Spring
1.[Spring] 스프링 핵심 원리

🌱핵심 원리를 이해하고, 고민하며 한층 더 성장해보자🌱
2.[Spring] IoC, DI, 그리고 컨테이너
기존 프로그램은 클라이언트 구현 객체가 스스로 필요한 서버 구현 객체를 생성하고, 연결하고, 실행했다. 한마디로 구현 객체가 프로그램의 제어 흐름을 스스로 조종했다. 개발자 입장에서는 자연스러운 흐름이다.반면에 AppConfig가 등장한 이후에 구현 객체는 자신의 로직
3.[Spring] 싱글톤 컨테이너
아래 코드를 보자.우리가 만들었던 스프링 없는 순수한 DI 컨테이너인 AppConfig는 요청을 할 때 마다 객체를 새로 생성한다.고객 트래픽이 초당 100이 나오면 초당 100개 객체가 생성되고 소멸된다! \-> 메모리 낭비가 심하다.해결방안은 해당 객체가 딱 1개만
4.[Spring] 컴포넌트 스캔
지금까지 스프링 빈을 등록할 때는 자바 코드의 @Bean이나 XML의 <bean> 등을 통해서 설정 정보에 직접 등록할 스프링 빈을 나열했다.등록해야 할 스프링 빈이 수십, 수백개가 되면 일일이 등록하기도 귀찮고, 설정 정보도 커지고, 누락하는 문제도 발생한다.\
5.[Spring] 의존관계 자동 주입 - 방법
의존관계 주입은 크게 4가지 방법이 있다.생성자 주입수정자 주입(setter 주입)필드 주입일반 메서드 주입제일 많이 쓰이는 방법이다.이름 그대로 생성자를 통해서 의존 관계를 주입 받는 방법이다.특징생성자 호출시점에 딱 1번만 호출되는 것이 보장된다.불변, 필수 의존관
6.[Spring] 의존관계 자동 주입 - 롬복
막상 개발을 해보면, 대부분이 다 불변이고, 그래서 다음과 같이 생성자에 final 키워드를 사용하게 된다.그런데 생성자도 만들어야 하고, 주입 받은 값을 대입하는 코드도 만들어야 하고… 필드만 적으면 끄읏!최근에는 생성자를 딱 1개 두고, @Autowired 를 생략
7.[Spring] 의존관계 자동 주입 - 빈
@Autowired 는 타입(Type)으로 조회한다.❗오류 발생이때 하위 타입으로 지정할 수 도 있지만, 하위 타입으로 지정하는 것은 DIP를 위배하고 유연성이 떨어진다. 그리고 이름만 다르고, 완전히 똑같은 타입의 스프링 빈이 2개 있을 때 해결이 안된다.스프링 빈을
8.[Spring] 의존관계 자동 주입 - 마무리
그러면 어떤 경우에 컴포넌트 스캔과 자동 주입을 사용하고, 어떤 경우에 설정 정보를 통해서 수동으로 빈을 등록하고, 의존관계도 수동으로 주입해야 할까?결론부터 이야기하면, 스프링이 나오고 시간이 갈 수록 점점 자동을 선호하는 추세다. 스프링은 @Component 뿐만
9.[Spring] 빈 생명주기 콜백
데이터베이스 커넥션 풀이나, 네트워크 소켓처럼 애플리케이션 시작 시점에 필요한 연결을 미리 해두고, 애플리케이션 종료 시점에 연결을 모두 종료하는 작업을 진행하려면, 객체의 초기화와 종료 작업이 필요하다.이번시간에는 스프링을 통해 이러한 초기화 작업과 종료 작업을 어떻
10.[Spring] 빈 스코프 - 프로토타입
지금까지 우리는 스프링 빈이 스프링 컨테이너의 시작과 함께 생성되어서 스프링 컨테이너가 종료될 때까지 유지된다고 학습했다. 이것은 스프링 빈이 기본적으로 싱글톤 스코프로 생성되기 때문이다. 스코프는 번역 그대로 빈이 존재할 수 있는 범위를 뜻한다.싱글톤: 기본 스코프,
11.[Spring] 빈 스코프 - 웹
싱글톤은 스프링 컨테이너의 시작과 끝까지 함께하는 매우 긴 스코프이다.프로토타입은 생성과 의존관계 주입, 그리고 초기화까지만 진행하는 특별한스코프이다.웹 스코프는 웹 환경에서만 동작한다.웹 스코프는 프로토타입과 다르게 스프링이 해당 스코프의 종료시점까지 관리한다. 따라
12.[JPA] 엔티티 설계시 주의점
Setter가 모두 열려있다. 변경 포인트가 너무 많아서, 유지보수가 어렵다. 나중에 리펙토링으로 Setter 제거🌟즉시로딩( EAGER )은 예측이 어렵고, 어떤 SQL이 실행될지 추적하기 어렵다. 특히 JPQL을 실행할 때 N+1 문제가 자주 발생한다.🌟실무에서
