안녕하세요 :) 🤗
SKT AI Fellowship 6기 '대규모 Multimodal AI모델을 이용한 영상 검색 시스템 개발' 과제를 수행 중인 📺 텔레토비전 📺 입니다!
저희 팀은 '사용자에게 중요한 영상을 검색하고 영상의 상세한 설명을 제공하는 영상 검색 서비스' 을 목표로 연구 개발에 힘쓰고 있습니다. 💪
텔레토비전?
저희 팀 이름에 대해 궁금하실 것 같습니다. 두 가지 의미를 내포하고 있는데요.
'텔레토비처럼 뛰어난 협업 능력과 통통 튀는 매력을 뽐내는 팀원들과 함께하는 비전 프로젝트' 라는 뜻과 'SK Telecom에서 개발하고 있는 비전 프로젝트 (Tele to Vision)' 라는 의미가 있습니다~!
팀 이름도 소개를 드렸으니, 이제 저희 팀이 풀고 있는 연구 과제에 대해 소개하고자 합니다. 준비되셨나요~?
1. 연구 과제 소개
💡 연구 배경 및 필요성
여러분, 실시간으로 저장되는 대규모 영상에서 검색을 통해 중요한 영상을 얻고 상세한 정보를 제공받을 수 있을 때의 파급 효과를 생각해 보셨나요?
영상 검색 시스템의 사회적 필요성은 CCTV 통합관제센터와 같은 제한된 인력으로 운영될 때 더욱 강조됩니다.
실시간으로 수집되는 다중 CCTV 영상에서 특이점을 찾아내기 어렵고 사고 발생 시 신속한 처리가 불가하기 때문입니다.
또한, 미디어 시대의 개막으로 영상 분석 시장 규모는 기하급수적으로 증가하는 추세입니다.
영상 검색 시스템의 제안 배경은 크게 3 가지 입니다.
1. Multi-modal AI 모델의 활용
영상, 텍스트 및 비주얼 프롬프트 정보를 활용하여 단일 모달에서 해석하기 어려운 종합적인 상황을 이해함.
2. Large Language Model의 발전
LLM의 발전으로 자연어에 대한 깊은 이해를 통해 복잡한 문제를 효과적으로 처리함.
3. 데이터에서 생성되는 데이터
멀티 태스크 러닝을 통해 영상 검색 및 분석에 필요한 새로운 정보를 추출하고 저장함.
영상 검색 시스템! 그래서 어떻게 개발하면 좋을까요?
2. 연구 과제 아이디어
저희 팀은 영상 검색 시스템이란 방대한 주제를 크게 4 가지 문제로 정의하였습니다.
1. 비디오 영상 간 검색
2. 비디오 영상 내 검색
3. 비디오 영상 분석
4. 비디오 영상 하이라이트 요약
통통 튀는 연구 과제 아이디어를 순서대로 소개해 드리겠습니다. 🤗
1) 비디오 영상 간 검색
영상 간 검색을 하기 위해 비디오 영상 분할 처리 및 특징 벡터를 추출하는 과정이 필요합니다.
실시간 비디오 영상의 효율적인 분할 처리 작업을 위해 적절한 stride를 사용하여 overlapping chunks를 생성하여 청크 단위 video vector를 저장합니다.
그 후, X-CLIP 등 Dual Encoder 구조를 통한 Text to Video 모델을 활용하여 검색 시스템을 개발하고자 합니다.
사용자 질문에 적합한 비디오 영상을 Multimodal Vector Database에서 검색하고, Text Encoder를 통해 추출된 텍스트 특징 벡터와 비디오 특징 벡터를 내적하여 유사도를 산출합니다.
또한, 텍스트 프롬프트에 시간 값이 명시적으로 주어진다면 키워드 추출을 통해 Meta DB에 저장 후 영상 검색 Index로 사용하고자 합니다.
비디오 영상 간 검색 프레임워크는 다음과 같습니다.
2) 비디오 영상 내 검색
영상 내 검색을 하기 위해 실시간으로 영상 검색에 필요한 유용한 정보를 추출하는 과정이 필요합니다.
따라서, General Object Foundation Model을 활용하여 Open-World Object Detection을 수행하고자 합니다.
이미지 특징 벡터와 다중 객체 탐지 정보는 Multimodal Vector Database와 Meta Database에 저장하여 검색 시 활용할 수 있도록 합니다.
앞서 추출된 정보를 텍스트 및 비주얼 (visual) 프롬프트를 통해 객체 추적 및 상황 인식을 하고자 합니다.
Category, Arbitrary Name, Expression, Object Caption 등 Text Prompt를 입력으로 받아 객체를 탐지하고 상황을 인식하고, Visual Prompt를 통해 Interactive segmentation 작업을 수행하고 비디오 영상 내에서 객체를 추적합니다.
