인터뷰 질문
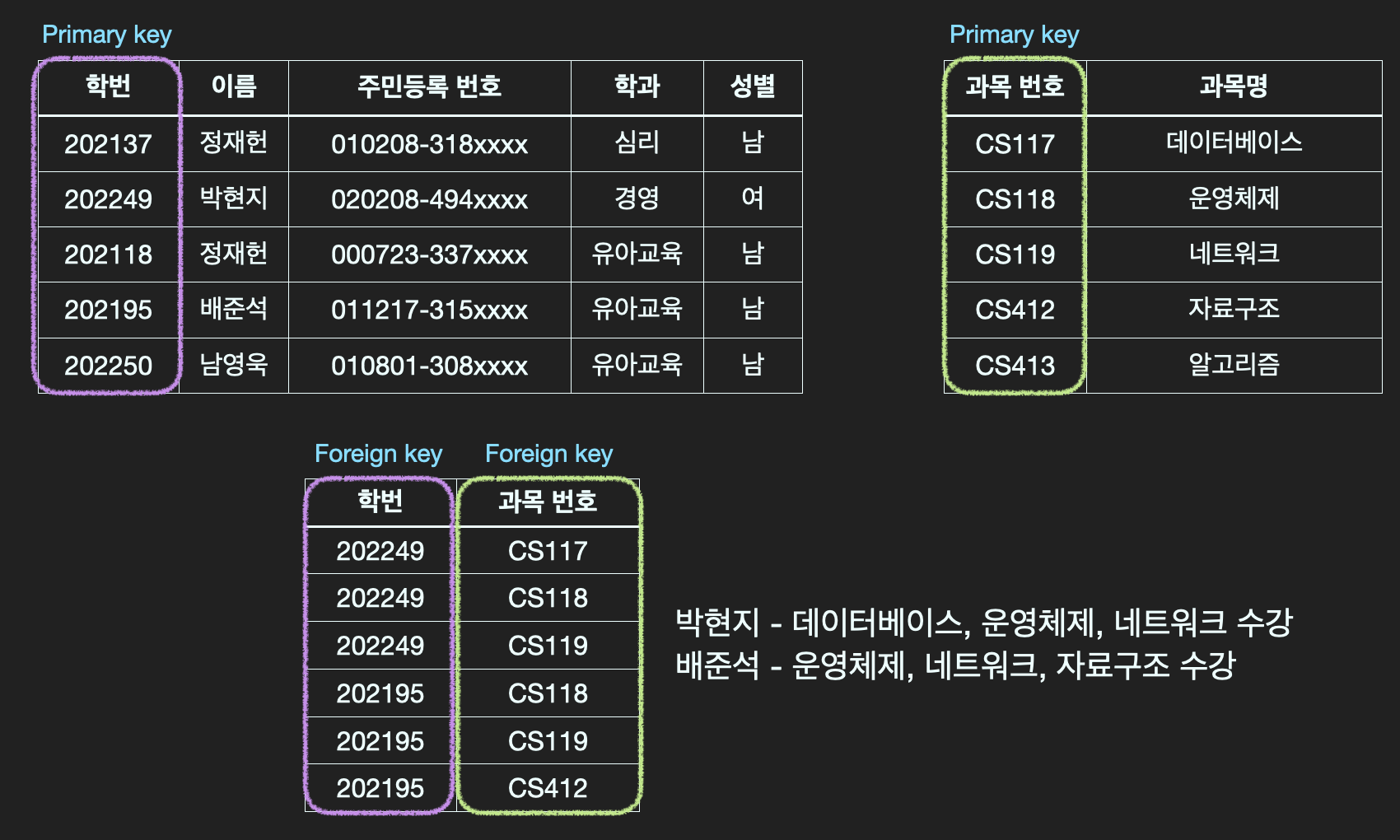
Primary Key
각 row를 unique하게 구분할 때 사용하는 column
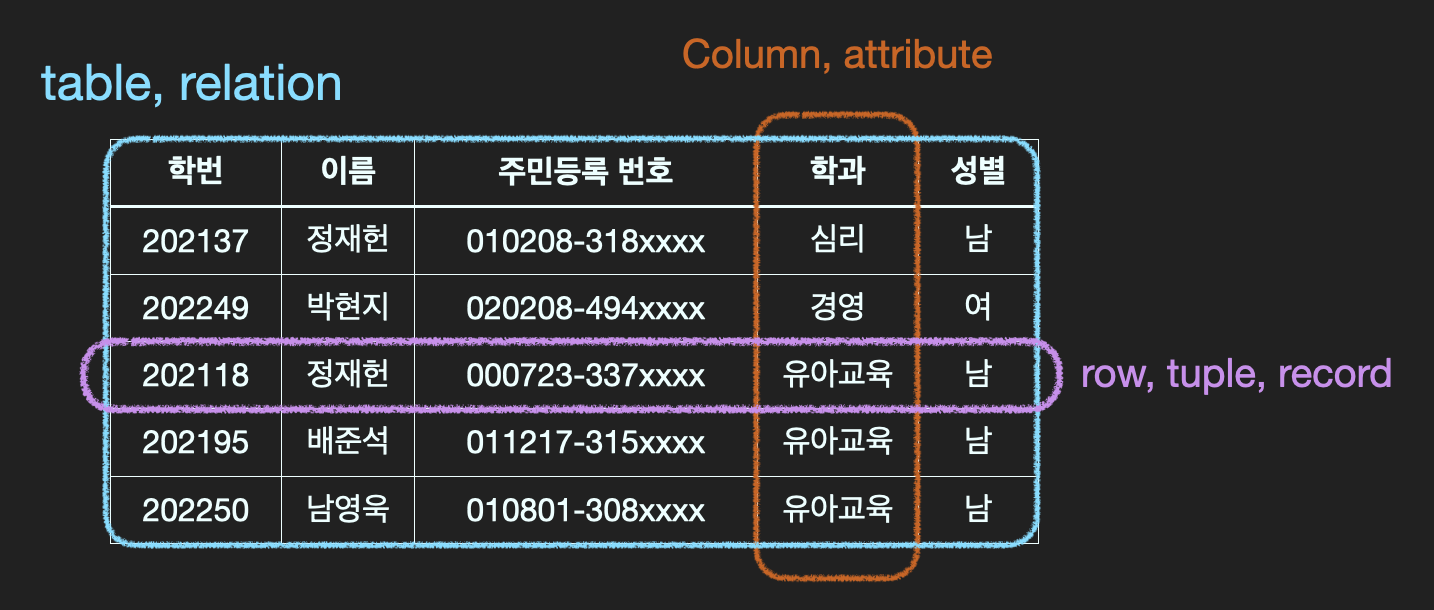
- table의 cell은 단일 값을 갖는다.
- 어떤 두 개의 row도 동일하지 않다.
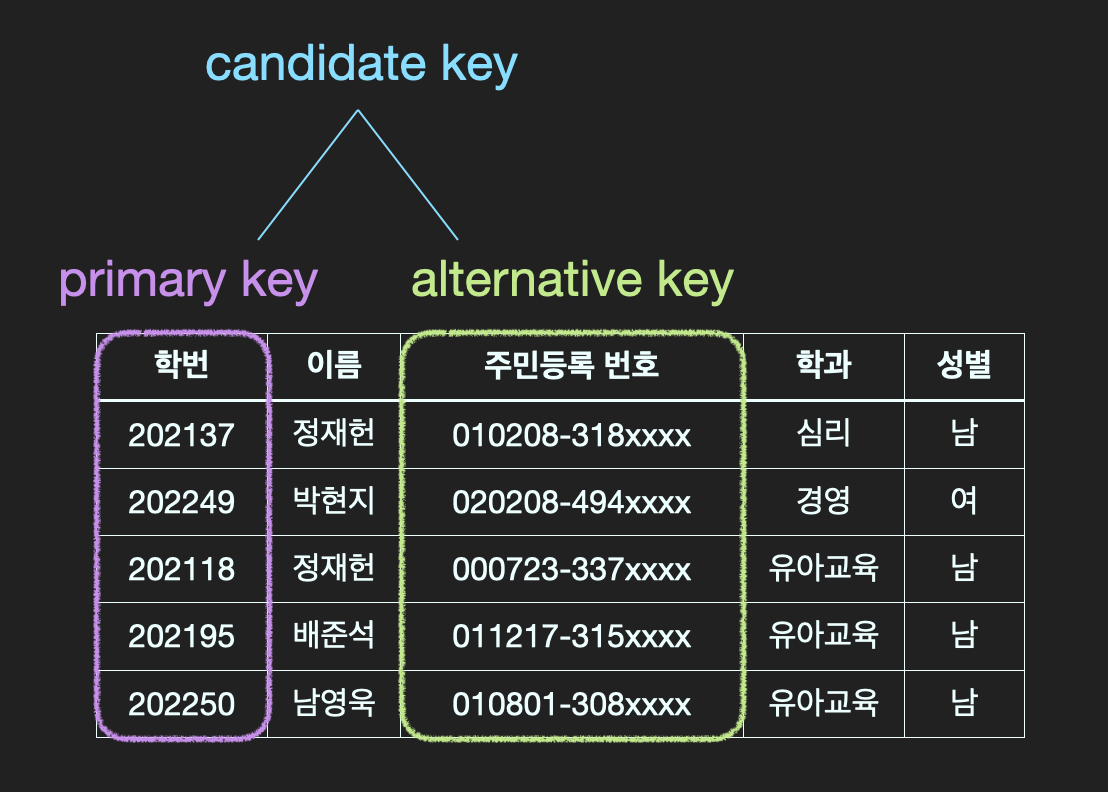
- super key:
유일성- 각 row를 unique하게 구분해주는 column들의 집합
- candidate key와 차이: 불필요한 column들이 포함되어도 됨
Ex) (학번,이름),(학번,이름,성별),(주민번호,학과) 등
- candidate key:
최소성- Super key 중에서 더 이상 쪼개질 수 없는 최소한의 단위
- 위 그림에서는 [학번]과 [주민번호]가 row를 구분해주는 main key이므로 candidate key다.
- primary key: candidate key 중 선택한 main key
- 1개만 선택
- Null ❌
- 중복 ❌
- alternative key: candidate key 중 선택받지 못 한 sub key
