
📌 4차 미니 프로젝트
⭐ AIVLE-EDU 1:1 문의 유형 분류하기
목표: AIVLE SCHOOL TUTORING CENTER의 업무 고도화를 위해 1:1 질문 게시판에 업로드 되는 에이블러들의 질문 유형을 자동으로 분류해주는 모델을 만들고 성능을 개선한다.
1. 데이터 분석 및 전처리
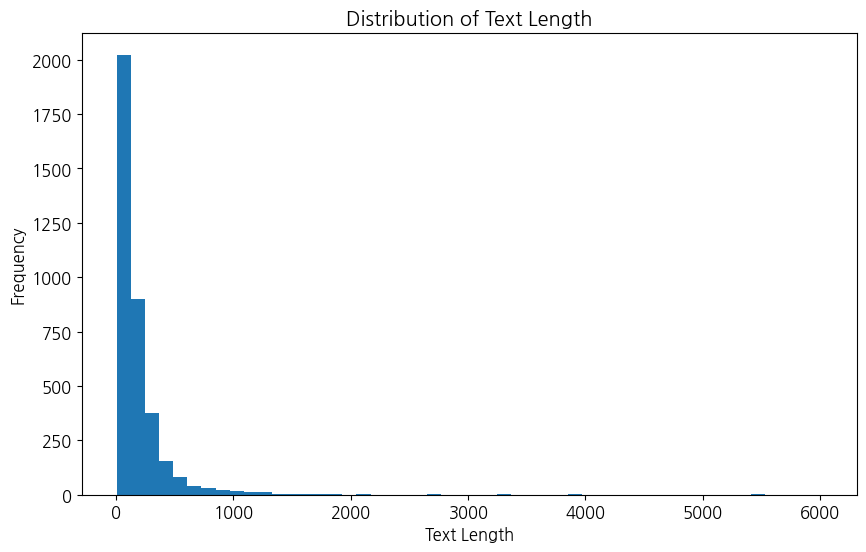
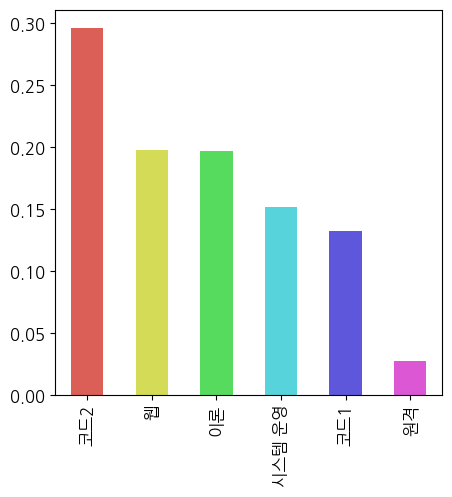
먼저 데이터는 각 문의 내용에 대해 label이 '코드2', '웹', '이론', '코드1', '시스템 운영', '원격'로 분류되어 있다. 문의 내용 중 길이가 제일 긴 인덱스는 2561번으로 길이가 6012이다.
 |  |
|---|
이 프로젝트를 어떻게 진행할까 팀원들과 이야기를 하면서 영어, 특수 문자, 숫자를 모두 제거하고 'NNG(일반명사)', 'NNP(고유명사)' 품사에 해당하는 단어만 추출하여 분석을 진행하기로 결정했다. 추가로, 한글 단어 중에서 한 글자로 이루어진 단어를 확인해 보니, 제대로 처리되지 않은 조사나 이해하기 어려운 단어가 많았다. 이를 보완하기 위해 한 글자 단어를 삭제한 데이터프레임과 그렇지 않은 데이터프레임 두 가지를 만들어 분석을 진행했습니다.