13.[JPA] 변경 감지와 병합(merge)
영속성 컨텍스트가 더는 관리하지 않는 엔티티를 말한다.DB에 한번 갔다온 친구🙋♀️임의로 만들어낸 엔티티도 기존 식별자를 가지고 있으면 준영속 엔티티로 볼 수 있다.영속성 컨텍스트에서 엔티티를 다시 조회한 후에 데이터를 수정하는 방법트랜잭션 안에서 엔티티를 다시 조
14.[Spring] Swagger 3.x 적용하기
Swagger(스웨거)는 개발자가 REST API 서비스를 설계, 빌드, 문서화할 수 있도록 하는 프로젝트이다.Swagger는 다음과 같은 경우에 유용하게 사용된다.다른 개발팀과 협업을 진행할 경우이미 구축되어있는 프로젝트에 대한 유지보수를 진행할 경우백엔드의 API를
15.[Spring] DAO, DTO, VO, Entity Class의 차이
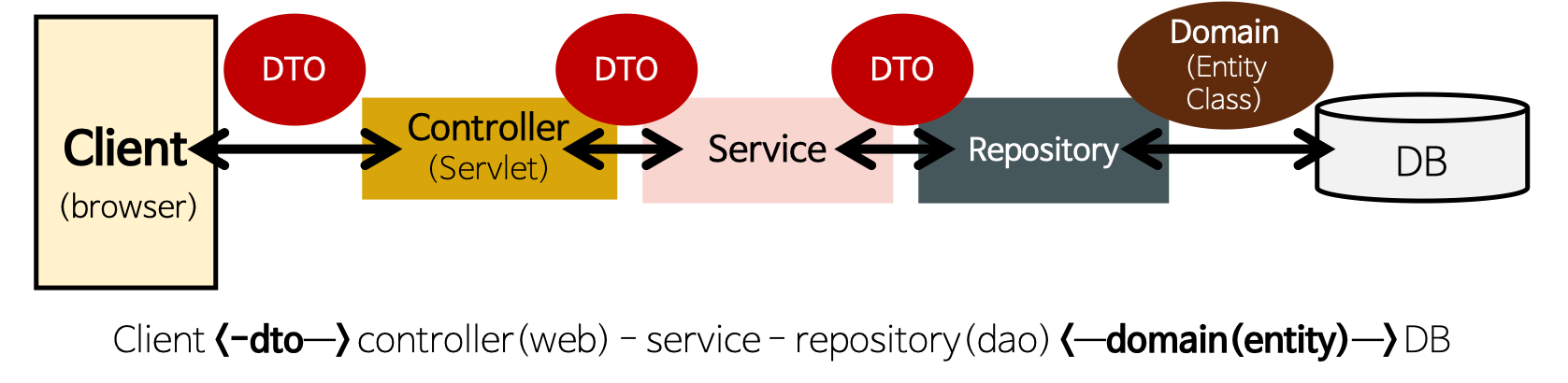
실제로 DB에 접근하는 객체이다.Persistence Layer(DB에 data를 CRUD하는 계층)이다.Service와 DB를 연결하는 고리의 역할을 한다.SQL를 사용(개발자가 직접 코딩)하여 DB에 접근한 후 적절한 CRUD API를 제공한다.JPA 대부분의 기본
16.[Spring] Project Structure
각 계층을 대표하는 디렉터리를 기준으로 코드들이 구성한다.해당 프로젝트에 이해가 상대적으로 낮아도 전체적인 구조를 빠르게 파악할 수 있다.내가 참여하지 않은 프로젝트 코드를 봤을 때, 계층형 방식이 빨리 훑기 좋은 것 같다.도메인 디렉터리 기준으로 코드를 구성한다.관련
17.[JPA] 다양한 연관관계 매핑
다대일(@ManyToOne)일대다(@OneToMay)일대일(@OneToOne)다대다(@ManyToMany)다대다 관계는 실무에서 거의 사용하지 않는데, 그 이유는?@ManyToMany를 사용하면 연결 테이블을 자동으로 처리해주므로 도메인 모델이 단순해지고, 여러가지고
18.[JPA] 다양한 연관관계 매핑 - 다대일, 일대다
JPA는 객체가 기준이지만, 다중성은 데이터베이스가 기준이다.연관 관계는 대칭성을 갖는다.일대다 <-> 다대일일대일 <-> 일대일다대다 <-> 다대다게시판(Board)과 게시글(Post)이 있다.하나의 게시판에는 여러 게시글을 작성할 수 있다.하나의 게
19.[JPA] 다양한 연관관계 매핑 - 일대일
다중성 JPA는 객체가 기준이지만, 다중성은 데이터베이스가 기준이다. 연관 관계는 대칭성을 갖는다. 일대다 다대일 일대일 일대일 다대다 다대다 일대일(1 : 1) 게시글(Post)과 첨부파일(Attach)이 있다. 요구사항 게시글에 첨부파일을 반드시 1개만 첨
20.[JPA] 다양한 연관관계 매핑 - 다대다
JPA는 객체가 기준이지만, 다중성은 데이터베이스가 기준이다.연관 관계는 대칭성을 갖는다.일대다 <-> 다대일일대일 <-> 일대일다대다 <-> 다대다중간 테이블이 숨겨져 있기 때문에 자기도 모르는 복잡한 조인의 쿼리(Query)가 발생하는 경우가 생길
21.[Spring] Feign client 적용기
마이크로서비스에서 서비스간 통신을 위한 2가지 방법이 있다.Rest Template vs Spring Cloud OpenFeign기존 프로젝트에서Rest Template으로 구현되어 있던 api 호출을 Spring Cloud OpenFeign으로 대체해보고 차이점을 알
22.[JPA] NULL 제약 조건과 조인 전략
JPA는 매핑관계의 필수 여부에 따라 실제 데이타베이스로 보내는 SQL 구문이 달라진다.@ManyToOne 의 optional 속성이 true (default) 이거나 @JoinColumn 의 nullable 속성이 true(default) 인 경우에는 Team이
23.[Spring] @Transactional 롤백은 언제 되는 걸까?
