
오늘 배운 것
Database & SQL
SQL Syntax
- 불러오는 데이터베이스 객체
CustomersTable은 다음과 같다고 가정하자
| CustomerID | CustomerName | ContactName | Address | City | PostalCode | Country |
|---|---|---|---|---|---|---|
| 1 | Alfreds Futterkiste | Maria Anders | Obere Str. 57 | Berlin | 12209 | Germany |
| 2 | Ana Trujillo Emparedados y helados | Ana Trujillo | Avda. de la Constitución 2222 | México D.F. | 05021 | Mexico |
| 3 | Antonio Moreno Taquería | Antonio Moreno | Mataderos 2312 | México D.F. | 05023 | Mexico |
| 4 | Around the Horn | Thomas Hardy | 120 Hanover Sq. | London | WA1 1DP | UK |
| 5 | Berglunds snabbköp | Christina Berglund | Berguvsvägen 8 | Luleå | S-958 22 | Sweden |
Select
데이터베이스에서 원하는 데이터를 선택하고자 할 때 사용한다.
-
기본 :
SELECT column1, column2, ... FROM table_name; -
예시 1 :
SELECT CustomerName FROM Customers;Customers테이블의CustomerNameCoulumn을 가져옴
-
예시 2 :
SELECT * FROM Customers;Customers테이블의 모든 Coulumn을 가져옴
Where
특정 조건을 만족하는 데이터를 추출할 때 사용한다.
- 기본 :
SELECT column1, column2, ... FROM table_name WHERE condition; - 예시 1 :
SELECT * FROM Customers WHERE City = "México D.F.";Customers테이블에서City가"México D.F."과 일치하는 데이터를 가져옴
=, >, <, >=, <=, <>과 같은 다양한 비교 연산자를 사용할 수 있음.
And, Or, Not
Where 절과 함께 쓰이는 일종의 논리 연산자
- AND Operator :
SELECT column1, column2, ... FROM table_name WHERE condition1 AND condition2 AND condition3 ...; - OR Operator :
SELECT column1, column2, ... FROM table_name WHERE condition1 OR condition2 OR condition3 ...; - NOT Operator :
SELECT column1, column2, ... FROM table_name WHERE NOT condition1;
Order By
내림차, 오름차 순으로 정리할 때 사용
기본으로 오름차순(ASC)이 적용되어 있다.
-
기본 :
SELECT column1, column2, ... FROM table_name ORDER BY column1, column2, ... ASC|DESC; -
예시 1 :
SELECT * FROM Customers ORDER BY Country;Customers테이블에서Countrycolumn을 기준으로 오름차순 정렬
-
예시 2 :
SELECT * FROM Customers ORDER BY Country ASC, CustomerName DESC;Customers테이블에서Countrycolumn을 기준으로 오름차순 정렬을 하되, 같은Country를 가진 rows들 사이에서는CustomerName을 기준으로 내림차순으로 정렬
Insert Into
table에 새로운 데이터를 입력한다.
- 기본 :
INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...); - 예시 :
INSERT INTO Customers (CustomerName, City, Country) VALUES ('Cardinal', 'Stavanger', 'Norway');- 해당 coulumn에 values의 내용을 추가한다. 이 경우 누락된 coulum의 row에는
null이 표시될 것이다.
- 해당 coulumn에 values의 내용을 추가한다. 이 경우 누락된 coulum의 row에는
Update
table에 있던 기존 데이터를 수정한다.
- 기본 :
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition; - 예시 :
UPDATE Customers SET ContactName = 'Alfred Schmidt', City= 'Frankfurt' WHERE CustomerID = 1;Customers테이블의CustomerID가 1인 row의 해당 column의 값을 바꾼다.- WHERE 절이 누락되면 해당 테이블의 전체 row의 해당 column값이 바뀐다.
Delete
table에 있던 기존 데이터를 삭제한다.
- 기본 :
DELETE FROM table_name WHERE condition; - 예시 :
DELETE FROM Customers WHERE CustomerName='Alfreds Futterkiste';Customers테이블의CustomerName이 value와 일치하는 row를 삭제한다.- WHERE 절이 누락되면 해당 테이블의 전체가 삭제된다.
Count
특정 조건에 맞는 rows의 수가 반환된다.
-
기본 :
SELECT COUNT(column_name) FROM table_name WHERE condition; -
예시 :
SELECT COUNT(CustomerID) FROM Customers WHERE Country = "Mexico";Customers테이블의CustomerIDColumn중에서Country가 value와 일치하는 rows의 수를 반환- WHERE 절이 누락되면
CustomerIDCoulumn의 모든 rows의 수가 반환된다.
Join
두 개 이상의 테이블의 서로 관련된 column을 기초로 rows를 조합하는데 사용된다.
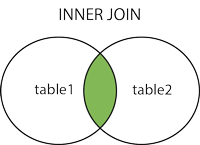
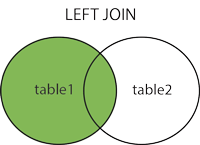
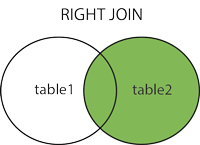
- (INNER) JOIN : 서로 공통된 레코드들을 반환
- LEFT (OUTER) JOIN : 왼쪽 테이블의 모든 레코드들과 오른쪽 테이블과의 공통 레코드들을 반환
- RIGHT (OUTER) JOIN : 오른쪽 테이블의 모든 레코드들과 왼쪽 테이블과의 공통 레코드들을 반환
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders
INNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
//예를 들어 Orders와 Customers 테이블을 INNER JOIN 한다면
//Orders가 그림 상 왼쪽 테이블, Customers는 오른쪽 테이블이다.
//이 경우 SELECT를 통해 양 쪽 Column에 모두 접근가능하다.
//ON 다음에는 조건문이 들어가게 되며, 조건문을 만족하는 레코드들이 반환될 것이다.
//이 경우 Orders테이블과 Customers 테이블에서 ID가 겹치는 레코드들만이 반환된다.
//보통 조건문에 들어가는 Column는 두 테이블간에 연관이 있는 경우가 많다.
//INNER 대신에 LEFT를 넣으면 조건문을 만족하는 레코드들뿐만 아니라,
//조건문을 만족하지 못하는 왼쪽 테이블의 모든 레코드들이 출력된다.
//대신 이 경우에는 OrderDate Column 부분은 Null으로 표시될 것이다.
Group By
보통 COUNT, MAX, MIN, SUM, AVG와 같은 함수들과 같이 쓰이며, 이 값들을 그룹화해서 반환한다.
//기본
SELECT column_name(s)
FROM table_name
GROUP BY column_name(s)
//상황에 따라 WHERE나 ORDER BY와 같은 구문이 들어갈 수 있다.
//예시
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country;
//위 경우 Customers 테이블에서 CustomerID의 개수를 계산한 뒤,
//그것을 Country에 따라 반환한다.
//만약 CustomerID의 레코드 수가 10일 때,
//Group By 구문이 없다면 CustomerID Column에 단순히 10을 출력할 것이다.
//하지만 Group By와 함께 쓰이면,
//Country에 따라 개수가 분할되어 출력된다.
하...JOIN을 뒤늦게 이해했습니다ㅋㅋㅋㅋ
mysql 첫 진입이 힘들지 그 뒤부터는 술술 넘어가네요ㅎㅎ
내일도 퐈이팅입니당!