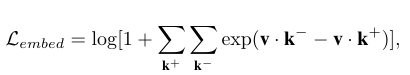[Paper Review] GLEE: General Object Foundation Model for Images and Videos at Scale (2024)
Paper I should read
Motivation
NLP에서는 foundation models이 많이 나오고 있으나 Vision 분야에서는 task types의 다양성과 통합된 형태의 부재로 foundation models는 오직 특정한 subdomains만 다룬다.
그러나 객체를 찾고 식별하는 것은 컴퓨터 비전 시스템에서 기본적인 능력을 구성하며, 세분화, 장면 이해, 객체 추적, 이벤트 탐지 및 활동 인식과 같은 복잡하거나 고급 시각 작업을 해결하는 기초로서 다양한 응용 프로그램을 지원하는 상황이다.
따라서, GLEE에서는 vision domain에서 object-level foundation models를 개발하였다.
통합된 입력 및 출력 패러다임 정의를 통해 다양한 데이터로부터 학습하고 일반적인 객체 표현을 예측할 수 있으며, 제로샷 방식으로 잘 일반화하고 높은 성능을 달성하였다.
A general object foundation model framework
image encoder, text encoder, visual prompter를 multi-modal input으로 통합한다. 통합된 input을 디코더로 전달하여 multiple modalities를 object-centric tasks를 동시에 해결할 수 있다.
A multi-granularity joint supervision and scaleable training paradigm
통합된 프레임워크는 multiple tasks를 다루는데 joint training을 가능하게 한다. 추가적으로 비디오 데이터는 시간적 일관성을 향상시키고, open world 데이터는 클래스에 구애받지 않는 오브젝트 주석을 추가하였다.
Strong zero-shot transferability to a wide range of object level image and video tasks
학습 과정을 거친 후 GLEE는 탁월한 일반화와 zero-shot 능력을 보여준다.
Related Work
Visual Foundation Model
SAM과 같은 객체를 점이나 박스 같은 시각적 단서를 기반으로 분할하는 object information은 객체를 특정하고 이미지 내에서 객체를 명확히 식별하며 구분하는데 유용하다.
그러나, 이 정보에는 semantic context(의미적 맥락)이 부족하다. 객체를 효과적으로 분리하고 식별할 수 있지만, 그 객체가 어떤 상황에서 어떻게 사용되는지, 주변 객체들과 어떻게 상호작용하는지 등의 배경적인 의미를 충분히 포함하지 않는다는 문제가 있다. 이는 객체 정보가 단지 시각적인 특성과 위치 정보에 초정을 맞추고 있음을 의미하며, 이러한 정보만으로는 보다 복잡한 인지적이나 인지적이나 상황적 작업을 수행하는 데 한계가 있다.
본 연구에서는 object-level에서 의미적 맥락을 충분히 파악하여 더 이상 추가적인 파라미터나 파인 튜닝 없는 foundation models를 만들고자 한다.
Unified and General Model
unified models는 foundation models과 multiple vision 또는 단일 모델에서 multi-modal tasks를 처리할 수 있다는 점에서 multi-task unification 측면에서 유사하다.
-
Unified model: 여러 다른 종류의 작업을 하나의 모델로 처리할 수 있도록 설계된 모델이다.
-
Foundation model: 대규모의 데이터에서 학습된 큰 규모의 모델을 의미한다.
GLEE는 object-level tasks에서 unified하고, universal object representations를 제공하여 새로운 데이터와 tasks를 일반화하여 구체적인 object information을 요구하는 tasks에 초석 역할을 할 수 있다.
Vision-Language Understanding
language-based detectors는 언어 모델의 능력과 편향에 의해 localization과 recongnition에 큰 제약을 준다.
GLEE는 objects를 detect하고 identify 할 뿐만 아니라, downstream tasks를 위해 universal object represenations를 제공한다.
Method
-
Text Encoder
object categories
name: 객체와 관련된 구체적인 이름이나 명칭, free form
caption: 객체에 대한 설명이나 주석
expression: 특정 객체를 지칭하거나 설명하는 표현 -
Visual Prompter
points: 이미지 상의 특정 위치를 나타내는 점
bounding boxes: 객체를 둘러싸는 직사각형 영역
scribbles: 객체의 경계를 대략적으로 그리는 자유형 선
이러한 입력들은 시각적 정보와 텍스트 정보가 통합되어 이미지 객체를 추출하는 디텍터에 입력된다.
-
Image Backbone
(3, H, W)로 이미지가 주어지면, ResNet을 통해 multi-scale features Z로 추출한다.
-
Object Detector
object embedding과 text embedding의 유사도를 측정하는 dynamic class head를 가진 MaskDINO 모델을 기반하였다.
Image Backbone에서 추출된 features Z는 object decoder와 (classification, deteciton, segmentation) 3가지 prediction heads로 전달하여 output embedding는 (N, C)가 된다.
object segmentation은 백본과 트랜스포머 인코더로부터 얻은 다양한 스케이르이 특징 맵을 업샘플링하고 fusing하여 1/4 resolution pixel embedding map을 구성한다.
N mask embeddings와 pixel embedding map을 dot product하여 binary mask prediction 을 얻는다. 여기서 FFN은 3-layer feed forward head with ReLU activation func and a linear projection layer이다.
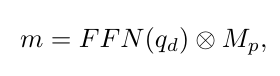
GLEE에서는 임의의 어휘와 객체 설명을 지원하기 위해 FFN 분류기를 텍스트 임베딩으로 대체하였으며, DetCLIP을 따른다. 구체적으로, K 카테고리 이름을 별도의 문장으로 텍스트 인코더 에 입력하고, 각 문장 토큰의 평균을 출력 임베딩 로 사용한다. 그 다음 객체 임베딩과 텍스트 임베딩 사이의 정렬함 를 계산한다.
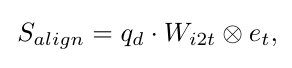
여기서 는 image-to-text projection weights이다.
Task Unification
GLEE는 object detection, instance segmentation, grounding, multi-target tracking (MOT), video instance segmentation (VIS), video object segmentation (VOS), interactive segmentation and tracking, 그리고 supports open-world/large-vocabulary image and video detection and segmentation tasks를 통합한다.
Detection and Instance Segmentation
Detection: 고정된 길이의 카테고리 목록이 제공되며, 목록의 모든 객체를 감지해야 한다. 텍스트 input으로 각 카테고리 이름이 입력값으로 주어진다.
Instance Segmentation: mask 일치에 따라 손실을 추가함
-
Grounding and Referring Segmentation
text expression을 참고함
-
MOT and VIS
VIS는 추가적인 mask가 필요함
-
Visual Prompted Segmentation
점, 박스, 스크리블과 같은 다양한 형태의 시각적 프롬프트를 사용하여 이미지 내 지정된 객체를 분할한다.
VOS: 비디오의 첫 프레임에서 제공된 마스크를 바탕으로 전체 비디오를 통해 전체 객체를 분할하는 것을 목표로 한다.
Training Unification
각 task별로 맞는 loss를 사용하였다.
video의 경우 따로 아래의 수식을 통해 학습한다.