[Paper seminar] SEnsor Alignment for Multivariate Time-Series Unsupervised Domain Adaptation
SEnsor Alignment for Multivariate Time-Series Unsupervised Domain Adaptation
Introduction
시간 시계열(Time-Series, TS) 데이터는 다양한 분야에서 널리 연구되고 있으며, 특히 딥러닝(Deep Learning, DL) 방법론이 TS 문제 해결에 큰 성과를 거두고 있습니다. 하지만 DL 모델은 대량의 라벨링된 데이터를 필요로 하며, 현실적으로 데이터 라벨링은 높은 비용이 발생하는 어려움이 있습니다.
이를 해결하기 위해 Unsupervised Domain Adaptation(UDA) 방법론이 제안되었습니다. UDA는 라벨이 없는 타겟 도메인에서 도메인 차이를 줄여, 라벨이 있는 소스 도메인의 지식을 활용할 수 있도록 합니다. 그러나 기존 UDA 방법론은 Univariate Time-Series(UTS) 데이터에 집중하여 다변량 시계열(Multivariate Time-Series, MTS) 데이터의 도메인 차이를 효과적으로 줄이는 데 한계를 보입니다.
이 논문에서는 Multivariate Time-Series Unsupervised Domain Adaptation(MTS-UDA) 문제를 정의하고, 이를 해결하기 위해 SEnsor Alignment(SEA) 기법을 제안합니다. SEA는 로컬(Local) 및 글로벌(Global) 센서 수준에서 도메인 차이를 줄이는 방법론을 도입하여, 각 센서의 특성과 센서 간 상호 작용을 효과적으로 정렬합니다. 또한, 다중 분기(Self-Attention 기반) 메커니즘을 적용하여 공간-시간(spatial-temporal) 종속성을 모델링합니다.
Motivation
MTS-UDA 문제는 UTS 데이터보다 훨씬 복잡한 특징을 가지며, 기존 UDA 방법론이 효과적으로 적용되기 어려운 이유는 다음과 같습니다:
센서 간 분포 차이:
MTS 데이터는 여러 센서에서 수집되며, 각 센서는 서로 다른 데이터 분포를 가짐
기존 UDA 방법론은 전체 데이터를 하나의 글로벌 분포로 취급하여 개별 센서의 차이를 고려하지 못함
센서 간 상호 작용 정보의 부재:
MTS 데이터는 센서 간 강한 공간적-시간적 상호작용을 가짐
기존 UDA 방법론은 이러한 종속성을 모델링하지 않아 도메인 간 적절한 정렬이 어려움
기존 UDA 방법의 한계:
단순한 피처 정렬(Global Feature Alignment) 방식은 개별 센서 정렬을 고려하지 않아 일부 센서의 정렬이 실패할 가능성이 높음
위 문제를 해결하기 위해 논문에서는 로컬 센서 정렬(Endo-feature Alignment)과 글로벌 센서 정렬(Exo-feature Alignment)을 결합한 SEA 프레임워크를 제안합니다.
Proposed Method: SEnsor Alignment (SEA)
Problem Definition
주어진 MTS-UDA 문제는 소스 도메인(Source Domain)과 타겟 도메인(Target Domain)을 다음과 같이 정의할 수 있습니다:
소스 도메인: (라벨이 있는 데이터)
