
📢 5차 미니 프로젝트
⭐ 스마트폰 센서 데이터 기반 인간 행동 인식 분류
목표: 스마트폰 기반의 센서 데이터를 활용해 동작을 분류하는 모델을 완성
1. 탐색적 데이터 분석
data.shape : (5881, 563)
칼럼이 너무 많다! 이걸 어떻게 분석해야 할까 생각하다가, 변수 중요도 상위 10개, 하위 10개만 살펴보자고 생각했다.
변수중요도 상위 10개, 하위 10개 확인
랜덤 포레스트는 튜닝 없이 하이퍼 파라미터의 기본값으로도 적절한 성능의 모델을 생성하므로, 랜덤 포레스트를 이용하여 변수 중요도 추출
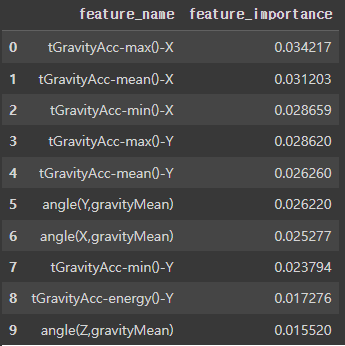 | 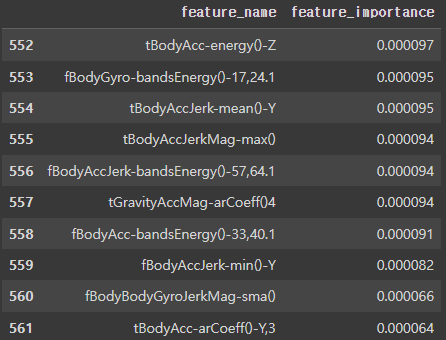 |
|---|
target = 'Activity'
 |  |
|---|
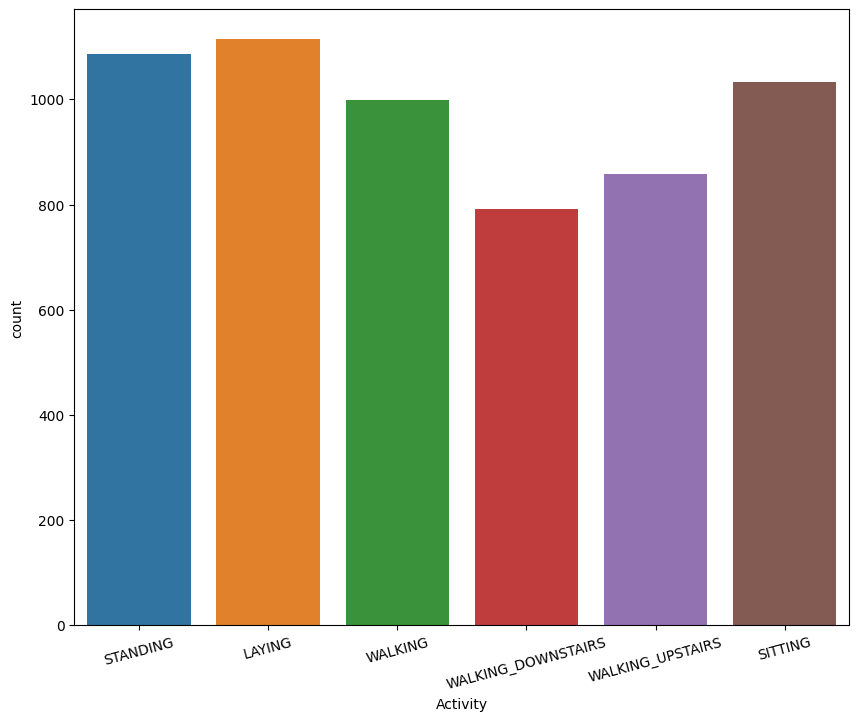
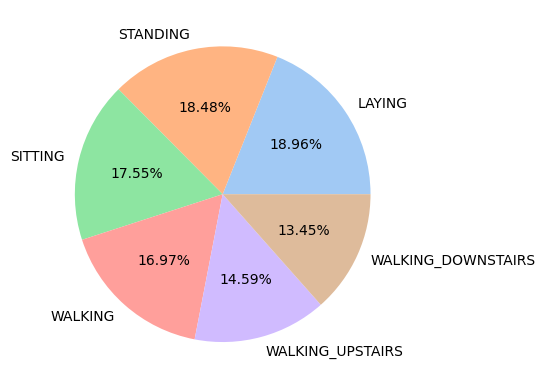
6개의 클래스로 구분하여 분류를 진행하므로 타깃 값 분포를 확인해 보았다.
countplot을 봤을 때는 데이터 분포가 고르다고 느끼지 못했으나, pieplot을 봤을 때 이 정도면 데이터 분포는 고른 거 같다고 생각했다.