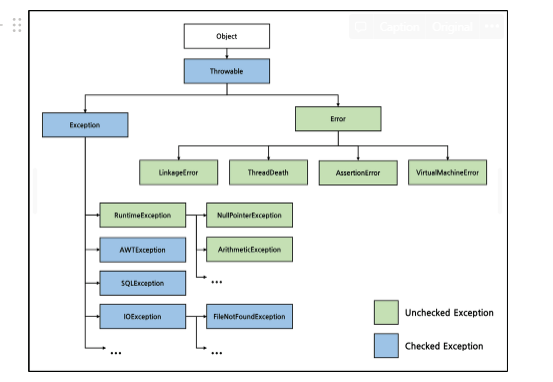
프로그래밍에서 예외란 입력 값에 대한 처리가 불가능하거나, 프로그램 실행 중에 참조된 값이 잘못된 경우 등 정상적인 프로그램의 흐름을 어긋나는 경우를 말한다. 그리고 자바에서 예외는 개발자가 직접 처리할 수 있기 때문에 예외 상황을 미리 예측하여 핸들링할 수 있다.그러
24. [Spring] 영속성 컨텍스트
데이터베이스를 하나만 사용하는 애플리케이션은 일반적으로 EntityManager Factory를 하나만 생성한다.EntityManager Factory는 여러 스레드가 동시에 접근해도 안전하므로 서로 다른 스레드 간에 공유해도 되지만, EntityManager는 여러
25.[Spring Data JPA] Spring Data JPA는 어떻게 interface만으로 동작할까?
MemberRepository는 인터페이스고, @Repository 애노테이션을 붙여 놓지도 않았는데, 다음과 같은 코드가 가능할까?🤔memberRepository의 실제 객체를 보니 Proxy가 주입되다. 그리고 그 Proxy는 SimpleJpaReposito
26.[JPA] JPA의 낙관적 잠금(Optimistic Lock), 비관적 잠금(Pessimistic Lock)
요청이 많은 서버에서 여러 트랜잭션이 동시에 같은 데이터에 업데이트를 발생시킬 경우에 일부 요청이 유실되는 경우가 발생하여 장애로 이어질 수 있다.그 만큼 엔터프라이즈 애플리케이션의 경우 데이터베이스에 대한 동시 액세스(concurrency)를 적절하게 관리하는 것이
27.[JPA] findByPk 와 findByNonePk 에 차이가 있을까
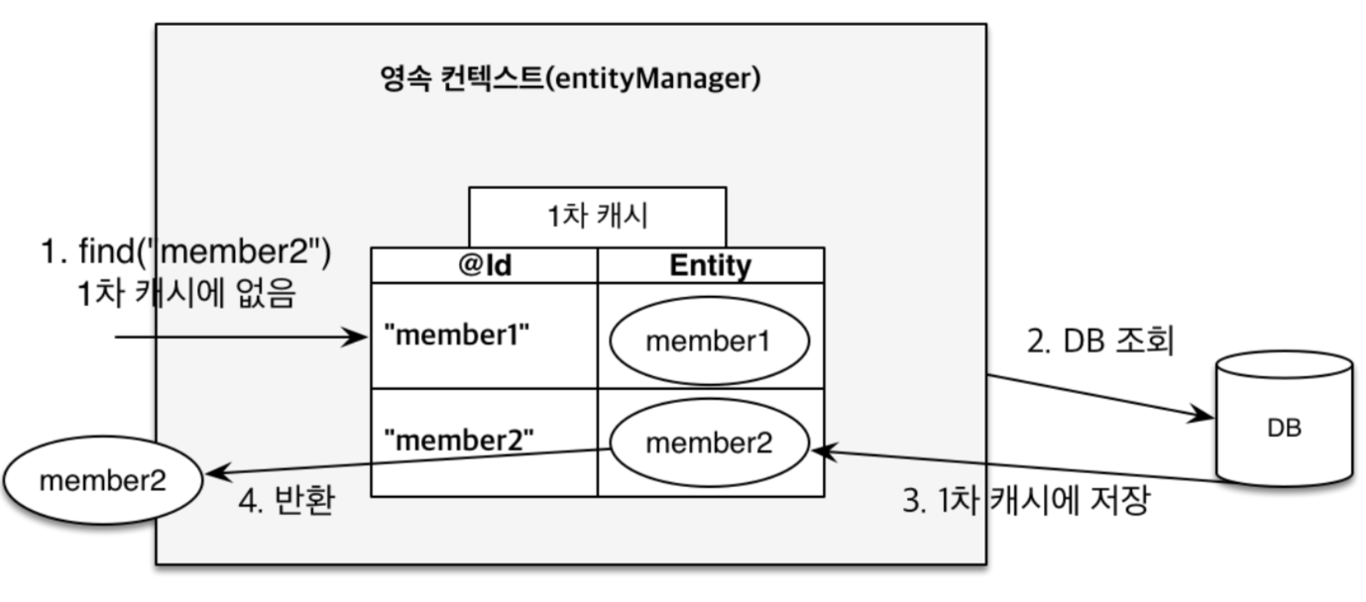
findByXXX 로 영속성 컨텍스트에 저장 후에 더티체킹을 통해서 update 를 할 수 있다.findByXXX 에서 XXX 가 Pk(@Id) 인지 아닌지에 따라 더티체킹 순서에 차이가 있는 것을 발견했다.편의상 PK 로 조회하는 경우를 findByPk, PK 외에
28.[Spring] 롤백 마크가 생긴 트랜잭션은 재사용이 불가능할까?
