
📢 6차 미니 프로젝트
⭐ AIVLE School FAQ ChatBot
목표: Aivle School 지원 질문, 답변 챗봇 만들기
0. 배경 및 문제 정의
챗봇의 유용성
- 이용자는 챗봇을 통해 시간 절약, 사용자 경험 개선, 접근성 제고 가능
- 인터넷이 접속되며 시간과 장소에 제약 없이 서비스 이용 가능함에 따라 대기 시간이나 방문시간 절약
- 디지털 서비스.기기의 이용 환경(혹은 사용자 경험) 개선
- 추가적인 앱이나 프로그램 설치 없이 온.오프라인 서비스 이용 가능
- 정보역량에 관계 없이 원하는 결과 획득
- 일상적인 대화 방식으로 쉽게 접근하여 정보 수집 가능
PAIN POINT
Aivle School 지원자들의 단순 반복 문의에 따른 업무 부담 증가
교육 운영담당자는 단순 반복 문의에 따른 업무 피로도 증대, 제한된 시간과 인력으로 인한 응대업무 한계 존재
- 교육 운영담당: 지원자들의 단순 반복 문의에 대해 늘어나고 있어, 업무 효율이 낮고 부담이 크다!
- 교육 지원자: 교육 관련 문의를 위해 메일로 요청했는데, 너무 오래 걸려 답답하다!
1. 데이터 탐색 및 전처리
데이터셋
| 일상대화 | 챗봇데이터 |
|---|---|
 |  |
- 일상대화: 일상적인 질문과 답변
- 챗봇데이터: 에이블스쿨 지원 Q&A
- 두 데이터 셋을 통합하여 사용 → 약 1300여개
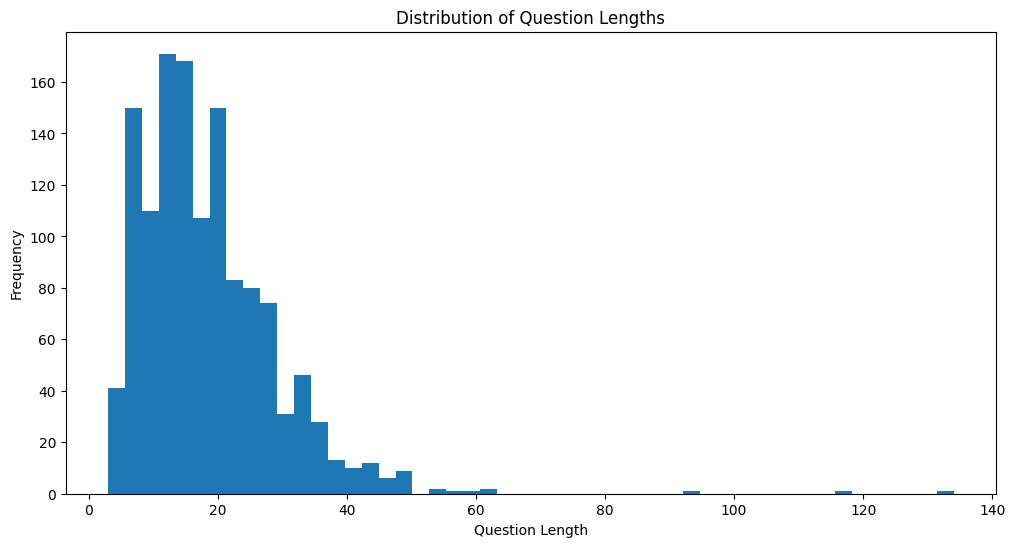
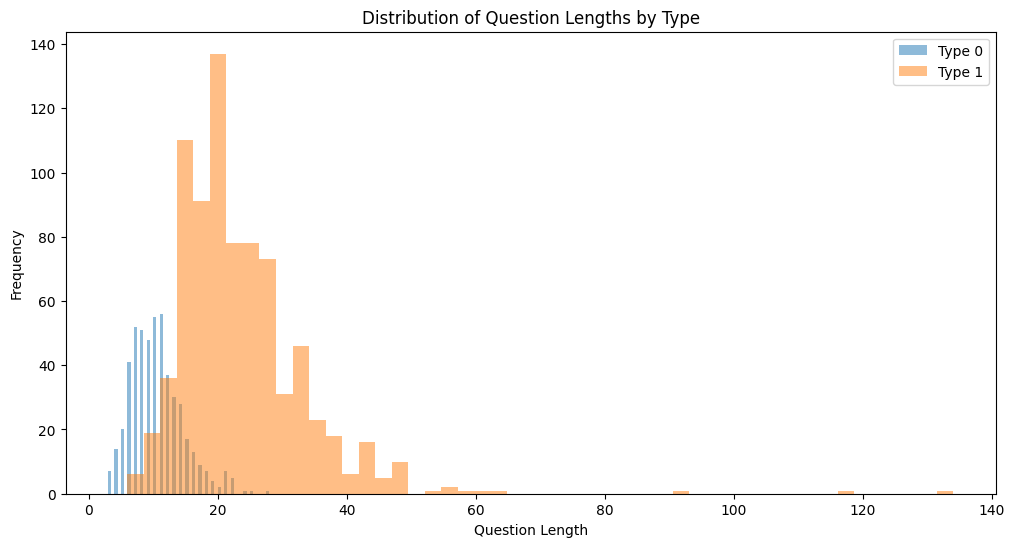
질문 별 문장 길이(글자 수)를 추출하여 분포
 |  |
|---|
- 문장 길이도 상당히 짧다.