Foreign Key
Primary key로 연결된 다른 table의 column
관계형 데이터베이스 N:M 관계
1:N
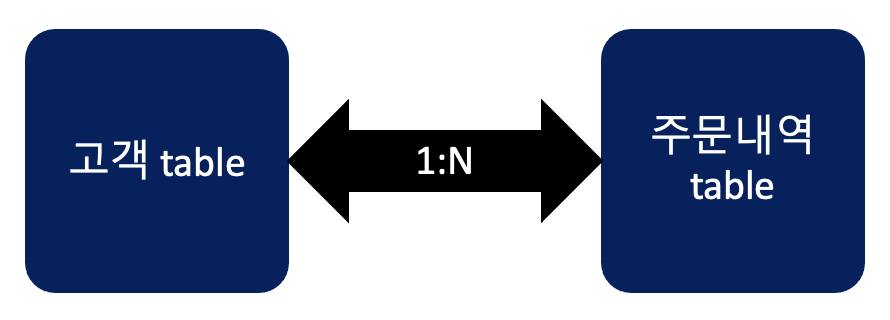

- 장점: primary key table의 정보가 바뀌어도 foreign key table은 수정 ❌
N:M
left outer join vs inner join
join은 두 테이블을 합칠 때 사용
테이블 A와 B가 있을 때,
left join
A의 모든 내용에 대하여 합침
inner join
A⋂B의 내용에 대하여 합침
Example
- video table
| id | title | y_id |
|---|---|---|
| 1 | 데이터베이스 완전정복 | 2 |
| 2 | 볼리비아 광산 탐방기 | 4 |
| 3 | 침vs펄 토론 | 3 |
| 4 | 운영체제 완전 정복 | 2 |
| 5 | 충격실화 대한민국이 해냈다 | Null |
- youtuber table
| id | name | 채널 설명 |
|---|---|---|
| 1 | 쯔양 | 먹방 |
| 2 | 개발남노씨 | 개발 |
| 3 | 침착맨 | 예능 |