2. 기본 모델링
사실 1번 파일에서 변수 중요도를 8개의 관점에서 뽑고 하나의 데이터프레임으로 합친 후 저장하였다. 그러나, 5차 프로젝트의 경우 AICE를 제외하고 3일 동안 진행되었다. 더욱이, 본 프로젝트는 캐글을 제외한 이틀 동안 진행되었다. 이러한 이유로, 변수중요도를 다양한 관점에서 뽑아 저장한 데이터 프레임은 사용되지 않았다.
스케일링
데이터프레임의 최댓값과 최솟값을 확인해 보았을 때, -1과 1임을 확인했다. 따라서 -1 ~ 1 사이에 모든 데이터가 분포하므로, 스케일링의 필요성을 느끼지 못했다.
머신러닝
best_model: Logistic Regression Model Accuracy: 0.9855564995751912
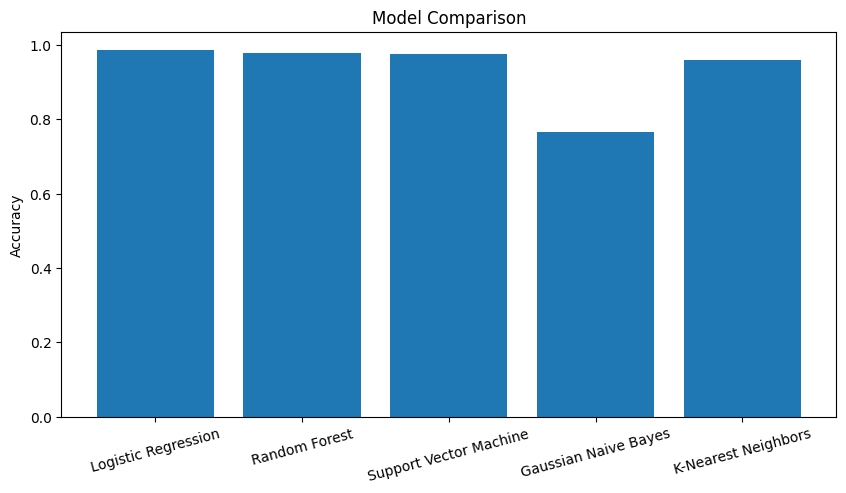
- 다른 분들의 의견을 들었을 때는 LGBM이나 XGBoost 성능이 더 좋았다는 의견도 있었습니다!
- 보시다시피 전체적으로 성능이 좋은 것을 볼 수 있었어요!
위 N개 변수를 선택하여 모델링 수행 및 성능 비교
아무래도, 기본적으로 성능이 좋다 보니, 칼럼을 어느 정도까지 줄여도 성능이 좋을까 하고 확인할 필요가 있었습니다!
