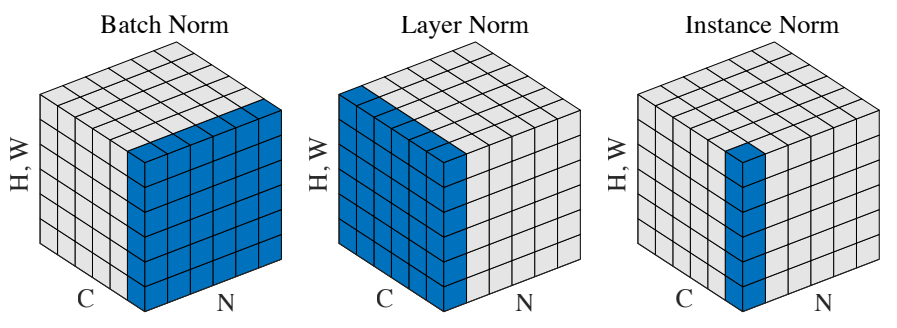
Batch Norm
간략하게 수식에 대한 설명을 하자면 감마는 scale factor이고 베타는 bias factor입니다. 즉 정규화한 sample들에 대해 어느 정도의 scale로 잡아서 어느 위치에 뿌릴지 학습하는 방법이라고 생각하면 될 거 같습니다.

직관적으로 Batch Norm의 학습 파라미터 코드를 살펴보자.
['BatchNorm1d', 'LazyBatchNorm1d', 'BatchNorm2d', 'LazyBatchNorm2d', 'BatchNorm3d', 'LazyBatchNorm3d', 'SyncBatchNorm'] 모두 아래의 _NormBase 코드를 공통적으로 사용한다.
class _NormBase(Module):
"""Common base of _InstanceNorm and _BatchNorm"""
_version = 2
__constants__ = ["track_running_stats", "momentum", "eps", "num_features", "affine"]
num_features: int
eps: float
momentum: float
affine: bool
track_running_stats: bool
# WARNING: weight and bias purposely not defined here.
# See https://github.com/pytorch/pytorch/issues/39670
def __init__(
self,
num_features: int,
eps: float = 1e-5,
momentum: float = 0.1,
affine: bool = True,
track_running_stats: bool = True,
device=None,
dtype=None
) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super().__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
self.affine = affine
self.track_running_stats = track_running_stats
if self.affine:
self.weight = Parameter(torch.empty(num_features, **factory_kwargs))
self.bias = Parameter(torch.empty(num_features, **factory_kwargs))
else:
self.register_parameter("weight", None)
self.register_parameter("bias", None)
if self.track_running_stats:
self.register_buffer('running_mean', torch.zeros(num_features, **factory_kwargs))
self.register_buffer('running_var', torch.ones(num_features, **factory_kwargs))
self.running_mean: Optional[Tensor]
self.running_var: Optional[Tensor]
self.register_buffer('num_batches_tracked',
torch.tensor(0, dtype=torch.long,
**{k: v for k, v in factory_kwargs.items() if k != 'dtype'}))
self.num_batches_tracked: Optional[Tensor]
else:
self.register_buffer("running_mean", None)
self.register_buffer("running_var", None)
self.register_buffer("num_batches_tracked", None)
self.reset_parameters()self.weight = Parameter(torch.empty(num_features, **factory_kwargs))
self.bias = Parameter(torch.empty(num_features, **factory_kwargs))
weigth 와 bias 초기화시 파라미터 차원을 위와 같이 등록합니다. num_features에 대해서 학습 파라미터 감마와 베타를 학습하는 것입니다. Batch Norm의 그림을 보면 알 수 있듯 배치차원에 대해서 채널별로 평균과 분산을 계산하여 감마, 베타를 통해 분포를 정규화합니다. 짐작할 수 있듯, 각 채널별로 서로 다른 베타와 감마가 부여되어야하기 때문에 이미지관련 코드에서 num_features로 channel dimension을 줍니다. 아래는 _NormBase 코드를 상속받아 실제 수행되는 _BatchNorm 코드입니다.