| 4 | 빠니보틀 | 여행 |
left join
| id | title | y_id | name | 채널 설명 |
|---|---|---|---|---|
| 1 | 데이터베이스 완전정복 | 2 | 개발남노씨 | 개발 |
| 2 | 볼리비아 광산 탐방기 | 4 | 빠니보틀 | 여행 |
| 3 | 침vs펄 토론 | 3 | 침착맨 | 예능 |
| 4 | 운영체제 완전 정복 | 2 | 개발남노씨 | 개발 |
| 5 | 충격실화 대한민국이 해냈다 | Null | Null | Null |
inner join
| id | title | y_id | name | 채널 설명 |
|---|---|---|---|---|
| 1 | 데이터베이스 완전정복 | 2 | 개발남노씨 | 개발 |
| 2 | 볼리비아 광산 탐방기 | 4 | 빠니보틀 | 여행 |
| 3 | 침vs펄 토론 | 3 | 침착맨 | 예능 |
| 4 | 운영체제 완전 정복 | 2 | 개발남노씨 | 개발 |
RDB vs No SQL ⭐️
RDB = Relational Data Base
Data Update Frequency ⬆️: RDB
Data Update Frequency ⬇️: No SQL
데이터 구조 ✅: RDB
데이터 구조 ❌: No SQL
데이터 양 ⬆️: No SQL
데이터 양 ⬇️: RDB

Scale Up vs Scale Out
출처 : https://www.slideshare.net/teoliphant/scaling-pydata-up-and-out
Transaction? ⭐️⭐️
데이터베이스 작업의 최소 단위, 장애 발생 시 복구의 효율성을 높이기 위함 = [데이터베이스의 무결성]을 유지하기 위함
Example
은행에서의 Transaction을 입금과 출금 따로 분리하면
송금을 했음에도 불구하고 상대방이 돈을 받지 못 하는 오류가 발생할 수 있음.
따라서 은행에서는 [입출금]을 하나의 최소단위(Transaction)로 구분함.
ACID
데이터베이스의 무결성을 위해
- Atomicity(원자성) : transaction에 포함된 작업은 전부 수행되거나 아니면 전부 수행되지 말아야 합니다.(all or nothing)
- Consistency(일관성): transaction이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지하는 것을 의미한다. 송금 전후 모두 잔액의 data type은 integer이여야 한다는 것이 일관성의 한 예가 될 수 있습니다.