사용자 질문을 통해 비디오 영상 간 검색을 진행 후 유사도가 높은 영상에 대해서 비디오 영상 내 검색 및 분석을 진행고자 합니다.
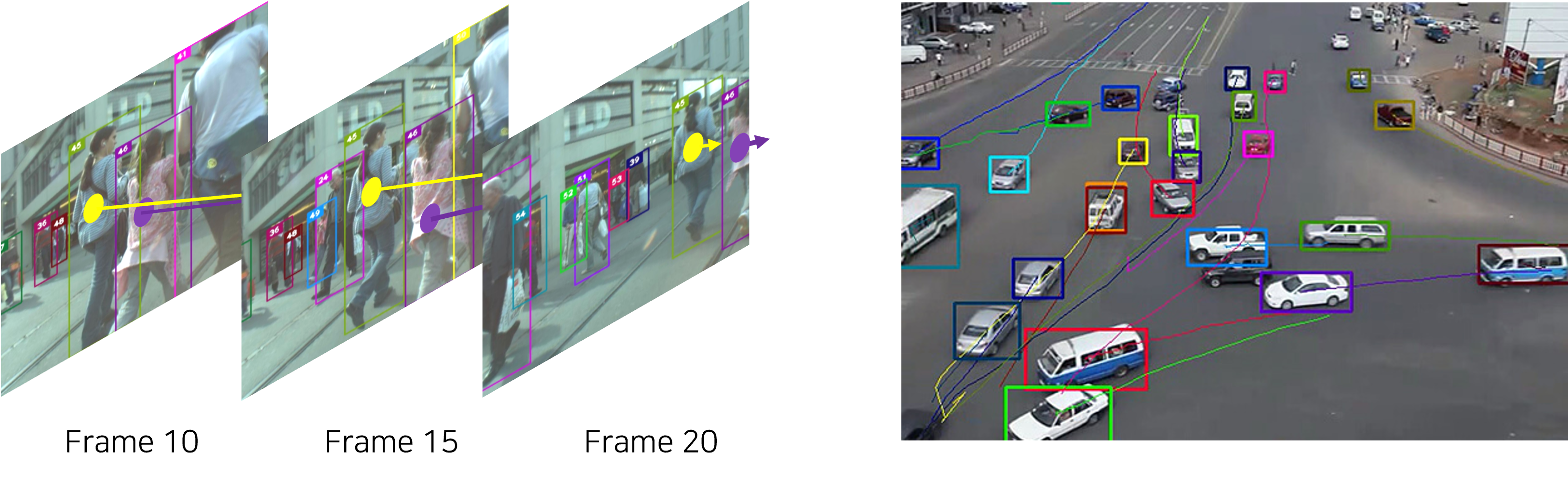
영상 내 검색 프레임워크는 아래와 같습니다.
3) 비디오 영상 분석
영상 분석은 영상 프레임 및 프롬프트를 통한 실시간 Large Language Model 답변 생성을 통해 개발하고자 하였습니다.
User는 영상 프레임과 Text 또는 Visual Prompt를 입력하고 Large Language Model을 통해 답변을 생성합니다.
Visual Prompt를 사용하기 위해 Object Bounding Box 데이터를 Verbalization을 활용하여 Visual Information-Language Alignment를 진행합니다.
Baseline으로 LLaVA 기반의 모델을 사용하고자 합니다.
추가적으로, Retrieval-Augmented Generation를 활용하여 검색 기반 답변을 생성하고 객체 속성 정보를 활용한 실시간 데이터 시각화를 진행할 계획입니다.
영상 분석 프레임워크는 아래와 같습니다.
4) 비디오 영상 하이라이트 요약
CCTV 관제 시스템 교대 인수인계 시 특이사항 보고를 효율적으로 하기 위해 해당 서비스를 제안하였습니다.
먼저, 영상이 입력으로 들어오면 훈련된 하이라이트 인덱싱 모듈을 활용하여 이벤트 프레임을 정의합니다.
영상에서 객체의 속성 정보를 기반으로 특정 이벤트 발생 시 하이라이트 인덱스를 0 또는 1로 설정하고, 1로 설정된 경우 해당 이벤트를 Meta DB에 저장됩니다.
그 후, 저장된 하이라이트 인덱스의 비디오 영상을 검색하고 추출된 이벤트 프레임을 통한 LLM 요약 답변을 생성합니다.
이를 통해, 관제사 인수인계 시 근무 시간동안 발생한 이벤트에 대한 보고서 작성 서비스를 제공할 수 있습니다.
영상 하이라이트 요약 프레임워크는 아래와 같습니다.
3. 연구 과제 수행 계획
1) 연구 진행 상황
자~! 앞에서 저희 팀이 영상 검색 시스템을 어떻게 개발하고자 하는지 소개드렸습니다. 🤗
내용이 정말 많은데 성공적인 과제 수행을 위해 크게 4 가지 단계로 접근하고자 하였습니다.
