JOIN
💡 2개의 테이블을 1개의 테이블로 만들고 싶을 때 사용
- INNER JOIN: 두 테이블을 조인할 때, 두 테이블에 모두 지정한 열의 데이터가 있어야 함.
- OUTER JOIN: 두 테이블을 조인할 때, 1개의 테이블에만 데이터가 있어도 됨
- 그냥 JOIN이라고 하면 보통 INNER JOIN을 의미
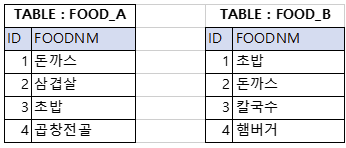
INNER JOIN
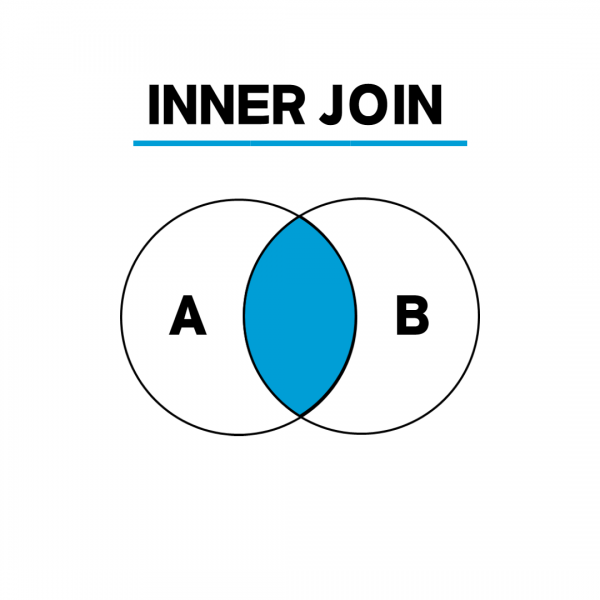
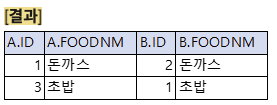
위 테이블 에서 INNER JOIN을 수행했을 때
OUTER JOIN
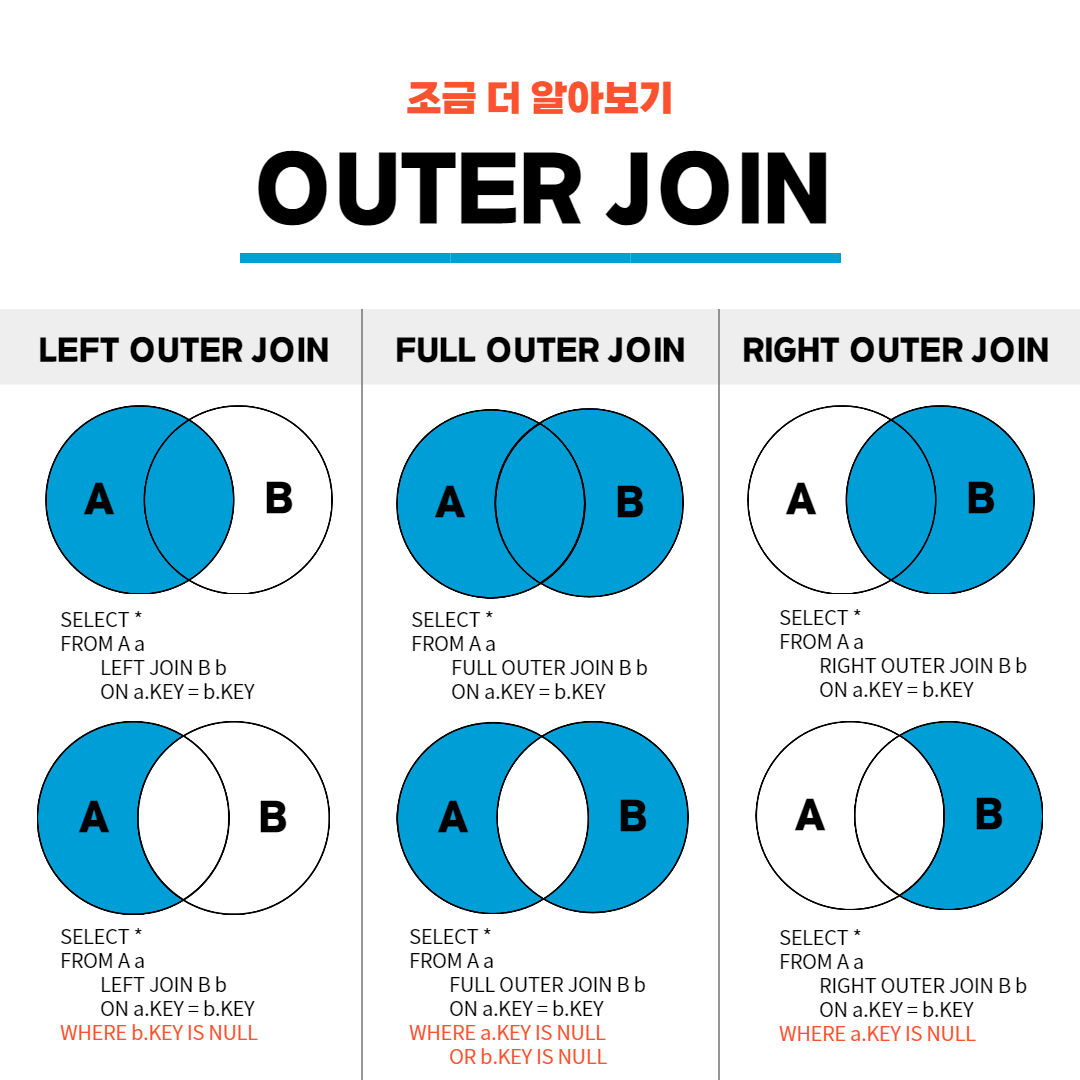
LEFT OUTER JOIN
A를 전부 추출하고 B는 A에 존재하는 행들만 추출
A
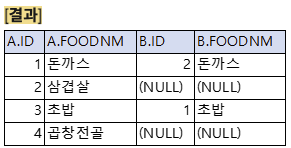
LEFT ONLY OUTER JOIN
B를 제외한 A만 추출
A-B
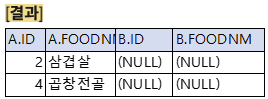
RIGHT OUTER JOIN
B
RIGHT ONLY OUTER JOIN
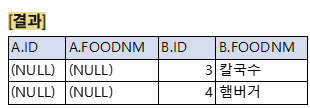
B-A
Scale Up / Scale Out