- 대부분 60자 이내이고, 평균적으로 18자 정도이다.
- 일상대화를 0, Q&A를 1로 지정 시 일상대화의 경우 평균 10자, 챗봇데이터의 경우 평균 23자 정도이다.
intent
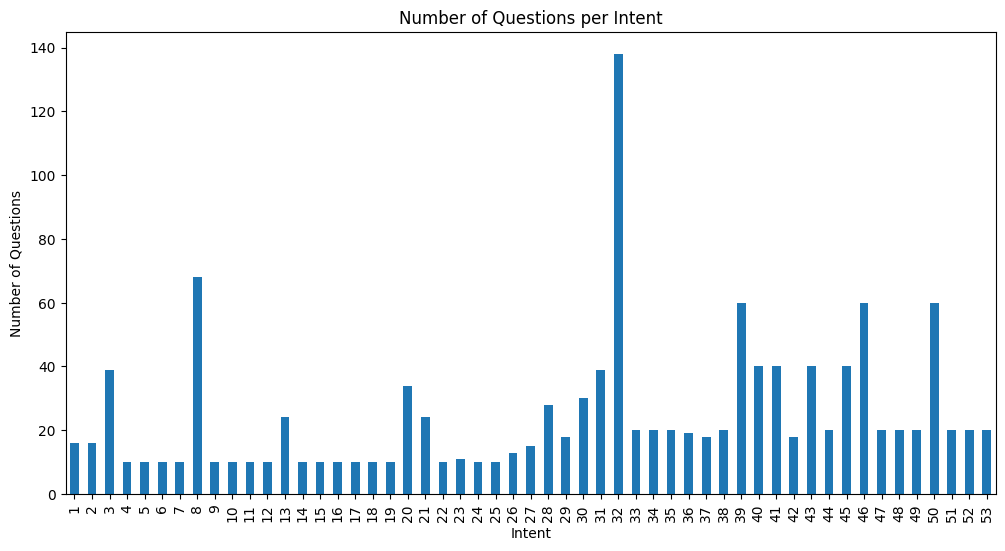
- 30 intent까지가 일상대화에 대한 intent 그 이후는 챗봇데이터에 대한 intent이다.
- 보시다시피, 32 intent가 유독 많은 것을 볼 수 있다.
- 이 부분을 어떻게 해야할지 생각할 필요가 있다.
py-haspell
네이버 맞춤법 검사기를 이용한 파이썬용 한글 맞춤법 검사 라이브러리

- 따라서 A에 대한 Q를 출력해야하다보니, Q와 A에 맞춤법 검사기를 사용하면 좋을 거 같다고 생각했다.
- 데이터의 일관성 - 동일한 의미를 가진 단어나 구문이 다르게 쓰여져 있으면, 이를 통일시킴으로써 모델이 더욱 정확하게 학습할 수 있을 것이라 생각했다.
- 잘못된 정보의 최소화 - 맞춤법 검사기를 사용해 철자나 문장 구조를 수정하기에, 데이터에 포함된 잘못된 정보를 줄일 수 있다고 생각했다.