class _BatchNorm(_NormBase):
def __init__(
self,
num_features: int,
eps: float = 1e-5,
momentum: float = 0.1,
affine: bool = True,
track_running_stats: bool = True,
device=None,
dtype=None
) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super().__init__(
num_features, eps, momentum, affine, track_running_stats, **factory_kwargs
)
def forward(self, input: Tensor) -> Tensor:
self._check_input_dim(input)
# exponential_average_factor is set to self.momentum
# (when it is available) only so that it gets updated
# in ONNX graph when this node is exported to ONNX.
if self.momentum is None:
exponential_average_factor = 0.0
else:
exponential_average_factor = self.momentum
if self.training and self.track_running_stats:
# TODO: if statement only here to tell the jit to skip emitting this when it is None
if self.num_batches_tracked is not None: # type: ignore[has-type]
self.num_batches_tracked.add_(1) # type: ignore[has-type]
if self.momentum is None: # use cumulative moving average
exponential_average_factor = 1.0 / float(self.num_batches_tracked)
else: # use exponential moving average
exponential_average_factor = self.momentum
r"""
Decide whether the mini-batch stats should be used for normalization rather than the buffers.
Mini-batch stats are used in training mode, and in eval mode when buffers are None.
"""
if self.training:
bn_training = True
else:
bn_training = (self.running_mean is None) and (self.running_var is None)
r"""
Buffers are only updated if they are to be tracked and we are in training mode. Thus they only need to be
passed when the update should occur (i.e. in training mode when they are tracked), or when buffer stats are
used for normalization (i.e. in eval mode when buffers are not None).
"""
return F.batch_norm(
input,
# If buffers are not to be tracked, ensure that they won't be updated
self.running_mean
if not self.training or self.track_running_stats
else None,
self.running_var if not self.training or self.track_running_stats else None,
self.weight,
self.bias,
bn_training,
exponential_average_factor,
self.eps,
)결국 최종으로 실행하는 코드는 F.batch_norm()입니다. 해당 메서드를 살펴보기전에 Batch Norm1,2,3D 각 각이 요구하는 차원과 실제 num_features를 어떻게 부여해야하는지 살펴보겠습니다.
class BatchNorm1d(_BatchNorm):
def _check_input_dim(self, input):
if input.dim() != 2 and input.dim() != 3:
raise ValueError(
f"expected 2D or 3D input (got {input.dim()}D input)"
)
class BatchNorm2d(_BatchNorm):
def _check_input_dim(self, input):
if input.dim() != 4:
raise ValueError(f"expected 4D input (got {input.dim()}D input)")
class BatchNorm3d(_BatchNorm):
def _check_input_dim(self, input):
if input.dim() != 5:
raise ValueError(f"expected 5D input (got {input.dim()}D input)")모든 차원에 대해서 BatchNorm은 가장 첫번째 차원을 batch차원으로 기대합니다.
BatchNorm1d
input 차원이 2,3이 아니면 ValueError를 출력하도록 설계되어 있습니다. 2차원과 3차원일 경우에 따라 batch norm이 작동되는 방식과 왜 num_features를 channel로 주어야하는지 이해할 수 있습니다. 결국 배치마다 서로 다른 학습 파라미터 감마, 베타를 부여해야하기에 채널의 수를 입력값으로 주게 됩니다.
BatchNorm2d
4차원 입력값이 아니면 ValueError가 발생합니다. 위의 Bact Norm2d 그림에서는 3차원으로 표현되어있지만, H,W가 flatten되어 표현되어 있기 때문에 이해하기 쉽도록 flatten하지 않았을 때 BatchNorm2d를 한번 그려보겠습니다.