- Isolation(고립성): 여러 Transaction은 동시에 수행됩니다. 이때 각 transaction은 다른 transaction의 연산 작업이 끼어들지 못하도록 보장하여 독립적으로 작업을 수행합니다. 따라서 동시에 수행되는 transaction이 동일한 data를 가지고 충돌하지 않도록 제어해줘야 합니다. 이를 동시성제어(concurrency control) 라고합니다.
- Durability(지속성): 성공적으로 수행된 transaction은 데이터베이스에 영원히 반영되어야 함을 의미합니다. transaction이 완료되어 저장이 된 데이터베이스는 저장 후에 생기는 정전, 장애, 오류 등에 영향을 받지 않아야 합니다.
동시성 제어
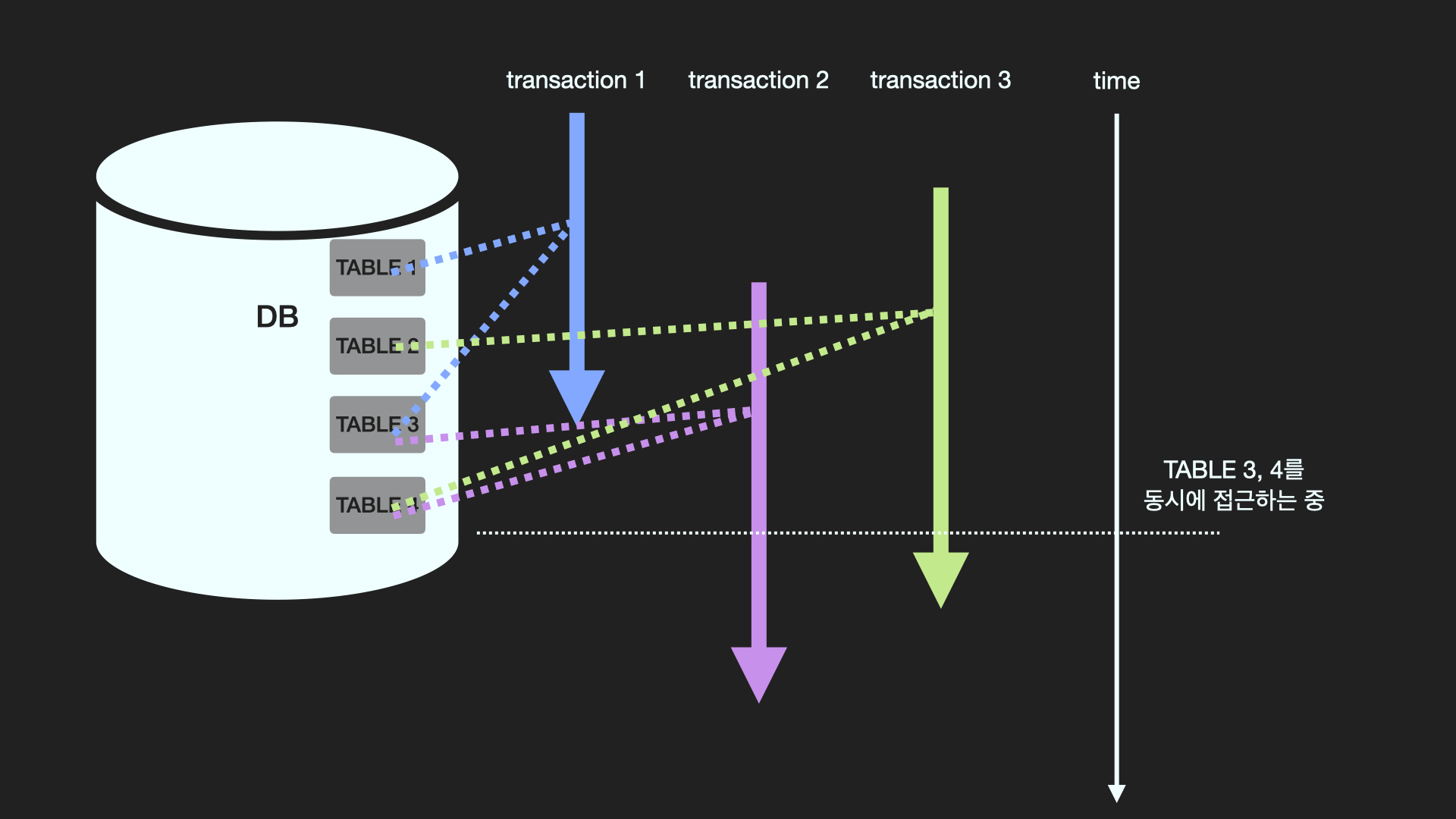
위 그림은 ACID의 Isolation 원칙을 무시하고 있다. 따라서 이를 해결하기 위해 동시성 제어가 필요하다.
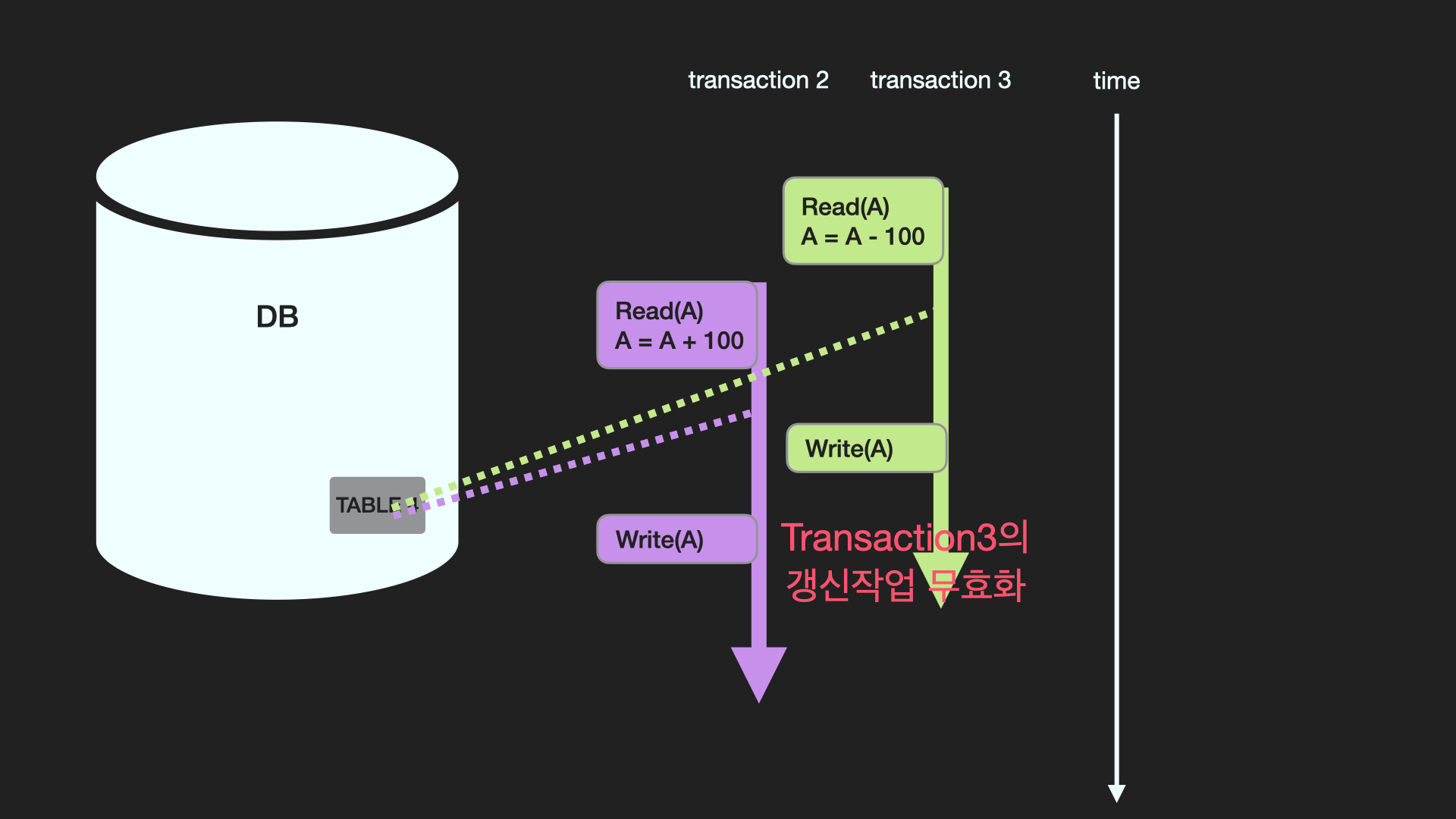