변수 중요도 상위 N개를 10개씩 증가시켰을 때 가장 성능이 좋았던 모델:
Best Model with top 320 features, Accuracy: 0.9881053525913339
변수 중요도 상위 N개를 10개씩 증가시켰을 때, Early Stoppig 기법을 사용:
이전 3번의 반복에서 정확도가 0.01 이내로 변동하지 않으면 반복을 중단하고, 그 시점의 가장 높은 정확도를 가진 모델을 최종 모델로 선택
Best Model with top 30 features, Accuracy: 0.9804587935429057
3. 단계별 모델링
단계 1: 정적/동적 행동 분류 모델
def label_activity(activity):
if activity in ['STANDING', 'SITTING', 'LAYING']:
return 0
else:
return 1
data['Activity_dynamic'] = data['Activity'].apply(label_activity)
new_data['Activity_dynamic'] = new_data['Activity'].apply(label_activity)
data.head()Best Model: LogisticRegression with Accuracy: 0.9821580288870009
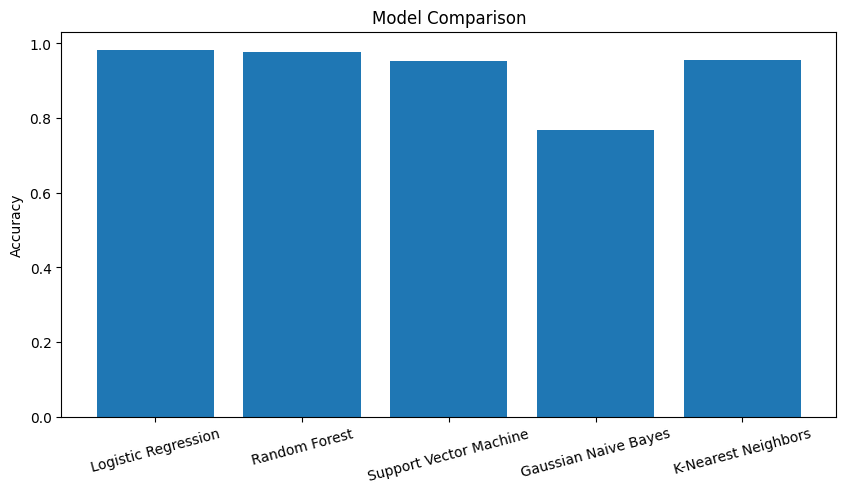
단계2-1 : 정적 동작 세부 분류
- 정적 행동(Laying, Sitting, Standing)인 데이터 추출
- Laying, Sitting, Standing 를 분류하는 모델을 생성
- 몇가지 모델을 만들고 가장 성능이 좋은 모델을 선정
# 정적인 데이터 추출
static_data = data.loc[data['Activity_dynamic'] == 0]
static_data.head()Best Model: RandomForestClassifier with Accuracy: 0.9752704791344667
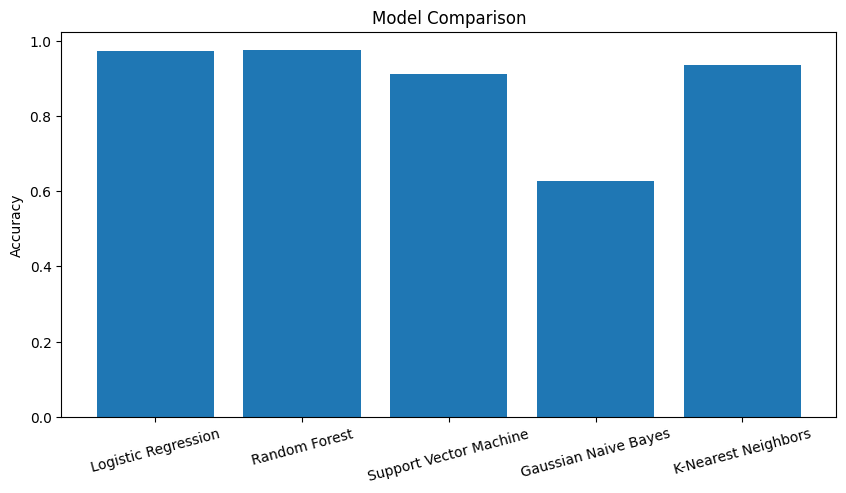
단계2-2 : 동적 동작 세부 분류
- 동적 행동(Walking, Walking Upstairs, Walking Downstairs)인 데이터 추출
- Walking, Walking Upstairs, Walking Downstairs 를 분류하는 모델을 생성
- 몇가지 모델을 만들고 가장 성능이 좋은 모델을 선정
# 동적인 데이터 추출
dynamic_data = data.loc[data['Activity_dynamic'] == 1]
dynamic_data.head()Best Model: LogisticRegression with Accuracy: 0.9905660377358491
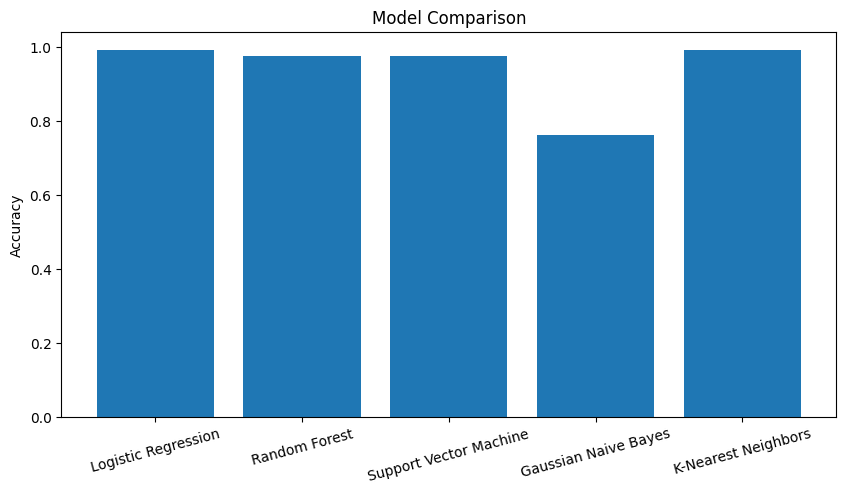
분류 모델 합치기
- 두 단계 모델을 통합하고, 새로운 데이터(test)에 대해서 최종 예측결과와 성능평가가 나오도록 함수로 만들기
- 데이터 파이프라인 구축 : test데이터가 로딩되어 전처리 과정을 거치고, 예측 및 성능 평가 수행
from sklearn.model_selection import train_test_split