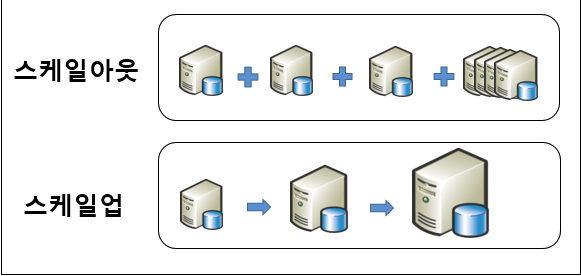
💡 "서버의 확장을 어떤 방식으로 할 것인가?"에 대한 답
Scale Up
- 하나의 서버 성능을 향상시키는 방법 / 수직 확장
- ⭐️ 데이터베이스 서버에 적합
장점
- 데이터 일관성, 파일의 일관성을 유지하기 위한 별도 작업이 필요없으므로 구축이 쉽다
단점
- 서버 한 대에 리소스를 올려 운영하기에 부하가 걸리기 쉽고 장애 발생시 치명적
- 리소스는 한계가 있으므로 확장에 제한적
Scale Out
- 여러 대의 서버를 사용해 전체 서버의 성능을 향상시키는 방법 / 수평 확장
- ⭐️ 웹서버/하둡 같은 분산파일 시스템에 적합
장점
- 장애 발생 시 다른 서버로 대체 가능
단점
- 추가적인 컨트롤러가 필요하기 때문에 관리 비용 증가
B+ Tree
⭐️ 데이터베이스에서 인덱스 테이블을 구현할 때 사용
B- Tree
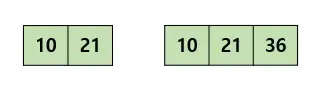
- 노드에는 2개 이상의 데이터(key)가 들어갈 수 있으며, 항상 정렬된 상태로 저장된다.
- 내부 노드는 M/2 ~ M개의 자식을 가질 수 있다. 최대 M개의 자식을 가질 수 있는 B 트리를 M차 B트리라고 한다.
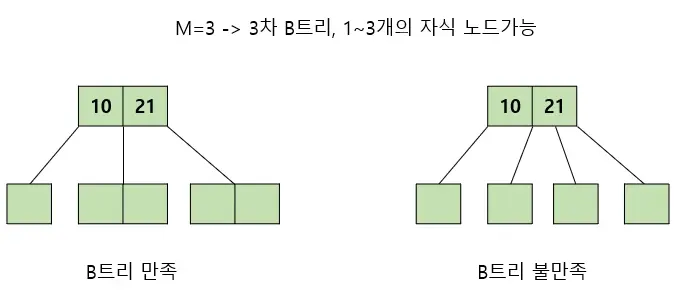
- 특정 노드의 데이터(key)가 K개라면, 자식 노드의 개수는 K+1개여야 한다.