엄청 유명한 배민의 블로그 글(응? 이게 왜 롤백되는거지?)에서 봤던 에러가 발생했다. 이 참에 공부해보자.참여 중인 트랜잭션이 실패하면 기본정책이 전역롤백인데, 이 에러는AbstractPlatformTransactionManager(https://github
29.[Spring] 벌크 계정 생성 시, 병목 지점을 개선해보자
10000개의 데이터를 처리하는데 1시간 20분 정도가 걸리고 있다. 클라이언트와 read timeout 설정이 5분이라서 해당 메서드는 @Async 처리를 하였지만, 여전히 백그라운드에서 로직처리에 1시간 20분이 소요되고 있고, 이 시간동안 요청자는 기다려야 한다.
30.[Spring] 애플 로그인을 구현해보자
번거로운 회원가입 절차없이 버튼 클릭 하나만으로 서비스를 이용할 수 있는 소셜 로그인은 사용자 유입에 도움이 된다.하지만 iOS 앱은 카카오, 구글 로그인과 같은 소셜 로그인을 추가하려면 애플 로그인이 구현되어있어야 앱스토어 심사에서 리젝을 면할 수 있다.카카오나 구글
31.[JPA] 연관관계를 이용하여 객체를 조회해보자
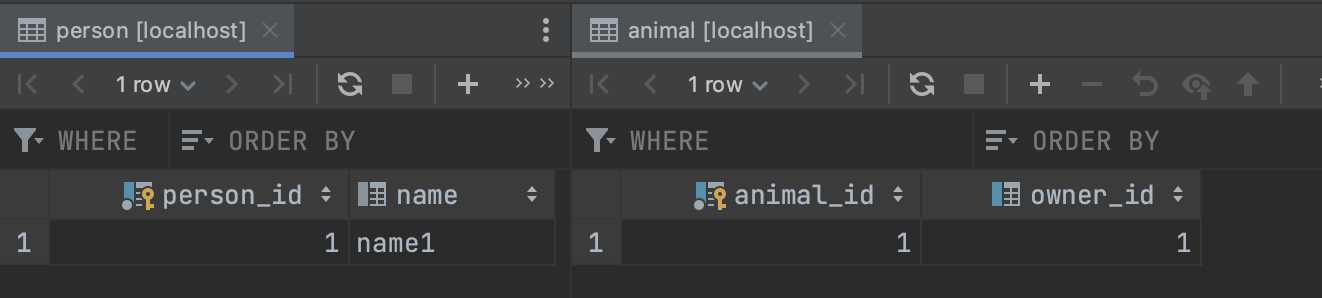
Person (사람)과 Animal(동물)이라는 객체가 있다.사람은 동물을 가지고 있을 수도 있고, 가지고 있다면 1마리만 가지고 있을 수 있다.Animal(동물)의 ownerId(주인 아이디) 필드에는 personId(사람 아이디)가 들어간다.사람에게 hasAnima
