
Selenium?
Requests 편에서 잠깐 언급하였듯이 셀레니움은 웹 크롤링을 할 때 쓰는 라이브러리다.
requests에 비해 속도가 느리다는 단점이 있지만 웹 페이지를 직접 컨트롤하는(이를테면, 클릭!) 장점이 있다.
네이버 바이브에서 노래 가사 가져오기
1. 크롬 드라이버 실행
from selenium import webdriver
def init_chrome(url):
driver = webdriver.Chrome()
driver.get(url) # URL 접속
return driverurl = "https://vibe.naver.com/track/54692454"
driver = init_chrome(url)위의 URL은 "윤하 - 사건의 지평선"이다.
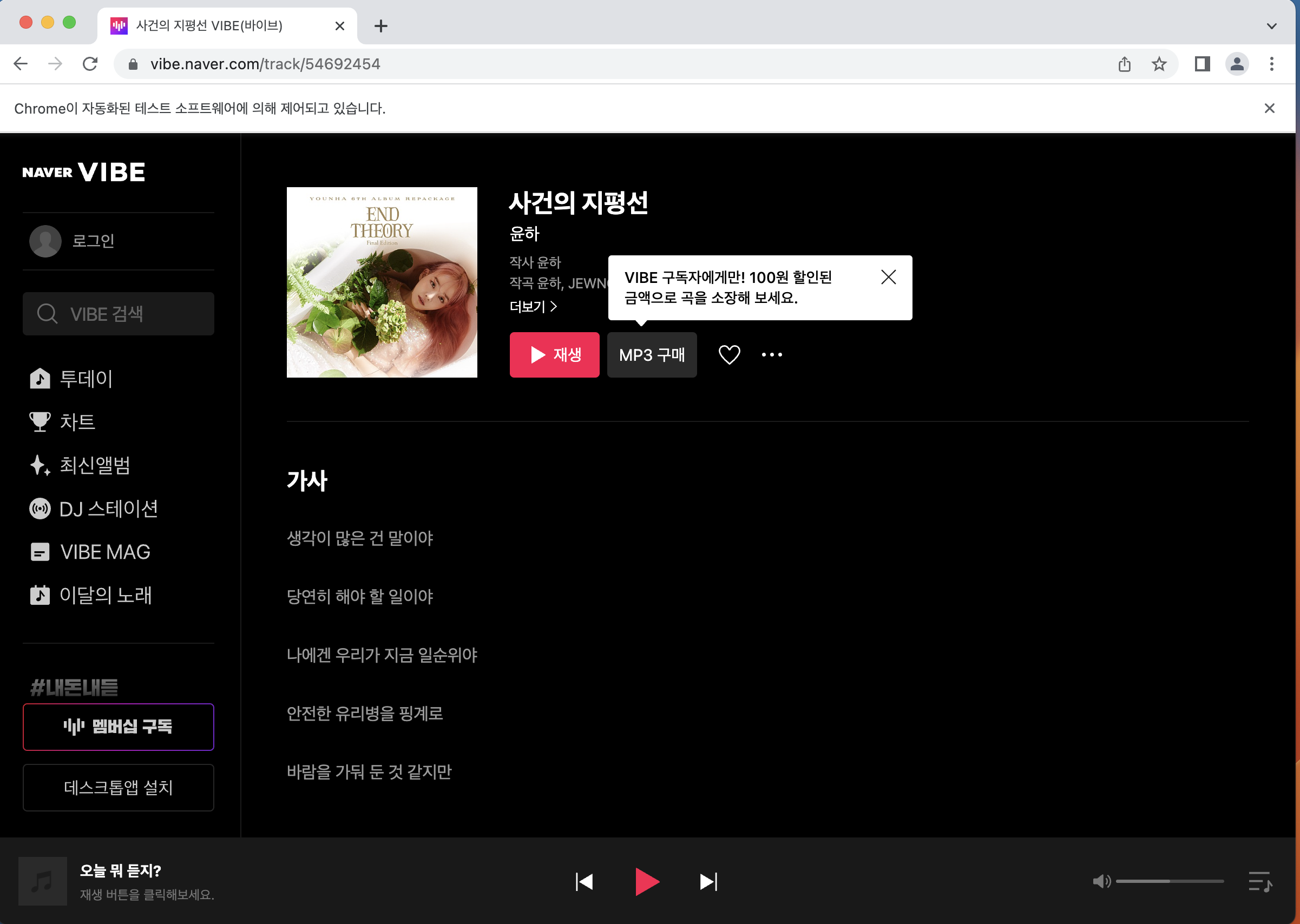
"Chrome이 자동화된 테스트 소프트웨어에 의해 제어되고 있습니다."라는 문구와 함께 파이썬이 조종하는 크롬 앱이 실행된다.
