
사진은 LG Aimers 2기 수상 사진으로 넣어보았다. (사실 이때가 그립기도 하다..)
일정은 아래와 같이 진행되었다.

Material Inteligence Lab 김기영님
- Drug Generative Model
- VAE로 학습된 Chemical Latent Space에서 원하는 물성을 가진 분자 생성 가능
1-1. VAE를 통해 약물의 latent space학습 // 이 부분이 최선일까??
1-2. Evolutionary Alogo으로 latent space 최적화
1-3. DMPNN기반 효능 예측 모델 개발(GNN)
Question) 현재 어떤 방식으로 풀어내고 있는지?
- Personalized Nanceer Vaccine
맞춤형 항암 백신 개발
화학항암제 -> 표적항암제 -> 면역항암제(자자면역을 이용해보자!!)
면역세포에 미리 항원을 넣어주어 항체를 생성할 수 있도록 하는 것
- IEDB
T세포 활성, MHC-peptide 결합 실험에 따른 결과 데이터
AAindex + BLOSUM matrix
MHC contextual한 정보가 필요 => LLM 을 활용하였음
facebook ESM 모델
Petide를 self-attention한 query로 주고 MHC는 cross-attention을 통해 key, value로 주었음
Q1. LG AI가 제안한 네트워크가 잘 적용되었던 이유는?
A1. 정보량의 차이로도 key, query, value에 따른 overlap이 될 수 있다는 점.
MHC 같은 경우 정보량이 중복되고 길이가 아주 길기 때문에 peptide에 대한 정보가 뭍힐 수 있었음.
이를 단순히 바로 반영해주는 것도 꽤 좋을 수 있다?! 따라서 정보의 중복성이 낮은 경우 self-attention을 적용하고 정복의 중복성과 양이 많은 경우 그냥 cross-attention으로 간단하게 반영해주는 것이 답일 수 도 있음.
추가 느낀점 (24.05.16)
Improving Diffusion Models for Authentic
Virtual Try-on in the Wild
해당 논문은 virtual try-on 주제의 논문이다.
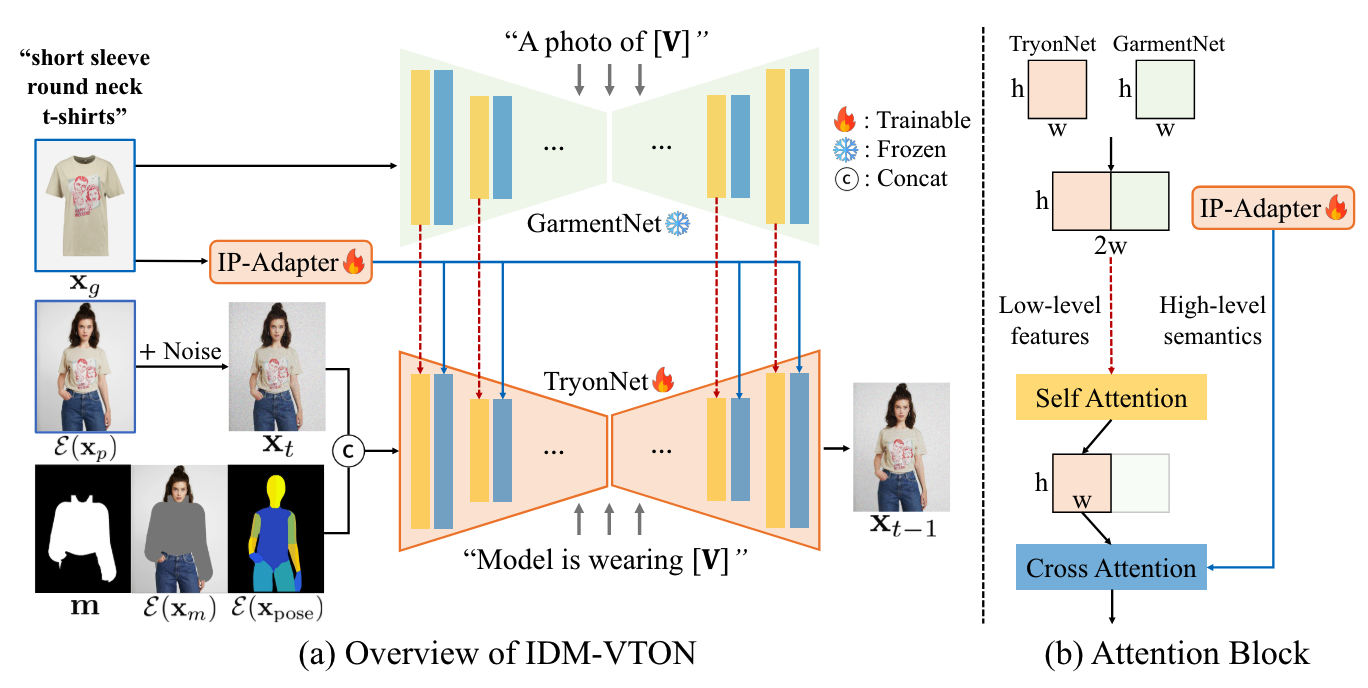
해당 논문의 구조를 보면 Self-attention과 Cross-attention 의 역할을 Q&A를 복기하며 명확히 이해할 수 있었다. 그리고 feature를 concat 해준 것 또한 원형의 feature를 그대로 반영해줄 수 있기에 구조를 잘 설계했다고 느꼈다.
생성 모델을 활용함으로서 시간 단축이 화두임
Domain 지식이 중요함
Multimodal Lab 송광모님
Image Generation/ Understanding
