
📌 4차 미니 프로젝트
⭐ 서울시 공공 데이터 기반, 서울시 생활인구 예측
목표: 서울의 생활인구 데이터를 분석하여, 특정 지역의 생활인구를 파악하고 해당 지역의 생활인구를 예측한다
데이터
- 특정 시점을 기준으로 일정시간 동안에 유입, 유출, 이동한 총 인구
- 생활인구: 특정(조사) 시점에 존재하고 있는 사람의 수
1. 데이터 분석(EDA)
기본 데이터는 서울시 특정구 특정동의 생활인구 데이터가 주어졌다. train 데이터의 경우 2017년부터 2021년까지의 데이터를 합쳐서 사용하였고, test 데이터의 경우 2022년의 반년치 데이터만 주어졌다.
컬럼은 총 31개였고, 다음과 같다.

이 칼럼들을 보면서 너무 나눠져있는 연령대를 좀 합칠 필요가 있다고 판단했다. 따라서 생애 주기 단계에 맞춰 청소년(13세 이상 19세 미만인 사람), 성인(19세부터 30세까지), 장년(30세부터 45세까지), 중년(45세부터 64세까지), 노인(65세 이상)으로 합침으로써 구분하였다. 따라서 오직 생애 주기로 만 나눈 데이터와, 생애 주기에서 여성과 남성으로 나눈 데이터까지, 총 두 개의 데이터 프레임을 구성하였다.
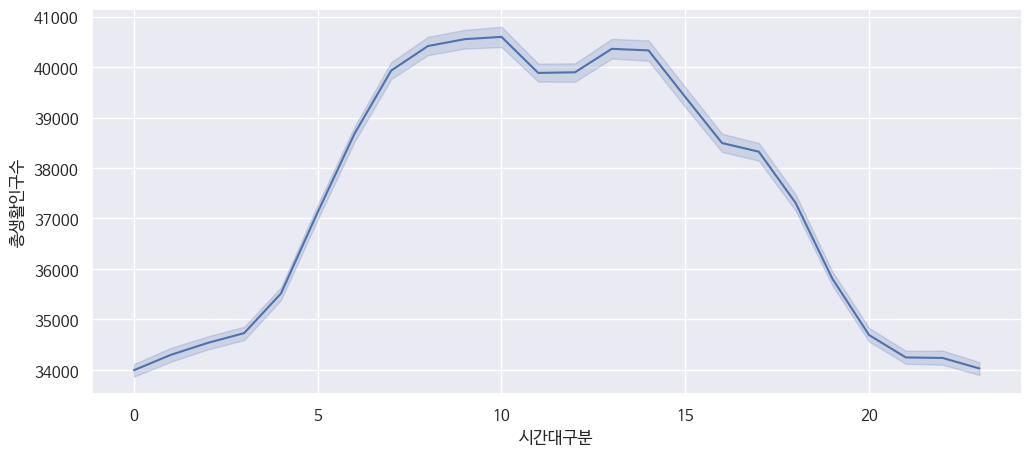
다음은 시간대별로 '총 생활 인구수'의 변화를 나타내는 그래프이다.
2. 데이터 전처리
- '기준일ID'열을 datetime 형식으로 변경 후 dt.year, dt.month, dt.day, dt.weekday를 진행후 가변수화를 진행하였다. 하지만, 22년 데이터의 경우 반년치 데이터 밖에 없다보니까, 칼럼의 갯수가 맞지 않는 문제가 발생하였다. 따라서 '기준일ID'열은 삭제하고 진행하였다.
- shift와 rolling을 이용
원 데이터는 1시간대로 나뉘어진 시계열 데이터이기 때문에 미래시점의 인구를 예측하는 것이다. 따라서 하루 전 그 시간대, 7시간 동안의 이동평균, 3시간전까지의 평균, 바로 직전 1시간 전의 데이터를 가져왔다.
df_total['1d예측'] = df_total['총생활인구수'].shift(24)
df_total['이동평균 수'] = df_total['총생활인구수'].rolling(7, min_periods = 1).mean()
data_total['3h_mean'] = data_total['총생활인구수'].rolling(3, min_periods = 1).mean()
data_total['1h_before'] = data_total['총생활인구수'].shift(1)3. 모델링
LinearRegression, RandomForestRegressor, GradientBoostingRegressor, KNeighborsRegressor, XGBRegressor 총 5개 모델로 진행했다.
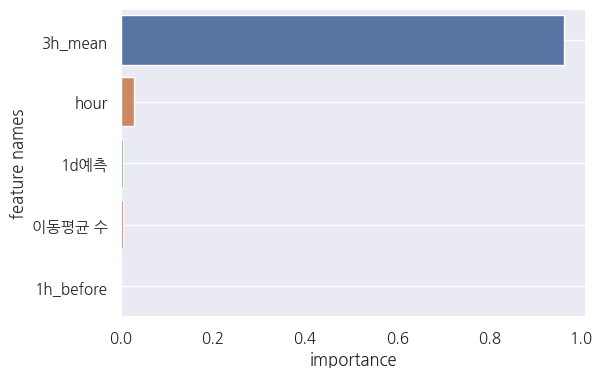
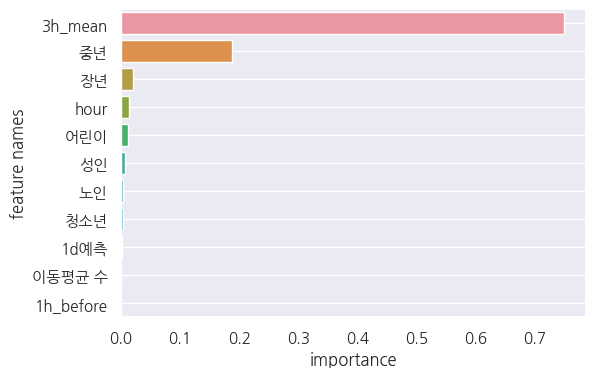
아래 사진은 GradientBoostingRegressor의 변수 중요도이다. 참고로 왼쪽은 shift와 rolling을 진행한 칼럼만 남겨둔 데이터 프레임에 대한 변수 중요도, 오른쪽은 생애 주기로 합치고 shift와 rolling을 진행한 데이터 프레임이다.
보시다시피, 직전 3시간 전까지의 평균이 아주 높은 변수 중요도를 차지하고 있는 것을 볼 수 있다. 이는 GradientBoostingRegressor이 아닌 다른 모델 또한 마찬가지였다.
그 덕에 전체적으로 좋은 성능이 나왔음을 확인했다.
왼쪽 R2-Score: 0.9841506948197996
오른쪽 R2-Score: 0.9909533353119533
 |  |
|---|
❗마치며
사실 시계열 데이터를 다룰 때, shift와 rolling이 중요하다는 점은 알고 있었지만, 오늘처럼 다른 그 어떤 데이터보다, 내가 전처리한 rolling 하나로 성능이 좋게 나왔음을 확인했다. 다음부터는 더더욱 왜?라고 생각하며, shift와 rolling을 진행해야겠다. 이렇게 뭔가 하나하나 배워가는 중...