1. 중요도가 높은 주제 선정 및 단계별 접근
2. 과제에 적합한 데이터셋 정의 및 구축
3. 모델 구현 및 검증을 통한 성능 최적화
4. 파이프라인 구축 및 멘토님의 피드백을 통한 서비스 고도화 전략 수립
이러한 접근 방법에 기반하여 현재 수행 중인 연구 주제에 대해 설명드리겠습니다.
영상 분석은 텍스트, 비주얼 프롬프트와 메타 정보를 LLM 이 이해하여 답변할 수 있어야 하는 복잡한 주제입니다.
때문에, 사용자에게 유용한 정보를 제공해 줄 수 있는 영상 분석을 우선적으로 해결하고자 하였습니다.
현재 영상 분석 과제는 구체적으로 아래와 같이 계획 및 수행 중에 있습니다.
1. 논문 세미나를 통한 모델 이해 및 베이스라인 정의 (완료)
2. 다양한 CCTV 영상 및 텍스트와 비주얼 프롬프트를 활용한 zero-shot LLM 답변 실험 (완료)
3. 검색을 통해 선별된 비디오라 가정 후\, 정해진 구간의 비디오에 대한 전체 파이프라인 구축 (수행 중)
4. 검색 시스템을 통한 비디오에 대한 영상 분석 파이프 라인 구축 (수행 예정)
5. 성능 고도화 필요 시 데이터 셋 구축을 통한 파인 튜닝 (수행 미정)
각 주제에 대해서 단계별 연구 수행을 하고자 합니다. 모든 주제를 완성시키는 것보다 하나의 완성된 파이프라인을 구축하는 것이 현재 저희 팀의 목표입니다!
2) 연구 계획 일정표

3) 텔레토비전 팀 소개
텔레토비전은 고려대학교 산업경영공학부 🌱 김태형, 정현기, 함지율 🌱 로 구성된 팀입니다.
최고의 SKT 멘토 😎 김범준님, 류도훈님 😎 과 함께 멋있는 프로젝트 즐겁게 완성해보겠습니다!
저희 팀이 한 걸음씩 나아가는 모습 지켜봐주세요! 앞으로도 꾸준히 성실하게 연구 수행하겠습니다. AIF 6기 화이팅!!
🤝 Ground Rule
- 2주 간격 멘토님 참여 프로젝트 회의할 예정입니다. (1달에 1번 비대면 회의)
- 8월 2주차 프로젝트 중간 발표 전 발표 피드백 예정입니다.
- 매주 월, 목 오후 3시 팀원 간 회의할 예정입니다. (필요시 조정)
🏠 팀 공간
- 팀 공간은 AIF 6기 디스코드 방에서 진행할 계획입니다.
- 팀원 간의 회의는 꿈 꾸는 디그다 블로그에서 기록할 예정이며, DEVOCEAN 포스팅을 통해 소식을 전할 예정입니다.
4. 과제 요약
연구 목표
본 연구 과제는 실시간으로 저장되는 대규모 영상에서 검색을 통해 중요한 영상을 얻고 상세한 정보를 제공받을 수 있는 영상 검색 시스템 개발을 목표로 합니다.
핵심 도전 과제
- 비디오 영상 간 검색
- 비디오 영상 내 검색
- 비디오 영상 분석
- 비디오 영상 하이라이트 요약
 ####
####
🔥 무조건 해내겠습니다. 5개월의 성장과정을 지켜봐 주시기 바랍니다. 🔥
Reference
- Ma, Yiwei, et al. "X-clip: End-to-end multi-grained contrastive learning for video-text retrieval." Proceedings of the 30th ACM International Conference on Multimedia. 2022.
- Wu, Junfeng, et al. "General object foundation model for images and videos at scale." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
- Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
- Liu, Ze, et al. "Swin transformer: Hierarchical vision transformer using shifted windows." Proceedings of the IEEE/CVF international conference on computer vision. 2021.
- Lee, Byung-Kwan, et al. "Moai: Mixture of all intelligence for large language and vision models." arXiv preprint arXiv:2403.07508 (2024).
- Dai, Wenliang, et al. "Instructblip: Towards general-purpose vision-language models with instruction tuning." Advances in Neural Information Processing Systems 36 (2024).
- Wang, Yi, et al. "Internvideo: General video foundation models via generative and discriminative learning." arXiv preprint arXiv:2212.03191 (2022).
- Liu, Haotian, et al. "Visual instruction tuning." Advances in neural information processing systems 36 (2024).
- Su, Jianlin, et al. "Roformer: Enhanced transformer with rotary position embedding." Neurocomputing 568 (2024).
- Liu, Haokun, et al. "Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning." Advances in Neural Information Processing Systems 35 (2022)