32.[Spring] @DataJpaTest 는 자동 롤백이 기본 정책이다
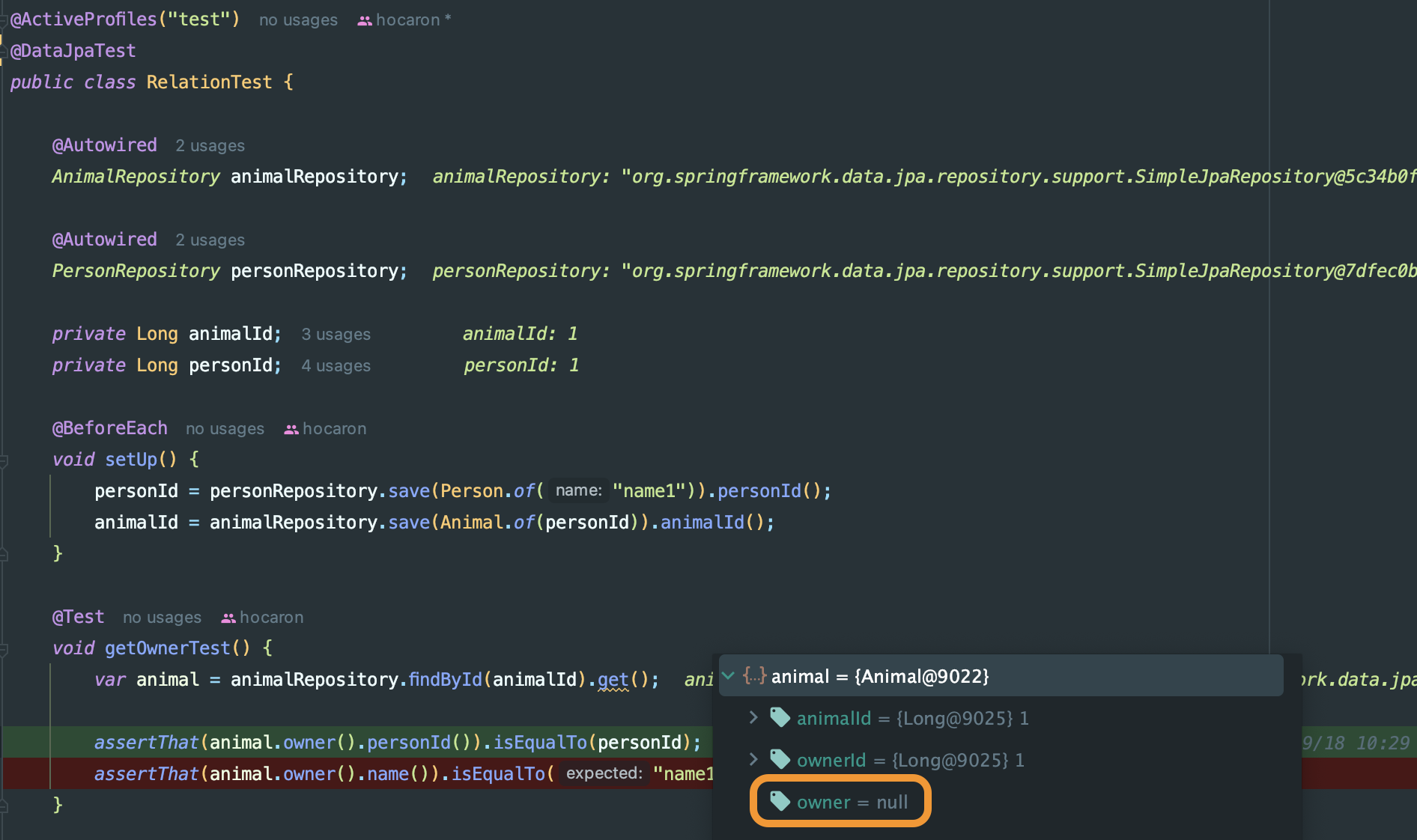
@DataJpaTest 로 OneToOne 연관관계가 있는 객체를 조회하는데, Owner 에는 null 이 들어와서 테스트 코드는 실패한다.위의 테스트는 setUp(), getOwnerTest() 로 나누어져 있지만, 사실은 위와 같이 하나의 트랜잭션에서 수행되는 것과
33.[Spring] Client IP 는 어떻게 가져오는 걸까
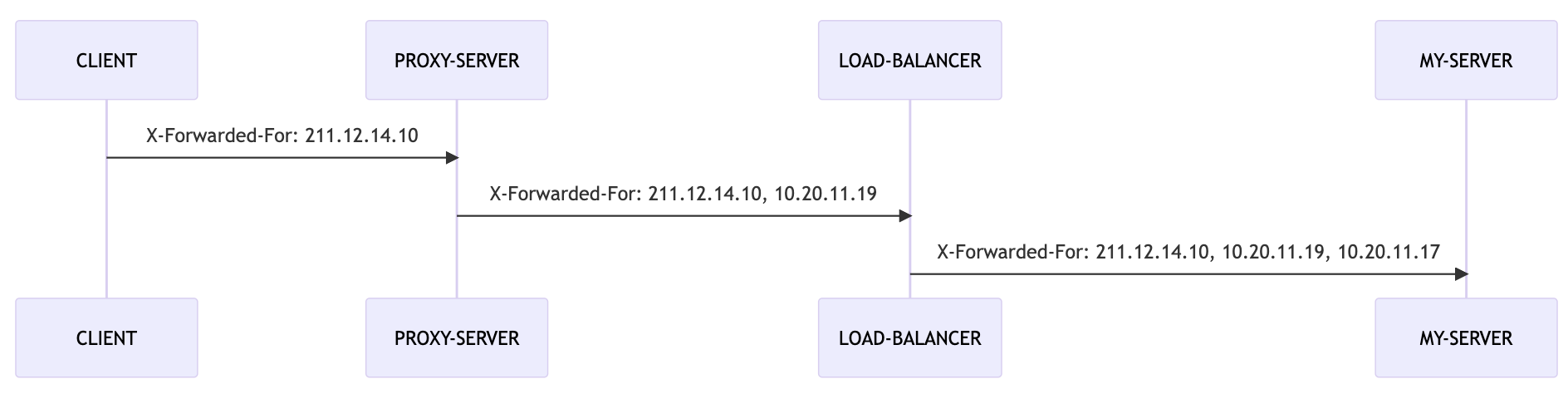
우리 서버로 오기까지의 많은 인스턴스를 거쳐오지만, 우리는 최초 IP(Client IP) 가 필요하다.스프링은 X-Forwarded-For 에서 어떻게 최초 IP 를 가져오는지 알아보자.framework 로 설정 시, 표준 헤더 외에 비표준 헤더를 가져올 수 있다.임베
34.[Spring] 설정파일 우선순위를 알아보자
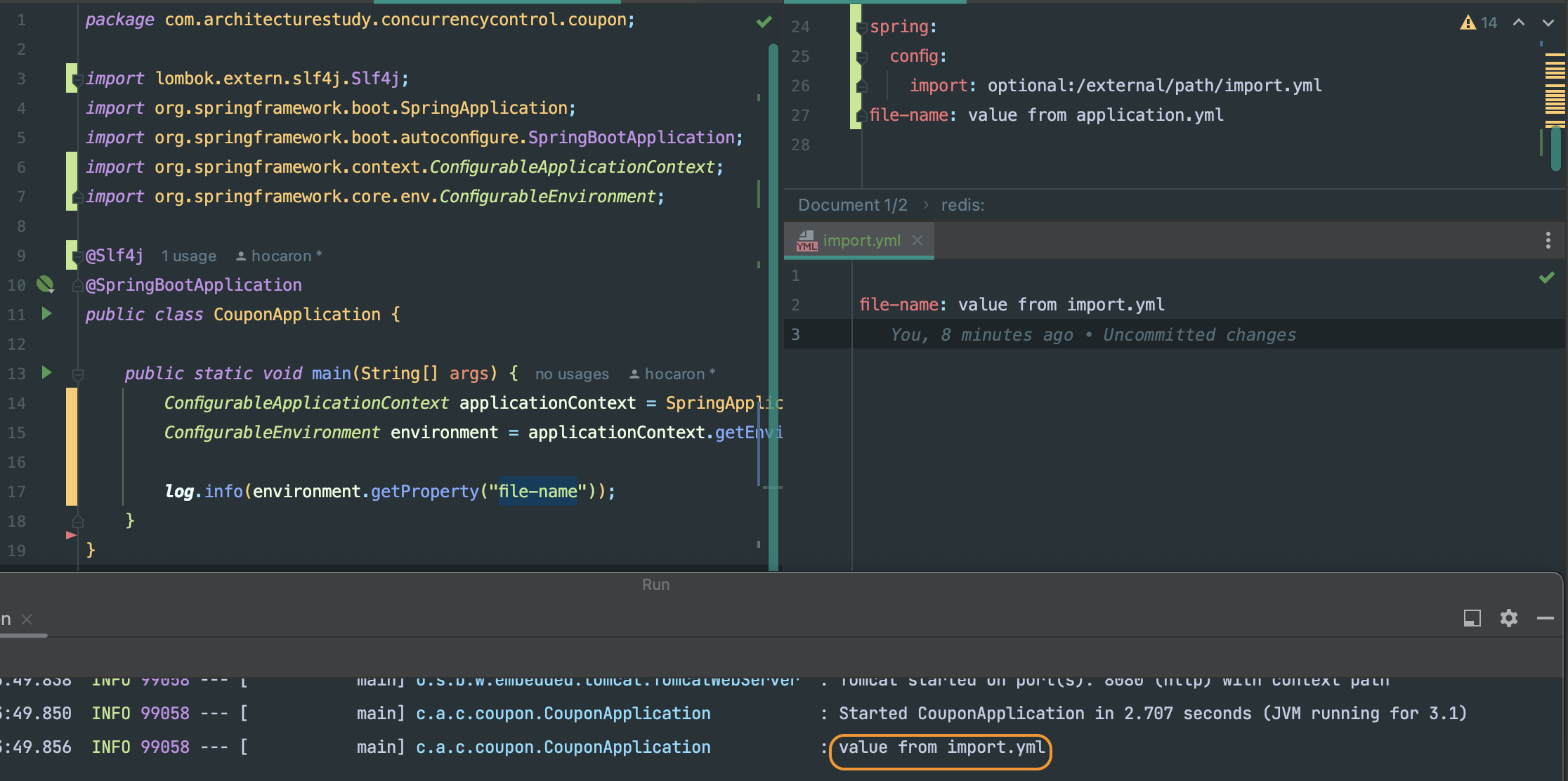
서비스의 설정값을 변경해주었는데도, 반영이 안 되는 경우가 있다🫠설정값들이 위치하는 설정파일의 우선순위를 공부하고, 알맞은 파일에 설정값을 변경해주자.11번 application.properties(yml) 의 경우 파일 위치와 프로파일에 따른 우선순위가 적용된다.c
35.[Spring AOP] 레거시 데이터와 하위 호환성을 유지하며 새로운 데이터를 추가해보자
