findByXXX 로 영속성 컨텍스트에 저장 후에 더티체킹을 통해서 update 를 할 수 있다.
findByXXX 에서 XXX 가 Pk(@Id) 인지 아닌지에 따라 더티체킹 순서에 차이가 있는 것을 발견했다.
편의상 PK 로 조회하는 경우를 findByPk, PK 외에 값으로 조회하는 경우를 findByNonePk 로 명명해보자.
findByPk 후에 update
수행 메서드
@Transactional
public void findByPkAndUpdate() {
for (int i = 1; i < 21; i++) {
var member = memberRepository.findById((long) (i)).get();
member.update(i + NEW_NICKNAME);
log.info("{} 번째", i);
}
}수행되는 쿼리
Hibernate:
select
member0_.id as id1_0_0_,
member0_.nickname as nickname2_0_0_
from
member member0_
where
member0_.id=?
Hibernate:
select
member0_.id as id1_0_0_,
member0_.nickname as nickname2_0_0_
from
member member0_
where
member0_.id=?
...
Hibernate:
update
member
set
nickname=?
where
id=?
Hibernate:
update
member
set
nickname=?
where
id=?
Hibernate:
update
member
set
nickname=?
where
id=?select 가 모두 일어난 후, update 가 일괄적으로 수행되는 것을 알 수 있다.
findByNonePK 후에 update
수행 메서드
@Transactional
public void findByNonePkAndUpdate() {
for (int i = 1; i < 21; i++) {
var member = memberRepository.findByNickname(i + DEFAULT_NICKNAME).get();
member.update(i + NEW_NICKNAME);
log.info("{} 번째", i);
}
}수행되는 쿼리
Hibernate:
select
member0_.id as id1_0_,
member0_.nickname as nickname2_0_
from
member member0_
where
member0_.nickname=?
Hibernate:
update
member
set
nickname=?
where
id=?
Hibernate:
select
member0_.id as id1_0_,
member0_.nickname as nickname2_0_
from
member member0_
where
member0_.nickname=?
Hibernate:
update
member
set
nickname=?
where
id=?
...select 후에 바로 update 가 수행된다.
차이가 발생하는 이유는 무엇일까?
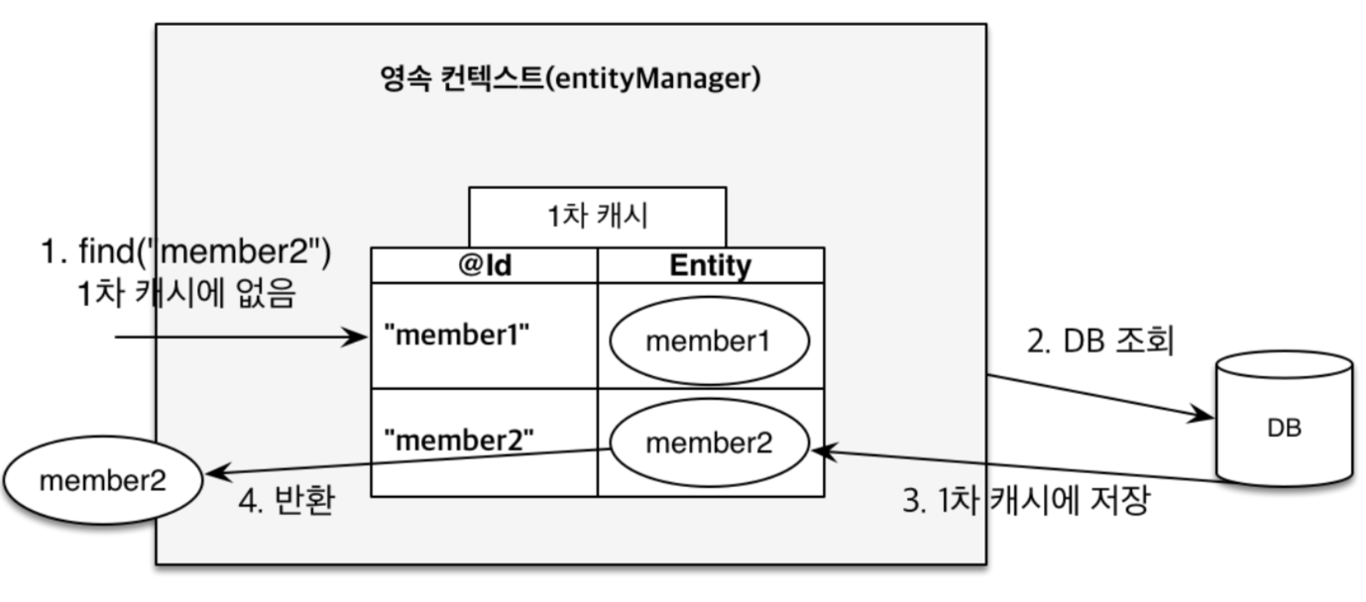
영속성 컨텍스트 1차 캐시에 Pk(@Id)로 매핑이 되는데, PK 외에 값은 영속성 컨텍스트가 관리하는 식별자로 값을 찾는게 아닌
위의 (2) , (3) 처럼 query methods 방식을 사용하게되면 영속성 컨텍스트가 관리하는 식별자로 값을 찾는게 아닌 JPQL로 쿼리가 나가기 때문에 1차캐시에서 데이터를 불러오지 못한다.
