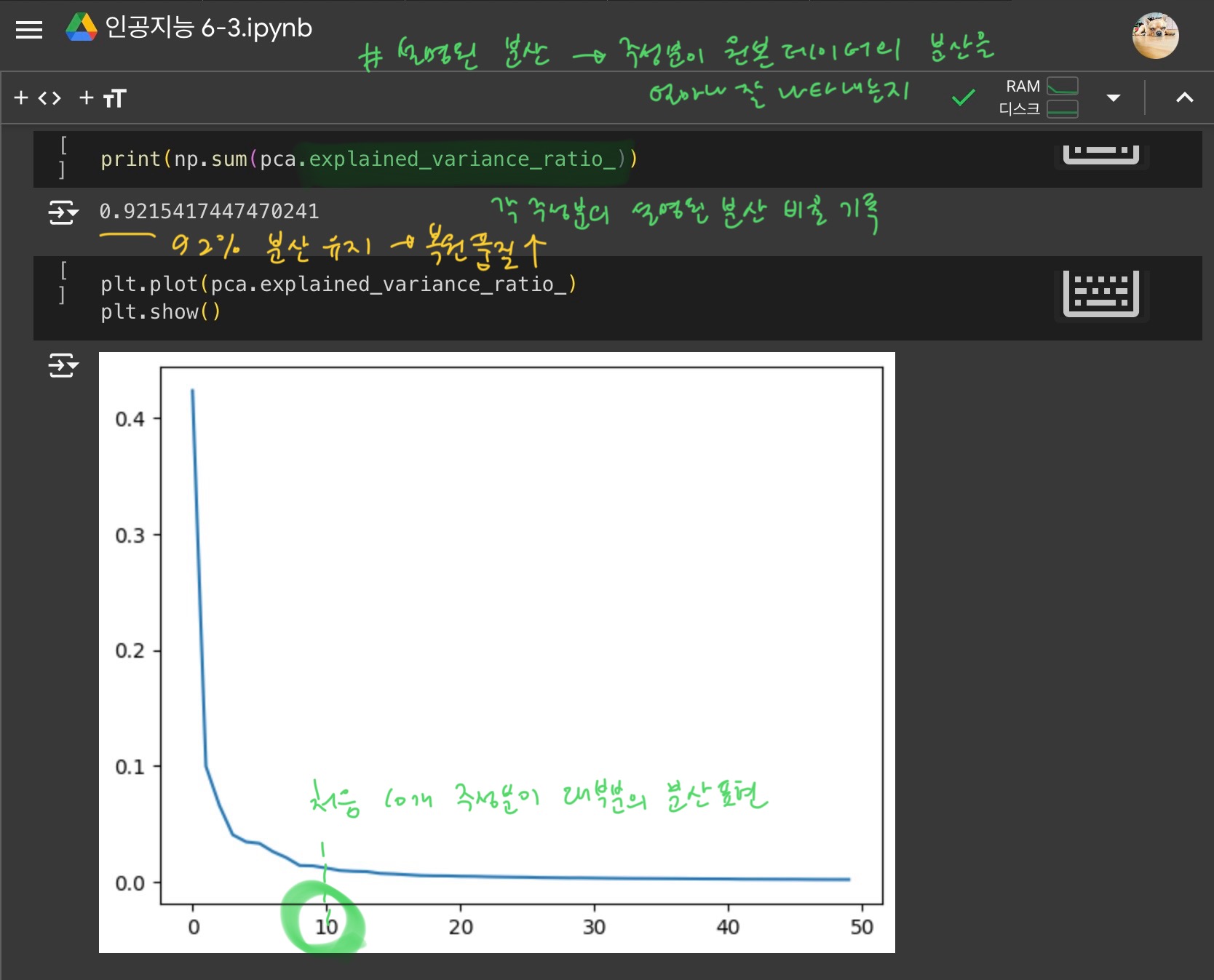
3) 설명된 분산
- 설명된 분산 : 주성분이 원본 데이터의 분산을 얼마나 잘 나타내는지 기록한 값
5주차 학습일기
머신러닝의 기본파트가 끝이 났다!!
벌써 책 절반을 공부했다니, 너무너무 뿌듯하다.
완벽하게 머신러닝을 다 안다! 라고 하긴 어렵지만 그래두ㅎㅎㅎ
다음 장 딥러닝은 더 어려워보이는데... 잘 할 수 있겠지 @_@
마지막까지 잘 해내보자!!

공부기록