레거시 프로젝트를 이관하며 레디스에 쌓고 있던 레거시 데이터를 새로운 키값과 자료구조를 가진 새로운 데이터 변경해야했다. 기존에 이미 적재된 레거시 데이터와 하위호환성을 유지하며 새로운 데이터를 추가해보자🫠 데이터의 흐름은 다음과 같아요 데이터 삭제 시에 아래와
36.[Spring] 멀티 데이터 소스 환경에서 더티체킹이 왜 동작하지 않을까
Member, Account 라는 2개의 데이터 소스를 사용하는 프로젝트가 있다. 더티체킹을 통해 Account 라는 엔티티의 데이터를 업데이트 하려고 한다. 코드를 보자.더티체킹을 통해 업데이트를 하는 전형적인 로직이다. 왜 updateAccount 메서드 종료 후에
37.[JPA] 기본키 생성 전략과 DataIntegrityViolationException
데이터가 정상 저장되면, 저장된 닉네임을 반환하는 메서드가 있다. 하지만 중복키 에러에 의해 에러 발생시에는 기본 닉네임(DEFAULT_NICKNAME) 을 반환하는 요구사항이 있다.기본키 생성 전략이 어떤 것인지에 따라 try - catch 에서 에러가 발생할 수 있
38.[Spring] 유효성 검사 시에 UnexpectedTypeException 에러가 발생한다면
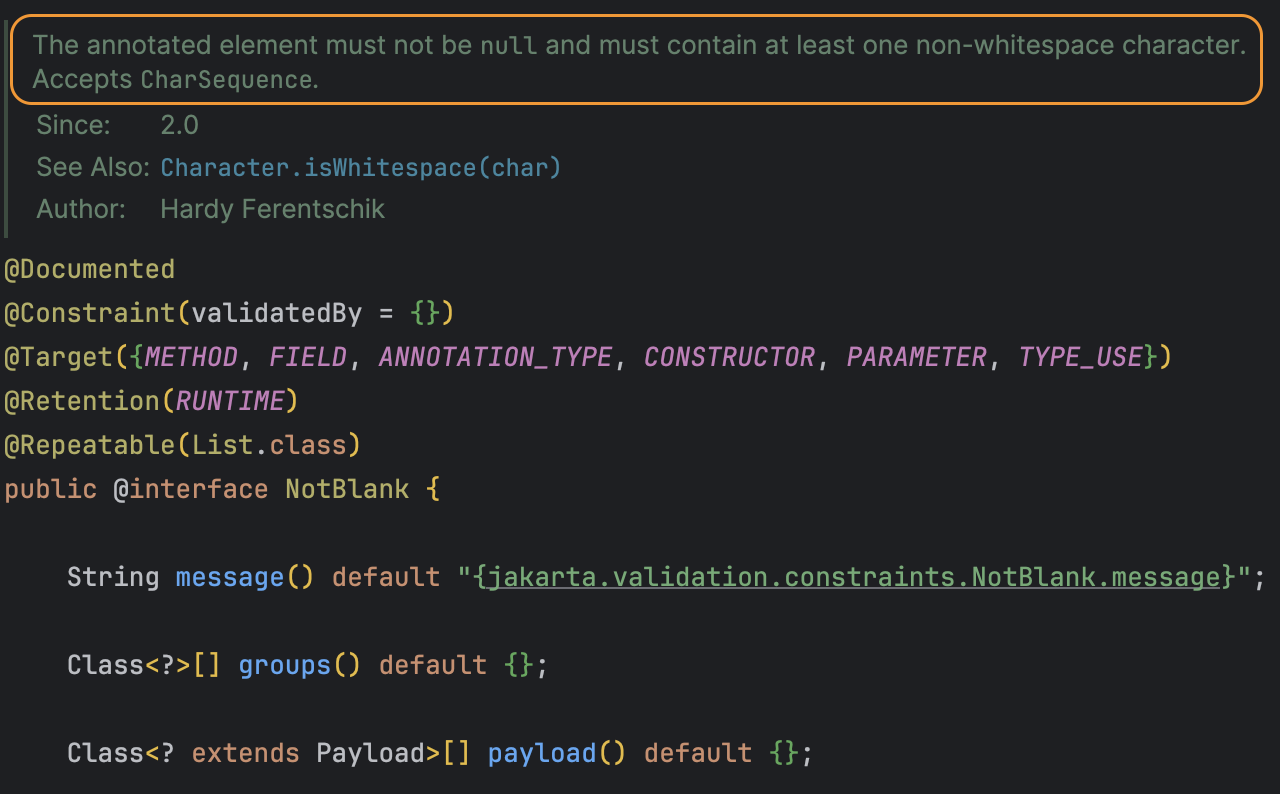
입력값 검증 시에 @NotBlank 와 같은 유효성 검사를 위한 어노테이션을 많이 사용할 것이다.enum 같은 경우 null, "", " "(공백이 포함된 문자열)이 모두 유효성 검사에서 통과되지 않도록 @NotBlank 를 사용할 수 있는데, 사용 시에 Unexpec
