Paper I should read
1.[Paper Review] Point Transformer (2021) (1/2)
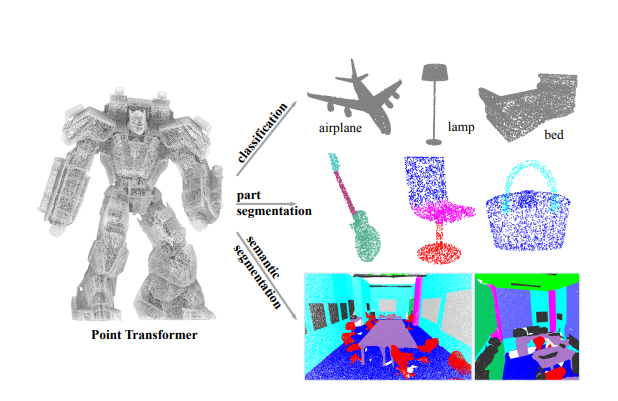
Point Transformer
2.[Paper Review] Point Transformer (2021) (2/2)

Transformer
3.[Paper Review] Text Is MASS: Modeling as Stochastic Embedding for Text-Video Retrieval (2024)

기존 데이터셋에서 텍스트 콘텐츠는 일반적으로 short and concise하므로, 비디오의 the redundant semantics을 완전히 설명하기 어려움.\--> A single text embedding은 비디오 임베딩을 포착하고 검색 기능을 강화하는 데 있어
4.[2D Feature Descriptor] HoG, SIFT 정복하기

Feature Descriptor에 대해서 살펴보자
5.[Model Fitting] RANSAC 알고리즘
RANSAC이 왜 필요한지 살펴보자.
6.[3D Point Feature Descriptors] PFH, FPFH 정복하기
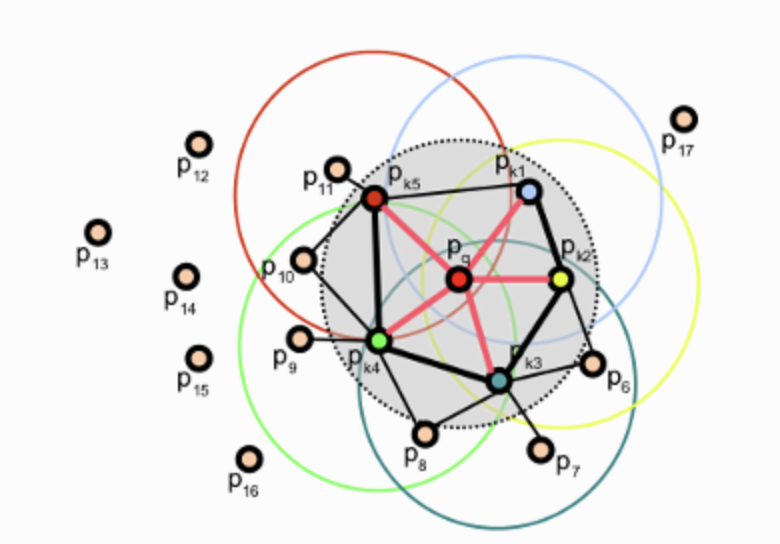
Point Feature Histograms(PFH)와 Fast Point Feature Histograms(FPFH)를 살펴보고자 한다.