- Computer Vision
- Deep Document Understanding
- VIsion Inspection (공장 자동화)
- EXAONE (초거대 모델 vision 파트, vision 관련 초거대 모델)
- Medical Data Analysis
-
Multimodal Model (Vision Language Multimodal Model)
Image - Text -
Image Generation
DALLE-3, Stable DIffusion 3 -
Imgae Understanding
GPT-4V, LLaVA
- 현재 생성형 AI가 산업 현장에 바로 적용할 수 있을까?
1. 보안 이슈 등으로 Data 공개에 폐쇄적
2. 업종 특성상 Digital Data 축적 부족
3. 어떤 Data를 믿고 적용?
--> 저작권 이슈가 없는 데이터를 학습하자!!
-
Text to Image Generation
- EXAONE LMM -> Diffusion Model -
Image to Text Generation (Image Captioning)
- 이미지 -> caption -> key-word
- Image & Text 정보를 동시에 입력 받는 LMM(Large MultiModal)
Q1. 이미지 캡셔닝 LLM 답변 생성, 감성적 키워드 생성 => 기술적으로 어떻게?
A1. 학습할 때 사람의 주관을 많이 포함한 데이터를 많이 사용하고 있음
Q2. Zero-shot sider로 평가한 이유는?
A2. 정성적으로 평가하여 Sider를 선택하여 평가하였음, 실제 평가시에는 정성적인 것을 더 중요하게 사용함
GPT Evalution을 사용함
Q3. Conditional Image Generation 기술은 무엇인지? Sora와 유사한지?
A3. 같은 결의 모델이라고 생각하면 될 것 같음, 사용자가 입력한대로 출력되지만, Preset을 정해놓고 출력하도록 되어 있음
Q4. 할루시네이션을 어떻게 관리하는지? Rule-base로 해결하는지?
A4. End-user를 계열사로 두고 있기에 아이디에이션을 목표로 사용하고 있음
Q5. Text-to-Image에서 정성적인 평가를 우선시 하는지?
A5. Lower boundary는 정량적인 것을 두고 나머지는 정성적으로 평가함
Data Inteligence Lab 안원빈님
시계열 다루는 일을 많이하심
Demand Forecasting
The Bullwhip effect로 인해 예측하기 어려움
Clients -> Distribution Center -> Regional Hub -> Production Facility -> Supplier
- 어떻게 접근해야할까??