# 'NNG(일반명사)', 'NNP(고유명사)' 품사만 추출
def extract_nouns(text, target = ['NNG','NNP'], to_list=True):
# ['NNG','NNP','NP','NNB','NNBC','NR']
nouns_list = []
pod_text = mecab.pos(text)
for s in pod_text:
if s[1] in target:
if to_list:
nouns_list.append(s[0])
else:
nouns_list.append(s)
return nouns_list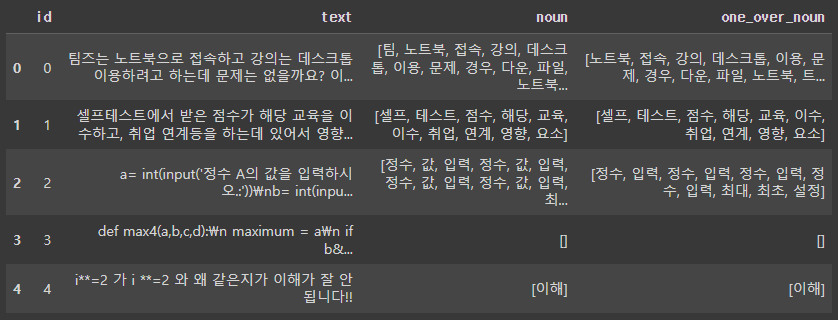
텍스트 데이터를 처리하는 과정에서 중복 단어를 제거할지에 대한 고민을 많이 했다. 그러나 단어가 여러 번 반복될수록 그 문장에서 해당 단어가 중요한 요소로 작용할 수 있을 거라 생각했다. 단어의 빈도가 그 중요성을 나타내는 경우가 많기 때문에, 중복 단어를 제거하지 않기로 결정했다.
벡터화 - N-grams
벡터화는 문서를 벡터로 변환하는 과정이다. 여기서 n-gram은 글자/단어를 n 개씩 묶는 것이다. 만약에 n을 2로 설정한다면 '토마토'를 ['토마', '마토', '토토'] 이렇게 두 글자씩 묶어준다. 이 과정을 통해 문장의 문맥을 이해하는 데 도움이 된다고 한다.
# 확인
ngram_list = []
for f in f_nouns:
tmp = []
two_gram = zip(f, f[1:])
for i in two_gram:
tmp.append(i[0] + i[1])
ngram_list.append(tmp)
print(ngram_list)TF-IDF는 단어의 빈도수에 따라 가중치를 부여한다. 따라서 TF-IDF 값이 높은 단어일수록 해당 문서에서 중요한 단어로 간주된다.
n-gram에 TF-IDF를 적용함으로써 텍스트 데이터를 더욱 효과적으로 분석하고 이해할 수 있다고 한다...
사실 이 부분은 완전히는 이해하지 못했다. 차차 공부하다 보면 더 잘 알겠지..
def identity_tokenizer(tokens):
return tokens
count_vectorizer = CountVectorizer(tokenizer=identity_tokenizer, lowercase=False)
count_mecab_vectorizer = CountVectorizer(tokenizer = mecab_tokenizer, lowercase=False)
x_tr_counts = count_vectorizer.fit_transform(X_tr["noun"])
x_val_counts = count_vectorizer.transform(X_val["noun"])
x_te_counts = count_vectorizer.transform(X_te)
x_tr_mecab_counts = count_mecab_vectorizer.fit_transform(X_tr["noun"])
x_val_mecab_counts = count_mecab_vectorizer.transform(X_val["noun"])
x_te_mecab_counts = count_mecab_vectorizer.transform(X_te)
transformer = TfidfTransformer()
x_tr_tfidf = transformer.fit_transform(x_tr_mecab_counts)
x_val_tfidf = transformer.transform(x_val_mecab_counts)
x_te_tfidf = transformer.transform(x_te_mecab_counts)
tfidf_vectorizer = TfidfVectorizer(tokenizer=identity_tokenizer, lowercase=False)
x_tr_tfidfv = tfidf_vectorizer.fit_transform(X_tr["noun"])
x_val_tfidfv = tfidf_vectorizer.transform(X_val["noun"])
x_te_tfidfv = tfidf_vectorizer.transform(X_te)
print("Count Vectorizer Vocabulary size : ", len(count_vectorizer.vocabulary_))
print("Count Vectorizer(Mecab tokenizer) Vocabulary size : ", len(count_mecab_vectorizer.vocabulary_))
print("TF-IDF Vectorizer(Mecab tokenizer) Vocabulary size : ", len(tfidf_vectorizer.vocabulary_))임베딩 - Sequence
주로 단어나 문장 등의 시퀀스 데이터를 저차원의 벡터로 임베딩하는 과정을 의미한다.