import numpy as np
x = data.drop(columns='Activity')
y1 = data['Activity']
y_dynamic = y1.copy().map(lambda x: 1 if x in ['WALKING', 'WALKING_UPSTAIRS', 'WALKING_DOWNSTAIRS'] else 0)
static_indices = y1.isin(['LAYING', 'SITTING', 'STANDING'])
x_static = x[static_indices]
y_static = y1[static_indices]
acting_indices = y1.isin(['WALKING', 'WALKING_UPSTAIRS', 'WALKING_DOWNSTAIRS'])
x_act = x[acting_indices]
y_act = y1[acting_indices]
x_train, x_valid, y_train, y_valid = train_test_split(x, y1, test_size=0.2, random_state=0)
x_train_dynamic, x_valid_dynamic, y_train_dynamic, y_valid_dynamic = train_test_split(x, y_dynamic, test_size=0.2, random_state=0)
x_train_act, x_valid_act, y_train_act, y_valid_act = train_test_split(x_act, y_act, test_size=0.2, random_state=0)
x_train_static, x_valid_static, y_train_static, y_valid_static = train_test_split(x_static, y_static, test_size=0.2, random_state=0)
model_dynamic = RandomForestClassifier()
model_dynamic.fit(x_train_dynamic, y_train_dynamic)
model_act = RandomForestClassifier()
model_act.fit(x_train_act, y_train_act)
model_static = RandomForestClassifier()
model_static.fit(x_train_static, y_train_static)
y_pred_dynamic = model_dynamic.predict(x_valid)
y_pred_act = model_act.predict(x_valid)
y_pred_static = model_static.predict(x_valid)
y_pred_total = []
for i in range(len(y_pred_dynamic)):
if y_pred_dynamic[i] :
y_pred_total.append(y_pred_act[i])
else:
y_pred_total.append(y_pred_static[i])
accuracy_dynamic = accuracy_score(y_valid, y_pred_total)
print(f"Accuracy = {accuracy_dynamic}")Kaggle Competition
짧게 적어보자면..