Key
Pricing, Promotions, Shortages
Inventory가 Sales를 쫓아가지 못했을 때 Shortages가 발생함
--> 어떻게 적정선을 찾으면 좋을까????
예측을 한다고 하면 예측 오차로 측정, 과연 예측 오차를 잘 따라가면 잘 예측하는걸까??
-
Evalution
RPS (Ranked Probability Score)
IR (Information Ratio) -
ETF "LQAI"
LAIR-Forcesting
LAIR-Rank
LAIR-Portfolio
간단하게 정리하면 3번째 세션 Data Inteligence Lab이 가장 좋았고, 몇 가지 포인트를 정리하면
1. LLM based Forecasting
Q. Time Series에 왜 LLM이 잘 적용되었을까?
A. 관점에 따라 해석이 달라질 것 같다. 단순한 임베딩으로 사용했다고 볼 수 있지만, 여기서는 LLM을 뜯어보라는 것이 아닌 어느 위치에서 LLM을 잘 사용할 수 있을 지 고민해보면 좋을 것 같다. 결국 LLM이 가지고 있는 기반 지식이 있고 이를 에이전트화 한 것.
Q. TimeLLM을 적용할 때, 경험적으로 어떤 부분이 중요했는지? Knowledge를 활용하는 부분들.
A. LLM이 지금 다루고 있는 정보들을 잘 반영하는가? 정보를 다 쓰고 있는가? LLM이 잘 동작하고 있는지를 살펴보면 좋을 것 같다.
Q. Shock이 발생했을 때 어떻게 잘 예측을 할 수 있는지? 경제학도로서 경제학적 지식을 왜 bias라고 생각하고 적용하지 않는지?
A. 데이터와 모델 환경에서만 제대로 작동할 수 있어야만, 사람이 더 이상 개입하지 않을 수 있기 때문임. 초반에는 사람이 건드릴 수 있지만 결국 이는 학습한 모델의 가중치와 이전 학습 모델에서 계속된 변형(오염)이 일어날 수 있음.
2. Time series Forecasting 몇 가지 주요 포인트
- Distribution Shift
Train 과 Test가 맞지 않음, Out of distribution - Known Input
미래에 알고 있는 것들을 반영한다는 뜻임. “여러분들은 강의가 끝나면 밥을 먹고 집을 가고 저녁에는 잘 것이다.” 이는 예측을 잘 한 것인가? 우리는 이미 미래의 정보를 많이 알고 있다. - Causality
인과성 - Multi-Modal Forecasting
Image, Video, Text, Audio… 과연 우리는 예측에 필요한 정보를 전부 사용하고 있는가? 진정 예측을 위해 데이터를 모두 적합하게 사용하고 있는지 질문을 던져보아야할 시간이다.
3. 사용자를 위한 Forecasting 관점
- Probability Forecasting
수치 하나를 예측하기 보단 확률적으로 유의미한가? - Hierarchical Forecasting
계층적인 형태를 띄는 시계열일 경우 이를 잘 반영해서 예측할 수 있는가?
4. The Future of Forecasting
- Multimodal (모든 형태의 데이터)
- Known Inputs (미래 알고 있는 미래의 정보가 반영)
- Distribution Shift (변동의 속성도 파악)
- Causality (변동의 원인도 설명)
- Probabilistic forecasting (예측에 대한 모델의 신뢰도를 알 수 있음)
- Hierarchical forecasting (상/하위 단계)
- Human Interaction (전문가와 대화를 통해 점점 개선)
-> Zero-shot으로. => Foundation!!
- TEMPO: Prompt-based generative pre-trained ~
- AdaRNN, https://arxiv.org/pdf/2108.04443)
The Future of Forecasting

- 마지막 Question
예측이 정확해야 할까요?
그냥 정확하면 될까요???
항상 맛있는 도시락을 주신다!!

LG Aimers 3기때 사진도 넣어보려한다ㅎㅎ


LG Aimers 2기때 사진도 추가해봤다!!