7.[Paper Review] Real3D-AD: A Dataset of Point Cloud Anomaly Detection (2023) (1/2)
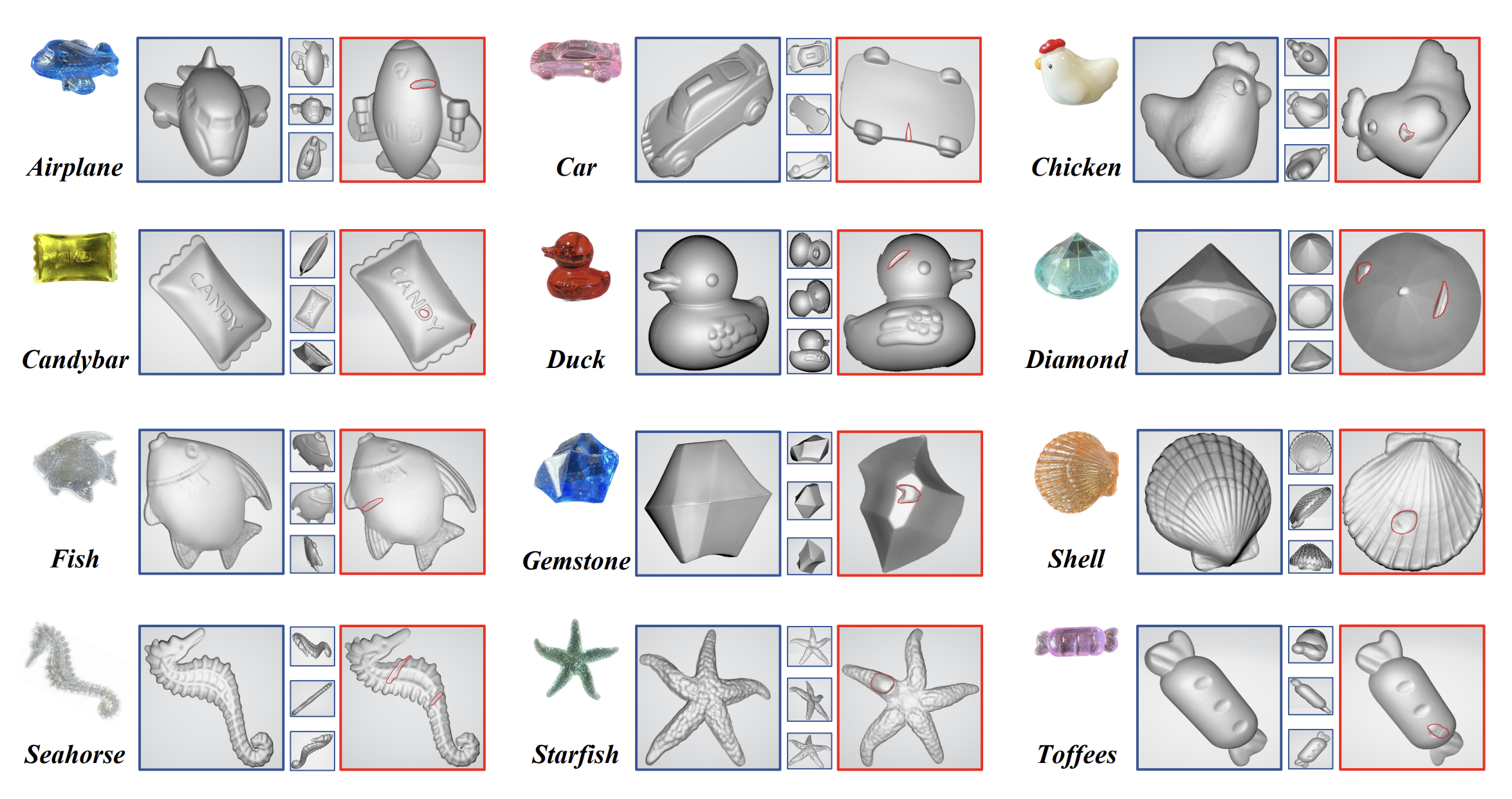
Real3D-AD 논문을 리뷰하고자 한다.