1. timestamp
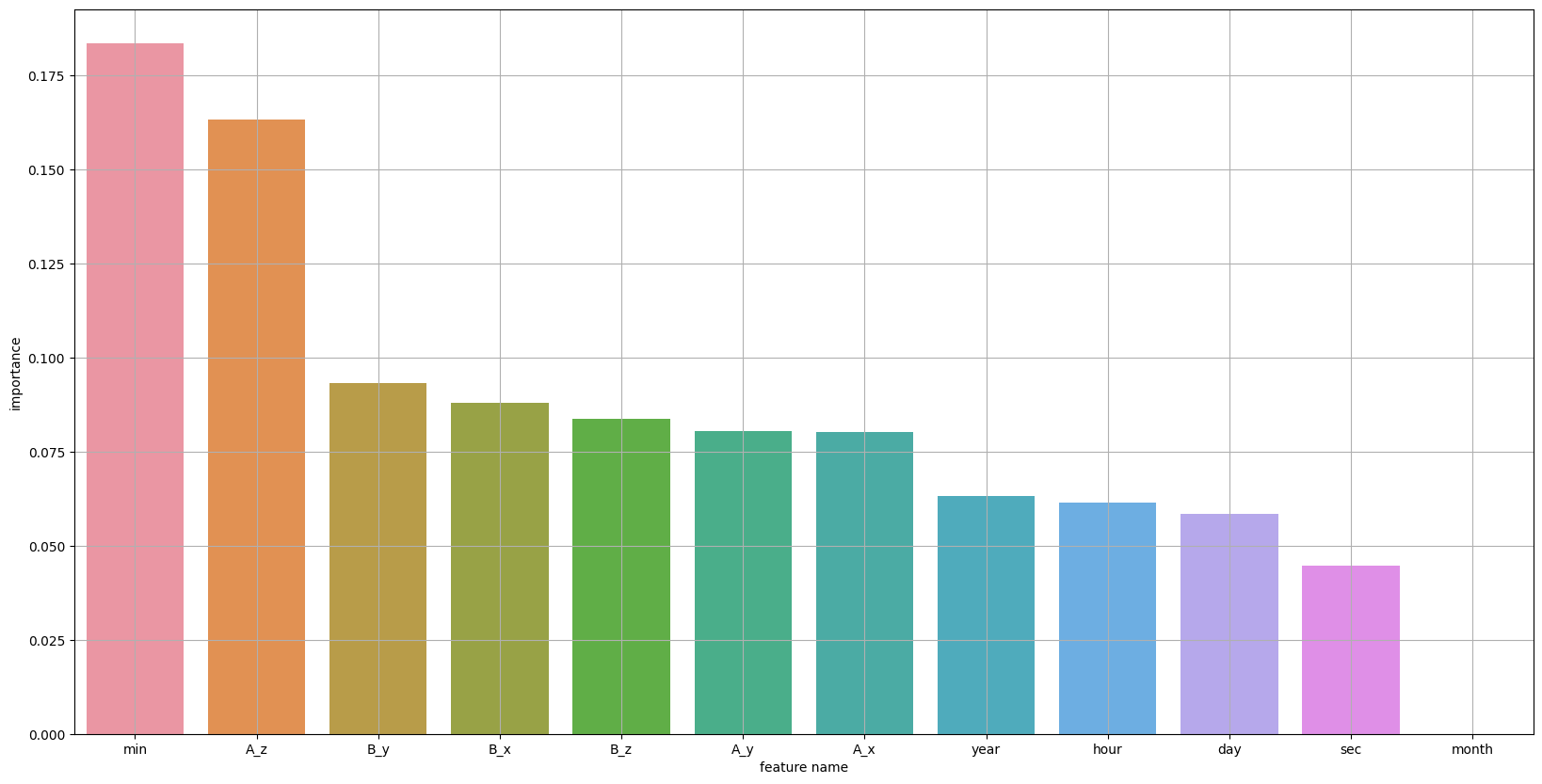
나는 처음 '스마트폰 센서 데이터 기반 인간 행동 인식 분류'에서 timestamp는 그다지 필요 없는 칼럼이라 생각하고 칼럼 자체를 삭제했었다. 삭제하고 모델 성능을 높이려고 아무리 노력해도 다른 사람들의 성능을 따라잡을 수 없었다. 그래서 그럼 timestamp를 한 번 넣어볼까?라고 생각하고, 넣었더니.. 헉!! 성능이 말도 안 되게 높아졌다!! 이것이 이 프로젝트의 사기였음을..
사실 왜 성능이 좋아지는지 잘 모르겠지만, 연도에 따라 사용하는 사람의 수도 많아졌을 수도 있고, 등등의 이유와, 시간대에 따라 직장인들이 앉아있거나, 퇴근 출근 시간대에는 비교적 많이 움직일 테니까, 성능을 높이는데 중요한 feature가 될 수 있었다고 생각한다.