[transaction 3]에서 'A-100'연산을 했지만 [transaction 2]에서 연산을 다시 하면서 무효화 됐다.
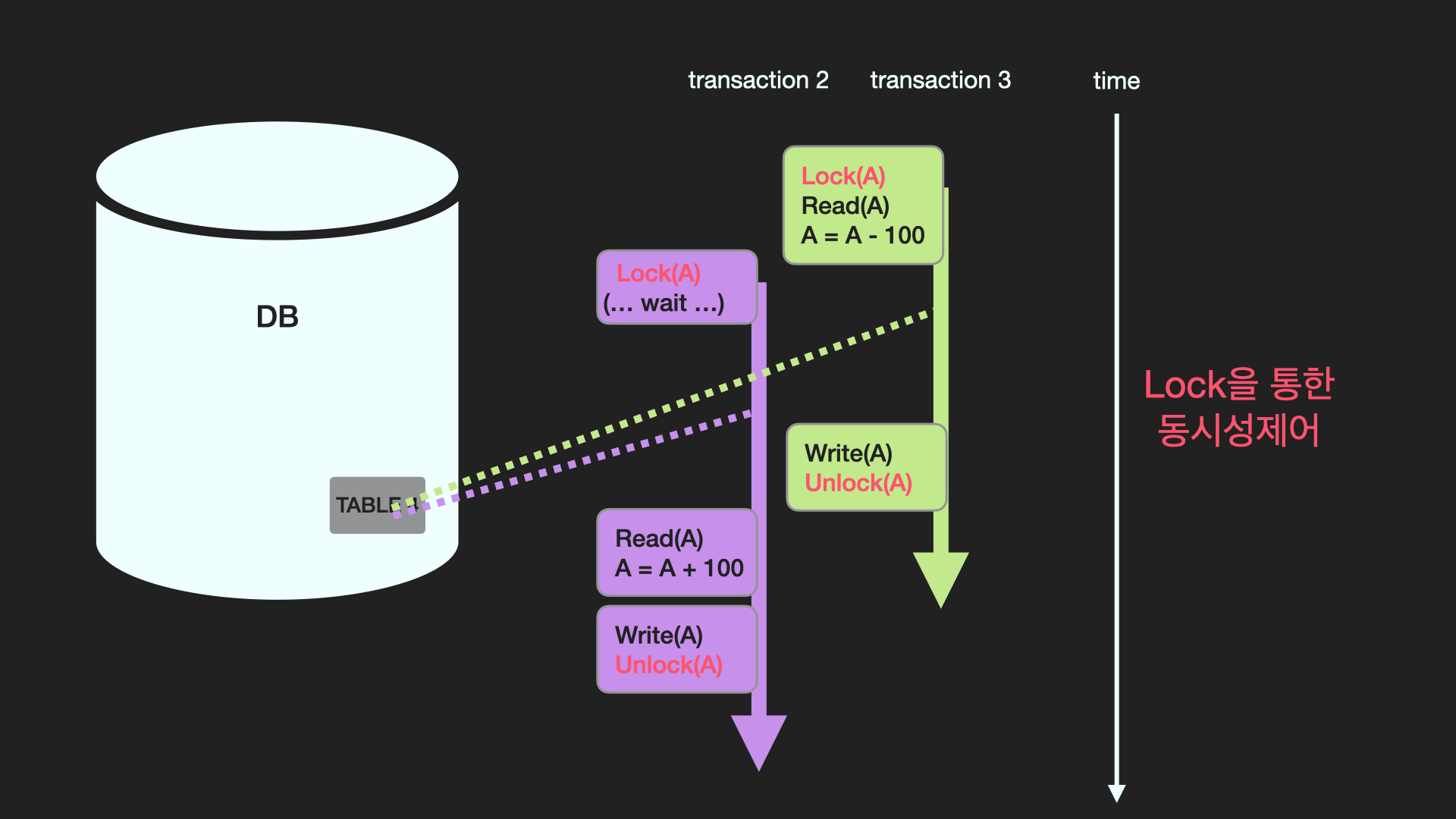
이를 해결하기 위해 [transaction 3]에서 lock을 걸어놓고 작업을 한다. lock이 걸려있는 동안 [transaction 2]는 대기를 해야하고 unlock 상태로 전환되고 나서 작업을 한다.
Deadlock ⭐️
Why Index?
Table의 [검색 성능 향상]을 위하여
- 인덱스가 없으면 Full Table Scan을 해야하기 때문에
단점
- 인덱스를 위한 추가 저장 공간 필요
- 데이터 변경시 인덱스 재구성이 필요함 👉🏻 데이터 변경 횟수가 잦으면 성능 저하
Index 사용 최적의 Column ⭐️⭐️⭐️⭐️
| 기준 | 적합성 |
|---|---|
| 카디널리티(Cardinality) | 높을수록 적합 (데이터 중복이 적을수록 적합) |
| 선택도(Selectivity) | 낮을수록 적합 |
| 조회 활용도 | 높을수록 적합 (where 절에서 많이 사용되면 적합) |
| 수정 빈도 | 낮을수록 적합 |
카디널리티
-
카디널리티 = 집합의 길이
-