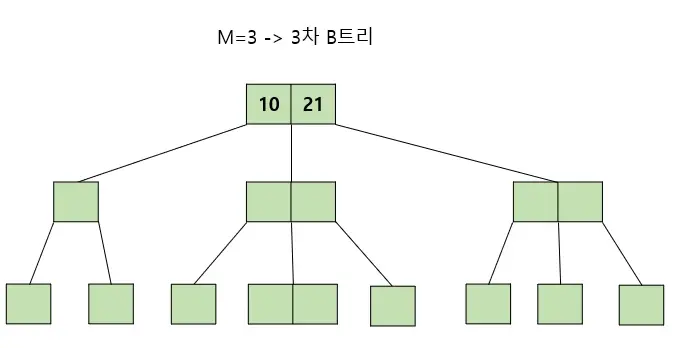
- 특정 노드의 왼쪽 서브 트리는 특정 노드의 key 보다 작은 값들로, 오른쪽 서브 트리는 큰 값들로 구성된다.
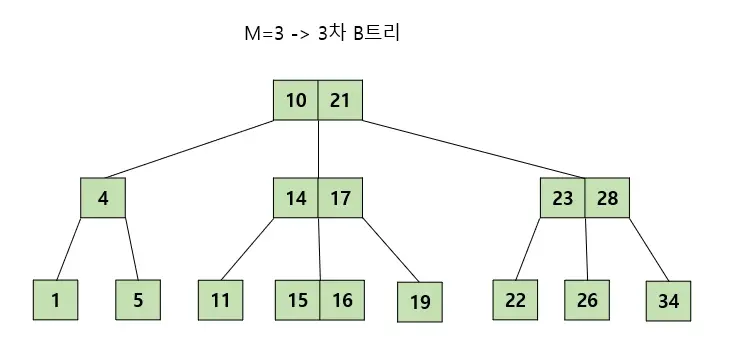
- 노드 내에 데이터는 floor(M/2)-1개부터 최대 M-1개까지 포함될 수 있다 ( floor : 내림 함수 Ex-floor(3.7) = 3 )
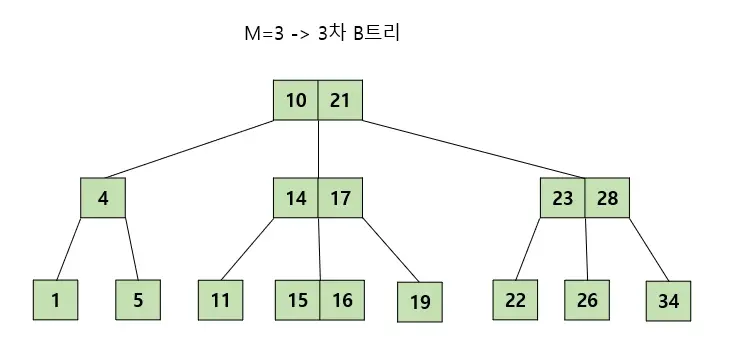
- 모든 리프 노드들이 같은 레벨에 존재한다.