8.[Code Review] Real3D-AD: A Dataset of Point Cloud Anomaly Detection (2023) (2/2)
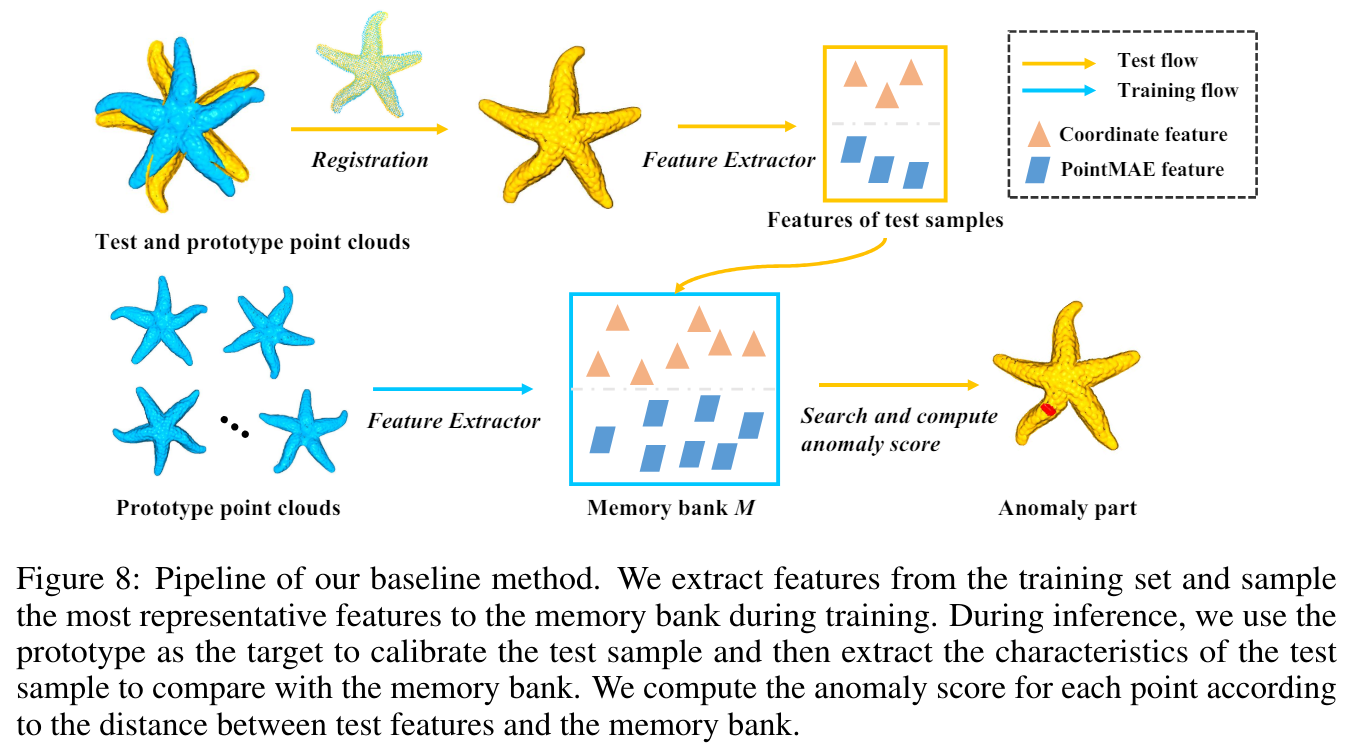
Real 3D-AD에서 제안한 reg3dad 코드를 리뷰하고자 한다.
9.3D 정복기
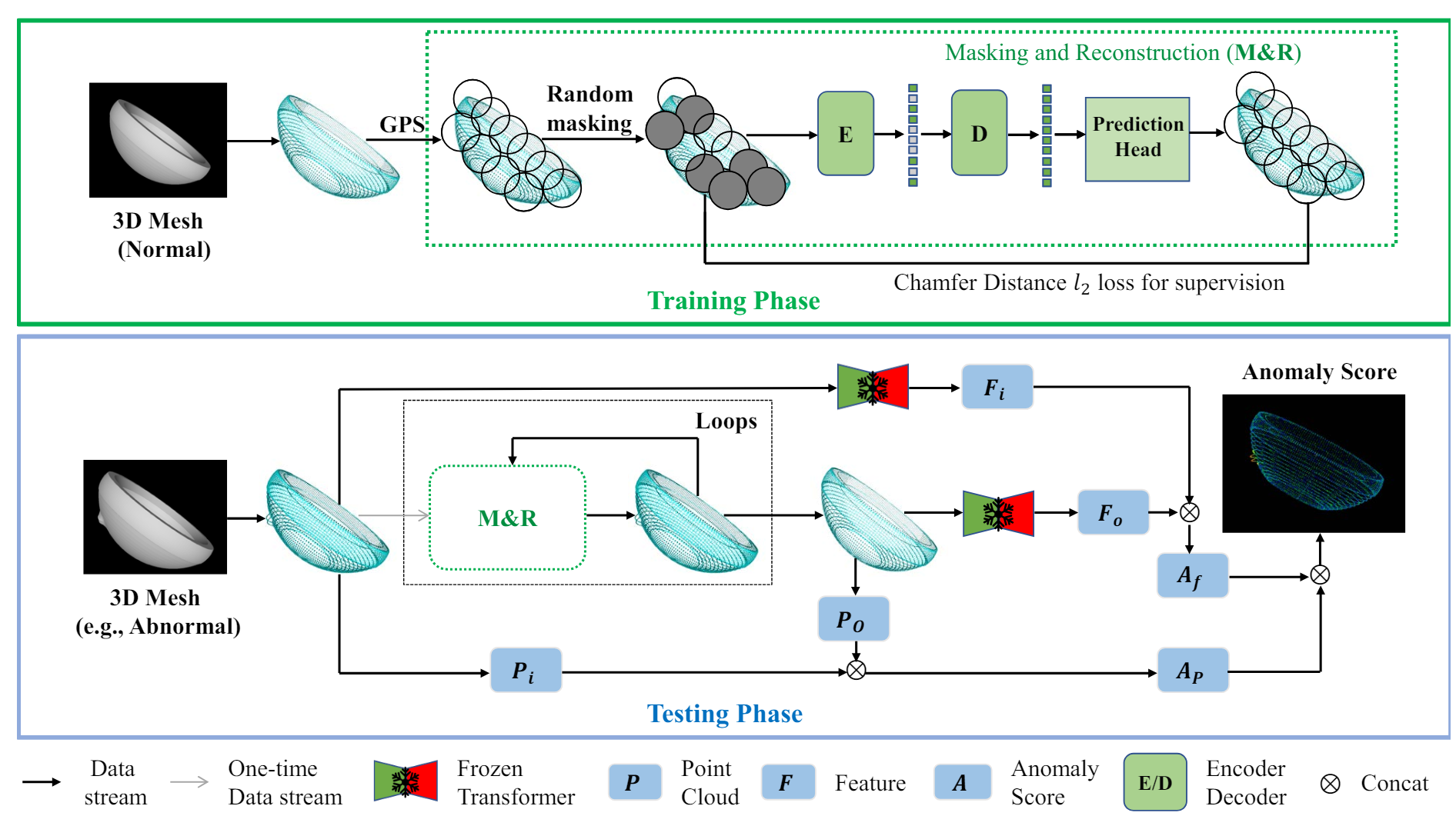
Towards Scalable 3D Anomaly Detection and Localization: A Benchmark via 