타겟 도메인: (라벨이 없는 데이터)
각 샘플 는 개의 센서에서 수집된 길이의 시계열 데이터로 표현되며, 센서 간 데이터 분포 차이를 고려해야 합니다.
SEA Framework Overview
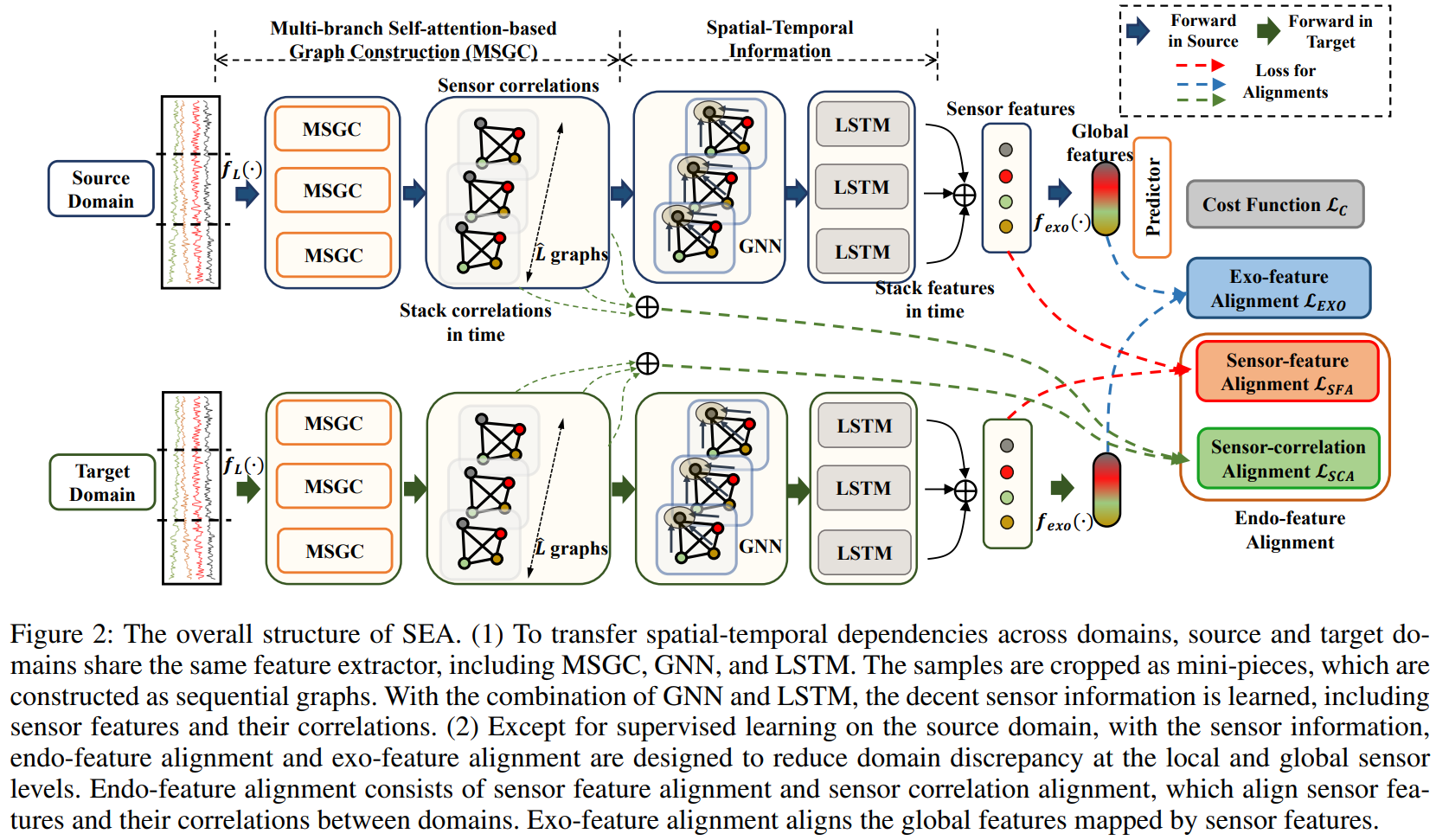
SEA는 다음과 같은 세 가지 주요 구성 요소를 포함합니다:
Multi-Branch Self-Attention 기반 그래프 구성(MSGC): 센서 간 공간적 관계(Spatial Dependency)를 학습하기 위해 그래프 신경망(GNN)과 LSTM을 결합, 각 센서의 정보를 효과적으로 추출하고 센서 간 관계를 명확히 정렬
Endo-feature Alignment (로컬 센서 정렬): 센서 특징 정렬(Sensor Feature Alignment, SFA): 동일한 센서의 특성을 도메인 간 정렬, 센서 간 관계 정렬(Sensor Correlation Alignment, SCA): 도메인 간 센서 간 상호 작용 패턴을 일관되게 유지
Exo-feature Alignment (글로벌 센서 정렬): 개별 센서의 특징을 통합하여 글로벌 수준에서 도메인 간 차이를 줄이는 정렬 기법, Deep CORAL 방법을 이용하여 글로벌 피처를 정렬
이러한 방법을 통해 SEA는 기존 UDA 방법론보다 도메인 차이를 더욱 효과적으로 줄이고, 센서 간 정렬을 보다 세밀하게 수행할 수 있습니다.
Experiments
Datasets & Setup
C-MAPSS (Remaining Useful Life Prediction): 항공 엔진의 수명을 예측하는 데이터셋, 14개의 센서로 구성된 다변량 시계열 데이터를 포함
평가 지표: RMSE (Root Mean Square Error), Score
Opportunity HAR (Human Activity Recognition): 4명의 사용자의 센서 데이터를 기반으로 활동을 예측하는 데이터셋, 113개의 센서를 활용하여 인간 활동을 분류

SEA는 두 개의 데이터셋에서 기존 최첨단(State-of-the-Art, SOTA) 방법론을 능가하는 성능을 보였습니다.
Ablation Study
Exo-feature Alignment만 적용한 경우보다 Endo-feature Alignment를 추가할 경우 성능이 향상됨
SFA와 SCA를 함께 적용할 경우 가장 뛰어난 성능을 달성함
이러한 결과는 센서 간 개별적인 특징과 관계를 동시에 정렬하는 것이 중요함을 의미합니다.
Conclusion & Future Work
본 논문에서는 MTS-UDA 문제를 해결하기 위해 SEnsor Alignment(SEA) 방법론을 제안하였습니다. SEA는 다음과 같은 기여를 합니다:
MTS-UDA 문제 정의: 기존 방법이 해결하지 못한 다변량 시계열 도메인 적응 문제를 새롭게 정의
Endo-feature & Exo-feature Alignment 제안: 개별 센서 및 글로벌 수준에서 도메인 차이를 줄이는 정렬 기법
공간-시간적 종속성 고려: MSGC를 통해 센서 간 상호 작용을 학습
앞으로의 연구 방향은 센서 데이터의 샘플링 속도 변화 및 타임스탬프 불일치 문제를 해결하는 자가 지도 학습(Self-Supervised Learning) 기법을 결합하는 것입니다.