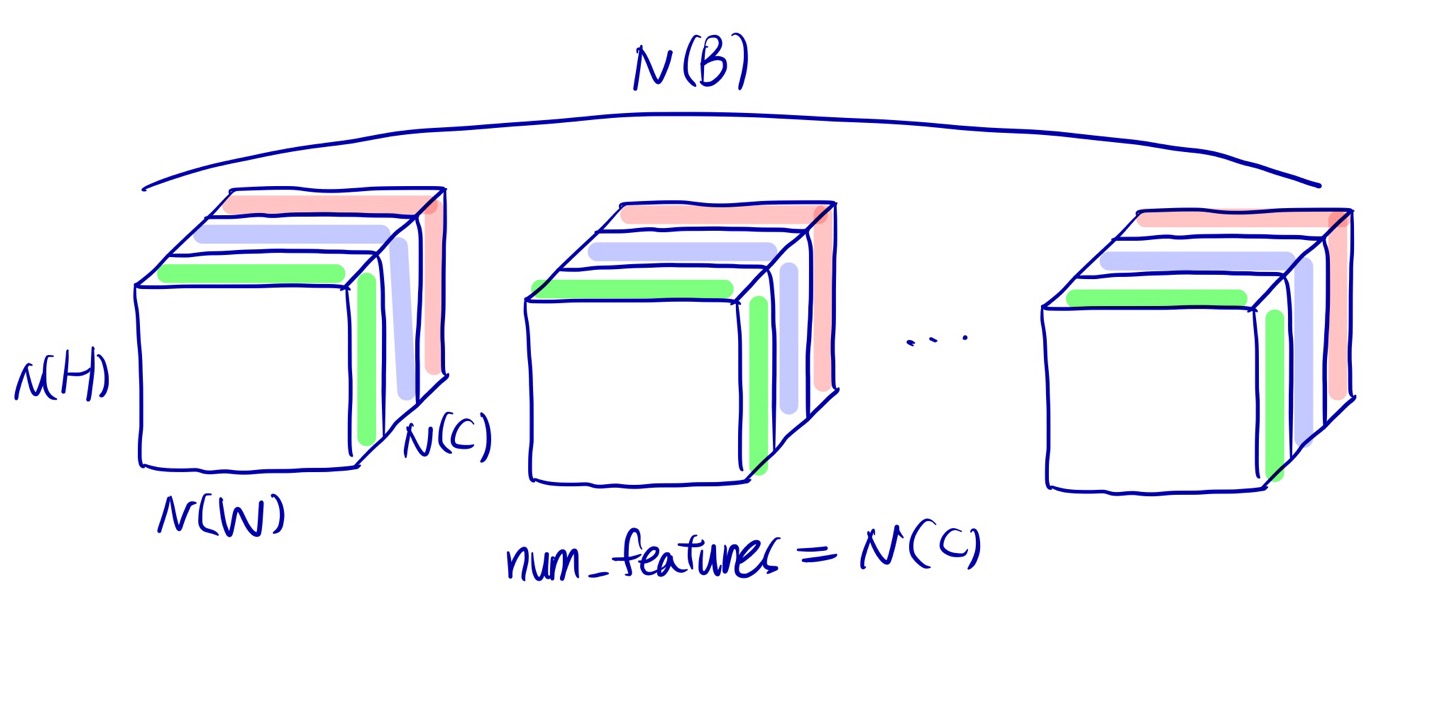
각 채널별로 배치당 모든 이미지에 대해서 normalization을 하는 것을 볼 수 있고 있때 channel에 따라 다른 학습 파라미터를 생성해야하기 때문에 num_features=N(C)가 됩니다.
BatchNorm3d
input 차원이 5차원이길 기대합니다. 5차원일때 Batch Norm을 어떻게 이루어질까요? 이해하기 쉽게 3차원 공간상에서 그려보았습니다.