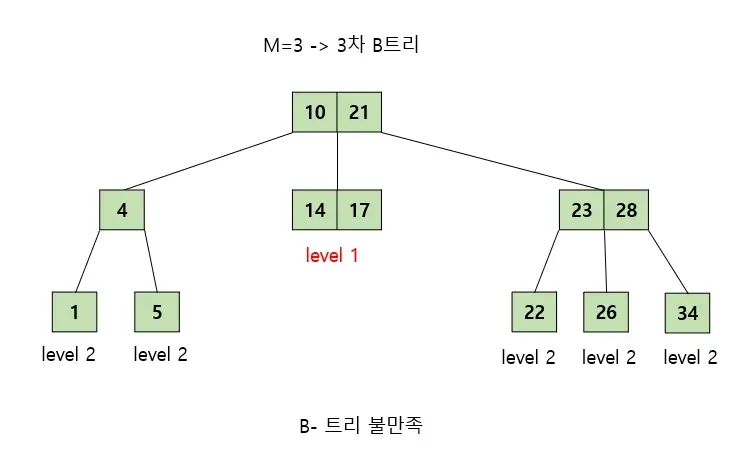
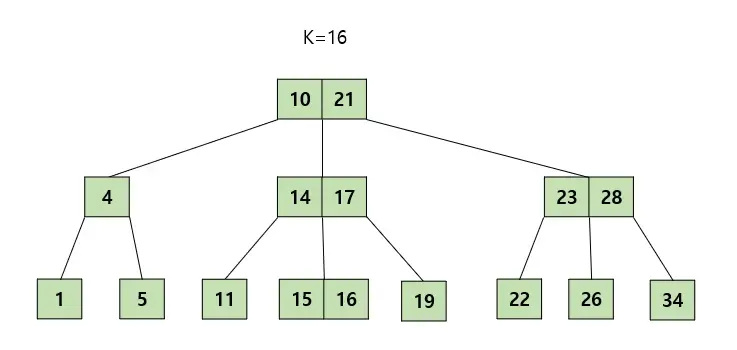
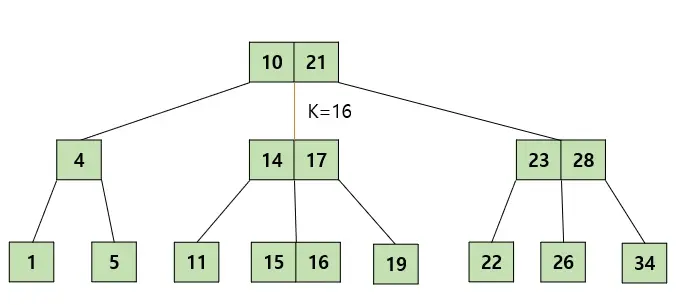
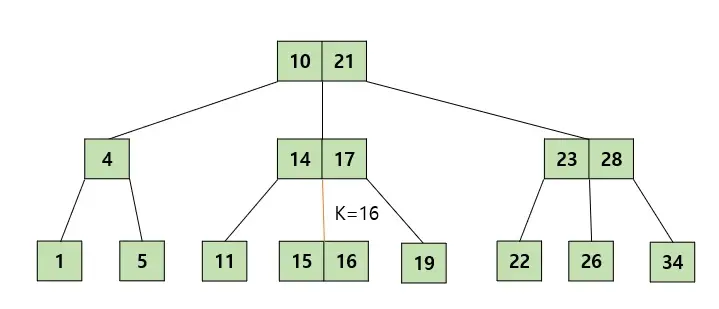
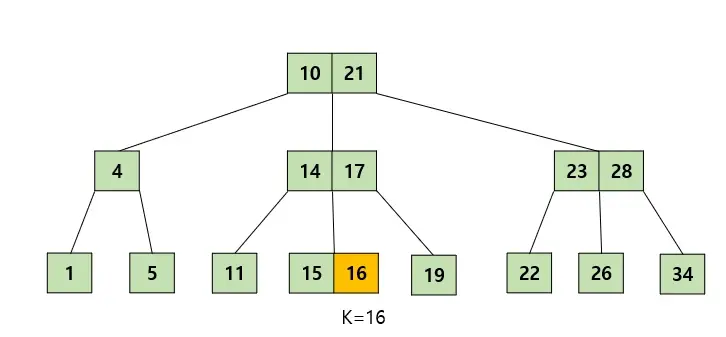
탐색 과정
- 루트 노드에서 탐색을 시작한다.
- K를 찾았다면 탐색을 종료한다.
- K와 노드의 key값을 비교해 알맞은 자식 노드로 내려간다.
- 해당 과정을 리프 노드에 도달할 때까지 반복한다.
- 리프 노드에서도 K를 찾지 못한다면 트리에 값이 존재하지 않는 것이다.