진짜 그럴까?
findByPK 는 여러번 호출해도 select 는 한번 수행된다.
@Transactional
public void findByPk() {
memberRepository.findById(1L).orElseThrow();
memberRepository.findById(1L).orElseThrow();
memberRepository.findById(1L).orElseThrow();
}Hibernate:
select
member0_.id as id1_0_0_,
member0_.nickname as nickname2_0_0_
from
member member0_
where
member0_.id=?findByNonePk 는 여러번 호출하면 호출 횟수 만큼 select가 수행된다.
@Transactional
public void findByNonePk() {
memberRepository.findByNickname(1 + DEFAULT_NICKNAME);
memberRepository.findByNickname(1 + DEFAULT_NICKNAME);
memberRepository.findByNickname(1 + DEFAULT_NICKNAME);
}Hibernate:
select
member0_.id as id1_0_,
member0_.nickname as nickname2_0_
from
member member0_
where
member0_.nickname=?
Hibernate:
select
member0_.id as id1_0_,
member0_.nickname as nickname2_0_
from
member member0_
where
member0_.nickname=?
Hibernate:
select
member0_.id as id1_0_,
member0_.nickname as nickname2_0_
from
member member0_
where
member0_.nickname=?다시 돌아와서, 더티체킹 수행 순서에 있어서 차이가 있는 이유는?
jpql 로 쿼리가 나가기 때문에 1차 캐시 데이터 저장을 못 하게 되고, 그 다음 select 전까지 쿼리가 flush() 된다고 궁예를 해보았다. 명확한 답은 아직 찾지 못 했다..😭
그럼 findByNonePK 시에 어떤 문제가 있을까?
Row Lock 발생 가능성이 높아진다
findByNonePK 는 update 쿼리가 select 후에 바로 수행되기때문에 메서드가 수행된 시간 만큼 row lock 이 걸린다.
물론 findByPk 시에도 select 가 모두 실행되고, update 가 메서드 마지막에 일괄적으로 수행되는 중에는 row lock 이 걸리지만 findByNonePK 보다는 훨씬 적을 것이다. PK 로 업데이트 시에도 데이터가 너무 많다면 rewriteBatchedStatements 옵션을 통해 bulk insert / bulk update 로 시간을 단축할 수 있다.
예시
@Transactional
public void rowLock() {
for (int i = 1; i < LOOP_COUNT; i++) {
var member = memberRepository.findByNickname(i + DEFAULT_NICKNAME).get();
member.update(i + NEW_NICKNAME);
// 시간이 엄청 오래 걸리는 작업
}
}작업 * LOOP_COUNT 만큼 row lock 이 걸려서, 다른 트랜잭션에서 해당 row 를 접근하지 못하게 된다.
어떻게 해야할까?
findByXXX 시에 update 가 필요한 경우 PK 로 찾으면 된다. PK 대신findAllByNonePkIn 을 사용해도 update 쿼리가 일괄 수행된다.
정리
findByNonePk시에 PQL로 쿼리가 나가기 때문에 메서드 수행 수만큼 쿼리가 실행된다.findByNonePK시에 update 는 일괄수행이 아닌 select 후에 바로 수행된다.findByXXX시에 update 가 필요한 경우 PK 로 찾자.findByPK시에도 update 시에는 row lock 이 걸린다. update 하려는 데이터가 많다면 bulk insert / bulk update 를 고려해보자.
테스트 코드는 여기

유익한 글 잘 봤습니다, 감사합니다.