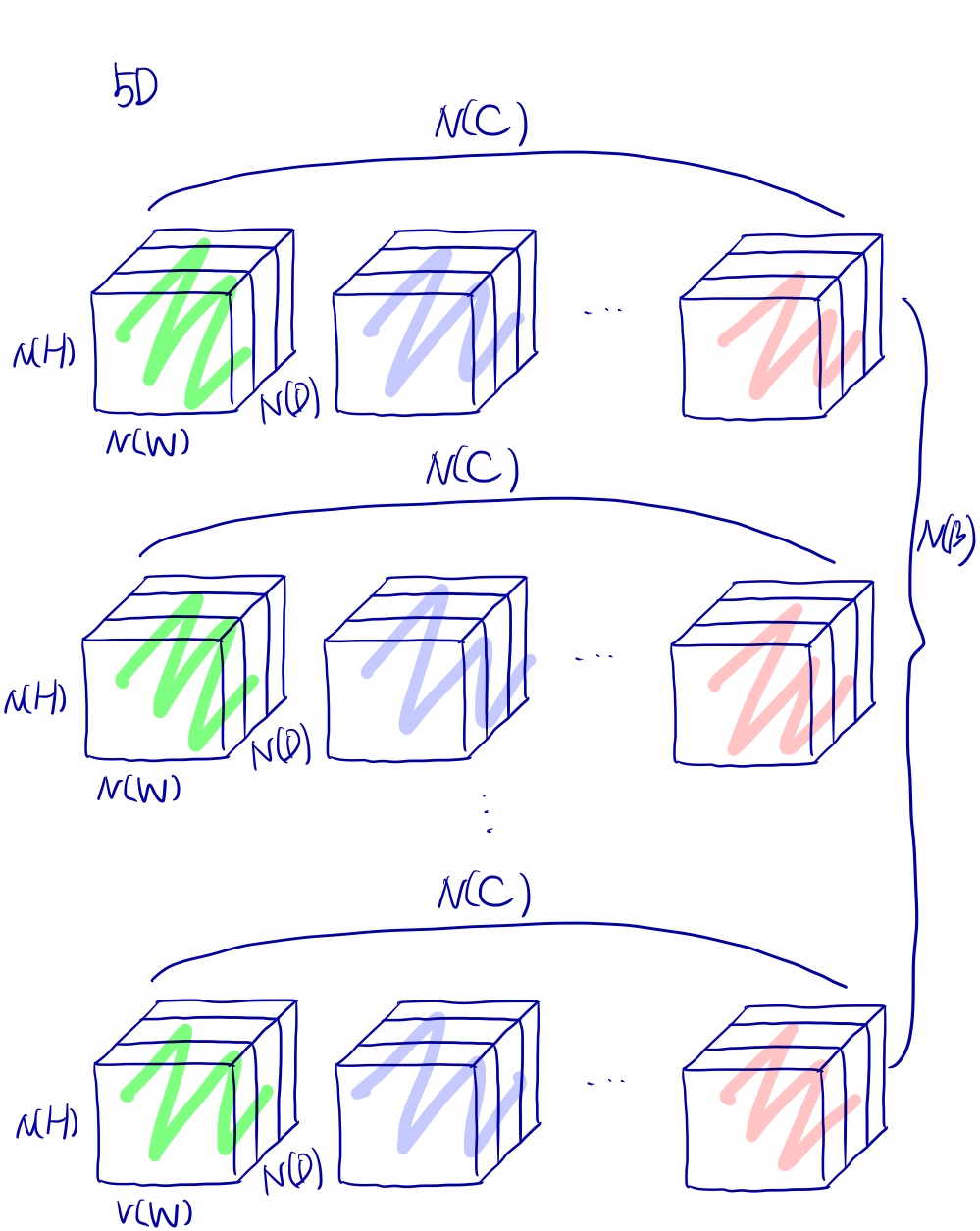
Layer Norm
Layer Norm은 Batch Norm과 다르게 batch에서 완전히 자유롭습니다. 그리고 모든 normalizing sample들에 대해 하나의 파라미터로 학습을 하기 때문에 channel에 대한 정보를 입력해주는 것이 아닌 normalizing size를 입력으로 주며 이에 대한 파라미터로 normalized_shape을 입력값으로 받습니다.
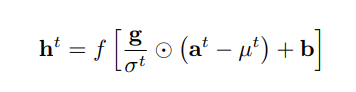
위의 수식(rnn에 적용된 layer norm)에서 g와 b가 학습 파라미터입니다. batch norm과 같은 수식을 나타냅니다. 다만 이 파라미터의 차원은 h의 차원과 완벽히 동일합니다. 그렇기에 layer norm은 벡터 하나에 대해서 각 벡터의 원소별로 어떻게 normalizing을 할 지 학습한다고 볼 수 있습니다. 따라서 입력 차원으로 [∗×normalized_shape[0]×normalized_shape[1]×…×normalized_shape[−1]] 을 받습니다.