2. Aivle 스쿨 지원 질문, 답변 챗봇 만들기
챗봇1
Word2Vec을 활용하여 머신러닝 모델링
tokenized_sentences = [sentence.split() for sentence in clean_train.tolist()]
# Skip-gram: 중심에 있는 '타겟' 단어로부터 주변의 '문맥' 단어들을 예측
# CBOW: 주변의 '문맥' 단어들을 가지고, 그 중심에 있는 '타겟' 단어를 예측하는 방식
from gensim.models import Word2Vec
# Word2Vec 모델 생성
wv_model = Word2Vec(
sentences = tokenized_sentences,
vector_size = 100,
window=5,
min_count = 1,
sg = 1
)
# 'train'과 'test' 데이터셋의 'Q' 컬럼에 있는 각 문장을 토큰화
train['Q'] = train['Q'].apply(lambda x : tokenize('mecab', x).split())
test['Q'] = test['Q'].apply(lambda x : tokenize('mecab', x).split())
# 학습 데이터의 문장들을 Word2Vec 모델을 사용하여 벡터화
train_data_vecs = get_dataset(train['Q'], wv_model, 100)
test_data_vecs = get_dataset(test['Q'], wv_model, 100)
# X와 y 데이터 분리
x = train_data_vecs
y = train['intent'].values
# Train-Test split
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=0.2, random_state=42, stratify=y)LightGBM
# LightGBM 분류기 생성
lgbm_model = LGBMClassifier()
# 학습
lgbm_model.fit(x_train, y_train)
lgbm_model.score(x_val, y_val)
# 예측 및 검증
y_pred = lgbm_model.predict(x_val)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_val, y_pred)
print('Validation Accuracy: ', accuracy)
# Validation Accuracy: 0.5188284518828452RandomForest
# RandomForest
from sklearn.ensemble import RandomForestClassifier
# 학습
rf_model = RandomForestClassifier()
rf_model.fit(x_train, y_train)
rf_model.score(x_val, y_val)
# 예측 및 검증
y_pred = rf_model.predict(x_val)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_val, y_pred)
print('Validation Accuracy: ', accuracy)
# Validation Accuracy: 0.46443514644351463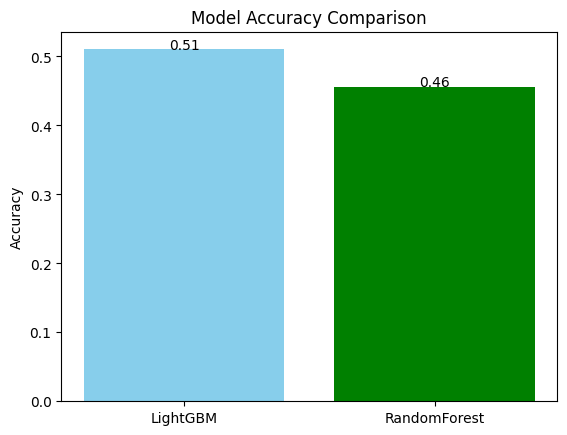
챗봇 함수 만들기
def get_answer1(question):
# token = twitter.morphs(question)
token = tokenize('mecab', question)
input_q = get_dataset([token], wv_model, 100)
answer_list = train.loc[train['intent'] == lgbm_model.predict(temp)[0], 'A'].unique()
answer_prob = train.loc[train['intent'] == lgbm_model.predict(temp)[0], 'A'].value_counts(normalize=True).values
return np.random.choice(answer_list, 1, p=answer_prob)[0]
print(get_answer1('노트북 사양이 어떻게 되나요?'))test 데이터에 대해 성능 측정
성능이 비교적 좋았던 LightGBM 사용
x_test = test_data_vecs
y_test = test['intent'].values
lgbm_model.score(x_test, y_test)