3DAnomaly Synthesis and A Self-Supervised Learning NetworkReal3D-AD: A Dataset
10.[Registration Algorithm] Point-to-Point, Point-to-Plane ICP

대표적인 Registration 알고리즘을 살펴보고자 한다.
11.[Computer Vision] Object Detection의 기본
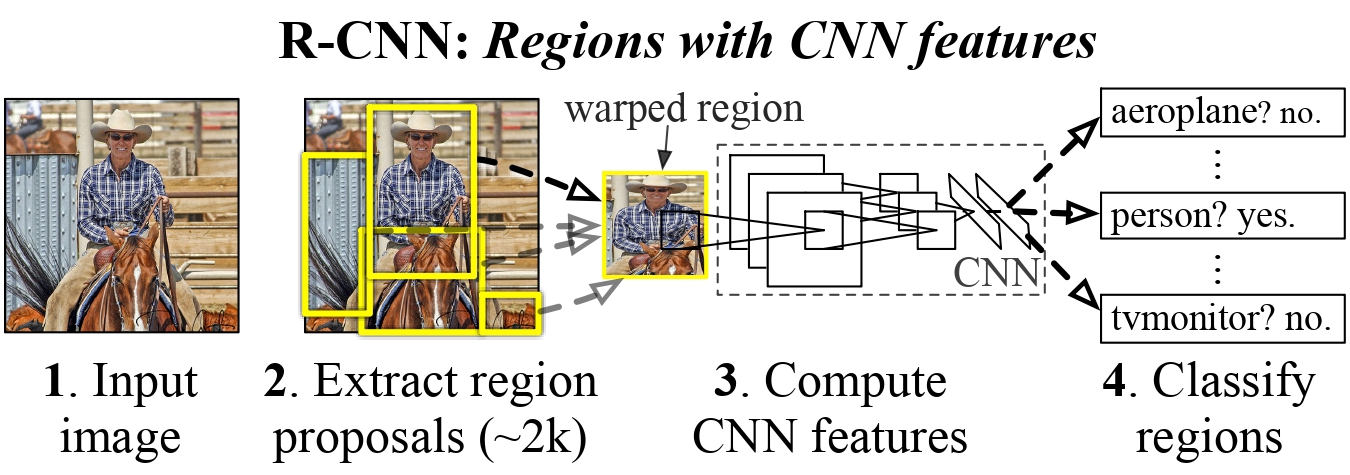
Object Detection의 기본에 대해 살펴보자.