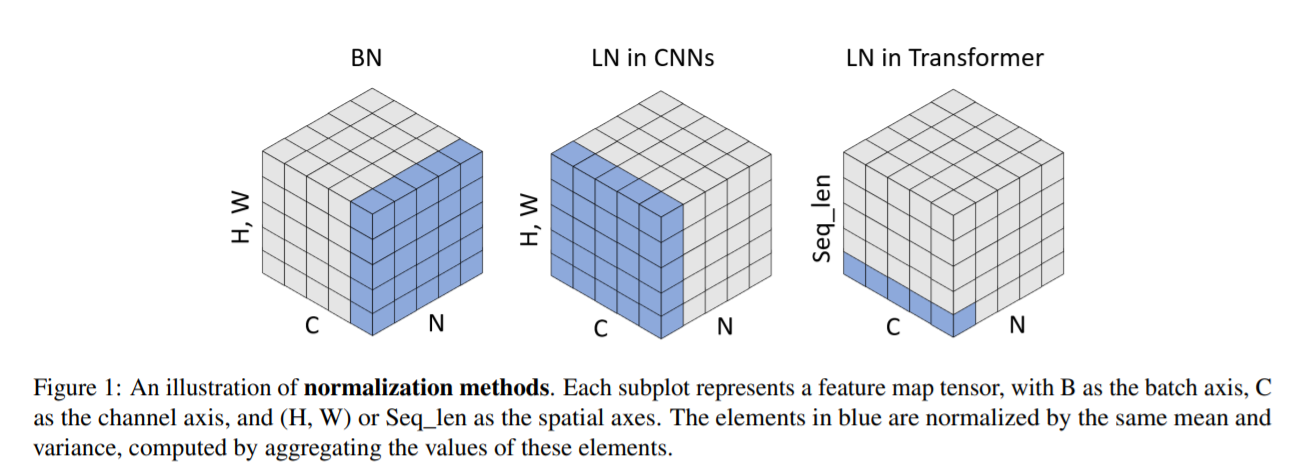
NLP와 Vision 코드를 예시로 보겠습니다.
>>> # NLP Example
>>> batch, sentence_length, embedding_dim = 20, 5, 10
>>> embedding = torch.randn(batch, sentence_length, embedding_dim)
>>> layer_norm = nn.LayerNorm(embedding_dim)
>>> # Activate module
>>> layer_norm(embedding)
>>>
>>> # Image Example
>>> N, C, H, W = 20, 5, 10, 10
>>> input = torch.randn(N, C, H, W)
>>> # Normalize over the last three dimensions (i.e. the channel and spatial dimensions)
>>> # as shown in the image below
>>> layer_norm = nn.LayerNorm([C, H, W])
>>> output = layer_norm(input)NLP에서는 text의 차원이 개,단,차 임으로 layer norm을 적용할 때, 각 단어마다 norm을 하기 위해서 normalized_shape은 각 단어에 대한 임베딩 차원이 됩니다. 이와 다르게 이미지에서 layer norm을 적용하고자 한다면, normalized_shape=[C, H, W]로 줄 수 있습니다. 즉, 이미지 한장에 대해서 normalizing을 진행합니다.