# 0.330188679245283성능이 떨어지는 것을 볼 수 있다..
챗봇2
type 분류 모델링(LSTM)
데이터 준비
# 각각의 토큰에 인덱스 부여하는 토크나이저 선언
tokenizer = Tokenizer()
# .fit_on_texts 이용하여 토크나이저 만들기
tokenizer.fit_on_texts(clean_train_questions)
# 전체 토큰의 수 확인
print("전체 토큰의 수:", len(tokenizer.word_index))
# 전체 토큰의 수가 vocab 사이즈가 됨
vocab_size = len(tokenizer.word_index) + 1 # <PAD> 때문에 +1
print("Vocab size:", vocab_size)
# fit_on_texts을 위에서 한번만 해도 되지만, vocab 사이즈를 확인하고 줄이거나 하는 시도를 할 수도 있기에 다시 수행
# .texts_to_sequences : 토크나이즈 된 데이터를 가지고 모두 시퀀스로 변환
train_sequences = tokenizer.texts_to_sequences(clean_train_questions)
test_sequences = tokenizer.texts_to_sequences(clean_test_questions)
# 각 토큰과 인덱스로 구성된 딕셔너리 생성
word_index = tokenizer.word_index
# <PAD> 는 0으로 추가
word_index = {k:(v+1) for k,v in word_index.items()}
word_index["<PAD>"] = 0
max_len = 30
# pad_sequences 함수를 이용하여 시퀀스 데이터로 변환
train_padded = pad_sequences(train_sequences, maxlen=max_len)
test_padded = pad_sequences(test_sequences, maxlen=max_len)
train['type'].unique()
# array([0, 1])
y_train = train['type']
y_test = test['type']문장별 토큰 수의 탐색적 분석
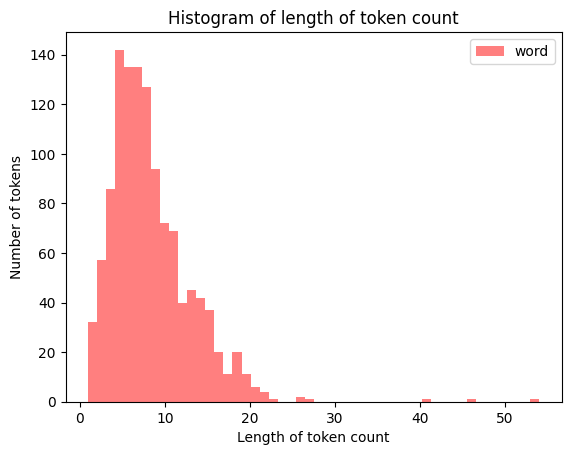
- 문장별 토큰이 가장 큰 것이 57개 입니다.
- 문장이 짧기 때문에 MAX_SEQUENCE_LENGTH는 정하지 않아도 되지만, 그러나 분포를 보고 적절하게 자릅시다. ▶ 30개면 충분할 거 같다!
모델링
토크나이징 한 데이터를 입력으로 받아
Embedding 레이어와 LSTM 레이어를 결합하여 이진 분류 모델링을 수행
# 임베딩 차원 설정
embedding_dim = 128
# LSTM 노드 수 설정
lstm_units = 64
# 모델 구성
dmodel = Sequential()
dmodel.add(Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=embedding_dim, input_length=max_len))
dmodel.add(LSTM(lstm_units))
dmodel.add(Dense(1, activation='sigmoid'))
# 모델 컴파일
dmodel.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델 요약 출력
dmodel.summary()
# 모델 학습
history = dmodel.fit(train_padded, y_train, epochs=10, batch_size=32, validation_split=0.2)
# 예측 수행
predictions = dmodel.predict(test_padded)
# 예측 결과를 0과 1로 변환
predictions = [1 if pred > 0.5 else 0 for pred in predictions]
from sklearn.metrics import accuracy_score
# 성능 평가
accuracy = accuracy_score(y_test, predictions)
print(f'Accuracy: {accuracy * 100:.2f}%')
# Accuracy: 100.00%이번에는 100%!!
도대체 뭐지 싶었다.