39.[Spring] Redis 트랜잭션 적용하기
MySQL 에서도 트랜잭션을 사용하듯이 Redis 에서도 트랜잭션이 필요한 경우가 있을 것이다. Redis 에서는 어떻게 설정할 수 있는지 코드로 살펴보자.
40.[Spring] 레디스 Replica 설정하기
모든 저장소가 그렇듯 Redis에서도 HA(High Availability)를 지원한다. Lettuce 사용시, 일반적인 설정으로는 master 에서만 read/write 작업을 하기 때문에, replica 에서도 read 작업을 수행하기 위해서 추가적인 설정이 필요하
41.[Spring] 꺼진 OSIV 도 다시보자
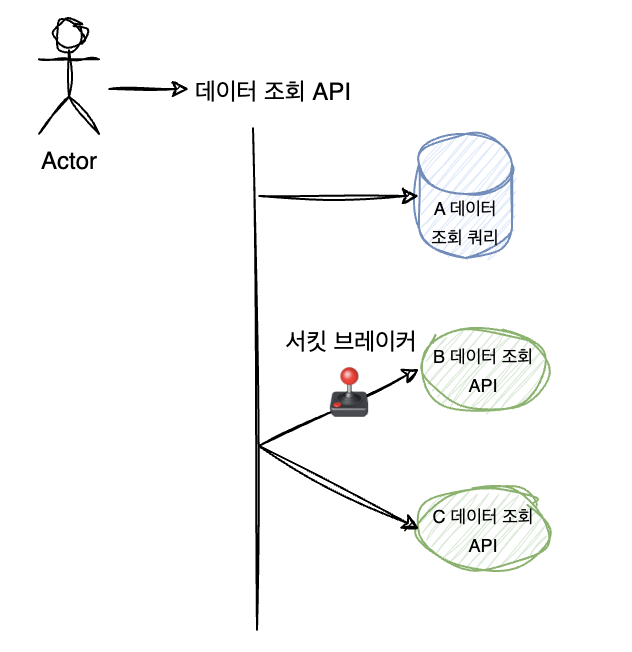
클라이언트에서 필요한 정보를 클라이언트에서 모두 호출하기 보다는 하나의 서버에서 DB, 다른 서버 호출해서 응답해야하는 요구사항이 있다. B 데이터를 조회하는 서버에서 장애 발생시에 다른 서비스로 장애 전파가 되면 안 되기 때문에, B 데이터를 조회하는 서버에는 서킷
42.[Spring] 캐시매니저를 Redis 로 전환해보자

로컬 캐시를 사용하던 프로젝트에서 캐시 동기화 이슈와 캐시 히트율을 높히기 위해 캐시 매니저를 Caffein에서 Redis 로 전환해야했다.전환하면서 겪은 역직렬화시 클래스 데이터 타입으로 인한 이슈와 캐시되어있던 데이터에 필드가 추가되면서 겪었던 ObjectMappe