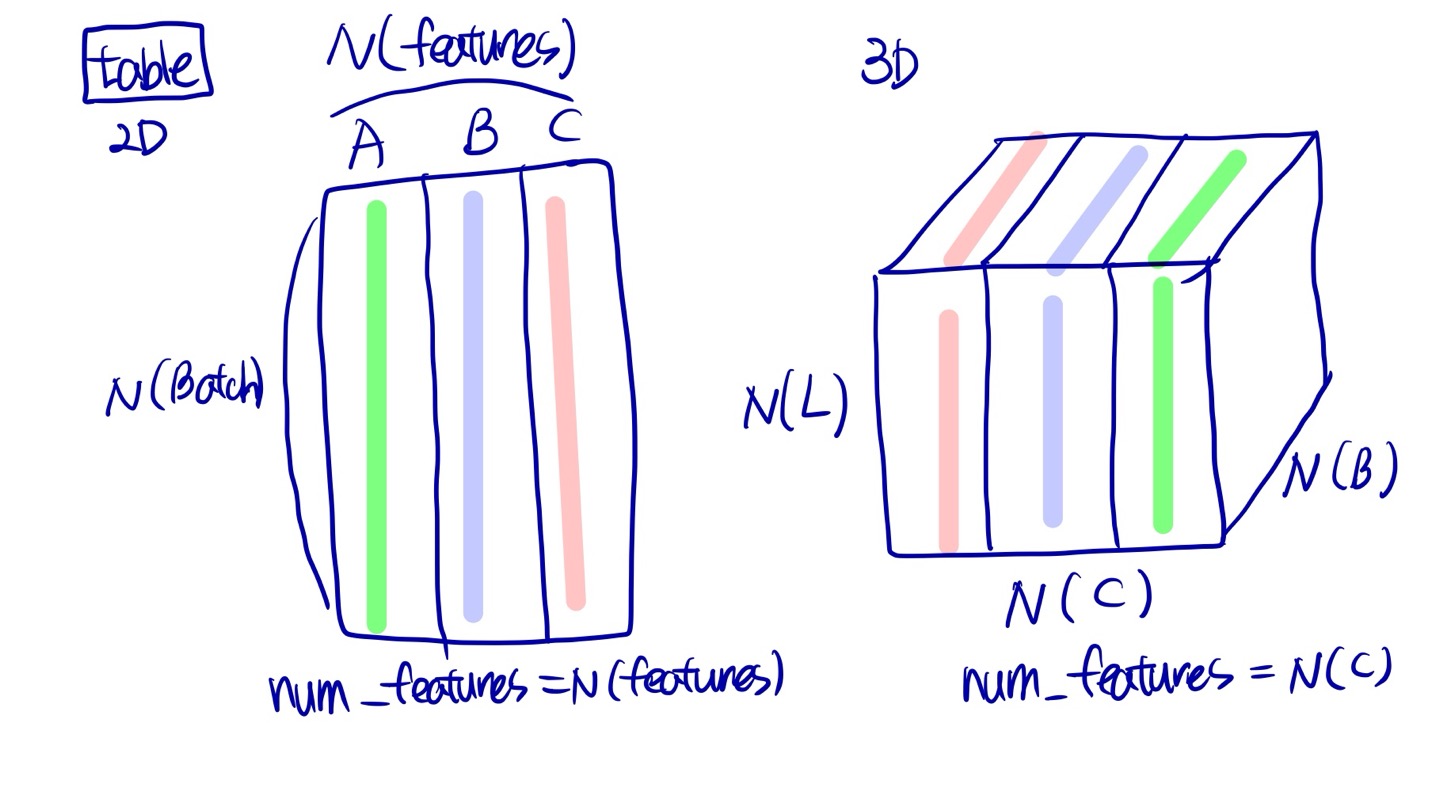
시계열에서도 layer norm을 사용한 경험이 있습니다. 그렇다면 시계열에서는 어떻게 적용될 수 있을 지 살펴보겠습니다. 아래의 그림은 일반적인 samples, num features 테이블 데이터를 transpose 시킨 데이터입니다. 이런식으로 구현하게 되면 결국 layer norm은 각 feature 별로 time에 따라 어떻게 normalize를 해야할지 동일한 파라미터로 normalizing하게 됩니다.