FastText 모델 생성
from gensim.models.fasttext import FastText
import gensim.models.word2vec
# 모델 생성
ft_model = FastText(sentences = x_train,
min_count = 1,
vector_size = 100,
window = 5)
x_train = clean_train_questions.apply(lambda x: get_sent_embedding(ft_model, 100, x))
x_test = clean_test_questions.apply(lambda x: get_sent_embedding(ft_model, 100, x))
x_train = np.array(x_train.tolist())
x_test = np.array(x_test.tolist())
y_train_type = train['type'].values
y_test_type = test['type'].values
y_train_intent = train['intent'].values
y_test_intent = test['intent'].values
intent_clf = LGBMClassifier()
intent_clf.fit(x_train, y_train_intent)
intent_clf.score(x_test, y_test_intent)
test_input = train.loc[600, 'Q']
test_answer = train.loc[600, 'A']
temp = tokenizer.texts_to_sequences([test_input])
temp = pad_sequences(temp, maxlen=max_len, padding='pre', truncating='post')
type_pred = dmodel.predict(temp)
type_pred
#1/1 [==============================] - 0s 23ms/step
#array([[0.9997847]], dtype=float32)
# 이미 토큰화된 리스트를 임베딩 벡터로 변환
temp = get_sent_embedding(ft_model, 100, test_input)
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity(temp.reshape(1, -1), x_train).argmax() # 531
def get_intent2(question):
type_input = tokenizer.texts_to_sequences([test_input])
type_input = pad_sequences(type_input, maxlen=max_len, padding='pre', truncating='post')
type_pred = np.round(dmodel.predict(type_input.reshape(1, 30), verbose=0)[0][0])
ft_vecs = get_sent_embedding(ft_model, 100, question)
temp_df = train[train['type'] == type_pred].reset_index(drop=True)
q_vecs = temp_df['Q'].apply(lambda x: get_sent_embedding(ft_model, 100, x))
q_vecs = np.array([list(x) for x in q_vecs])
answer_idx = cosine_similarity(ft_vecs.reshape(1, -1), q_vecs).argmax()
intent_pred = temp_df.loc[answer_idx, 'intent']
return intent_pred
y_pred = [get_intent2(x) for x in test['Q'].tolist()]
accuracy_score(test['intent'].values, y_pred)
# 0.29245283018867924질문에 대한 답변 비교해보기
def get_answer1(question):
token = tokenize('mecab', question)
input_q = get_dataset([token], wv_model, 100)
intent = lgbm_model.predict(input_q)[0]
answer_list = train.loc[train['intent'] == intent, 'A'].unique()
answer_prob = train.loc[train['intent'] == intent, 'A'].value_counts(normalize=True).values
return np.random.choice(answer_list, 1, p=answer_prob)[0], intent
def get_answer2(question):
type_input = tokenizer.texts_to_sequences([test_input])
type_input = pad_sequences(type_input, maxlen=max_len, padding='pre', truncating='post')
# type_pred = np.round(dmodel.predict(type_input.reshape(1, 30), verbose=0)[0][0])
type_pred = (dmodel.predict(type_input.reshape(1, 30), verbose=0)[0][0] > 0.5).astype(int)
ft_vecs = tokenize('mecab', question)
ft_vecs = get_sent_embedding(ft_model, 100, ft_vecs)
temp_df = train[train['type'] == type_pred].reset_index(drop=True)
q_vecs = temp_df['Q'].apply(lambda x: get_sent_embedding(ft_model, 100, x))
q_vecs = np.array([list(x) for x in q_vecs])
answer_idx = cosine_similarity(ft_vecs.reshape(1, -1), q_vecs).argmax()
intent_pred = temp_df.loc[answer_idx, 'intent']
# print(type_pred, answer_idx, intent_pred)
return temp_df.loc[answer_idx, 'A'], intent_predquestion = '에이블스쿨 지원하고 싶어요'
ans1, int1 = get_answer1(question)
ans2, int2 = get_answer2(question)
# ans3, int3 = get_answer3(question)
# print("="*120)
print("질문 :", question)
print("="*120)
print("챗봇1 답변 :", int1, ans1)
print("="*120)
print("챗봇2 답변 :", int2, ans2)
print("="*120)
# print("챗봇3 답변 :", int3, ans3)
# print("="*120)
❗마치며
사실 챗봇2부터는 꽤 어려웠다.
이전에 같은 프로젝트 한 다른 에이블 기수분들의 블로그가 아니였다면 한참 더 헤맸을 거 같다.
그래서 이번에 내 코드를 올린 이유이기도 하다.
내 코드가 좋은 코드다!는 아니지만, 이런코드도 있다!를 보여주고 싶었다.
사실 validation때 0.5넘게 나와서 나름 0.5넘게 나와서 기대를 했는데, test하면 0.3, 심하면 0.2까지 내려가는 것을 보고 너무 어이없고 화가 났다.
다른 분들 보니까 validation때 0.6, test 시 0.4로 내려가신 분도 있다고 들었다.
다들 어쩜 그리 잘하는지...나도 더욱 공부하고 분발해야겠다.
그리고 점점 하면서 느끼는데, 나는 자연어 처리가 나름 재미있는거 같다.
더 잘해보고 싶은데, 어떻게 해야할까?
더욱 찾아보고 공부하는 방법 뿐이겠지만, 다음에는 이 모델을 왜 쓰는지, 어떻게 하며 성능을 더 높일 수 있는지 생각해봐야겠다.