카디널리티가 높다는 뜻은 집합이 길다는 뜻이고 이는 다양한 검색이 가능하다는 뜻이다.
선택도
-
선택도가 낮아야 특정 레코드를 찾는데 효과를 볼 수 있음.
-
전체 데이터에서 1개밖에 없는 데이터를 찾을 때 풀스캔을 하는 손해와 전체 데이터의 70%의 데이터를 찾을 때 풀스캔을 하는 손해는 전자가 더욱 큼
조회 활용도
당연히 많이 쓰이는 column일수록 index를 걸어두면 요긴하게 사용 가능
수정 빈도
[Index 단점 #2]와 같이 데이터 업데이트가 많이 일어날수록 과부하가 발생하므로 수정 빈도는 낮아야 한다.
B+ Tree ⭐️
데이터를 검색을 할 때 hash table의 시간복잡도는 O(1)이고 b+tree는 O(logn)으로 더 느린데 왜 index는 hash table이 아니라 b+tree로 구현되나요?
하나의 값을 찾을 때는 hash table이지만 여러 개의 값을 찾을 때는 b+tree가 유리하기 때문이다.
장점
- 항상 정렬된 상태를 유지하여 부등호 연산에 유리
- 데이터 탐색뿐 아니라, 저장, 수정, 삭제에도 항상 O(logN)의 시간 복잡도
인터뷰 질문 목록과 설명은 패스트캠퍼스 강의를 기반으로 제작하였습니다.