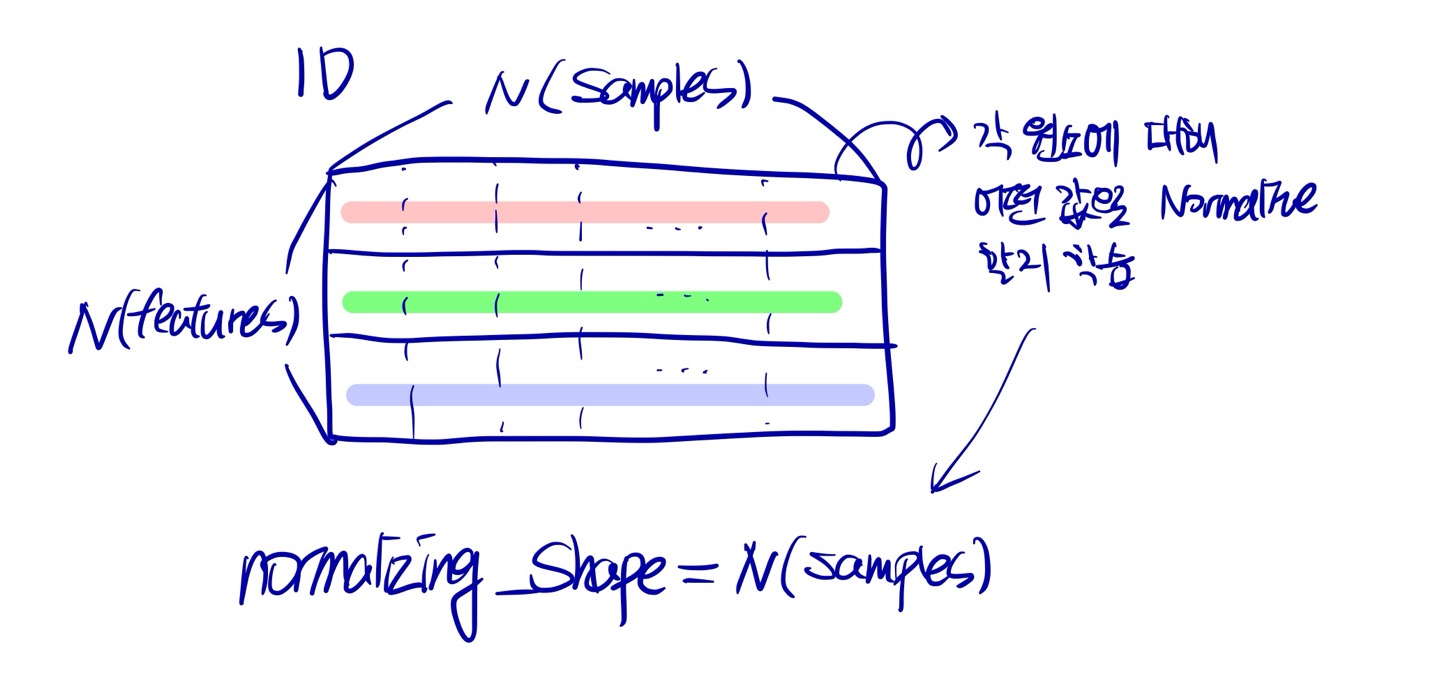
Instance Norm
Instance Norm과 Batch Norm의 차이에 대해 논문에서 서술한 내용입니다.
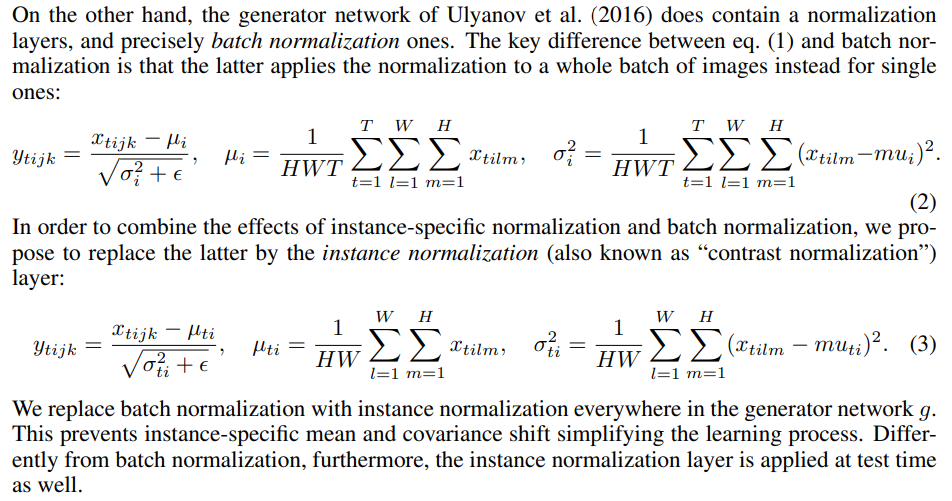
instance norm은 하나의 instance에 대해서 각각 normalizing을 합니다. 여기서도 batch norm과 동일하게 num_features 파라미터를 입력으로 받습니다. 이때, num_features는 여전히 channel에 대한 정보가 들어갑니다. 이는 batch에 대해서 자유로워졌지만 channel을 존중하여 서로 다른 파라미터로 normalizing 하겠다는 의미입니다.