12.[Paper Review] GLEE: General Object Foundation Model for Images and Videos at Scale (2024)
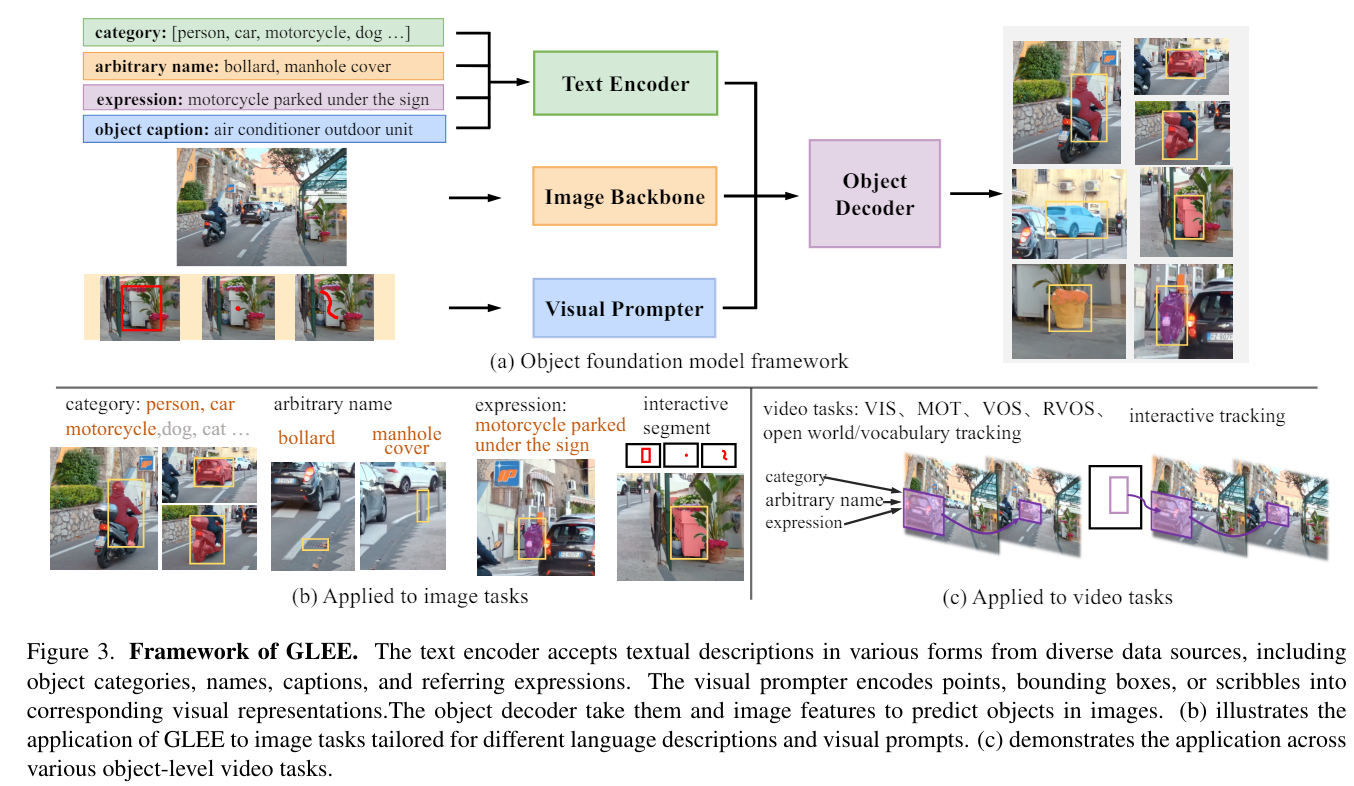
NLP에서는 foundation models이 많이 나오고 있으나 Vision 분야에서는 task types의 다양성과 통합된 형태의 부재로 foundation models는 오직 특정한 subdomains만 다룬다.그러나 객체를 찾고 식별하는 것은 컴퓨터 비전 시스템
13.[Paper Review] MoAI: Mixture of All Intelligence for Large Language and Vision Models (2024)
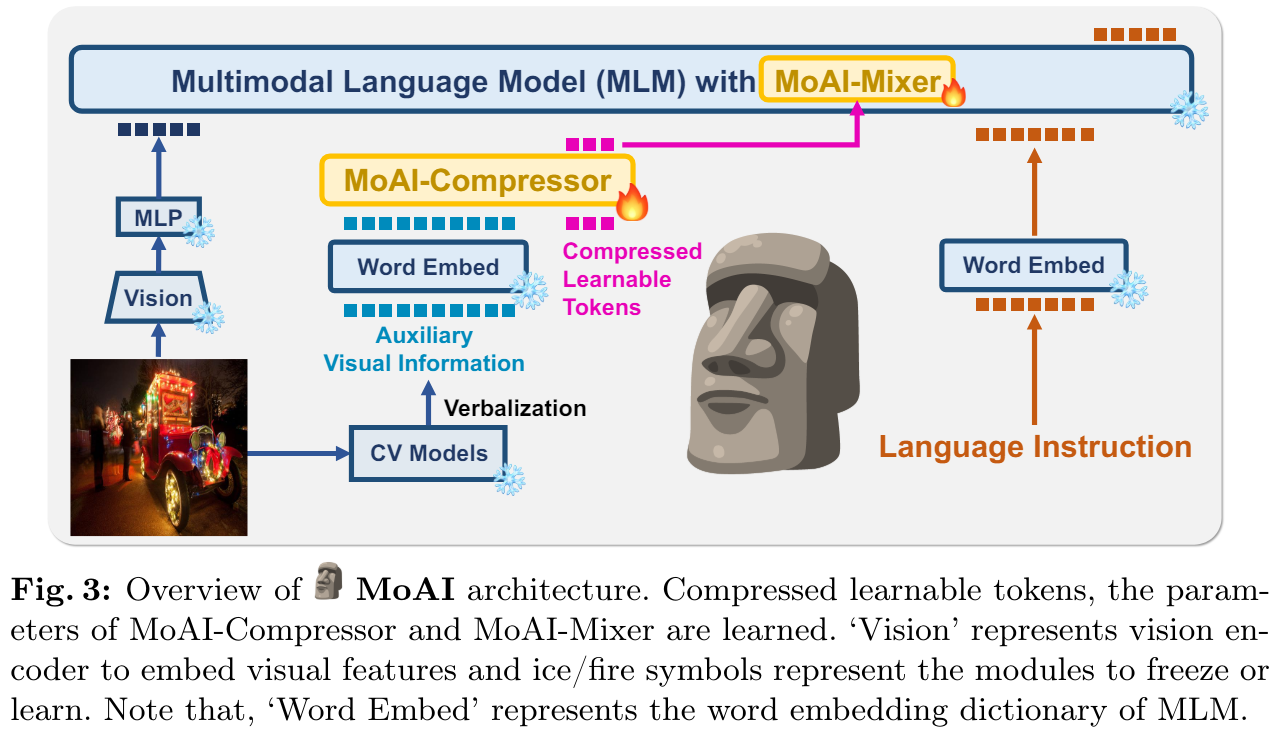
MoAI-Compressor & MoAI-Mixer를 소개한다.MoAI-Compressor는 external CV 모델의 출력값을 VL task에 적합한 보조적인 visual information을 aligns하고 condenses한다.MoAI-Mixer는 3가지 타입
14.[Paper Review] LLaVA: Large Language and Vision Assistant, Visual Instruction Tuning

LLaVA! Visual Instruction Tuning 논문 리뷰하였습니다.
15.[Papaer Review] LLaVA-NeXT: A Strong Zero-shot Video Understanding Model

LLaVA-NeXT 를 알아보고자 한다.