2. BeautifulSoup로 노래 가사 가져오기
from bs4 import BeautifulSoup as BS
from selenium.webdriver.common.by import By
def get_lyrics(driver,tag,class_id,selector_id):
bs = BS(driver.page_source) # HTML return
bs.find(tag, {'class' : f"{class_id}"})
driver.find_element(By.CSS_SELECTOR, selector_id).click()
bs = BS(driver.page_source)
lyrics = bs.find("div", {'class': "lyrics"})
return lyrics.find("p").textlyrics = get_lyrics(driver,"div","end_section section_lyrics","#content > div.end_section.section_lyrics > a")
print(lyrics)노래 가사에 대한 태그와 셀렉터는 개발자 도구를 통해 가져왔다.
하는 방법은 링크텍스트 참고.
결과 화면

XML ➡️ JSON 변환
고속도로 휴게소 예제
가끔씩 json 파일이 아니라 xml로 데이터를 주는 곳이 있다.
예를 들어, 공공데이터센터의 고속도로 휴게소 데이터가 그러하다.
따라서 위와 같은 경우에 우리에게 익숙한 json file로 변환해야하는 경우가 생기는데 이때 사용할 수 있는 요긴한 함수가 있다.
import requests,xml.etree.ElementTree as ET
def xml_to_json():
total = []
for i in range(1,4):
url = f"http://data.ex.co.kr/openapi/locationinfo/locationinfoRest?key=8097256368&type=xml&numOfRows=1000&pageNo={str(i)}"
r = requests.get(url)
root = ET.fromstring(r.text)
items = root.iter(tag='list')
for element in items:
tmp = {}
for x in element:
tmp[x.tag] = x.text
total.append(tmp)
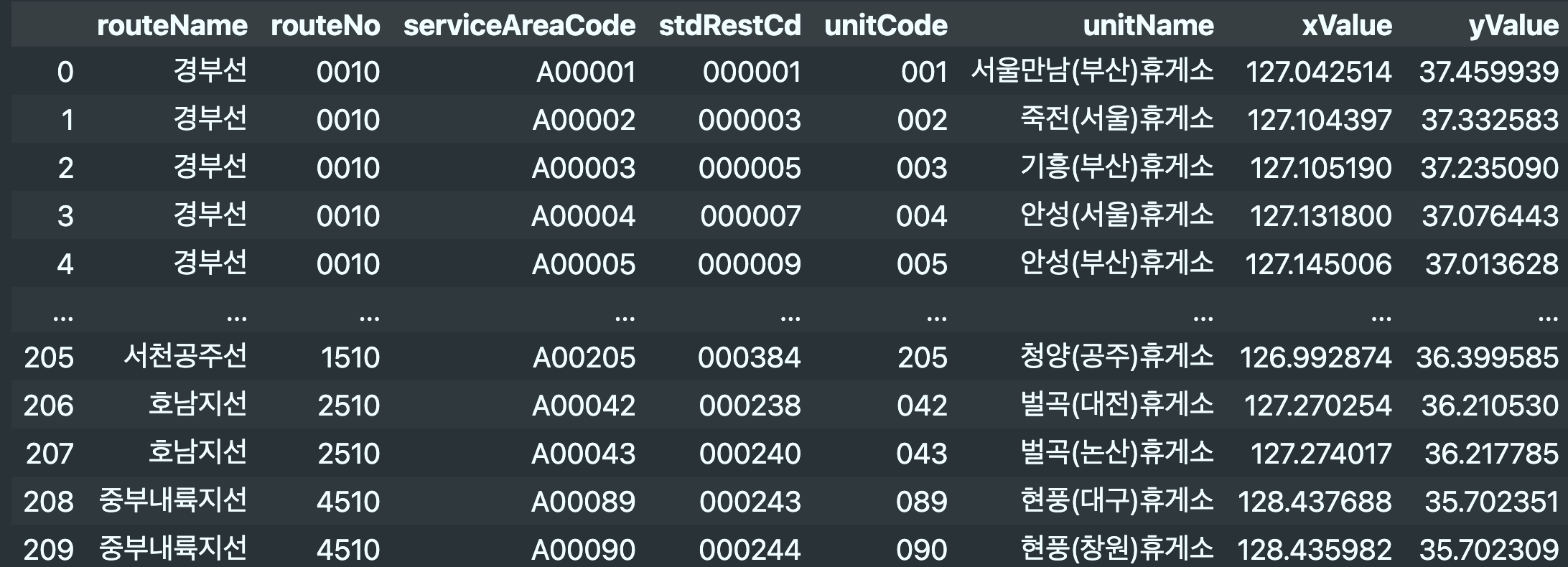
return totalimport pandas as pd
total = xml_to_json()
pd.DataFrame(total)결과 화면

0x68656C6C6F21