43.[Jackson] 기본 ObjectMapper 의 configuration 을 알아보자
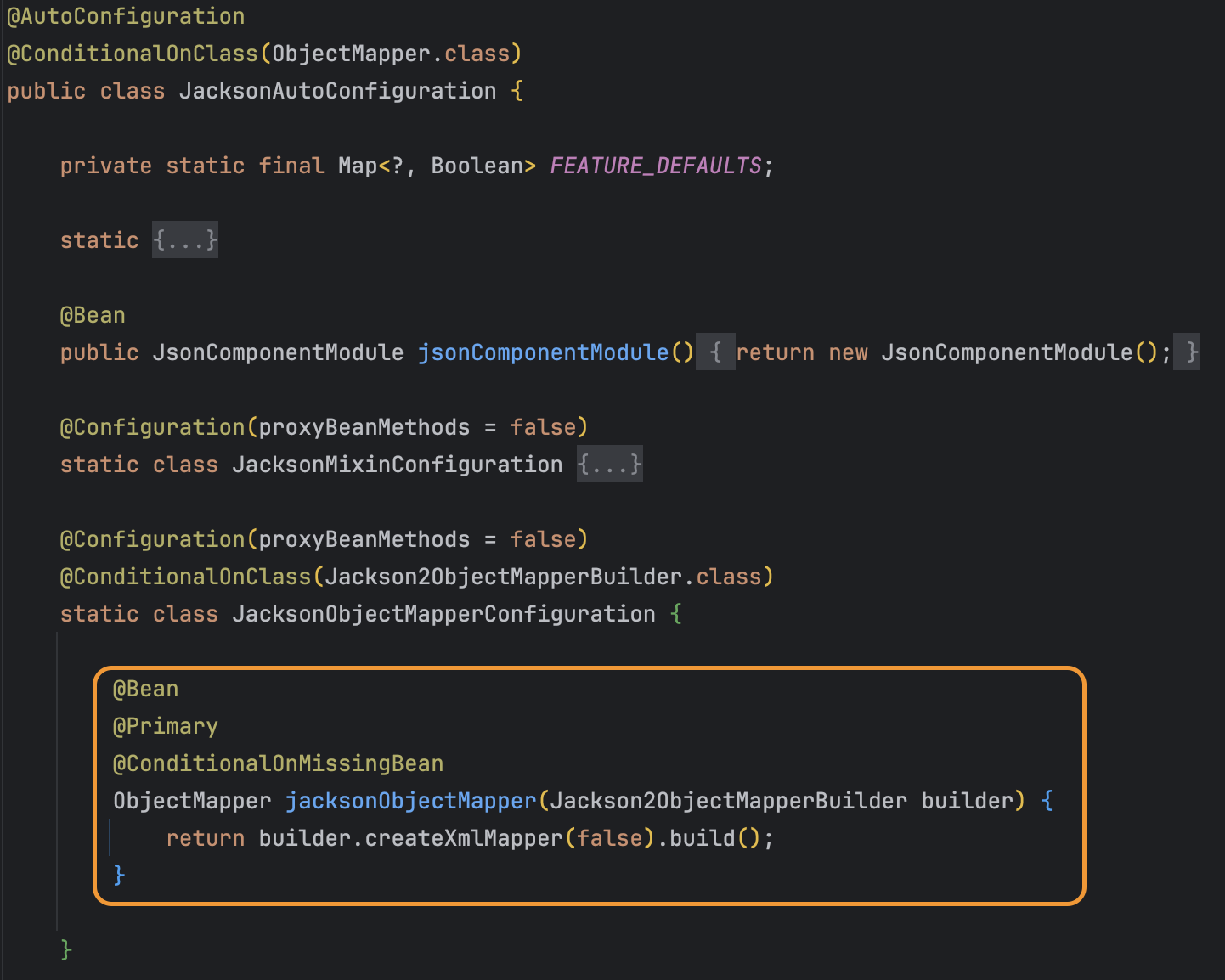
\[Spring 캐시매니저를 Redis 로 전환해보자 포스팅]
44.[HikariCP] set autocommit 개선을 통한 성능 최적화를 해보자

회사 기술 공유 시간에 다른 팀 개발자님께서 set autocommit 쿼리 호출을 개선하여 API 응답시간을 1/2 로 줄여버렸다는 발표를 하셨다.엄청 간단하다. yml 파일에 이 설정을 추가해주기만 하면 된다.HikariCP를 사용하고 있기 때문에 HikariCP
45.[HikariCP] Connection Pool 획득 과정에서 발생하는 지연시간 개선하기
서비스 시작 시점에 HikariCP의 커넥션 획득 시간이 2.58초로 급격히 증가하는 현상이 발생했다. 지연 발생 원인과 해결방법을 알아보자. 커넥션 풀 초기화와 포트 오픈 타이밍으로 인한 지연 HikariCP는 기본적으로 커넥션 풀을 비동기로 채운다. 이로 인
46.[Feign] HTTP 구현체 성능 비교: HttpURLConnection vs Apache HttpComponents 5
MSA(Microservice Architecture) 환경에서는 서비스 간 통신이 매우 중요하다. Spring Cloud에서 제공하는 Feign 클라이언트는 선언적 방식으로 HTTP API 통신을 쉽게 구현할 수 있게 해주는 도구이다.Feign의 기본 HTTP 클라이