16.[Paper Review] RoFormer: Enhanced Transformer with Rotary Position Embedding
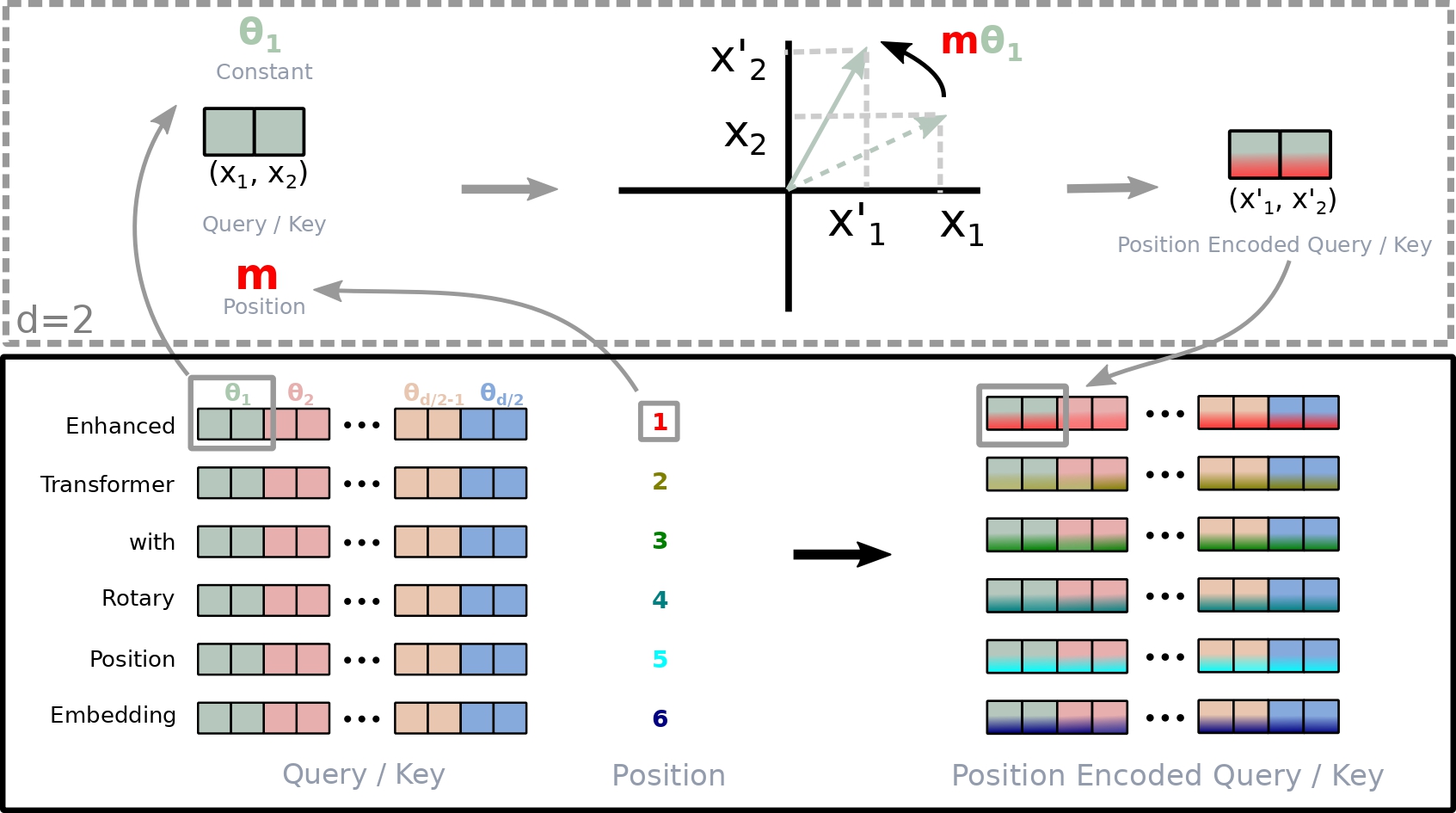
Roformer 에 대해서 알아보자.