B+ Tree
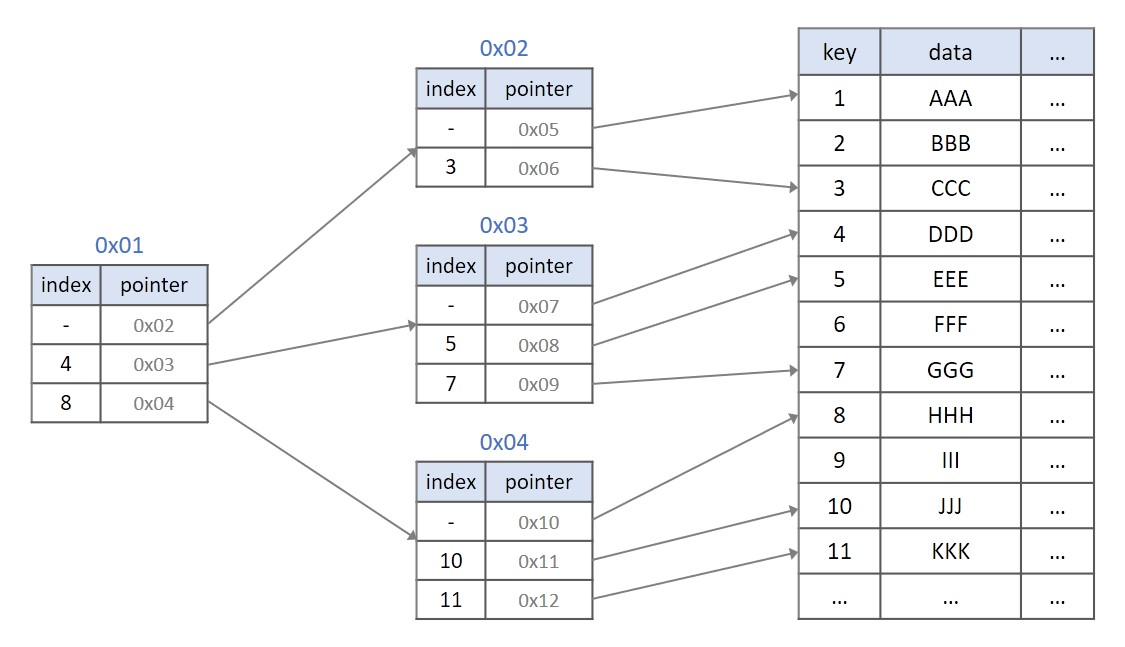
위와 같은 인덱싱 테이블을 B+ Tree로 구현하면 아래와 같다.
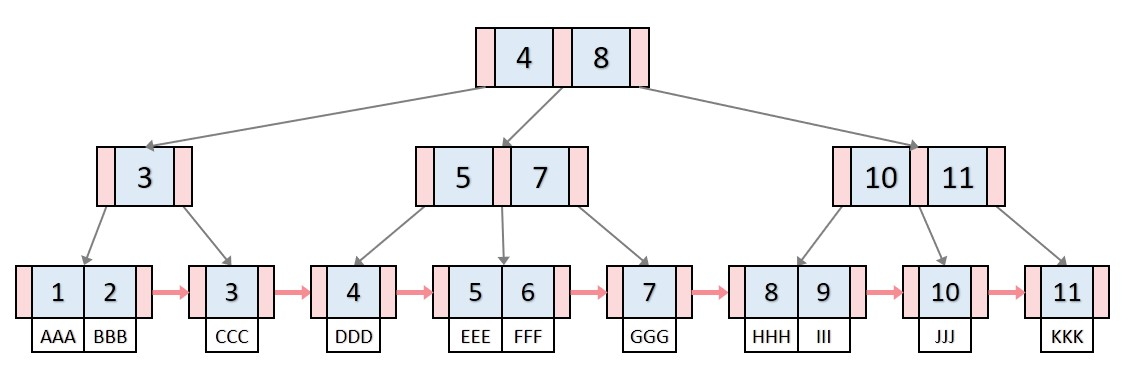
B- Tree와의 차이점
- 모든 키/데이터가 리프 노드에 모여 있다.
- 리프 노드가 연결 리스트의 형태
👉🏻 B-Tree는 옆의 노드를 검사하려면 루트 노드까지 되돌아가야 하는 반면, B+ Tree는 한 칸만 움직이면 되므로 시간복잡도 ⬇️
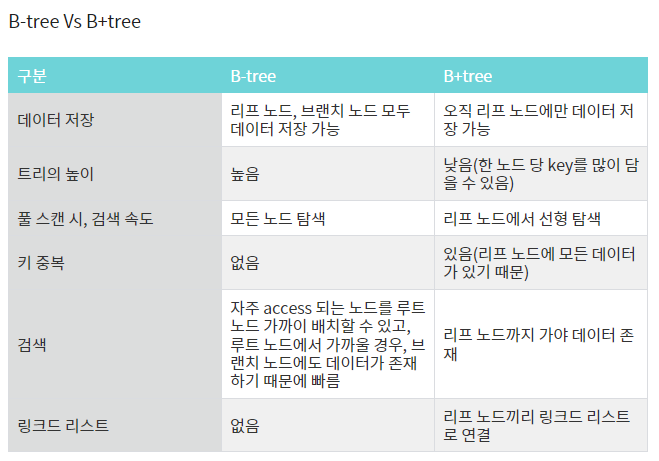
참고 자료

0x68656C6C6F21