%%time
import tensorflow as tf
import numpy as np
import tensorflow.keras as keras
from keras.preprocessing import sequence
from keras.preprocessing import text
TOP_K = 5000
MAX_SEQUENCE_LENGTH = 500
X_mor_tr_str = X_tr["noun"].apply(lambda x: ' '.join(x))
X_mor_val_str = X_val["noun"].apply(lambda x: ' '.join(x))
X_mor_tr = X_tr["noun"]
X_mor_val = X_val["noun"]
tokenizer = text.Tokenizer(num_words=TOP_K, char_level=False)
tokenizer.fit_on_texts(X_mor_tr)
X_mor_tr_seq = tokenizer.texts_to_sequences(X_mor_tr)
X_mor_val_seq = tokenizer.texts_to_sequences(X_mor_val)
max_length = len(max(X_mor_tr_seq, key=len))
if max_length > MAX_SEQUENCE_LENGTH:
max_length = MAX_SEQUENCE_LENGTH
print(max_length)
X_mor_tr_seq = sequence.pad_sequences(X_mor_tr_seq, maxlen=max_length)
X_mor_val_seq = sequence.pad_sequences(X_mor_val_seq, maxlen=max_length)임베딩 - Word2Vec
이 부분은 애초에 함수가 제공되었다.
# 아래 함수는 제공합니다.
def get_sent_embeddings(model, embedding_size, tokenized_words):
# 단어 임베딩 및 n_words의 크기가 0인 feature_vec 배열을 0으로 초기화합니다.
# 또한 model.wv.index2word를 사용하여 Word2Vec 모델의 어휘에 단어 세트를 생성합니다.
feature_vec = np.zeros((embedding_size,), dtype='float32')
n_words = 0
index2word_set = set(model.wv.index_to_key)
# 토큰화된 문장의 각 단어를 반복하고 Word2Vec 모델의 어휘에 존재하는지 확인합니다.
# 그렇다면 n_words가 증가하고 단어의 임베딩이 feature_vec에 추가됩니다.
for word in tokenized_words:
if word in index2word_set:
n_words += 1
feature_vec = np.add(feature_vec, model.wv[word])
# Word2Vec 모델의 어휘에 있는 입력 문장에 단어가 있는지 확인합니다.
# 있다면 feature_vec를 n_words로 나누어 입력 문장의 평균 임베딩을 구합니다.
if (n_words > 0):
feature_vec = np.divide(feature_vec, n_words)
return feature_vec
def get_dataset(sentences, model, num_features):
# 각 문장에 대한 임베딩을 보유할 dataset이라는 빈 목록을 초기화합니다.
dataset = list()
# 문장의 각 문장을 반복하고 앞에서 설명한 get_sent_embeddings() 함수를 사용하여 문장에 대한 평균 임베딩을 생성합니다.
# 결과 문장 임베딩이 데이터 세트 목록에 추가됩니다.
for sent in sentences:
dataset.append(get_sent_embeddings(model, num_features, sent))
# 루프에서 생성된 문장 임베딩을 sent_embedding_vectors라는 2차원 배열에 쌓습니다.
sent_embedding_vectors = np.stack(dataset)
return sent_embedding_vectors2. 모델링
머신러닝에는 보통 벡터화된 데이터를, 딥러닝에는 임베딩된 데이터를 넣어줘야 한다.
머신러닝
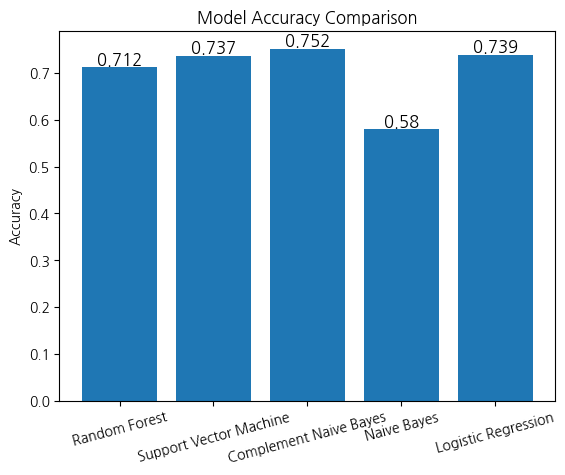
- N-gram으로 전처리한 데이터를 이용하여 3개 이상의 Machine Learning 모델 학습 및 성능 분석
딥러닝
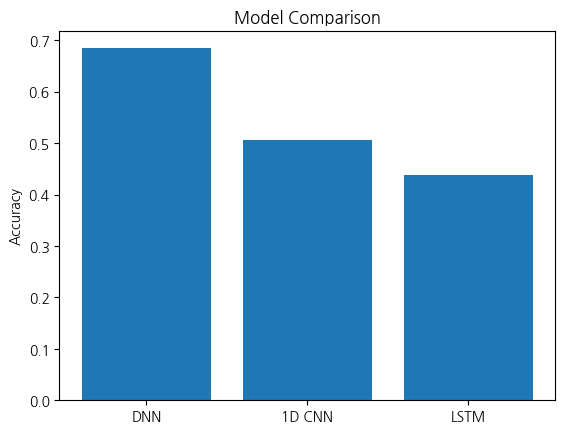
- Sequence로 전처리한 데이터를 이용하여 DNN, 1-D CNN, LSTM 등 3가지 이상의 deep learning 모델 학습 및 성능 분석
DNN Model Accuracy: 0.684636116027832
1D CNN Model Accuracy: 0.5053908228874207
LSTM Model Accuracy: 0.43800538778305054
3. Kaggle
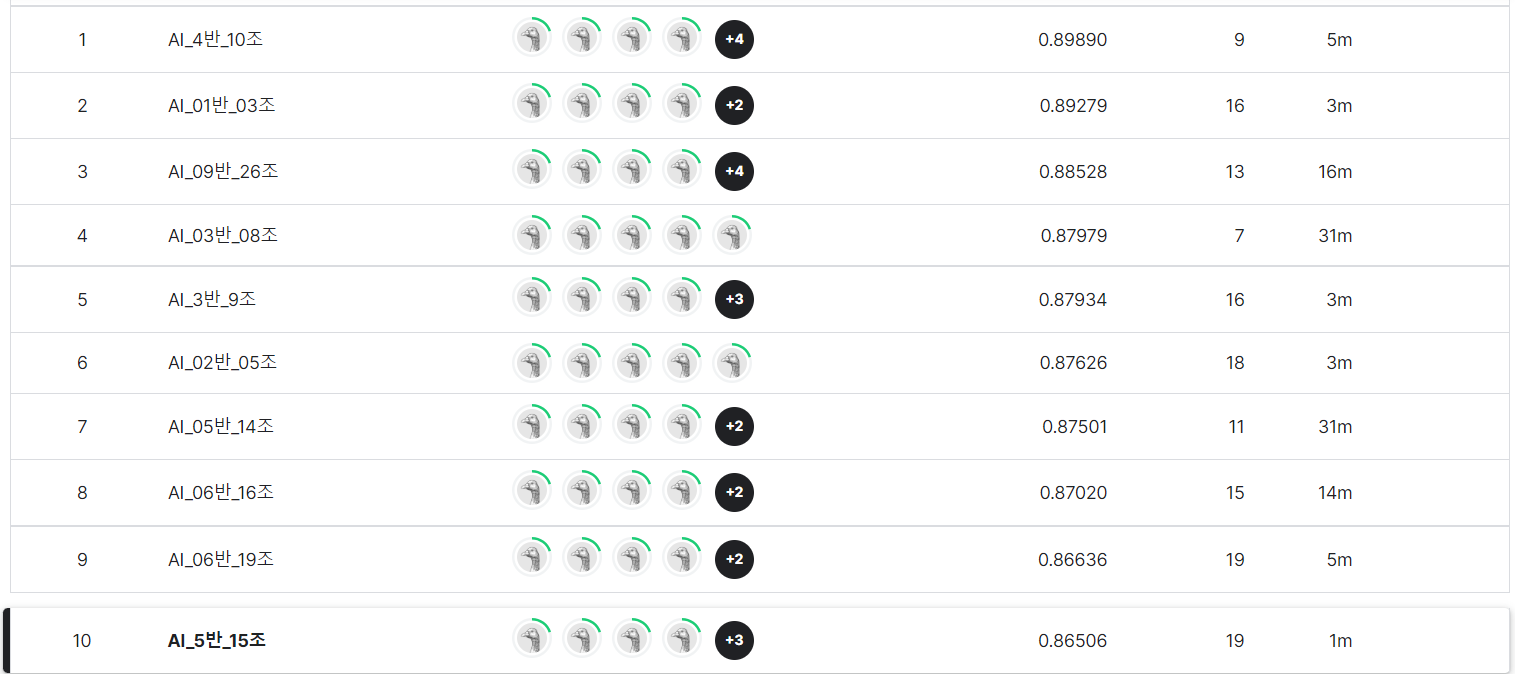
내 성능은 꽝이었지만! 다들 전처리를 다양하게 나눠서 한 덕분에 결론적으로 우리 팀은 27개 조 중에 10등으로 마무리할 수 있었다!