마치 Layer Norm과 비슷해보이지만, 완전히 다릅니다. instance norm을 각 채널별로 파라미터를 개별적으로 설정하여 학습하지만, layer norm은 완전히 같은 하나의 파라미터로 학습하는 대신에 각 원소별로 파라미터가 설정되어 개별적인 요소들을 어떻게 정규화할지를 학습합니다. nlp에 자주 쓰이는 이유가 각 단어에 따라 어떻게 normalizing 해야할 지 학습하기에 적합하며 instance norm을 하게 되면 하나의 단어는 같게 보지만, 각 문장에 들어가는 다른 모든 단어들을 완전히 다르게 normalizing하는 것이기에 문장의 의미가 퇴색될 수 있습니다.
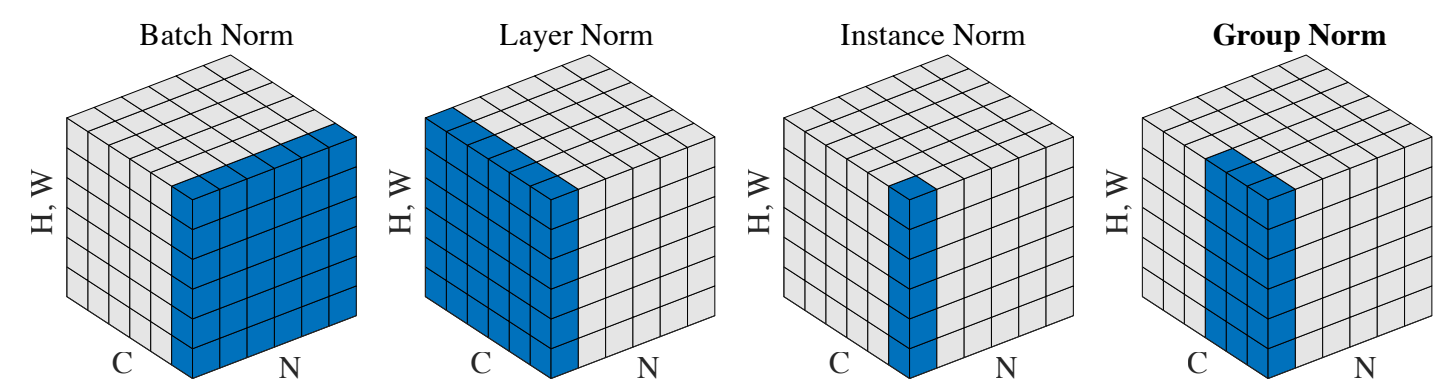
Group Norm
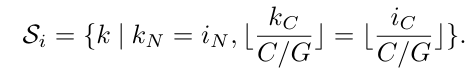
Group Norm은 channel에 따라서 group을 나누어서 normalize 합니다. 감마와 베타는 group channel별로 학습합니다.
>>> input = torch.randn(20, 6, 10, 10)
>>> # Separate 6 channels into 3 groups
>>> m = nn.GroupNorm(3, 6)
>>> # Separate 6 channels into 6 groups (equivalent with InstanceNorm)
>>> m = nn.GroupNorm(6, 6)
>>> # Put all 6 channels into a single group (equivalent with LayerNorm)
>>> m = nn.GroupNorm(1, 6)
>>> # Activating the module
>>> output = m(input)참고자료
- Wu, Yuxin, and Kaiming He. "Group normalization." Proceedings of the European conference on computer vision (ECCV). 2018.
- Yao, Zhuliang, et al. "Leveraging batch normalization for vision transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
- Ba, Jimmy Lei, Jamie Ryan Kiros, and Geoffrey E. Hinton. "Layer normalization." arXiv preprint arXiv:1607.06450 (2016).
- Ulyanov, Dmitry, Andrea Vedaldi, and Victor Lempitsky. "Instance normalization: The missing ingredient for fast stylization." arXiv preprint arXiv:1607.08022 (2016).
- https://discuss.pytorch.org/t/why-2d-batch-normalisation-is-used-in-features-and-1d-in-classifiers/88360/4