17.[Paper Review] OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER
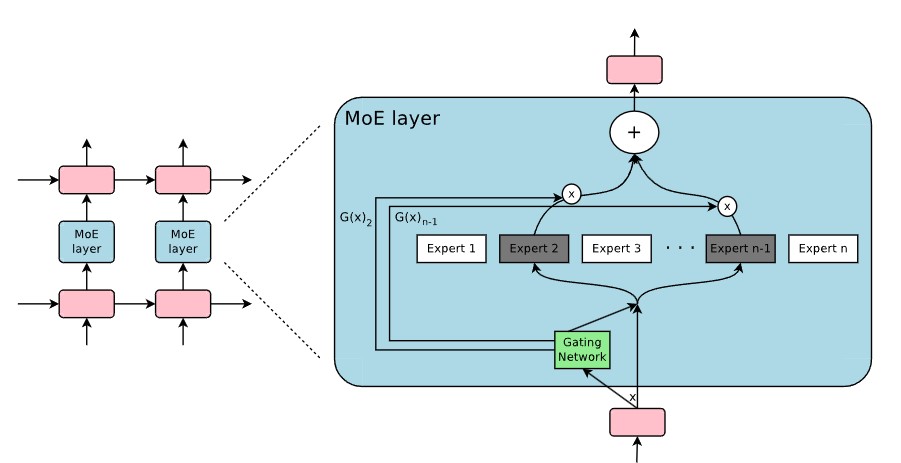
뉴럴 네트워크의 정보 흡수 능력은 파라미터의 개수에 의해서 제한된다. Conditional computation은 모델의 연산량 대비 성능이 극적으로 향상할 수 있다고 제안된 이론이다. 하지만, 실제로는 알고리즘적으로 그리고 성능 한계가 존재한다. 본 논문에서는 con
18.[Paper Review] Mixture-of-Experts with Expert Choice Routing
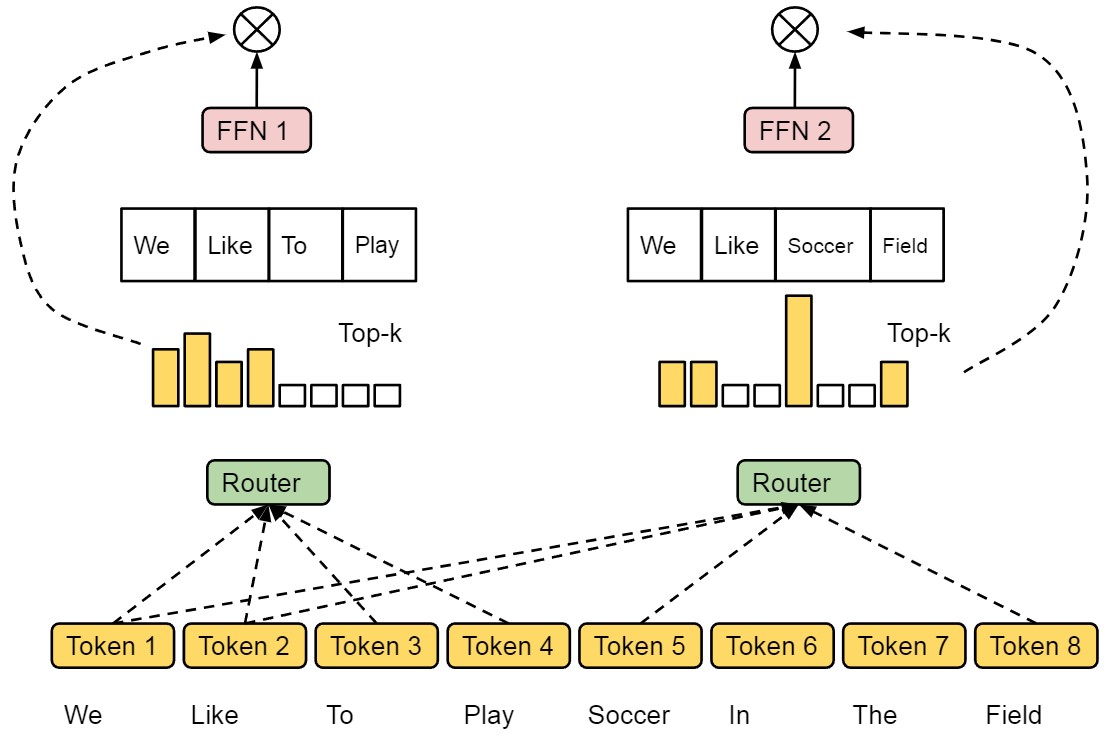
Abstract Sparsely-activated Mixture-of-experts(MoE)모델은 연산량을 유지하면서 파라미터의 수를 아주 많이 늘릴 수 있도록 하였습니다. 하지만, expert routing 전략의 부족으로 인해 특정 experts는 학습이 덜 되는