캐글 처음이지만.. 너무 재밌어!!

🍚 맛집 추천
이번 미프 때는 비도 오고 그래서... 배달을 시켜 먹었습니다!
아무래도, 음식물이 남으면 안 되니까, 안 생기는 음식으로 최대한 골랐습니다!
✔️ 노모어피자 분당정자점
- 매일 11:00 - 24:00
- 경기 성남시 분당구 정자일로 135 3차 푸르지오 시티 D동 1층 103호
- 스윗 고구마 피자 L 27,800
- 콰트로 치즈 피자 L 28,800
 |  |
|---|
피자.. 오랜만에 먹었는데 정말 맛있네요!
아무래도 피자가 먹다 보면 좀 느끼한 점이 있어서, 보통 하나는 좀 매운 거 해야 하는데, 고구마랑 치즈 피자로 해서, 마지막엔 많이 느끼했답니다..
다음부터는 생각하고 시키기... 하지만!!! 맛있었다❤️
✔️ 두찜 분당미금점
- 매일 10:45 - 22:45
- 경기 성남시 분당구 미금로 251 상가동 106호
- 까만 찜닭, 빨간 찜닭 23,800
 |  |
|---|
전날 피자로 다들 니글니글해져서 그런지 이번에는 꼭 밥! 먹기로 했습니다!
뭘 먹다고 고민하다가, 제가 찜닭을 좋아해서 찜닭 어떤지 여쭤봤는데 다들 좋다고 하셔서 두찜 먹기로 했습니다!
까만 찜닭 2단계, 빨간 찜닭 3단계로 시켜 먹었는데, 생각보다 많이 순해서 다음번에는 한 단계씩 더 높여서 먹기로 했습니다!
밥이 생각보다 양이 적어 보였는데, 먹다 보니 양은 충분하더라고요! 한 팀이 두 개 시켜서 각자 밥이랑 같이 드시면 아주 풍족하고 배부르게 드실 수 있을 듯합니다! 다음번에 또 먹어야지 ㅎㅎ
아무래도 시켜 먹으니까, 나가서 먹는 것보다 시간적 여유가 많이 생기더라고요. 안 나가도 되고, 음식 나올 때까지 기다리는 시간이 줄어드니까요. 그래도 어쩔 수 없이 어느 정도 음식물은 생겨서, 자주 시켜 먹진 못할 거 같아요. 그래도 한 번쯤은..?ㅎㅎ
❗마치며
나는 'NNG(일반명사)', 'NNP(고유명사)' 품사에 해당하는 단어만 추출하여 분석을 진행했습니다. 하지만 성능은 결과적으로 한국어 뿐만 아니라, 영어와 특수문자를 넣은것이 성능이 제일 좋았습니다! 결론적으로는 역시 데이터가 많을수록 성능이 좋다는거... 정말 열심히 전처리 했으나, 참 어이없고...열불도 나지만, 이렇게 또 하나 배운거겠죠?
제가 다른 프로젝트를 진행하면서 불용어 처리와 맞춤법 검사기!를 사용한 적이 있어서, 이번에도 이렇게 진행해야 할까? 하다가 일단 명사만 추출하는 방법으로만 진행했습니다.
하지만 전체 발표할 때, 1등 팀이 불용어를 진짜로 하나하나 보고 제거하셨고, 2등 팀이 맞춤법 검사기를 사용했다고 들었습니다! 다른 팀들의 발표를 보며, 아! 우리도 할걸!!이라고 생각했지만, 그 팀 분들이 대단하신 거죠 ㅎㅎ 다음번엔 저도 포기하지 않고 집념으로 한 번 제대로 불용어처리 해봐야겠습니다!
참고
-
한국어 불용어 처리
한국어 불용어 리스트 100개
보통 사람들이 만들어 둔 불용어 리스트에서 각자 데이터 프레임을 확인하며 처리해야 할 불용어를 추가하여 처리하는 방법으로 알고 있다.
다른 좋은 방법 있으면 공유 부탁드립니다!🙏🏻 -
한국어 전처리 패키지
# Py-Hanspell
# 한국어 전처리 패키지
# 네이버 한글 맞춤법 검사기를 바탕으로 만들어진 패키지로써 맞춤법을 고친 문장을 반환
!pip install git+https://github.com/haven-jeon/PyKoSpacing.git --no-deps argument