2. 결측치
test 데이터를 확인했을 때, 결측치가 하나도 없어서, 처음에는 결측치를 다 삭제했다. 하지만 성능을 어떻게 조금만이라도 더 올려볼까 고민하다가 각 칼럼의 mean 값으로 넣어봤더니 좀 더 높아진 것을 확인해 볼 수 있었다.
결측치 mean과 모델을 'RandomForestClassifier'이나 'KNeighborsClassifier'을 했을 때, accuracy가 0.9833 정도의 결과가 나왔다.
다른 더 점수가 높은 분들께 여쭤보니 해당 칼럼의 median 값으로 결측치를 채우고, 'LGBMClassifier'를 사용했더니 높게 나왔다고 말씀해 주셨다. 또 다른 분은 결측치를 '스플라인 보간법'을 사용하셨다고 한다. 결측치.. 크게 생각 못 했지만, 이것도 성능을 좌지우지한다는 것을 느꼈다..
🍚 맛집 추천
✔️ 라이라이
- 매일 11:00 - 22:30
- 경기 성남시 분당구 내정로11번길 10-4 1층
- 유니짜장면 8,000
- 등심탕수육 소 23,000
 |  |
|---|
짜장면이 너무 먹고 싶어서, 중국집 어떻냐고 여쭤보니 다들 찬성해 주셔서 다녀왔습니다!
이 집은 탕수육 튀김옷이 찹쌀? 인 것으로 알고 있습니다! 아주아주 맛있습니다!!! 다들 꼭 드세요!! 화붐은 간짬뽕 맛집이지만, 전 짬뽕을 안좋아하는 관계로 이 집에이 제일이네요..ㅎㅎ
짜장면도 아주 맛있고요, 간짜장, 삼선짜장에 계란 프라이도 올라갑니다!! 다들 맛있다고 하시더라고요 ㅎㅎ 이날 제가 속이 안 좋아서, 제대로 못 먹었는데.. 다음번에 다시 또 가봐야겠습니다!
아 사진은... 먹느라 자꾸 까먹어서 주변 분들 나눠드리고, 짜장면 섞으려다 찍었습니다..ㅎㅎ 이제는 같은 팀원 분들이 제 velog를 챙겨주시네요.. 팀원분들 아니었으면 사진도 못 찍었을 거 같아요.. 감사합니다 ㅎㅎ
✔️ 대세신당동즉석쌀떡볶이&양푼이매운갈비찜국물닭발
- 매일 11:00 - 22:30
- 경기 성남시 분당구 불정로77번길 14
- 신당동 즉석 쌀 떡볶이 15,000
- 매운갈비찜 중 33,000
 |  |
|---|
여기 오기 전날, 떡볶이가 먹고 싶어서, 근처에 떡볶이집이 있나 찾던 와중에 떡볶이랑 매운 갈비찜을 동시에 파는 집이 있었습니다! 아침에 팀원들을 보자마자 우리 이 집 가는 거 어떻냐고 여쭤봤는데 다들 흔쾌히 좋다고 해주셔서!! 감사합니다!!
떡볶이보다는 매운 갈비찜이 더 맛있었어요! 저희는 기본 맛을 먹었지만, 매워하시는 분들도 계셨고, 저는 맵지는 않았어요! 다음번에는 이거 큰 거 시켜서 밥이랑 같이 먹고 싶네요 ㅎㅎ 다른 집들보다는 조금 아쉬웠지만...! 그래도 맛있고 배부르게 잘 먹고 왔습니다!
❗마치며
사실 캐글을 진행하는 날, 학교 중간고사 일정이 있어서, 두 시에 조퇴를 했습니다. 하지만 이번에는 개인으로 진행하는 캐글... 50등 안에 너무나도 들고 싶더라고요.. 그래서 서울에서 대전으로 가는 고속버스 안에서 열심히 했지만, 아쉽게도 80등! 너무너무 아쉬웠지만, 캐글 끝나고 다른 분들께 어떻게 진행하셨는지 여쭤보면서, 제가 생각하지 못했던 부분들을 깨달았습니다! 다음번에는 더 잘하고 싶네요! 결측치를 어떻게 채우는지, 어떤 모델을 사용할 건지 정말 깊고 다양하게 생각해 보는 것이 좋을 거 같습니다!
